






低秩张量约束多视图子空间聚类
Abstract:
在本文中,我们探讨了多视图子空间聚类问题。我们引入低秩张量约束来探索多个视图的互补信息,并相应地建立了一种称为低秩张量约束的多视图子空间聚类“Low-rank Tensor constrained Multiview Subspace Clustering” (LT-MSC)的新方法。我们的方法将不同视图的子空间表示矩阵视为张量,它巧妙地捕获多视图数据背后的高阶相关性。然后,张量配备低秩约束,可以优雅地建模不同视图之间的交叉信息,有效减少学习到的子空间表示的冗余,并提高聚类的准确性。用于聚类的亲和力矩阵的推理过程被表述为张量核范数最小化问题,并受到额外的 l2,1-范数正则化器和一些线性等式的约束。最小化问题是凸的,因此可以通过增强拉格朗日交替方向最小化(AL-ADM)方法有效地解决。在四个基准图像数据集上的大量实验结果表明了所提出的 LT-MSC 方法的有效性。
“1. Introduction” 一、简介
机器学习和计算机视觉中的许多问题都涉及多视图数据,其中每个数据点由来自多个特征源的不同信息表示。例如,在计算机视觉问题中,图像和视频通常由不同类型的特征来描述,例如颜色、纹理和边缘。网页还能够基于文本、超链接和可能存在的视觉信息以多视图方式表示。一般来说,多视图表示可以无缝地捕获来自多个数据线索的丰富信息以及不同线索之间的互补信息,从而有利于各种任务,例如聚类、分类、去噪。在本文中,我们重点关注通过利用多视图表示来推进聚类。
为了将不同的特征集成到统一的框架中,大多数现有的多视图聚类方法都采用基于图的模型。早期的方法侧重于“two-view”的设置[14,1,6]:[14]中最新的方法构建二部图来连接两类特征,并使用标准的谱聚类算法来获得最终的聚类结果。 [1] 中的方法扩展了 k-means 来处理两个条件独立视图的数据。
这些早期的方法依赖于只有两个视图的假设,因此很难将它们扩展到三个或更多视图的情况。 [35]中的方法将来自多个图的信息与链接矩阵分解(LMF)融合。
为了利用互补信息,一些方法采用协同正则化和协同训练策略,例如[4]、[5]、[23] ,[37]和[22]。
基于降维的方法[2, 7]通常使用典型相关分析(CCA)将高维多视图数据投影到低维子空间上。
方法[39]恢复共享的低秩转移概率矩阵作为标准马尔可夫链聚类方法的关键输入。 [10]中的工作通过结合不同观点的拉普拉斯算子来学习谱聚类框架下的共同表示。
虽然有效,但现有方法可能无法充分发挥多视图表示的优势。事实上,大多数先前的方法仅捕获不同视图之间的成对相关性,但本质上忽略了多个视图背后的高阶相关性。此外,现有方法的推理过程经常导致非凸优化问题,通常不能保证产生全局最优解。 [38]中的方法达到了凸公式,但同样仅限于双视图的情况。正如稍后所示,所提出的方法将推理过程表述为凸优化问题,并无缝捕获多个视图之间的高阶交叉信息。
我们提出了一种新颖的多视图聚类方法,称为低秩张量约束多视图子空间聚类(LT-MSC)。与大多数现有方法通常忽略多视图表示的高阶信息不同,我们的 LT-MSC 将各个视图的所有子空间表示视为高阶结构,即张量,如图 1 所示。
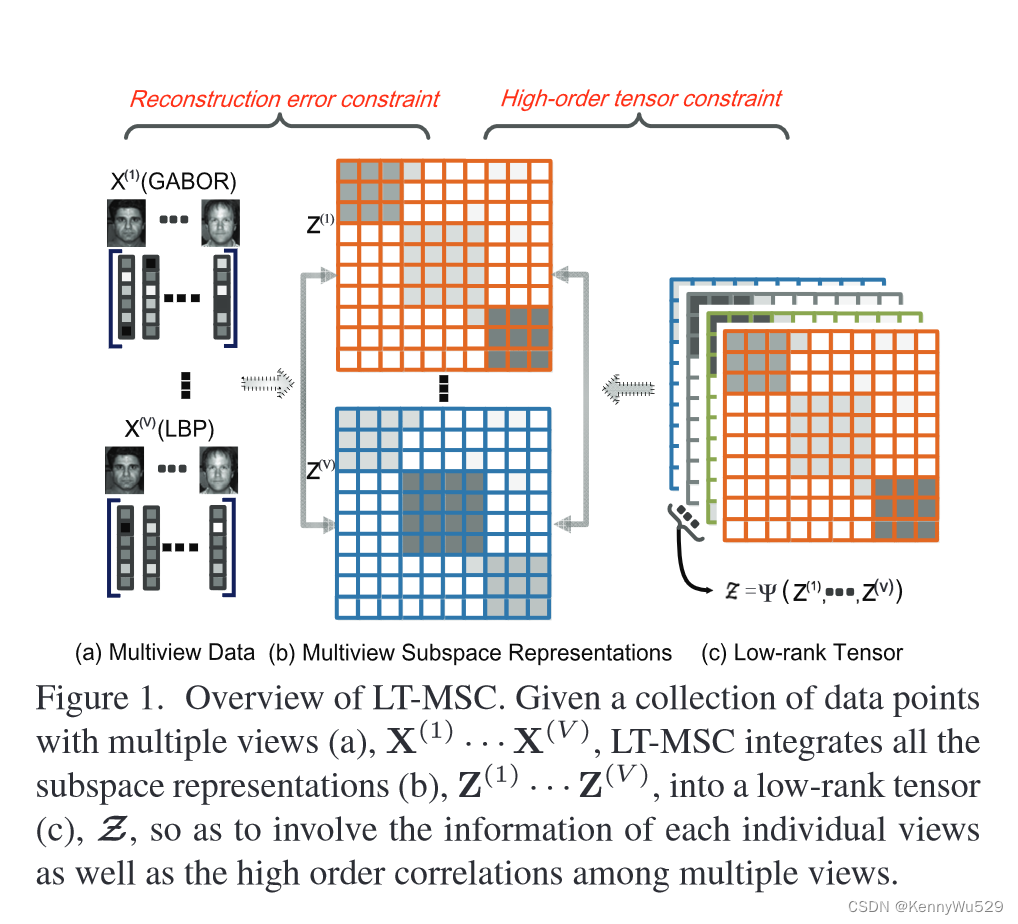
图 1. LT-MSC 概述。给定具有多个视图的数据点集合 (a), X(1) …X(V ),LT-MSC 将所有子空间表示 (b), Z(1) …Z(V ),整合成为一个低阶张量(c),Z,以包含每个单独视图的信息以及多个视图之间的高阶相关性。
张量配备了低秩约束,可以优雅地建模不同视图之间的高阶交叉信息,有效地减少了学习到的子空间表示的冗余,并提高了聚类的准确性。
与流行的子空间聚类方法(例如[15,28,21])类似,LT-MSC也采用两阶段聚类框架:首先从给定的数据点学习亲和力矩阵,然后使用谱聚类来产生最终的聚类结果。我们将亲和矩阵的推理过程表述为受附加 l2,1-范数正则化器约束的张量核范数最小化问题。最小化问题是凸的,因此可以通过增强拉格朗日交替方向最小化(AL-ADM)[26]方法有效地解决。
这项工作的贡献总结如下:
1)我们提出了一种新的方法,称为 LT-MSC,用于对多视图表示的数据进行聚类。通过使用低秩张量将各个视图的所有子空间表示集成在一起,LT-MSC 很好地捕获了高阶信息,从而在我们广泛的实验中明显优于以前的方法。
2)我们的方法中的张量用于捕获所有视图的全局结构并探索多个视图内和多个视图之间的相关性,而不是保留图像的空间信息(例如[16,20,3])。
3)我们为最近建立的低秩表示(LRR)[28]提供了有效的扩展,这是一种单视图数据的子空间聚类方法。
“2. Related Work” 2.相关工作
近年来,人们提出了大量的多视图学习方法。大多数现有方法侧重于通过标记数据进行监督学习。
对于聚类任务,现有的方法可以大致分为三类。
第一行利用基于图形的模型的多视图功能。例如,[14]中的工作构建二部图来连接双视图特征,并使用标准谱聚类来获得2视图聚类结果。 [35]中的方法将来自多个图的信息与链接矩阵分解相融合,其中每个图通过具有图特定因子和所有图共同因子的矩阵分解来近似。
第二类方法通常在聚类之前首先学习公共空间。 [23]、[37]中的方法共同规范聚类假设,以利用谱聚类框架内的补充信息。在[22]中,提出了一个基于协同训练的框架,它搜索在不同视图中一致的聚类。
第三条研究路线基于多核学习(MKL)。正如早期工作 [11] 中所建议的,与更复杂的分类方法相比,即使简单地通过添加不同的内核来组合它们也通常会产生接近最佳的结果。视图不是平均地添加这些内核,而是根据给定的内核矩阵来表达,并且与[17]中的划分并行地学习这些内核的加权组合。请注意,这些方法中的亲和力矩阵是独立构建的,而我们的 LT-MSC 联合构建亲和力矩阵,旨在捕获不同视图之间的高阶相关性。
我们的工作与[15,28,21,42]的工作密切相关,因为我们也专注于子空间聚类,但数据设置有所不同。在我们的例子中,数据配备了多视图功能。方法[15,28,21]已经实现了最先进的性能。然而,他们只考虑单视图特征,其中亲和力矩阵是基于这些重建系数构建的。 [18]中的工作将多视图子空间学习表述为具有公共子空间表示矩阵和群稀疏诱导范数的联合优化问题。 [38] 中的工作提供了 2 视图子空间学习的凸重构。有一些基于降维的方法,通常从多个视图中学习低维子空间,然后应用任何现有的聚类方法来获得结果。该流中的代表性方法在[2, 7]中提出,它们使用典型相关分析(CCA)将多视图高维数据投影到低维子空间上。请注意,与基于自我表示的方法[15,28,21]不同,所有这些多视图聚类方法都追求低维子空间。相反,我们通过使用高阶张量约束来探索不同视图之间的相关性,将基于自我表示的子空间聚类扩展到多视图设置。
“3. The Proposed Approach” 3. 提议的方法
子空间聚类将数据聚类到多个子空间中。具体来说,在本文中,我们考虑基于自表示的子空间聚类方法,该方法通过重建系数构造亲和力矩阵。假设 X =[x1, x2, ..., xN ] ∈ RD×N 是数据向量矩阵,其中每一列是一个 D 维样本向量。为了将数据聚类到各自的子空间中,我们首先计算以下 [15,28,21] 的子空间表示矩阵 Z:
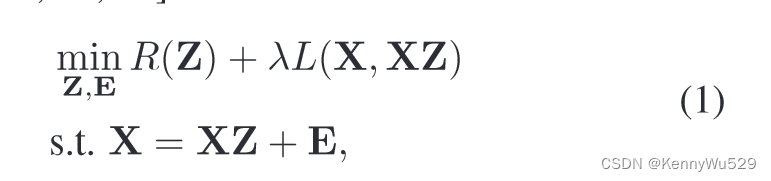
其中 Z =[z1, z2, ..., zN ] ∈ RN×N 是学习的子空间表示矩阵,每个 zi 是样本 xi 的学习子空间表示,E 是重建误差矩阵。 L(·,·)表示损失函数,R(·)是正则化器,λ是控制损失惩罚强度的超参数。
得到自表示矩阵Z后,进一步得到亲和度矩阵(例如(|Z| + |ZT |)/2,其中|Z|为Z的元素取绝对值形成的矩阵),并且输入到谱聚类算法[30]以产生最终的聚类结果。
尽管取得了有希望的性能,但所有这些方法都集中在单视图数据上。一种自然的方式扩展方程式(1)来处理多视图数据如下:

其中X(v)、Z(v)和E(v)分别表示第v个视图的数据矩阵、子空间表示矩阵和重建误差矩阵。 λv 是一个超参数,控制第 v 个视图的损失惩罚强度。 V 是观看次数。然而,这种幼稚的方式只独立地考虑每个视图,忽略了不同视图之间的相关性。为了解决这个问题,我们建议用张量来约束这些亲和矩阵。
“3.1. Formulation” 3.1.公式
在我们的努力中,我们将低秩张量约束引入子空间聚类,并提出一种低秩张量约束多视图子空间聚类方法来共同学习不同视图的子空间表示并探索不同视图之间的内在相关性。张量是矩阵概念的推广。我们给出了[29, 36]中使用的张量核范数的定义,它将矩阵(即2模或2阶张量)情况(例如[28, 40, 41])推广到高阶张量:

其中 ξm’s 是满足 ξi > 0 且 ΣM m=1 ξm =1 的常数。 Z ∈ RI1×I2×...×IM 是一个 M 阶张量,Z(m) 是张量 Z 沿着第 m 个模式展开的矩阵,定义为 unfoldm(Z)=Z(m) ∈ RIm×(I1×...×Im−1×Im+1...×IM ) [13, 12]。核范数 ||·||* 在低秩约束下强制执行张量。本质上,张量的核范数是沿每个模式展开的所有矩阵的核范数的凸组合。
在低秩张量约束下,我们的 LT-MSC 的目标函数可以表示为

其中 Ψ(·) 通过将不同的表示 Z(v) 合并为维度为 N × N × V 的三阶张量来构造张量 Z,如图 1(c) 所示。 E=[E(1); E(2); ...; E(V )] 是通过沿着与每个视图相对应的误差列垂直连接在一起而形成的。 ||.||2,1 是 l2,1-范数,它鼓励 E 的列为零。
这里的基本假设是损坏是特定于样本的,即一些数据点被损坏,一些数据点是干净的。这种积分方式将强制 E(1)、E(2)、...、E(V ) 的列具有共同一致的幅度值,其有效性已被广泛证明[8]。请注意,我们对不同视图的数据矩阵进行归一化,以强制不同视图的误差具有相同的尺度,这可以减少不同视图之间误差大小的变化。直观地说,方程中的目标函数(4)通过多种视图的共同协作来寻求自我表征的最低等级。
对于我们的目标函数方程(4),我们将 ||Z||* 替换为等式 (3)中的定义,相应地,方程(4) 的优化问题变换如下:

其中 γm = ξm/λ > 0 编码了低秩张量约束的强度,约束与(4)中相同。注意,Z(v)是第v个视图对应的子空间表示矩阵,而Z(m)是Z的第m个模式展开矩阵。
“3.2. Optimization Procedure” 3.2.优化程序
据我们所知,ALM 是解决该问题最快的算法。为了对我们的问题(5)采用交替方向最小化策略,我们需要使我们的目标函数可分离。因此,我们按照[36]引入M个辅助变量Gm’s,并将其转换为凸优化问题:
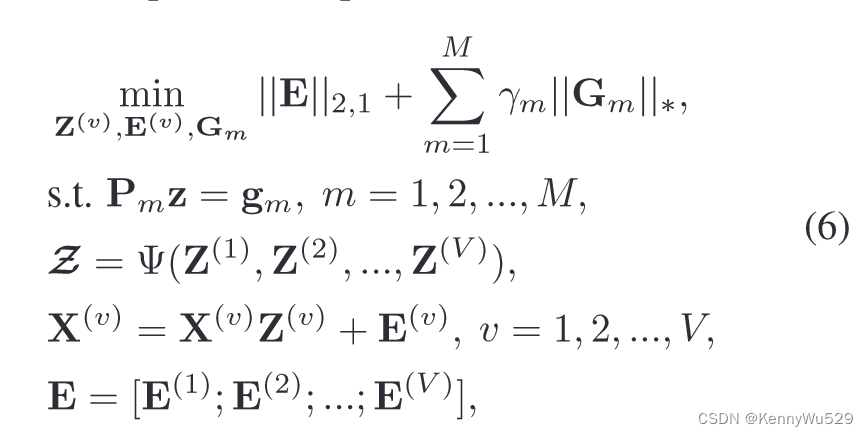
其中 z 是张量 Z 的矢量化,gm 是矩阵 Gm 的矢量化。 Pm是对应于模式k展开的对齐矩阵,它是用于对齐Z(m)和Gm之间的对应元素的置换矩阵。
第一个约束(前两个等式)确保解 Z 为低秩,因为 Gm’s 被强制为低秩。
第二个约束(第三个等式)将同一簇(即相同的线性子空间)的数据点关联起来,而带有 l2,1-norm 的最后一个约束(最后一个等式)给出了误差的基本假设,即样本-具体错误。
方程的优化问题(6) 可以通过 AL-ADM 方法[26]求解,该方法最小化以下增广拉格朗日函数:

为了简单起见,我们给出定义 Φ(Y, C)= 1/2 ||C||2F + 〈Y, C〉,其中〈·,·〉表示矩阵内积,μ 是正罚标量。上述问题是无约束的。因此,可以通过交替最小化方法对变量E(v)、Z(v)和Gm进行最小化,然后相应地更新拉格朗日乘子Yv和αm。幸运的是,每个子问题都有一个简单的封闭式解,因此可以有效地计算。本文采用了具有交替方向策略的不精确ALM算法[26],并在算法1中进行了概述。该算法的收敛特性可以与[26]中的类似证明。对于每次迭代,我们更新每个变量如下:
1. Z(v)-subproblem:
为了更新子空间表示 Z(v),我们解决以下子问题:

其中Ωv(·)表示选择元素并将它们重塑为对应于第v个视图的矩阵的操作。 Z(v) 的闭式解由下式获得:
 具体来说,M 路张量有 M 种展开方式。对于我们模型中的所有三种展开模式,算子 Ωv(·) 仅选择对应于第 v 个视图的 N × N 个元素,并将其重塑为对应于Z(v)的 N × N 维矩阵 Am(v) 和 Bm(v) 。
具体来说,M 路张量有 M 种展开方式。对于我们模型中的所有三种展开模式,算子 Ωv(·) 仅选择对应于第 v 个视图的 N × N 个元素,并将其重塑为对应于Z(v)的 N × N 维矩阵 Am(v) 和 Bm(v) 。
2. z-subproblem
用更新后的 Z(v),我们通过直接替换相应元素来更新 z:

由于Yv和E(v)在当前迭代中独立于其他视图,即算法1的内循环,因此更新z在多个视图之间也是独立的。当获得多个视图的所有 Z(v) 时,我们可以更新 z 一次。
3. E-subproblem
重建误差矩阵 E 通过以下方式优化:
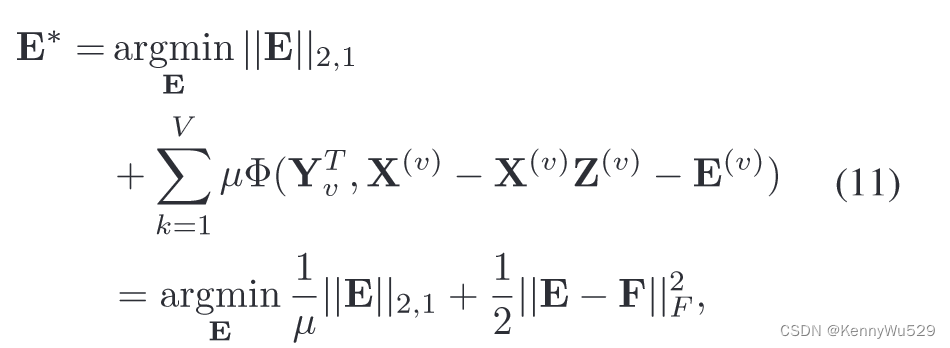
其中 F 是通过将矩阵 X(v) − X(v)Z(v) + Y(v) 沿列垂直连接在一起而形成的。这个子问题可以通过[28]中的引理3.2有效地解决。
4. Yv-subproblem
乘数 Yv 更新为:
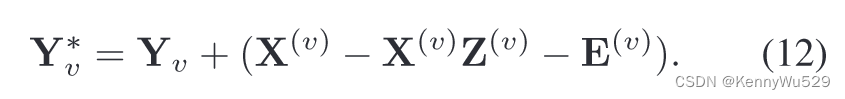
直观上,乘数根据违反等式约束的情况按比例更新。
5. Gm-subproblem
Gm更新通过:

其中 Ωm(Pmz + αm) 将向量 Pmz + αm 重塑为对应于第 m 个模式展开的矩阵。 βm = γm/μ 表示谱软阈值运算 proxtr βm (L)=U max(S − βm, 0)VT 的阈值,其中 L = USVT 是矩阵 L 的奇异值分解 (SVD),并且按元素进行最大操作。直观上,解根据子空间表示张量 Z 被截断。
6. gm-subproblem:
与更新 z 类似,我们通过直接替换相应元素来更新 gm:

7. αm-subproblem
与更新 Yv 类似,变量 αm 通过以下方式更新:

此估计的准确性每一步都会提高。 ALM 方法的主要优点是,与惩罚方法不同,它不需要采用 μ→∞ 来解决原始约束问题。相反,由于拉格朗日乘子项的存在,我们的算法收敛得很快,因为 μ 可以保持小得多。我们只为方程式(6)中的问题提供一般的优化解决方案。 事实上,任何优化算法都可以用来进一步改进我们的优化方案。具体来说,LADMPSAP [27] 是 AL-ADM 的更有效替代品,更适合大规模问题。此外,还有一些用于近似矩阵求逆计算的快速方法 [33, 34] 和一些用于奇异值阈值(SVT)更新 Gm 的方法 [31, 19],这些方法也可以用于我们的问题。

算法1:LT-MSC算法
输入:多种类型的特征矩阵X(1),…,X(V),参数γm’s和聚类数K
初始化:……
while 未收敛 do
for 每个V视图 do
根据方程(9).(11).(12)更新Z(v),E(v),Yv
end
根据方程(10)更新z
for 每个M模式 do
根据方程(13).(14).(15)更新Gm,gm和αm
end
更新μ通过μ = min(ρμ;max μ);
检查收敛条件:
||X(v) -X(v)Z(v) - E(v)||∞ <ε 且 ||Pmz - gm||∞ <ε
end
将每个视图的所有子空间表示组合为S = 1/V ΣVv=1|Z(v)|+|Z(v)T|
应用亲和矩阵S的谱聚类
输出:聚类结果C
“4. Experiments” 4. 实验
我们实验中使用的数据集在最近的人脸和图像聚类工作中被广泛使用[15,28,21]。图 2 是这些数据集的示例图像。

具体来说,我们使用四个基准数据集进行实验:
•Yale 1. 耶鲁人脸数据集包含15个人的165张灰度图像。每个主题有 11 张图像,每个不同的面部表情或配置都有一张图像。
•Extended YaleB 2. 扩展的YaleB 数据集由38 个个体和每个个体在不同照明下的大约64 个近正面图像组成。与其他工作[28]类似,我们使用前 10 个类别的图像,包括 640 张正面图像。
•ORL 3. ORL 人脸数据集中有 40 个不同主体的 10 个不同图像。他们在不同时间拍摄图像,改变了一些拍摄对象的灯光、面部表情和面部细节。
•COIL-20 4. 哥伦比亚物体图像库(COIL-20) 数据集包含20 个物体类别的1440 张图像。每个类别包含 72 张图像。所有图像均标准化为 32 × 32 像素阵列,每个像素有 256 个灰度级。
1http://cvc.yale.edu/projects/yalefaces/yalefaces.html
2http://cvc.yale.edu/projects/yalefacesB/yalefacesB.html 3http://www.uk.research.att.com/facedatabase.html 4http://www.cs.columbia.edu/CAVE/software/softlib/
对于所有数据集,我们提取三种类型的特征:强度、LBP [32] 和 Gabor [24]。采样密度为8,分块数为7×8,提取标准LBP特征。 Gabor 小波在四个方向θ = {0o, 45o, 90o, 135o}上以一个尺度 λ = 4 提取。因此,LBP和Gabor的维数分别为3304和6750。
大多数现有的聚类方法在获得配备 k 均值的亲和力矩阵后执行标准谱聚类算法。因此,我们通过运行这些方法 30 次并报告平均性能和标准推导来将我们的方法与 10 种方法进行比较。具体来说,比较的方法包括3种单视图和7种多视图方法:
• SPC best。该方法采用标准谱聚类算法[30]中信息最丰富的视图。
•LRRbest[28]。 LRR 方法使用低秩约束和性能最佳的单视图特征。
•RTC [3]。该方法利用张量来表示图像,并且对异常值具有鲁棒性。
•FeatConcatePCA。该方法连接所有视图并使用PCA将特征维度减少到300。
•PCA+LRR。该方法连接所有视图并使用PCA将特征维度减少到300,并应用LRR。
•Co-Reg SPC [23]。该方法共同规范聚类假设,以强制相应的数据点具有相同的聚类成员资格。
•Co-Training SPC [22]。该方法使用谱聚类框架内的协同训练方式。
•Min-Disagreement[14]。 “最小化分歧”的思想是基于二部图实现的。
•RMSC [39]。该方法恢复用于聚类的共享低秩转移概率矩阵。
•ConvexReg SPC[10]。该方法学习所有视图的通用表示。
六个评估指标用于评估性能:归一化互信息(NMI)、准确度(ACC)、调整兰德指数(AR)、F-score、精度和召回率,这些指标广泛用于聚类评估[9, 25]。对于所有这些指标,值越高表示聚类质量越好。每个指标都会惩罚或支持聚类中的不同属性,因此我们报告这些不同指标的结果以进行全面评估。这些指标已广泛用于评估集群性能。例如,比较的方法 Co-Train SPC [22] 和 LRR [28] 也使用相同的指标进行评估。具体来说,Co-Train SPC 使用 Fscore、Precision、Recall、NMI、AR 和 LRR 使用准确性 (ACC) 来评估聚类任务。
如果没有另外说明,内积核用于计算所有实验中的图相似度。在所有四个数据集上,对于我们方法的参数,我们只需将 M 个参数设置为相等的值,即 γ1 = .. = γM = γ,并相应地调整参数 γ。我们运行每个任务 30 次并报告平均性能和标准差。对于所有比较的方法,我们都将参数调整为最佳。
我们在表 1-4 中报告了四个基准数据集的详细聚类结果。在耶鲁大学,我们的方法优于所有基准。最具竞争力的多视图聚类方法 RMSC 已经取得了相对有希望的结果,但是,考虑到最佳特征,LRR 的性能甚至更好。我们的方法在 NMI、ACC、AR、F-score、Precision 和 Recall 方面分别比 LRR 显着提高了 5.6%、3.6%、5.5%、5.1%、4.0% 和 6.2%。此外,根据结果,直接将特征与 PCA 连接起来并不是一种有前途的方式,因为它并不总是比最好的单一视图表现得更好。我们的方法还优于最近发布的两种方法 [39, 10],并且在 ORL 和 COIL-20 上的性能(如表 3-4 所示)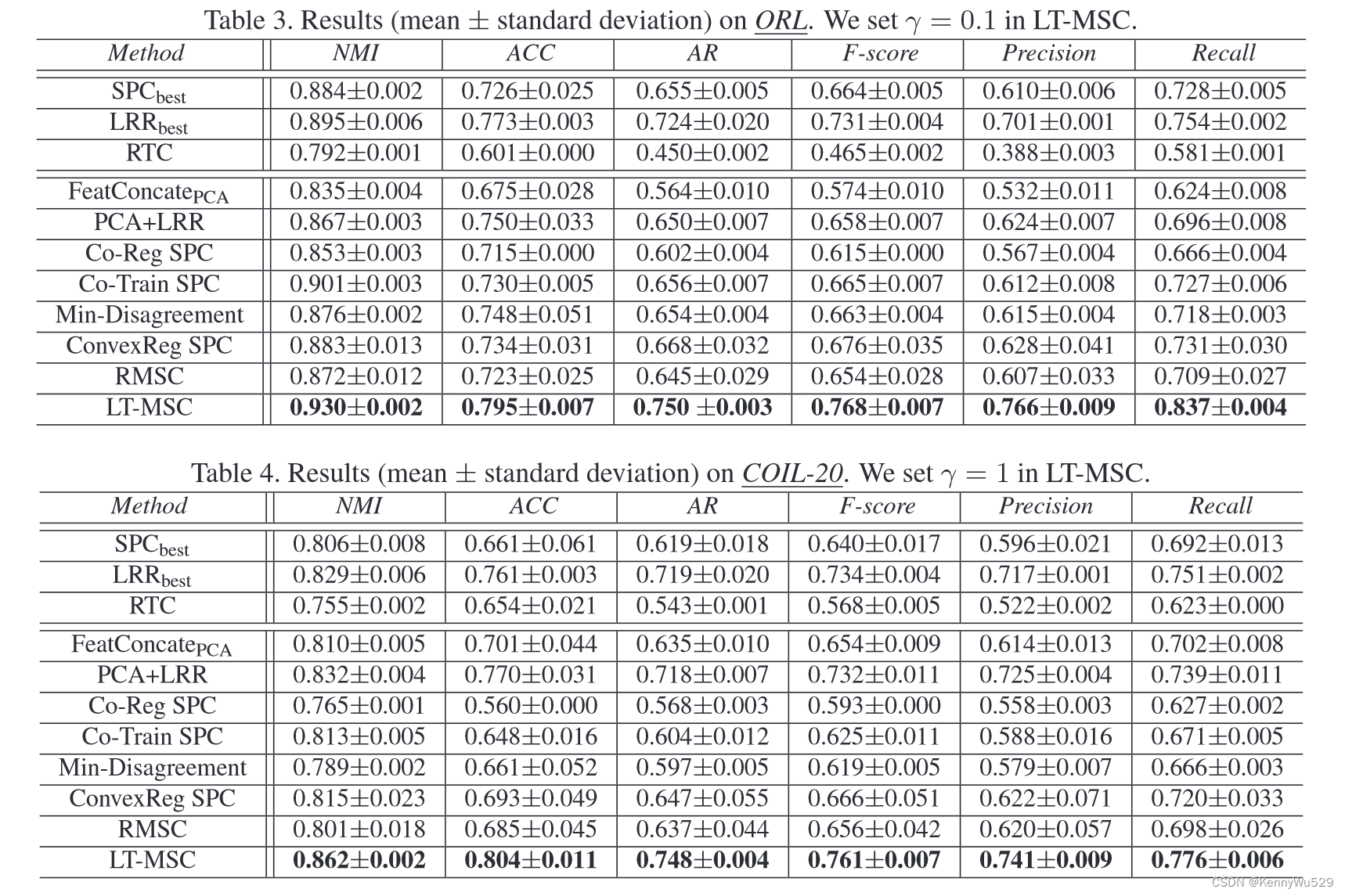 进一步证明了我们方法的有效性。
进一步证明了我们方法的有效性。
请注意,除了扩展 YaleB 上基于自我表示的方法(例如 LRR)之外,大多数比较的低性能都相对较低。主要原因是光照变化较大。以强度特征为例,子空间聚类方法由于具有自表示的优点而具有鲁棒性,而传统的基于距离的方法则急剧退化。如表 2 所示,LRR 在基线中表现最佳(例如,Min-Disagreement、Co-Reg SPC 和 Co-Training SPC)。然而,由于高阶低阶张量约束,我们的方法进一步显着优于 PCA+LRR。我们还注意到,LT-SMC 在扩展 YaleB 上相对于 LRR 的改进并不像在其他三个数据集上那么显着。主要原因是LBP和Gabor特征明显比最佳特征强度差,影响了LT-MSC的性能,如图4所示。

图4为不同单视图LRR的比较功能以及我们的具有多视图功能的 LT-SMC。鉴于最佳的单视图功能,LRR 实现了有希望的性能。然而,如图4所示,不同特征的LRR在不同数据集上的性能差异很大。例如,LBP 在 ORL 和 COIL-20 上表现最好,而在 Extended YaleB 上性能显着下降。因此,为不同的数据集选择相同的特征是不合理的。相比之下,LT-MSC直接利用所有类型的特征并取得了有竞争力的结果,而其他多视图聚类方法的性能却下降了。

图3比较了LT-MSC和LRR的naive方式之间的亲和力矩阵,LRR独立构建不同视图的亲和力矩阵,然后将它们相加。我们根据预期的聚类绘制这些亲和力矩阵。 LT-MSC对应的矩阵更清楚地揭示了底层的聚类结构,这进一步验证了探索不同视图之间高阶相关性的优势。
参数调整示例如图 5 所示。

请注意,扩展 YaleB 上的 γ 值明显大于 Yale 上的值,以获得良好的性能。这主要是因为扩展YaleB数据集对于光照的大变化更具挑战性,因此更加强的正则化对于减轻光照的影响至关重要。例如,在没有正则化的情况下(γ=0),Extended YaleB 上的性能相对较低,而 Yale 则不然。
“5. Conclusion” 5. 结论
在本文中,我们展示了如何通过联合利用不同视图的互补信息来发现数据的底层结构。为此,利用张量来探索高阶相关性。我们在统一的优化框架中制定了问题,并提出了一种有效的算法来寻找最优解。与最先进的方法相比,实验结果证明了所提出的方法在四个基准数据集上的明显优势。此外,该方法对于噪声视图相对稳健,保证了聚类结果的高质量。将来,我们将专注于将低秩张量分解纳入我们的方法中。
总结
1. Z(v)-subproblem:
为了更新子空间表示 Z(v),我们解决以下子问题:
其中Ωv(·)表示选择元素并将它们重塑为对应于第v个视图的矩阵的操作。 Z(v) 的闭式解由下式获得:
2. z-subproblem
用更新后的 Z(v),我们通过直接替换相应元素来更新 z:
由于Yv和E(v)在当前迭代中独立于其他视图,即算法1的内循环,因此更新z在多个视图之间也是独立的。当获得多个视图的所有 Z(v) 时,我们可以更新 z 一次。
3. E-subproblem
重建误差矩阵 E 通过以下方式优化:
其中 F 是通过将矩阵 X(v) − X(v)Z(v) + Y(v) 沿列垂直连接在一起而形成的。这个子问题可以通过[28]中的引理3.2有效地解决。
4. Yv-subproblem
乘数 Yv 更新为:
直观上,乘数根据违反等式约束的情况按比例更新。
5. Gm-subproblem
Gm更新通过:
其中 Ωm(Pmz + αm) 将向量 Pmz + αm 重塑为对应于第 m 个模式展开的矩阵。 βm = γm/μ 表示谱软阈值运算 proxtr βm (L)=U max(S − βm, 0)VT 的阈值,其中 L = USVT 是矩阵 L 的奇异值分解 (SVD),并且按元素进行最大操作。直观上,解根据子空间表示张量 Z 被截断。
6. gm-subproblem:
与更新 z 类似,我们通过直接替换相应元素来更新 gm:
7. αm-subproblem
与更新 Yv 类似,变量 αm 通过以下方式更新:
















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









