






概要
在本文中将介绍使用Python语言,基于TensorFlow搭建ResNet50卷积神经网络对四种动物图像数据集进行训练,观察其模型训练效果。
一、目录
-
ResNet50介绍
-
图片模型训练预测
-
项目扩展
二、ResNet50介绍
ResNet50是一种基于深度卷积神经网络(Convolutional Neural Network,CNN)的图像分类算法。它是由微软研究院的Kaiming He等人于2015年提出的,是ResNet系列中的一个重要成员。ResNet50相比于传统的CNN模型具有更深的网络结构,通过引入残差连接(residual connection)解决了深层网络训练过程中的梯度消失问题,有效提升了模型的性能。
-
深度卷积神经网络(CNN) CNN是一种专门用于图像处理的神经网络结构,具有层次化的特征提取能力。它通过交替使用卷积层、池化层和激活函数层,逐层地提取图像的特征,从而实现对图像的分类、检测等任务。然而,当网络结构变得非常深时,CNN模型容易面临梯度消失和模型退化的问题。
-
残差连接(Residual Connection) 残差连接是ResNet50的核心思想之一。在传统的CNN模型中,网络层之间的信息流是依次通过前一层到后一层,而且每一层的输出都需要经过激活函数处理。这种顺序传递信息的方式容易导致梯度消失的问题,尤其是在深层网络中。ResNet50通过在网络中引入残差连接,允许信息在网络层之间直接跳跃传递,从而解决了梯度消失的问题。
-
残差块(Residual Block) ResNet50中的基本构建块是残差块。每个残差块由两个卷积层组成,这两个卷积层分别称为主路径(main path)和跳跃连接(shortcut connection)。主路径中的卷积层用于提取特征,而跳跃连接直接将输入信息传递到主路径的输出上。通过将输入与主路径的输出相加,实现了信息的残差学习。此外,每个残差块中还使用批量归一化(Batch Normalization)和激活函数(如ReLU)来进一步提升模型的性能。
-
ResNet50网络结构 ResNet50网络由多个残差块组成,其中包括了一些附加的层,如池化层和全连接层。整个网络的结构非常深,并且具有很强的特征提取能力。在ResNet50中,使用了50个卷积层,因此得名ResNet50。这些卷积层以不同的尺寸和深度对图像进行特征提取,使得模型能够捕捉到不同层次的特征。
三、模型训练预测
在本文中选取了常见的四种动物数据(猫、狗、马、鸡),文件夹结构如下图所示。


在完成数据集的收集准备后,打开jupyter notebook平台,导入数据集通过以下代码可以计算出数据集的总图片数量。本次使用的数据集总图片为4000张。
import pathlib
data_dir = "./dataset/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
然后划分TensorFlow的image_dataset_from_directory方法划分测试集和训练集。再构建模型。在本文中如下图所示
# 加载resnet50模型
model = keras.applications.ResNet50(weights='imagenet', include_top=True)
这段代码的目的是使用Keras库加载预训练的ResNet50模型,并将其应用于图像分类任务。
具体解释如下:
-
keras.applications.ResNet50: 这是Keras库中的一个函数,用于加载ResNet50模型。ResNet50是一个已经定义好的模型架构,包含了数十个卷积层、池化层和全连接层,用于图像分类任务。 -
weights='imagenet': 这个参数指定了模型所使用的权重。'imagenet'是一个大规模的图像数据集,ResNet50在该数据集上进行了预训练,因此通过设置这个参数,我们可以加载已经在该数据集上训练好的权重。这样的预训练权重可以提供较好的特征表示能力,有助于提升模型在图像分类任务上的性能。 -
include_top=True: 这个参数指定是否包含模型的顶层(即全连接层)。当设置为True时,加载的模型将包含原始ResNet50模型的所有层,包括最后的全连接层,用于输出分类结果。如果我们只需要使用ResNet50的特征提取能力而不需要分类层,则可以将该参数设置为False。
然后开始训练,其训练过程如下图所示

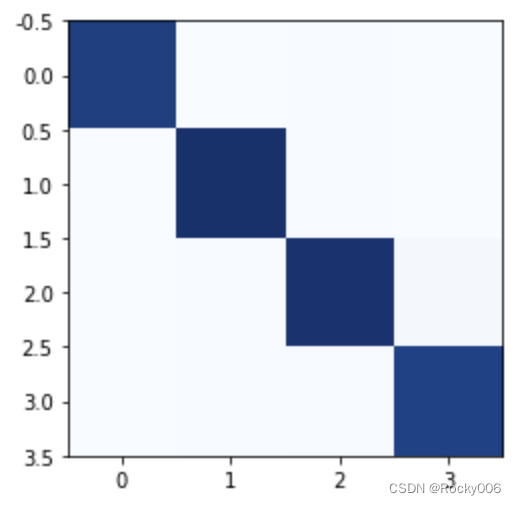
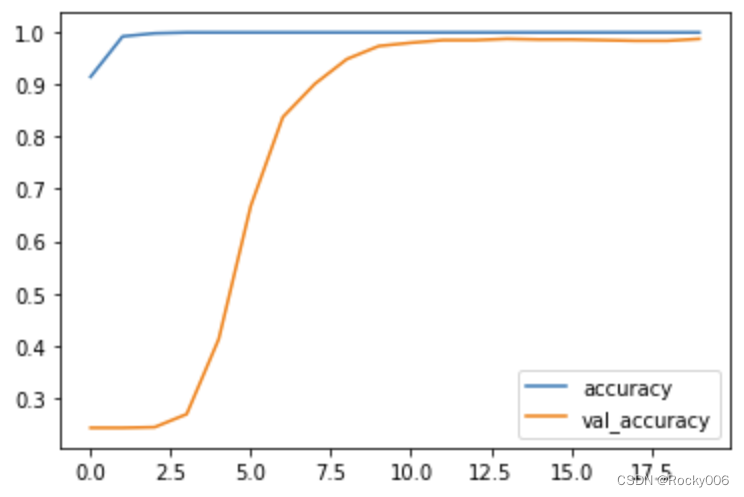
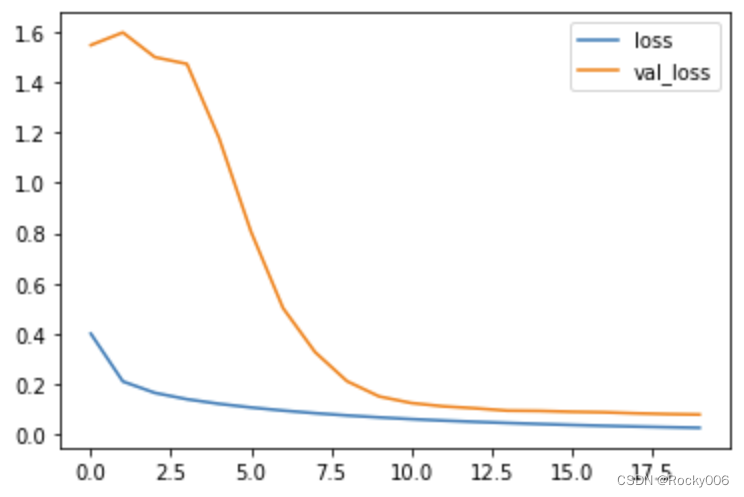
通过上图可知,通过20轮迭代训练,在最后一轮迭代完成后,模型在测试集上面的精度为0.9875,精度还是非常高的。接下来就是打印下ACC曲线图和LOSS曲线图以及混淆矩阵图等。通过图片可知,算法的拟合度还是比较理想的。
三、项目扩展
在完成模型训练后,通过model.save方法保存模型为本地文件,然后就可以基于改模型开发出非常多的应用了,比如开发出API接口给别人调用等。
今天的分享就到这里,欢迎点赞收藏转发,感谢🙏


















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











