






线性回归的基本要素
模型
y = w ⋅ x + b \mathrm{y} = w \cdot \mathrm{x} + b y=w⋅x+b
数据集
我们在收集到的数据中寻找合适的模型参数来使模型的预测价格与真实价格的误差最小。被训练的数据的集合称为训练数据集(training data set)或训练集(training set),每一条数据的主体作为一个样本(sample),被预测值称作标签(label),用来预测标签的因素叫作特征(feature)。特征用来表征样本的特点。
损失函数
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。 它在评估索引为 i i i 的样本误差的表达式为
l ( i ) ( w , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 , l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2, l(i)(w,b)=21(y^(i)−y(i))2,
L ( w , b ) = 1 n ∑ i = 1 n l ( i ) ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w ⊤ x ( i ) + b − y ( i ) ) 2 . L(\mathbf{w}, b) =\frac{1}{n}\sum_{i=1}^n l^{(i)}(\mathbf{w}, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2. L(w,b)=n1i=1∑nl(i)(w,b)=n1i=1∑n21(w⊤x(i)+b−y(i))2.
优化函数 - 随机梯度下降
鉴于大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值,在这种求数值解的优化算法中,通常使用小批量随机梯度下降(mini-batch stochastic gradient descent)。
算法
先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch) B \mathcal{B} B,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
( w , b ) ← ( w , b ) − η ∣ B ∣ ∑ i ∈ B ∂ ( w , b ) l ( i ) ( w , b ) (\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{(\mathbf{w},b)} l^{(i)}(\mathbf{w},b) (w,b)←(w,b)−∣B∣ηi∈B∑∂(w,b)l(i)(w,b)
学习率:
η
\eta
η代表在每次优化中,能够学习的步长的大小
批量大小:
B
\mathcal{B}
B是小批量计算中的批量大小batch size
总结一下,优化函数的有以下两个步骤:
- 初始化模型参数,一般使用随机初始化;
- 在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数。
线性回归模型的实现
以房屋为样本,价格为标签,面积和房龄为特征
p r i c e = w a r e a ⋅ a r e a + w a g e ⋅ a g e + b \mathrm{price} = w_{\mathrm{area}} \cdot \mathrm{area} + w_{\mathrm{age}} \cdot \mathrm{age} + b price=warea⋅area+wage⋅age+b
导入包和模块
# import packages and modules
%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
生成数据集
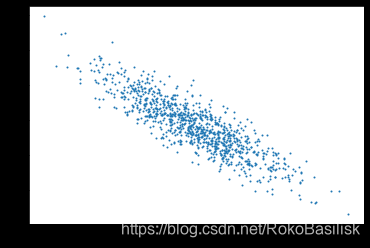
使用线性模型来生成数据集,生成一个 1000 个样本的数据集
# set input feature number
num_inputs = 2
# set example number
num_examples = 1000
# set true weight and bias in order to generate corresponded label
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32) #1000*2 vector
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32) #偏差通过正态分布随机生成
通过图像观察生成的数据合适程度
读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # random read 10 samples
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # the last time may be not enough for a whole batch
yield features.index_select(0, j), labels.index_select(0, j)
batch_size = 10 # read 10 samples
for X, y in data_iter(batch_size, features, labels): # input features and labels
print(X, '\n', y)
break
初始化模型参数
# init parameter
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
定义模型
# define model
def linreg(X, w, b):
return torch.mm(X, w) + b
定义损失函数
均方误差损失函数
l ( i ) ( w , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 , l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2, l(i)(w,b)=21(y^(i)−y(i))2,
# define loss function
def squared_loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
定义优化函数
小批量随机梯度下降优化
# define optimization function
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # ues .data to operate param without gradient track
训练
# super parameters init
lr = 0.03 #学习率
num_epochs = 5 #训练周期
net = linreg #单层网络
loss = squared_loss #均方误差损失函数
# training
for epoch in range(num_epochs): # training repeats num_epochs times
# in each epoch, all the samples in dataset will be used once
# X is the feature and y is the label of a batch sample
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum()
# calculate the gradient of batch sample loss
l.backward()
# using small batch random gradient descent to iter model parameters
sgd([w, b], lr, batch_size)
# reset parameter gradient
w.grad.data.zero_()#参数梯度清零,为防止叠加
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
检验训练结果
# output result of trainning
w, true_w, b, true_b
使用 torch 简化代码
未单独重写的步骤默认与上一致
读取数据集
import torch.utils.data as Data
batch_size = 10
# combine featues and labels of dataset
dataset = Data.TensorDataset(features, labels)
# put dataset into DataLoader
data_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # whether shuffle the data or not
num_workers=2, # read data in multithreading
)
for X, y in data_iter:
print(X, '\n', y)
break
定义模型
class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__() # call father function to init
self.linear = nn.Linear(n_feature, 1) # function prototype: `torch.nn.Linear(in_features, out_features, bias=True)`
def forward(self, x):
y = self.linear(x)
return y
net = LinearNet(num_inputs)
print(net) #单层线性网络
初始化模型参数
from torch.nn import init
init.normal_(net[0].weight, mean=0.0, std=0.01)
init.constant_(net[0].bias, val=0.0) # or you can use `net[0].bias.data.fill_(0)` to modify it directly
for param in net.parameters():
print(param)
定义损失函数
loss = nn.MSELoss() # nn built-in squared loss function
# function prototype: `torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')`
定义优化函数
import torch.optim as optim
#随机梯度下降
optimizer = optim.SGD(net.parameters(), lr=0.03) # built-in random gradient descent function
print(optimizer) # function prototype: `torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)`
训练
import torch.optim as optim
#随机梯度下降
optimizer = optim.SGD(net.parameters(), lr=0.03) # built-in random gradient descent function
print(optimizer) # function prototype: `torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)`
检验训练结果
# result comparision
dense = net[0]
print(true_w, dense.weight.data)
print(true_b, dense.bias.data)

















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









