






Abstact
具有图像级别标签的弱监督语义分割(WSSS)是一项重要且具有挑战性的工作。由于训练效率高,WSSS的端到端解决方案越来越受关注。然而,目前的方法主要基于卷积神经网络,无法正确探索出全局的信息,因此通常会导致对象区域(object regions)不完整。本文为解决上述问题引入了Transformer,它自然地集成了全局信息,为端到端的WSSS生成更完整的初始伪标签。受Transformer中的自注意力机制(self-attention)与语义亲和力信息(semantic affinity)有内在联系这一特点,本文提出了一个Affinity from Attention机制(AFA,从注意力中提取亲和性)来从Transformer中的多头自注意力机制(MHSA)学习语义亲和力(semantic affinity),然后利用学习到的亲和力来细化初始伪标签以进行分割。此外,为了有效地导出用于监督AFA的可靠亲和力标签,并确保伪标签的局部一致性,本文还设计了一个像素自适应细化模块(Pixel-Adaptive Refinement),该模块结合了low-level图像外观信息来细化伪标签。提出的方法PASCAL VOC 2012和MS COCO 2014数据集上显著优于最近的端到端方法。
1 Introduction
旨在标记图像中每个像素的语义分割是视觉中一项基本任务,过去十年中深度神经网络(DNN)在语义分割方面取得了巨大成功。然而由于DNN中数据匮乏(data-hungry)的特性,全监督语义分割通常需要耗费大量人力来进行像素级标签的标注。为了解决这个问题,近期的一些方法设计了使用弱标签的语义分割模型,如图像级别标签、点标签、涂鸦型标签和边界框等。本文的方法仅使用图像级别的标签,是所有WSSS场景中最具有挑战性的方法。
图像级标签的弱监督语义分割方法中,比较流行的是采用多阶段的框架。具体而言,这些方法首先训练一个分类模型,然后生成类激活图(CAM)作为伪标签。经过细化后,伪标签被用来训练一个独立的语义分割网络作为最终模型。这种多阶段的框架需要针对不同的目的训练多个模型,因此使训练流程复杂化,并减慢了训练速度。为避免这个问题,近期出现了几个WSSS问题的端到端(End-to-end)解决方案。然而这些方法通常基于卷积神经网络,无法正确探索全局特征关系——而全局关系对于激活整体对象区域至关重要,会显著影响生成的伪标签的质量。
最近,Transformer在众多视觉应用中取得重大突破,本文认为它自然有利于WSSS。首先,Transformer中的自注意力机制可以对全局特征关系进行建模,克服上述CNN的缺点,从而发现更多完整的对象区域。

如图1所示,Transformer中的多头自注意力(MHSA)可以捕获语义级别的亲和力,因此可以用于改进粗伪标签。然而从图1(b)中可以看出,在MHSA机制中捕获的亲和力仍然不够准确,即直接应用MHSA作为Affinity来修改标签效果不佳,如图1(c)所示。
基于上述分析,本文提出了一个基于Transformer的WSSS端到端框架。具体来说是利用Transformer生成CAM作为初始伪标签,以避免卷积神经网络的内在缺陷。本文进一步利用Transformer块中内在的亲和力来改进初始伪标签。由于MHSA中的语义亲和性很粗糙,我们提出了一个Affinity from Attention(AFA)模块,旨在导出可靠的伪亲和力标签,以监督从Transformer中的MHSA学习的语义亲和力。学习到的亲和力通过随机游走传播(random walk propagation)(CVPR2018)来修改初始伪标签,这可以扩散对象区域、抑制错误激活的区域。为了AFA推导出高度可信的伪标签并确保传播的伪标签的局部一致性,本文进一步提出了一个像素自适应细化模块Pixel-Adaptive Refinement(PAR)。基于像素自适应卷积,PAR有效地整合了局部像素的RGB和位置信息以细化伪标签,从而更好地与Low-level图像外观对齐。此外鉴于简单性,本文的模型可以以端到端的方式进行训练,从而避免了复杂的training pipeline(训练流程)。PASCAL VOC 2012和MS COCO 2014的实验结果表明,本文方法明显优于最近的端到端方法和几个采用多阶段框架的方法。
总体而言,本文的贡献主要有以下几点:
- 为图像级标签的WSSS任务提出了一个基于Transformer的端到端框架,这是对于Transformer运用到WSSS任务中的首次探索。
- 利用Transformer的内在优势并设计出AFA模块。AFA从MHSA机制中学习可靠的语义亲和性,并使用学习到的亲和性传播伪标签。
- 提出了一种高效的像素自适应细化模块(PAR),该模块结合了局部像素的RGB和位置信息以进行标签细化。
2.Related Work
2.1 弱监督语义分割
- 多阶段方法。大多数图像级别的WSSS方法都使用多阶段过程。通常先是训练分类网络,使用CAM生成初始伪像素级标签。为了解决CAM生成对象激活图不完整的问题,有方法(46,56,40)提出利用擦除策略,擦除最具有辨别力的区域,从而发现更完整的对象区域。受分类网络在不同训练阶段倾向于关注不同对象区域的观察的启发,(16,51,18)在训练过程中累积激活区域,(26,39,47)提出从多个输入图像中挖掘语义区域,发现相似的语义区域。还有一类流行的具有辅助任务的WSSS分类网络,确保完整的对象发现(45,7,35,36)。最近的一些研究从新颖的角度解释了CAM的生成,例如因果推理(55)、信息瓶颈理论(22)、反对抗攻击(23)
- 端到端方法(End-to-End Method):由于监督极其有限,很难为WSSS训练一个具有良好性能的端到端模型。【31】提出了一种自适应期望最大化框架来推断用于分割的伪标签(pseudo ground truth for segmention)。【32】将图像级标签的WSSS处理为多实例学习(MIL)问题,并设计了Log-Sum-Exp聚合函数来驱动网络分配正确的像素标签。结合nGWP pooling(利用归一化的全局加权平均池化),pixel-adaptive mask refinement和stochastic low-level information transfer等方法,单阶段模型实现了与多阶段模型相当的性能。【53】中,RRM(可靠区域挖掘)将CAM作为初始伪标签,并使用CRF(条件随机场)生成细化标签作为分割的监督。RRM还引入了辅助正则化损失来保证分割图和低级图像外观的一致性。上述的这些方法通常采用CNN,都带有卷积的固有缺点,即无法捕获全局信息,导致对象的不完全激活。本文探索了用于端到端的WSSS的Transformer来解决这个问题。
2.2 Transformer in Vision
ViT是第一个将纯Transformer架构应用于视觉识别任务的工作,在视觉分类基本问题上性能惊人,后来的变体表明,ViT也有利于下游视觉任务,如语义分割、深度估计和视频理解。有方法【13】提出了用Transformer-based method做弱监督目标定位(WSOL)。WSOL旨在仅通过图像级监督来定位对象。该方法训练具有图像级标签的ViT模型,生成语义感知CAM,并将生成的CAM与语义无关注意图耦合,与语义无关的注意力图是从class-token对其他patch-token的注意力提出的。尽管如此,该方法没有运用MHSA中内在的语义亲和力来提升定位结果。本文提出从MHSA中学习可靠的语义亲和力,并使用学习到的亲和力来传播CAM。
3.具体方法
文章的这一部分首先介绍了Transformer主干网络和CAM,它们生成了最初的伪标签。然后展示了AFA模块,它可以学习可靠的语义亲和力,并利用学习到的亲和力来传播最初的伪标签。随后文章又提出了像素自适应细化模块来保证伪标签的局部一致性。
3.1 Transformer Backbone
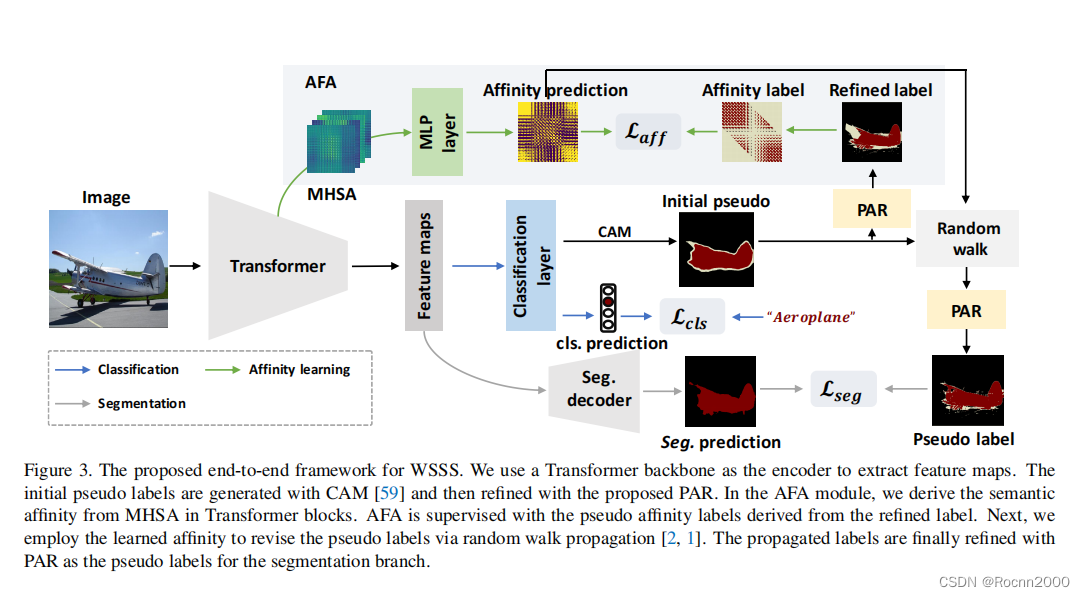
如图3所示,本文提出的框架以Transformer为主干,输入的图片首先被分割成
h
×
w
h×w
h×w个patches,每个patches都被拉平并线性摆放成
h
×
w
h×w
h×w个tokens。在每个Transformer模块中,多头自注意力机制(MHSA)捕获全局特征依赖关系。具体而言,对于MHSA中的第
i
i
i个头,patch tokens用一个MLP(多层感知机)进行投影,并建立起以下三个矩阵:
Q
i
∈
R
h
w
×
d
k
Q_i∈R^{hw×d_k}
Qi∈Rhw×dk,
K
i
∈
R
h
w
×
d
k
K_i∈R^{hw×d_k}
Ki∈Rhw×dk和
V
i
∈
R
h
w
×
d
v
V_i∈R^{hw×d_v}
Vi∈Rhw×dv,其中
d
k
d_k
dk是queries和keys的特征维度,
d
v
d_v
dv是values的特征维度。基于这三个矩阵进行计算,自注意力矩阵
S
i
S_i
Si和输出
X
i
X_i
Xi分别是
S
i
=
Q
i
K
i
T
d
k
\\S_i=\frac{Q_iK_i^T}{\sqrt{d_k}}
Si=dkQiKiT
最终Transformer Blocks的输出结果放入前馈神经网络(FFN)中(包含了Layer normalization和MLP层)。堆叠了多个Transformer块后,该主干部分能为后续模块生成特征图。
3.2 CAM生成
考虑到其简单性和推理效率,本文采用CAM方法作为初始伪标签。对于之前得到的特征图和给定的类别,CAM图由特征图中各部分对该类别的贡献得到。ReLU函数用来去掉激活值为负数的部分,min-max归一化将激活值的范围归一到[0,1]范围内,Background score被用来区分前景区域和背景区域。
3.3 Affinity from Attention
如图1所示,Transformer中的多头自注意力机制与语义亲和力之间存在一致性,这启发我们用MHSA来发现对象所在的区域。然而在训练过程中,由于没有对自注意力矩阵加以明确的约束,通过MHSA学习到的亲和力通常是粗糙且不准确的。这意味着直接应用MHSA作为亲和力来细化标签效果不佳。本文提出AFA模块来解决这一问题。
假设Transformer块中的MHSA表示为
R
h
w
×
h
w
×
n
R^{hw×hw×n}
Rhw×hw×n,其中
h
w
hw
hw是图片块被铺平后的长度,
n
n
n是自注意力的头数。在我们的AFA模块中,我们通过线性组合多头自注意力,也就是使用MLP层,直接产生语义亲和力。本质上自注意力机制是一种有向图模型,而亲和力矩阵应该是对称的,因为共享相同语义的结点应该是相等的。为了执行这种转换,我们只需要添加S及其转置,预测出来的语义亲和力矩阵可表示为
A
=
M
L
P
(
S
+
S
T
)
A=MLP(S+S^T)
A=MLP(S+ST)
伪亲和标签的生成:
要学习到正确的语义亲和力
A
A
A,关键的一步是生成可靠的伪亲和力标签
Y
a
f
f
Y_{aff}
Yaff作为监督。如图3所示,我们从细化的伪标签中生成
Y
a
f
f
Y_{aff}
Yaff(细化模块将会在稍后介绍)。















 9180
9180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









