







聊会天儿
欢迎加入深度“自”学研究所,让我们相互学习,共同进步!
本专栏以[美]弗朗索瓦·肖莱的《Python深度学习》一书作为学习资料,对其内容进行理解后制作思维导图和将代码进行运行后截图一并进行展示。
本专栏包含4篇内容,与目录一一对应。其中第8章与第9章代码未运行,只有思维导图。

环境配置:Anaconda创建keras2.6_gpu环境,其中
Python的版本号是:3.7.0
TensorFlow的版本号是:2.6.0
Keras的版本号是:2.6.0
本专栏所有内容基于个人理解,如有错误或偏颇,欢迎交流!
---------------------》》》》》目录《《《《《---------------------
第一章 相关资源库(含PDF、安装包、数据集)与环境搭建简介
第二章 Part 1 思维导图及代码清单
第三章 Part 2 思维导图及代码清单
第四章 纠错说明
---------------------》》》》》正文《《《《《---------------------
-
《Python深度学习》2018中文版PDF下载:https://pan.baidu.com/s/1Uav3gjqWPvyiEnja1U6HFw?pwd=2022
提取码:2022 -
环境搭建
2.1 下载Anaconda-
下载Anaconda历史史版本查询:https://repo.anaconda.com/archive/
-
官网下载Anaconda :https://www.anaconda.com/products/distribution#windows
-
百度网盘下载Anaconda 202205版本:链接:https://pan.baidu.com/s/1wSuL64ptIJv9tjSmWsoeyA?pwd=2022 提取码:2022
2.2安装Anaconda
默认选择一直到底; 建议安装位置选择非C盘,命名方式全英文与特殊字符组合。2.3查看GPU
桌面右键 --> 选择“NVIDIA控制面板” --> 选择“组件” --> 查看“NVCUDA64.DLL” --> 获取信息 —— CUDA版本是11.6.134 -


2.4安装GeForce Experience(需要注册账号)
参考安装博客:https://blog.csdn.net/weixin_43848614/article/details/117221384
CUDA是用于GPU计算的开发环境,它是一个全新的软硬件架构,可以将GPU视为一个并行数据计算的设备,对所进行的计算进行分配和管理。 在CUDA的架构中,这些计算不再像过去所谓的GPGPU架构那样必须将计算映射到图形API(OpenGL和Direct 3D)中,因此对于开发者来说,CUDA的开发门槛大大降低了 -------选自《百度百科》
2.5选择Python、TensorFlow、Keras版本
参考版本对比博客:https://blog.csdn.net/weixin_43760844/article/details/113477352
TensorFlow官网下载地址:https://pypi.org/project/tensorflow/
Python的版本号是: 3.7.0
TensorFlow的版本号是: 2.6.0
Keras的版本号是: 2.6.0
2.6创建环境并进行安装
创建环境名: Keras2.6_gpu
建议安装包下载后使用" pip 绝对路径 " 进行安装,
下载网址选择国内镜像,官网那个下载十分缓慢且亦中断。
安装jupyter notebok 参考博客:https://zhuanlan.zhihu.com/p/33105153(环境配置.pdf有相关内容)
2.7成果展示

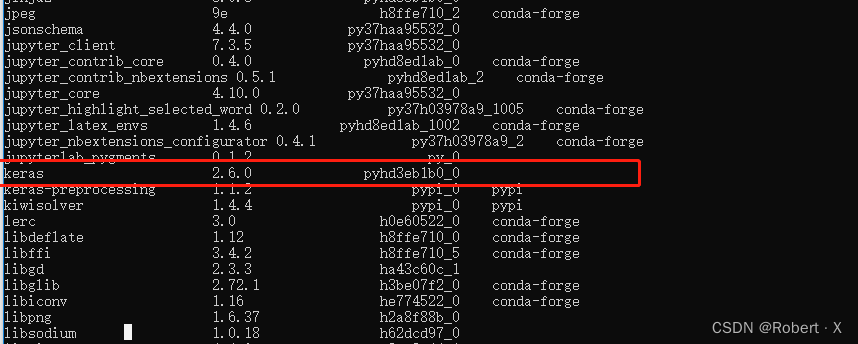
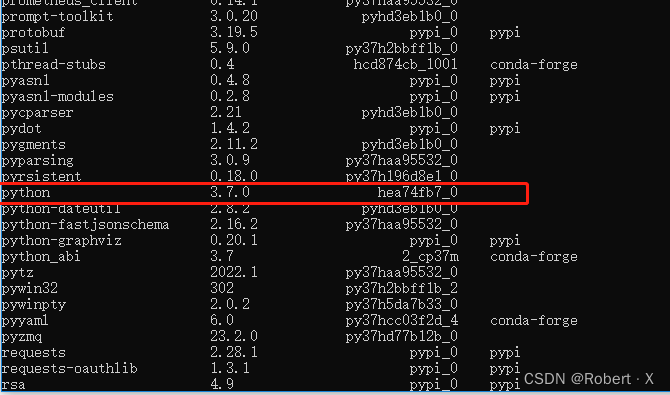
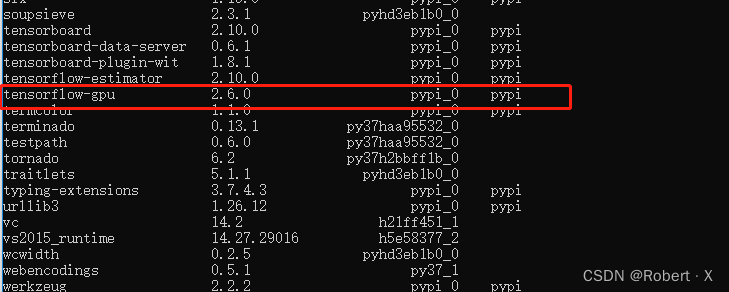
以上操作可看“环境配置.pdf”文件辅助查阅。
提取密码:2022















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









