










1 motivation
FEAT(CVPR2020)中提出了embedding adaptation这个概念,具体来说就是对support set的样本利用transformer等方式实现信息聚合,获取这些样本更好的特征。不足的地方是没有利用query信息。
2 contribution
1)为了改进基于模型的嵌入自适应,本文建议通过self attention对支持集和查询集的实例的嵌入/表示进行微调,以获取更利于分类的特征。
2)实验效果非常好,比最先进的方法高出3%∼5%。

3 Instance embedding adaptation

为了共同适应(co-adapt)支持和查询的嵌入 和
,本文引入一个额外的步骤,使用self-attention对得到的初始嵌入进一步适应。基本思想是通过只考虑区分性特征相似性,可以在
和
中找到需要关注的相关特征,从而重新加权特征。
3.1 Self attention
Attention function:
![]()
Multi-head Attention Block (MAB):
![]()
![]()
其中,γ 是ReLU函数。
3.2 Cross-adaptation with MAB
考虑从Support-query和query-support两个层面对实例的表示进行微调。具体地说,为了改进support特征,即query到support,使用query和support特征之间的注意分数来聚合初始support特征,生成与初始特征相关的支持原型,反之亦然,用于support到query,以生成改进初始查询特征的query特征。
对支持集和查询集的嵌入进行联合适应的过程:
![]()
![]()
![]()
MAB的具体实现:
![]()
![]()

根据适应后的支持集嵌入计算原型:
![]()
根据上面得到的原型和适应后的查询集嵌入对query进行分类:
![]()
4 实验部分
相比于FEAT效果提升很明显:
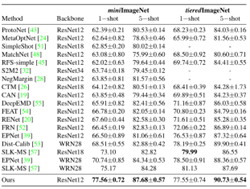
5 总结
本文主要是参考FEAT的方法进行了进一步的扩展,利用了query的信息,并且对query同样进行了信息聚合来微调表示,取得的效果非常好。而且,在元学习任务中分成了支持集和查询集两个部分,对query的利用应该是合理的,这和用testing的数据不太一样。















 1493
1493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









