







1、Flume安装(apache-flume-1.7.0-bin.tar.gz)
解压:tar -xzf /home/spark/桌面/apache-flume-1.7.0-bin.tar.gz
移动:sudo mv apache-flume-1.7.0-bin /home/spark/app/flume
配置环境变量:
①vi ~/.bash_profile
export FLUME_HOME=/home/spark/app/flume
export PATH=$FLUME_HOME/bin:$PATH
②source ~/.bash_profile
③echo $FLUME_HOME
2、Flume架构及核心组件
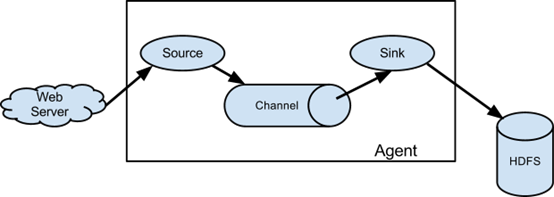
Flume提供一个高可用的、高可靠的、分布式的海量日志采集、集合和传输的系统。Flume基于流式架构,灵活简单。
①Source——收集(Avro、Thrift、Exec、Spooling Directory、Kafka、NetCat)
②Channel——聚集(Memory、File、Kafka)
③Sink——输出(HDFS、Hive、Logger、Avro、HBase、ElasticSearchSink、Kafka)
注:①Source将事件写到一个或多个Channel;②Channel作为事件从Source到Sink传递的保留区;③Sink只从一个Channel接收事件;④代理可能有多个Source、Channel与Sink。
Memory Channel是内存中的队列。适用于不需要关心数据丢失的情景,程序死亡、机器宕机或重启都会导致数据丢失。File Channel将所有事件写到磁盘,因此在程序关闭或机器宕机时不会丢失数据。
3、Flume配置(路径:/flume/conf)
①cp flume-env.sh.template flume-env.sh
②sudo vi flume-env.sh
export JAVA_HOME = /home/spark/app/jdk
4、使用Flume
使用Flume的关键是写配置文件:①配置Source;②配置Channel;③配置Sink;④把以上三个组件串起来。
(1)Source(NetCat) --> Channel(Memory) --> Sink(Logger)(路径:/flume/conf)
①touch NetCat_Memory_Log.conf
②sudo vi NetCat_Memory_Log.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = Master
a1.sources.r1.port = 6666
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1#Source将事件写到一个或多个Channel
a1.sinks.k1.channel = c1 #Sink只从一个Channel接收事件
③启动agent
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/NetCat_Memory_Log.conf -Dflume.root.logger=INFO,console
验证:
打开另一终端界面,远程连接Master:6666:telnet Master 6666,连接成功,则显示” Connected to Master”。在该终端上输入字段“Hello Spark”、“Hello Hadoop”:
Hello Spark
OK
Hello Hadoop
OK
则在Master:6666端口上接收到的内容为:
2019-10-12 21:01:49,673 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 48 65 6C 6C 6F 20 53 70 61 72 6B 0D Hello Spark. }
2019-10-12 21:01:55,651 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 48 65 6C 6C 6F 20 48 61 64 6F 6F 70 0D Hello Hadoop. }
Event: { headers:{} body: 48 65 6C 6C 6F 20 53 70 61 72 6B 0D Hello Spark. }
Flume传输的基本数据负载称为事件(Event)。事件由0个或多个头与体(字节数组)组成。即Event = 可选的header + byte array
(2)Source(Exec) --> Channel(Memory) --> Sink(Logger)(路径:/flume/conf)
①touch Exec_Memory_Log.conf
②sudo vi Exec_Memory_Log.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/spark/PycharmProjects
/data_file/file1.txt #监控文件
a1.sources.r1.shell = /bin/sh -c
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1#Source将事件写到一个或多个Channel
a1.sinks.k1.channel = c1 #Sink只从一个Channel接收事件
③启动agent(flume/bin)
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/Exec_Memory_Log.conf -Dflume.root.logger=INFO,console
验证:
打开另一终端界面,在file1.txt(路径:/home/spark/PycharmProjects/data_file/)中添加内容:
echo 5,1 >> file1.txt
echo 5,4 >> file1.txt
则在原终端界面显示:
2019-10-12 21:32:39,169 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 35 2C 31 5,1 }
2019-10-12 21:33:09,990 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 35 2C 34 5,4 }
5、通道(Channel)
在Flume中,通道指的是位于Source与Sink之间的构件。通道类型一般分为内存(非持久化)通道和本地文件系统(持久化)通道。
持久化通道通常会在Sink接收到事件前将所有变化写到磁盘,比非持久化的内存通道慢,但可以在出现系统事件或Flume代理重启时进行恢复。内存通道要更快,在出现失败时会导致数据丢失,与拥有大量磁盘空间的文件通道相比,内存通道的存储能力要低很多。
6、拦截器(Timestamp,Host,Static,Regex Filtering, Regex Extractor)
拦截器指的是数据流中的一个点,可在此检查和修改Flume事件,拦截器的功能就是即时检测与转换事件。(可在源(Source)创建事件之后或接收器(Sink)发送事件之前插入0个或多个拦截器)
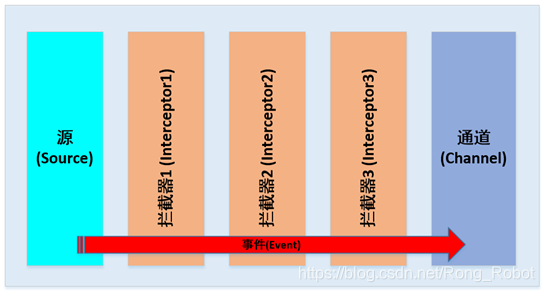
拦截器作为Flume事件传递,并且以Flume事件的形式返回。
向源添加拦截器:
agent.sources.s1.interceptors = i1 i2 i3
拦截器会按照列出的顺序运行,即i2会接收到来自i1的输出,i3会接收到来自i2的输出,通道选择器会接收来自i3的输出。
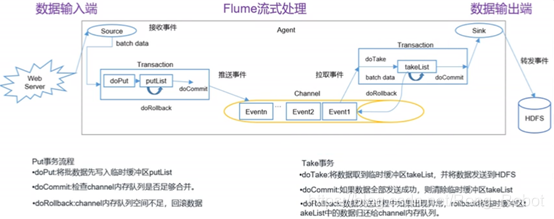
7、Flume事务
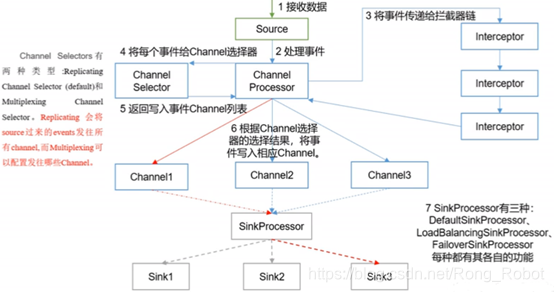
8、Agent内部原理














 1618
1618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









