







mnist的Bayes分类是基于python 3.7.0、numpy 1.16.2版本实现的。
总结:贝叶斯分类器的主要思想:P(y|X)=P(y)*P(X|y)/P(Y)
因为对所有类别来说,P(X)相同,因此求解P(y|X)的主要在于求解 先验概率 P(y)和 类条件概率 P(X|y),原问题简化为:当类别y取不同值时,求P(y)*P(X|y)的最大值,此时类别y即为 X 的类别。
原问题等价为:当类别y取不同值,max P(y)*P(X|y)
在训练模型的过程中,主要训练计算出先验概率P(y),以及与条件概率相关的中间量。对于每一个未知分类的测试样本,需要计算它属于每个类别时的类条件概率P(X|y)及后验概率等价公式P(y)*P(X|y),选取不同类别y下P(y)*P(X|y)的最大值来确定X的类别。
一、样本中的属性相互独立
step1. 基本思想
基于属性条件独立性假设,贝叶斯分类器的主要思想可重写为(d为单个样本的属性维度):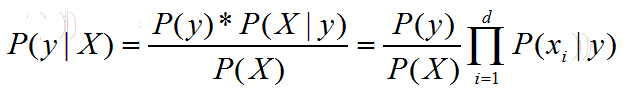
因此,原问题的等价问题为:
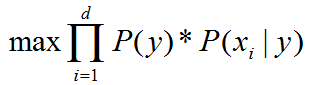
step2. 数据处理
为防止P(y)*P(X|y)的值下溢,对原问题取对数,即:
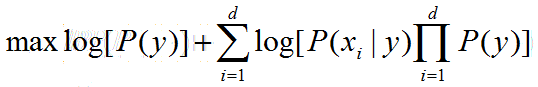
注意:若某属性值在训练集中没有与某个类同时出现过,则直接P(y)或P(X|y)可能为0,这样计算出P(y)*P(X|y)的值为0,没有可比性,且不便于求对数,因此需要对概率值进行“平滑”处理,常用拉普拉斯修正。
先验概率修正:令Dy表示训练集D中第y类样本组合的集合,N表示训练集D中可能的类别数
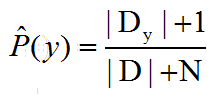
即每个类别的样本个数都加 1。
类条件概率:另Dy,xi表示Dc中在第 i 个属性上取值为xi的样本组成的集合,Ni表示第 i 个属性可能的取值数
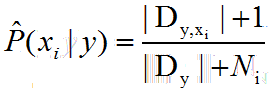
即该类别中第 i 个属性都增加一个样本。
step3. 程序实现
NO.1 数据预处理
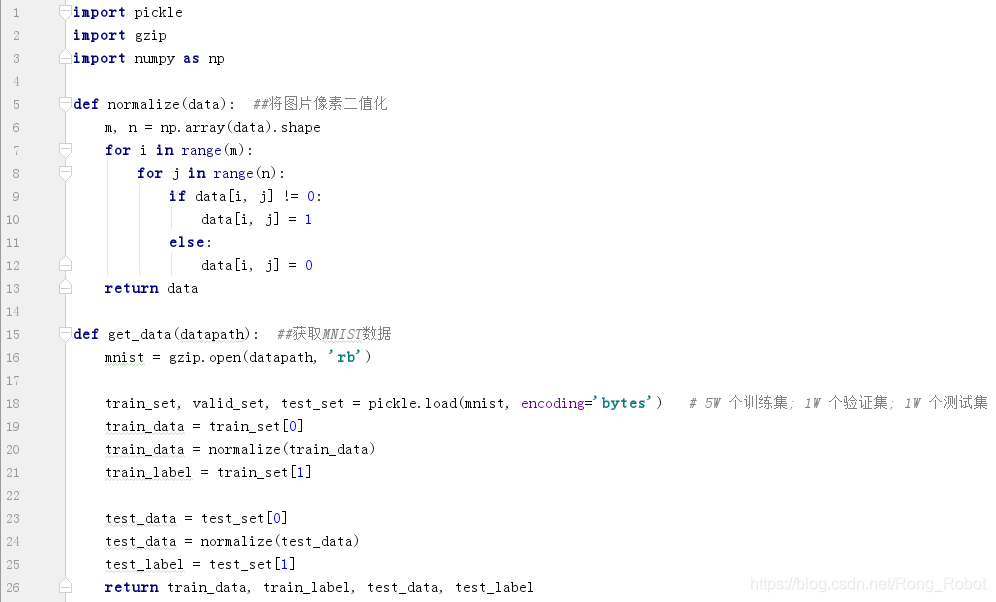
NO.2 训练模型

行41-42:计算先验概率和类条件概率
NO.3 测试样本

NO.4 函数调用

NO.5 测试结果
分类器的测试精度为:84.16%
二、样本中的属性服从高斯分布
step1. 基本思想
朴素Bayes的基本思想大致相同,最主要的工作就是求先验概率和后验概率,如下所示,属性服从高斯分布下的朴素Bayes分类器的目标函数。
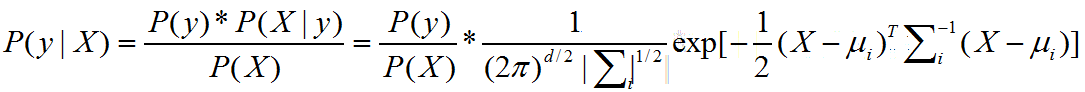
同样,此问题等价为(取对数):
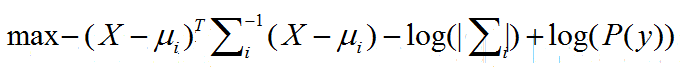
根据目标函数,需要明确在训练集中,需要求解的量为先验概率、各类别中各属性的均值矩阵及各类别中属性的协方差矩阵。
在测试一个未知类别的样本时,同样要先计算该样本在各类别条件下的类条件概率,进而得到后验概率,即上述等价问题。
step.2 程序实现
NO.1 读取数据

NO.2 训练模型

行20-23:对训练数据进行降维操作,原有784个属性,现选取340个属性进行训练
行29:计算每个类的属性均值矩阵
行30:计算每个类中属性的协方差矩阵(340*340)
行31:计算先验概率
NO.3 测试样本

行44:为了防止协方差矩阵的行列式为0,产生一个数值较小、与协方差类型相同的对角阵,加到训练得到的协方差矩阵上,得到新的协方差矩阵,方便之后求矩阵的逆,以及取协方差行列式的对数
行48:由于协方差矩阵所加的矩阵值过小,可能不能求逆,因此求协方差矩阵的伪逆
行49:求协方差矩阵的行列式
行55:目标函数,即等价的后验概率
NO.4 函数调用
NO.5 测试结果
分类器的测试精度为:95.97%














 3314
3314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









