










一、RTO/RPO
保障系统能在足够长的时间内提供指定程度的服务,衡量数据库系统的可用性用RTO和RPO;
(1)RTO(Recovery Time Obejective,恢复时间指标):故障恢复过程中所需的时间花费。故障发生后,从IT系统停止服务开始,到IT服务系统恢复为止,此两点之间的时间段成为RTO,比如:故障发生后系统服务在12小时内便可恢复,那么RTO值就是12小时,对数据库系统而言,RTO通常需要控制在秒到分钟级别,该项指标是描述系统可用的指标之一,不能完全代表可用性。
(2)RPO(Recovery Point Objective,恢复时间点目标):数据恢复后对应的时间点。即数据可恢复到哪个时间点上,该时间点之后的数据都会丢失,该值越小越好。如果数据库采用主备强同步或者多基于共识协议的副本技术,后者数据库依赖分布式文件系统,则RPO的值可以确保为0,即数据不丢失,该项指标更多的是在描述系统的可靠性,唯有可靠才更可用。
二、SLA
SLA是在传统领域,在商业上定义系统的高可用性时采用SLA(Service Level Agreement,服务等级协议)。SLA是在一定开销下为保障服务的性能和可用性,服务提供商与用户共同定义的一种双方认可的协定,该协议在网络服务供应商领域被广泛使用,会约定最小带宽、同时服务客户数、最长故障时间等一系列指标。在软件领域,最广泛使用的指标是平均服务时间,例如,我们经常听到的服务可用性可达到几个9,就是服务的可用性数字化衡量指标,99.99%表示一年里服务最多只能有25.6分钟不可用,99.999%表示一年里最多只有有5.26分钟不可用。
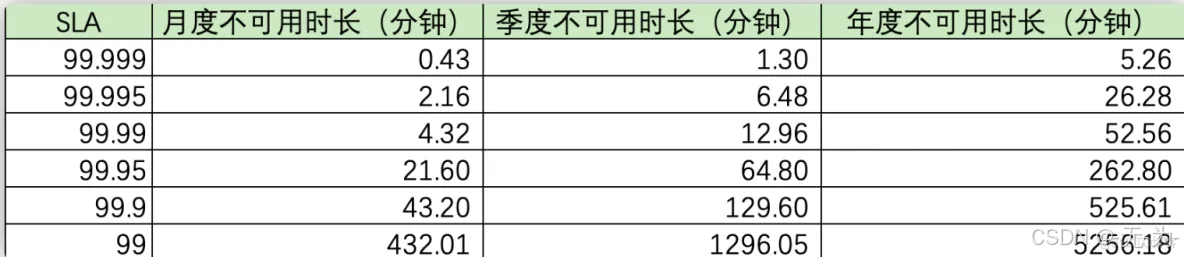
SLA=使用正常运行时间/(正常运行时间+故障时间)
三、MTBF/MTTF/MTTR
衡量计算机的高可用类似的指标,包括:MTBF、MTTR、MTTF
MTBF:(Mean Time Between Failure,平均无故障时间):对于可修复系统,系统的平均寿命是指平均情况下两次相邻失效(故障)之间的工作时间,又称系统平均时效间隔,该值越大表示可用性越好。就是从新的产品在规定的工作环境条件下开始工作到出现第一个故障的时间的平均值。MTBF越长表示可靠性越高正确工作能力越强。
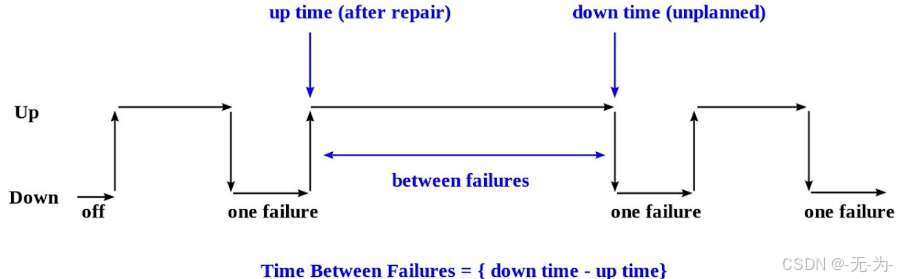
从上图可以看出,平均故障间隔时间就是多个故障间隔时间的平均值,而一次故障间隔时间则上图down time - up time的差值。
MTTF (Mean Time To Failure,平均失效时间):对于不可修复系统,系统的平均寿命指系统发生失效前的平均工作时间,又称系统在失效前的平均时间。系统平均能够正常运行多长时间,才发生一次故障。系统的可靠性越高,平均无故障时间越长。 可靠性是最初是确定一个系统在一个特定的运行时间内有效运行的概率的一个标准。可靠性的衡量需要系统在某段时间内保持正常的运行。
MTTR (Mean Time To Repair,平均修复时间):对于可修复系统,该指标表示故障的平均修复时间,故障出现到修复的时间,MTTR越小表示易恢复性越好。
目前,使用最为广泛的一个衡量可靠性的参数是,MTTF(mean time to failure,平均失效前时间),定义为随机变量、出错时间等的"期望值"。但是,MTTF经常被错误地理解为,"能保证的最短的生命周期"。MTTF的长短,通常与使用周期中的产品有关,其中不包括老化失效。

四、可靠性和可用性
可用性是产品在任意随机时刻需要和开始执行任务时,处于可工作或可使用状态的程度,其概率就是可用度。
可靠性是产品在规定的时间内和规定的条件下完成规定功能的能力,其概率就是可靠度。
可用性和可靠性是衡量系统性能的两个重要指标,它们分别衡量系统在不同条件下的运行状态和持续运行的能力。
-
可靠性主要衡量系统在规定条件下和规定时间内完成预定功能的能力。它通常用平均无故障时间(MTBF)来衡量,即相邻两次故障之间的平均工作时间。可靠性关注的是系统稳定运行的能力,是衡量系统质量的重要指标之一。
-
可用性则侧重于系统在面对软硬件故障时,保持用户程序继续运行的能力。它通过平均故障间隔时间(MTBF)和平均修复时间(MTTR)来综合衡量,其中MTBF表示系统正常运行的时间,而MTTR表示系统从故障状态恢复到正常状态所需的时间。可用性关注的是系统应对故障的能力,确保系统的高可用性和用户体验。
综上所述,可靠性和可用性是评价系统性能不可或缺的两个方面,它们共同决定了系统的整体质量和用户满意度。通过合理的设计和维护,可以提高系统的可靠性和可用性,从而提升用户体验和系统稳定性。
可用性
可用性是可靠性最简单的组成部分。此度量描述服务运行的时间百分比,这也被称为服务的“正常运行时间”。可用性可以通过连续查询服务并以预期的速度和准确性确认返回的响应来监控。
服务的可用性是用户感知可靠性的主要因素。考虑到这一点,设定一个100%正常运行时间的目标是很诱人的。但是SRE告诉我们失败是不可避免的;导致停机的事故总是发生在工程预期之外。可用性通常用“9”表示,表示正常运行时间的百分比可以达到多少位小数。一些主要的软件公司会吹嘘自己的“5个9”或者99.99%的正常运行时间,但永远不会有可确保的100%的正常运行时间。
此外,用户是可以容忍甚至无法注意到服务的某些领域出现宕机。致力于改善超出预期的可用性的开发资源并不会增加客户的满意度,把这些资源用在可维护性上会更好。
可靠性
可靠性可以定义为当用户访问服务时,服务按预期运行的可能性。这似乎与我们定义可用性的方式相同,但有关键的区别。可用性检查服务是否工作,用户是否正在访问它。如果用户在所有时间、所有功能上统一访问服务,可用性将决定可靠性。一般情况下,这不可能发生。
以两种情形为例:
服务A:
用户登录页面的可用性为97%
目录搜索的可用性为97%
站点设置页面的可用性为97%
服务B:
用户登录页面具有可用性为99%
目录搜索的可用性为98%
网站设置页面的可用性为90%
仅从可用性度量来看,服务A胜出。但是如果登录页面被100%的用户使用,目录搜索被90%的用户使用,而站点设置页面只有30%的用户使用,那么服务B就会被认为更可靠。可靠性需要考虑实际使用情况,将可用性指标转化为客户满意度的度量指标。
通过理解系统的可靠性,开发人员可以避免浪费时间来改进超出客户预期的可用性。服务级别指标将延迟和可用性等指标捆绑到更有效的度量中。然后将服务水平目标设定在顾客不满意的阈值。这种方法从客户的角度来看可靠性,因为对他们来说,服务的可靠性比它的可用性更重要。
可维护性也可以通过这种标准来评估。响应事件所花费的时间耗尽了服务正常运行时间的错误预算……SLI和SLO可以帮助分配开发工作,以改进可维护性和最影响客户满意度的事件响应过程。
可靠性不仅仅是度量的集合或代码库的质量。这是一个全局概念,包含了用户的观点、变化和增长的必然性以及开发代码的人员。这种整体方法是SRE的基础,是实践的集合,也是提高服务可靠性的文化课程。
五、网络可用性、可靠性分析
传输网络是网络通信的基础,为各种通信业务提供传输通道, 传输网络的质量对未来的业务发展有着深远的影响。如何衡量传输网络可用性、如何提高传输网络可用性等方面进行阐述。
一、网络可用性指标定义
平均故障间隔时间:MTBF( Mean Time Between Failures),即在规定的条件下和规 定的时间内,系统累计运行时间与故障次数之比。
平均修复时间:MTTR(Mean Time To Repair),即在规定的条件下和规定的时间内,产品在任一规定的维修级别上,修复性维修总时间与在该级别上被修复产品的故障总数之比。
可用度:A(Availability),指可维修产品在规定的条件与时间内,维持其规定功能的能力,它综合反映可靠性和维修性。计算方法:产品能工作时间与能工作时间、不能工作时间的和之比。如:A=MTBF/(MTBF+MTTR)。
年停机时间:DT(Downtime),在一年内,产品由于故障维修而处于不能工作的全部时间之和。停机时间跟可用度之间换算关系:年停机时间=(1-A)×8760×60(分钟)。
通常所指的产品可用性包括可靠性和可维修性两个方面。可靠性用MTBF来衡量,可维修性用MTTR来衡量,而可用性则用可用度A来衡量。
二、网络可用性的相关因素分析
评估和建设一个高可用性的网络是一个庞大的系统工程,需要对设备可靠性、网络介质的可靠性、网络拓扑结构、设备运行环境、管理和服务等多方面进行综合分析和改进。一般在确定网络模型之后,影响整个网络可用性的几个主要因素如图1所示。
网络可靠性影响因素大致可以分为:
(1) 传输介质因素:光纤、光纤连接器、电缆等;
(2) 设备因素:硬件板卡失效、软件失效等;
(3) 网络设计因素:网络的整体规划、网络解决方案等;
(4) 电网及运行环境因素:电网可用率、设备运行环境等;
(5) 备件、维护及服务等因素:备件策略、操作人员培训、网络维护、客户服务;
(6) 其他一些不可抗力因素:地震、战争、洪水等。
三、网络可用性的提高
通过前面的简单介绍可知,影响网络可用性的因素众多,所以实际分析时应从多个方面入手,抓住最重要的因素,在网络可用性和建设成本之间找到一个平衡点。
1. 提高传输介质的可靠性
对于一条端到端的电路,对可用性影响最大的是传输介质。传输介质包括光纤、光纤连接器、电缆、电缆连接器及其他传输线。
实际上,传输介质特别是光纤的可靠性,远远要比设备可靠性低。一般认为光纤失效率跟传输距离是成正比关系的。根据GR-418标准提供的光纤可靠性指标是400FITs/km,即相当于每285km平均每年失效一次。根据互联网上公布的国外某运营商的数据,2003年光纤失效率为422FITs/km,光纤的平均维修时间为13小时。可见光纤的失效率高、光纤维修时间长。传输介质中,除了光纤之外,光纤连接器也很容易失效,经常会由于连接器松动、灰尘、连接错误等造成光纤连接失效。
相比于光纤而言,电缆和电缆连接器比光纤指标还要差,其受到人为影响的可能性更大。电缆一般集中在传输网的业务落地侧,不过随着光口交换机、路由器的出现,传输电缆的用量在逐渐减少。一些咨询公司和运营商的统计数据表明,对于一个端到端的电路而言,光纤的失效往往在网络失效中占有非常大的比例,大部分都超过整个网络失效的50%,有的甚至在80%以上。所以提高网络可用性首先要考虑的是提高传输介质的基本可靠性。
下面是针对光纤等传输介质所提出的一些改进建议:
(1) 减少光纤和连接器的失效,控制采购质量;
(2) 减少光缆保护盲点,如采取接入层成环、入大楼管道双路由等保护措施;
(3) 控制由于人为因素造成的传输介质失效(比如挖断等人为破坏);
(4) 局内采取各种控制措施:室内光缆的有效保护、光缆/电缆的正确标识、提高插拔光纤/电缆的规范性、室内尾纤的合理布放等;
(5) 建立快速的维护响应队伍,减少光纤故障后的维修时间。
2. 提高设备基本可靠性
除了光纤之外,设备也是影响网络基本可靠性的主要因素。设备的硬件和软件都可能失效,对于不同的通信设备,软硬件失效比例是不同的。一般而言,传输设备硬件失效率要比软件失效率高一些,而路由器设备的软件失效率要比硬件失效率高。根据GR-418提供的数据,传输设备软硬件失效比例为1:3。
硬件失效与很多的因素相关,最主要的是器件的基本失效。器件失效率可以根据温度、静电影响、环境等参考相应标准(GJB299、TR-332)进行预计。除器件的基本失效之外,还有其他原因会间接影响到器件失效,如硬件的设计、制造、工艺、环境、EMC等。
软件的失效是由于软件设计过于复杂、对异常情况考虑不完善、软件的BUG等导致。一般是通过CMM流程的质量控制和对软件可靠性的度量、分析、测试来保证软件可靠性。软件失效除了可能导致板卡的功能失效之外,还可能导致系统或者整个网络的功能失效,并且软件失效后一般影响较大,故障难以定位。
因为上述一些因素的影响,设备制造商在生产设备的过程中需通过各种设计流程、质量保证流程、闭环等措施保证设备的可靠性。华为公司对于提高设备可靠性方面的主要保障措施主要表现在:通过完善的集成产品开发流程保证设备软硬件设计的可靠性;通过系统可靠性设计优化系统结构,充分考虑网络的解决方案;通过全面采购控制、设计规范等保证器件可靠性和应用的规范;提供闭环的问题处理、跟踪流程,保证问题及时解决和跟踪;通过FIT测试、老化试验、环境试验、HALT试验等措保障设备可靠性;设计中全面考虑故障检测、隔离、恢复设计,提高设备故障管理能力;通过CMM流程保证软件开发的规范,通过对软件的度量、分析和FIT测试保证软件可靠性;考虑设备支持计划性的在线升级、补丁、扩容等功能;对关键部件采用1+1保护提高设备可靠性,比如交叉板卡1+1,电源接入模块1+1等。所以,设备商的实际研发能力、完善的可靠性保障流程也应该是运营商在采购设备时考虑的重要因素。
四、优化网络拓扑结构
随着客户需求的变化、传送技术的发展以及市场竞争的加剧,传输网络将逐步从SDH向ASON演进,网络保护也将从1+1保护逐步向MESH组网保护发展。届时网络设计已经不再是将简单的几个设备连接在一起组成一个网络那么简单,而是需要根据实际的网络结构和现状,提供一个低成本、高可用性、高利用率的解决方案。
由于光纤介质的失效是整个网络中影响最大的,因此首先应该对光纤传输距离较长的网络进行网络保护,比如MSP、SNCP、MESH等。除了保护光纤失效外,还要考虑对于掉电可能性大的站点增加节点保护。对于可靠性要求高的网络可以考虑采用MESH组网保护。下面提供几种增强网络可用性的组网方法。
(1) 增强网络保护能力以减少光纤、节点失效的影响;
(2) 重要业务节点之间采用1+1MSP链保护;
(3) 通过采用小环加小环的组网方式代替大环组网,减少光纤失效影响;
(4) 减少传输路径长度和传输节点个数,用大容量设备取代背靠背转接。
总之,网络的设计需要针对网络的运行环境、网络的定位、不同的客户需求等进行综合分析,以便给出满足客户需求的解决方案。
五、提高电网与设备运行环境
环境因素的影响包括多个方面,最主要的是电网环境因素。这方面在国内尤为严重,有运营商的统计数据表明,在部分电源条件不好(如使用农村电力、机房无蓄电池)的本地网络,掉电事故占所有事故的50%以上,部分地方比例更高。而且电网的失效往往会导致整个设备掉电,甚至导致整个站点或者机房所有设备的失效。除了电网事故直接导致网络上节点的失效外,还有其他一些直接导致设备失效的原因如:火灾、地震、台风、洪水等不可抗拒的因素。
其他环境因素一般指环境温度、湿度、盐雾、粉尘等。这些因素会间接的逐步影响设备可靠性,比如缩短设备使用寿命、导致器件失效率增加、加快设备腐蚀等。
以下是针对环境因素所提供的改进方法:
(1) 通过对设备配备蓄电池、油机等备用电源,减少设备掉电导致的节点故障;
(2) 通过优化组网方式,如增加备份节点,相互备份的重要站点不要放于同一机房等;
(3) 对于重要的节点要提供空调环境;
(4) 通过环境改造,减少高温高湿、盐雾粉尘和腐蚀性气体对设备的影响。
六、提高备件、维护、服务水平
在建设一个网络的同时,必须配备相应的备件。备件方式和备件策略的好坏直接影响到最终板件失效后的维修时间。备件离故障点越近,故障的维修时间就越短,网络的可用性就会越高,但是如果备件的库存太多又会增加库存的成本。需根据实际情况确定备件更换率、周转时间、备件成本等因素,综合分析确定备件策略。
维护操作异常是人为造成设备失效的主要原因。维护操作的异常包括因操作流程的不规范导致直接发生事故,维护人员维护不及时导致事故以及割接和扩容导致业务中断等。
服务水平是体现设备商综合能力的重要因素,服务的好坏直接影响到一个网络的可靠运营。比如对设备的定期巡检、对用户需求的快速响应、对设备问题的快速定位和及时处理、对客户的定期培训和交流等都会间接的提高网络的可用性。
下面是针对备件、维护、服务等方面的改进措施。
(1) 优化维护体制,建立快速响应的维护队伍,减少业务中断时间。包括对设备的维修和传输介质的维修;
(2) 通过提高维护队伍的分布、技术水平,增加对维护人员的技术、流程培训,从而减少操作事故、减少故障定位时间;
(3) 制定完善的备件策略,减少备件响应时间;
(4) 采购设备时考虑设备制造商提供的服务水平;
(5) 增加计划性的维修,减少潜在故障的发生。


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











