






分析目的:
1、了解每个国家有多少运动员?
2、球员数量在100以上的国家数量有多少?
3、各大联赛运动员数量是多少?
4、查看各个俱乐部的平均周薪(看5条)?
5、球员年龄段分布情况?
#引入使用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#加载数据文件
df = pd.read_csv(r'D:\学习文件\Python案例\FIFA_2018_player.csv')
## ***开始清洗数据***
#查看数据类型
df.head()
#看一下数据整体的信息
df.describe()
#看看name列有没有null值
df[df.name.isnull()]
#看看full_name是不是有null值
df[df.full_name.isnull()]
#看看nationality是不是有null值
df[df.nationality.isnull()]
#看看league是不是有null值
df[df.league.isnull()] #发现有null值,数量不多,不影响正常分析删除即可
#删除空值
df.drop(df[df.league.isnull()].index,inplace = True)
#查看是否删除成功
df[df.league.isnull()]
#看看club有没有null值
df[df.club.isnull()]
#查看age列是不是有不正常的值存在
df[df['age'] ==16]
#看一下eur_value(价值)有没有异常值
df[df['eur_value']<=1000] #发现有几条数据eur_value值是0,用平均值填充
#用平均值填充eur_value为0的列
df['eur_value'].replace(0,df['eur_value'].mean(),inplace = True)
#查看是否填充成功
df[df['eur_value']<=1000]
df.loc[7734]
#看看eur_wage(周薪)的情况
df[df['eur_wage'] <1000 ]
#查看全部是不是有重复值
df[df.duplicated()]
#也可以查看部分自己需要用到的列('full_name','nationality','birth_date'是我现在需要用到的列,以此为列:)
df[df.loc[:,['full_name','nationality','birth_date']].duplicated()]
## ***数据清洗完毕,开始分析***
#统计一下总共有多少条可用数据
df.count()
#再来看一下数据整体的信息(重点关注最大最小 平均 数量等)
df.describe()
#1、了解每个国家有多少运动员?
nationality_data = df.groupby('nationality',as_index=False).count()[['nationality','ID']]
nationality_data #查看一下结果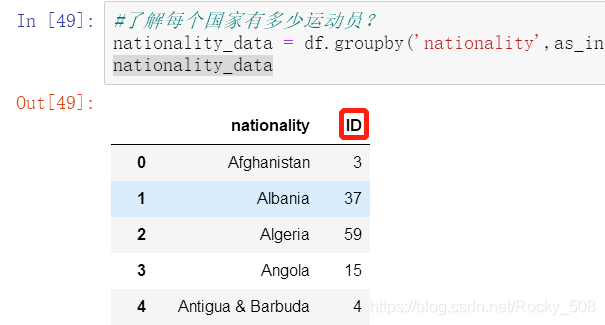
#为了方便查看,把ID列重新命名为:player_count
nationality_data.rename(columns={'ID':'player_count'},inplace=True)
nationality_data #命名成功,发现顺序是乱的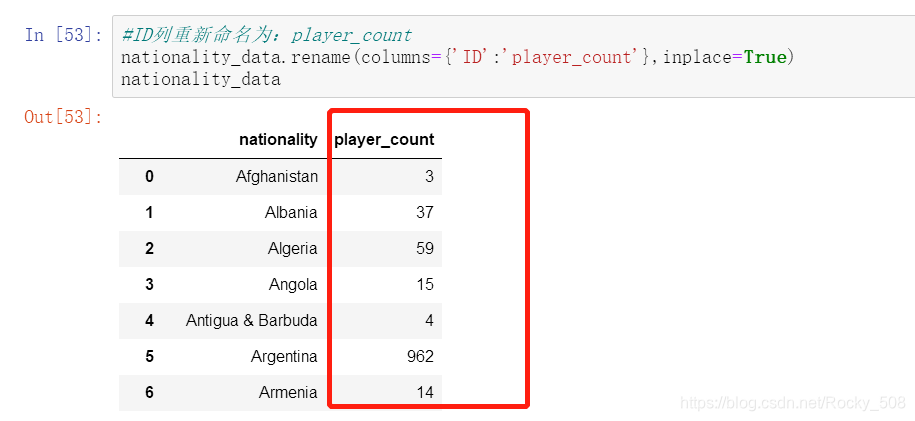
#按着远动员数量来排名 用 sort_values 来做排序
nationality_sorted_data = nationality_data.sort_values('player_count',ascending=False)
nationality_sorted_data
#2、查看球员数量在100以上的国家
nationality_sorted_data[nationality_sorted_data.player_count>100]
#球员数量在100以下的国家数量
nationality_sorted_data[nationality_sorted_data.player_count<100].count()
#各大联赛运动员数量
league_data = df.groupby('league',as_index=False).count()[['league','ID']].sort_values('ID',ascending=False)
league_data
#各个俱乐部的平均周薪,查看前5条
df.groupby('club',as_index=False).mean()[['club','eur_wage']].sort_values('eur_wage',ascending=False).head(5)
#球员年龄段分布,以3位间隔
bins = np.arange(15,50,3)
bins_data = pd.cut(df['age'],bins)
bins_counts = df['age'].groupby(bins_data).count()
bins_counts
#为了图标展示好看的数据index,使用直方图展示
bins_counts.index = [str(x.left) + '~' + str(x.right) for x in bins_counts.index]
bins_counts.plot(kind='bar',alpha=1,rot=0)
#使用饼图展示
bins_counts.plot(kind='pie')
plt.show()
##球员身高175-180总人数,
height = np.arange(155,205,5)
height_data = pd.cut(df['height_cm'],height)
height_counts = df['height_cm'].groupby(height_data).count()
height_counts
以上是自己敲出来的代码,小白第一次案例分析,还请大神多留言帮助小弟成长。
后续有新的学习案例分析会逐步更新哟————————

















 5220
5220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









