










概叙
RDMA(Remote Direct Memory Access,远程直接数据存取)是一种允许网络中的计算机直接从内存中读写数据的技术,而无需本地系统的CPU参与。这种机制可以显著减少网络传输的延迟和提高数据吞吐量,同时降低了CPU的使用率,使得高性能计算、大规模数据处理和云计算等场景下的网络通信更加高效。
尽管RDMA技术是一种高效、低延迟的网络通信技术,特别适用于需要处理大量数据和高性能网络通信的场景。
然而,在应用RDMA技术时,也需要充分考虑其硬件依赖、安全性问题、编程复杂性和网络规模限制等因素。
前面整理了RDMA技术相关的文章,这里做一个汇总,便于查看和阅读。
RDMA相关术语
RDMA(Remote Direct Memory Access)相关的主要术语。
基础术语
-
RDMA: 远程直接内存访问
-
RoCE: RDMA over Converged Ethernet
-
iWARP: Internet Wide Area RDMA Protocol
-
InfiniBand: 一种高速网络互连技术
硬件相关
-
HCA: Host Channel Adapter (InfiniBand 中的网卡)
-
NIC: Network Interface Card
-
RNIC: RDMA Network Interface Card
-
QP: Queue Pair (发送队列和接收队列的配对) - 是整个通信处理的基本单元 - 由发送队列(SQ)和接收队列(RQ)组成 - 每个 QP 代表一个通信端点 - 负责管理单向或双向的数据传输
-
CQ: Completion Queue (完成队列) - 记录操作完成状态的队列 - 跟踪 SQ 和 RQ 的操作结果 - 通知应用程序操作是否成功 - 提供错误处理和性能监控机制
-
WQ: Work Queue (工作队列) - 更广义的工作队列概念 - 包含发送队列(SQ)和接收队列(RQ) - 存储待处理的工作请求
-
SQ: Send Queue (发送队列) - 发送数据的队列 - 存储待发送的工作请求(Work Request) - 处理 Read、Write、Send 等操作 - 按顺序处理发送请求
-
RQ: Receive Queue (接收队列) - 接收数据的队列 - 存储可用于接收消息的缓冲区 - 准备接收对端发送的数据 - 匹配和处理接收到的消息
典型 RDMA 工作流程:
-
应用程序准备数据和缓冲区
-
将工作请求放入 Work Queue (WQ)
-
WQ 包含 Send Queue (SQ)和 Receive Queue (RQ)
-
SQ 用于发送数据请求
-
RQ 用于准备接收数据缓冲区
-
-
对于发送方:
-
在 SQ 中放置发送请求
-
RDMA 硬件直接处理 SQ 中的请求
-
将数据从本地内存直接传输到远程内存
-
-
对于接收方:
-
预先在 RQ 中注册接收缓冲区
-
当消息到达时,自动匹配 RQ 中的缓冲区
-
直接将数据写入预注册的内存区域
-
-
操作完成后,结果记录在 Completion Queue (CQ)
-
通知应用程序操作状态
-
提供错误处理和性能监控
-
-
应用程序通过 CQ 获取操作状态和结果
关键点:
-
WQ 是 SQ 和 RQ 的容器
-
RQ 确保接收缓冲区始终可用
-
SQ 管理主动发送的数据请求
-
CQ 提供操作完成的反馈
内存相关
-
MR: Memory Region (内存区域)
-
MW: Memory Window (内存窗口)
-
PD: Protection Domain (保护域)
-
VA: Virtual Address (虚拟地址)
-
PA: Physical Address (物理地址)
-
DMA: Direct Memory Access (直接内存访问)
操作类型
在 RDMA 中,主要的操作类型包括:
-
读操作 (Read) - 从远程节点读取数据到本地内存 - 单向操作,不需要远程节点 CPU 参与 - 发起方可以直接读取指定的远程内存区域
-
写操作 (Write) - 将本地内存数据直接写入远程节点内存 - 单向操作,不需要远程节点 CPU 参与 - 数据可以直接传输到远程指定内存地址
-
发送操作 (Send) - 传统的消息传递模式 - 需要远程节点的接收缓冲区和 CPU 参与 - 数据从发送方传输到接收方的接收队列
-
原子操作 (Atomic Operations) - 包括 Compare and Swap (CAS) - Fetch and Add (FAA) - 对远程内存进行原子性的读-修改-写入操作 - 保证操作的原子性和一致性
-
绑定操作 (Bind) - 动态管理内存区域的访问权限 - 控制远程内存区域的读、写、执行权限 - 提供细粒度的内存访问控制
连接相关
-
QPN: Queue Pair Number
-
PSN: Packet Sequence Number
-
LID: Local Identifier
-
GID: Global Identifier
-
MTU: Maximum Transfer Unit
工作请求相关
-
WR: Work Request (工作请求)
-
WQE: Work Queue Element (工作队列元素)
-
CQE: Completion Queue Element (完成队列元素)
-
SGE: Scatter/Gather Element (分散/聚集元素)
状态相关
-
RTR: Ready to Receive (准备接收)
-
RTS: Ready to Send (准备发送)
-
ERROR: 错误状态
-
RESET: 重置状态
协议相关
-
RC: Reliable Connected (可靠连接)
-
UC: Unreliable Connected (不可靠连接)
-
UD: Unreliable Datagram (不可靠数据报)
-
XRC: Extended Reliable Connected (扩展可靠连接)
服务质量相关
-
QoS: Quality of Service
-
SL: Service Level
-
VL: Virtual Lane
API 相关
-
Verbs: RDMA 编程接口
-
libibverbs: RDMA verbs 库
-
librdmacm: RDMA 连接管理库
-
MAD: Management Datagram
-
CM: Connection Manager
性能相关
-
Latency: 延迟
-
Bandwidth: 带宽
-
IOPS: Input/Output Operations Per Second
-
PPS: Packets Per Second
安全相关
-
AH: Address Handle
-
Keys: 密钥
-
Rkey: Remote Key
-
Lkey: Local Key
DMA/RDMA
科普文:软件架构网络系列之【高性能网络/存储之基础:TCP/IP、DMA、RDMA、Infiniband、RoCE、iWARP】-CSDN博客
科普文:软件架构网络系列之【RDMA技术概览:特点、优缺点与应用场景】_hpc网络 rdma-CSDN博客
科普文:软件架构网络系列之【详解RDMA 技术架构与实践】_rdma 计算机体系结构-CSDN博客
科普文:软件架构网络系列之【高性能存储网络的革新之路 NVMe over RDMA】-CSDN博客
传统IO(无DMA)
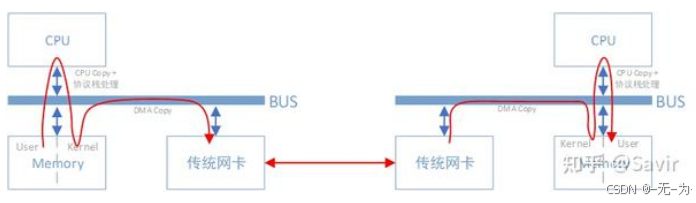
DMA
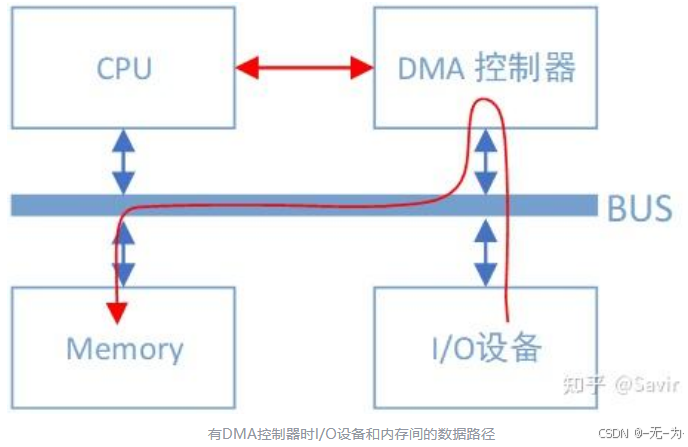
直接内存访问DMA( Direct Memory Access)方式,是一种完全由硬件执行I/O交换的工作方式。
在这种方式中,DMA控制器从CPU完全接管对总线的控制,数据交换不经过 CPU,而直接在内存和I/O设备之间进行。
DMA工作时,由DMA控制器向内存发出地址和控制信号;进行地址修改;对传送字的个数计数;并且以中断方式 向CPU报告传送操作的结束。DMA方式一般用于高速传送成组的数据。
-使用DMA方式目的:
- 减少大批量数据传输时CPU的开销;方法:
- 采用专用DMA控制器(DMAC)生成访存地址并控制访存过程;
优点:
- 操作均由硬件电路实现,传输速度快;
- CPU基本不干预,仅在初始化和结束时参与,CPU与外设并行工作,效率高。
DMA的数据块传送过程可分为三个阶段:传送前预处理;正式传送;传送后处理。
DMA控制流程:
1. 预处理:由CPU执行I/O指令对DMAC进行初始化与启动。
2. 数据传送:由DMAC控制总线进行数传。
3. 后处理:传送结束,DMAC向CPU发中断请求,报告DMA操作的结束。CPU响应,转入中断服务程序,完成DMA结束处理工作。
RDMA
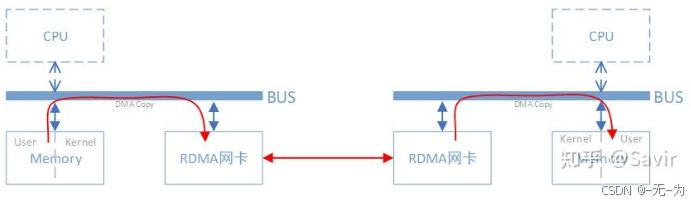
RDMA( Remote Direct Memory Access )意为远程直接地址访问,通过RDMA,本端节点可以“直接”访问远端节点的内存。
所谓直接,指的是可以像访问本地内存一样,绕过传统以太网复杂的TCP/IP网络协议栈读写远端内存,而这个过程对端是不感知的,而且这个读写过程的大部分工作是由硬件而不是软件完成的。
RDMA主要特点和解决的问题:
RDMA 解决了传统网络通信方式中存在的一些瓶颈,例如 TCP/IP 协议栈的复杂性和处理器的负载问题。它通过使用专门的适配器和硬件来绕过操作系统和协议栈的限制,实现了直接从一个主机内存到另一个主机内存的数据传输。
以下是 RDMA 的主要特点和解决的一些问题:
- 低延迟:RDMA 可以减少数据传输的延迟,因为它不需要通过操作系统协议栈进行数据包的处理,也不需要等待 CPU 处理数据。这使得 RDMA 在对延迟敏感的应用程序中具有很大优势,如金融交易、科学计算等。
- 高带宽:RDMA 可以实现非常高的数据传输速率,因为它可以直接访问主机内存而无需 CPU 的介入。这对于大规模数据传输、高性能计算和存储系统非常重要。
- 减轻 CPU 负载:RDMA 可以将数据传输的任务从 CPU 上卸载,这样 CPU 可以更专注于计算任务,提高整体系统性能。
- 零拷贝:RDMA 通过绕过操作系统协议栈,可以实现零拷贝的数据传输。这意味着数据在传输过程中不需要进行额外的复制操作,减少了数据传输的开销。
- 灵活性:RDMA 支持多种传输协议,如 InfiniBand、RoCE(RDMA over Converged Ethernet)和 iWARP(Internet Wide Area RDMA Protocol),可以适应不同网络环境和需求。
RDMA支持三种基本的操作类型:
-
写操作:允许一个节点将数据直接写入另一个节点的内存。
-
读操作:允许一个节点直接读取另一个节点的内存中的数据。
-
原子操作:一种特殊的操作,可以在远程节点上执行一些原子性的操作,如比较并交换(CAS)等。
尽管 RDMA 提供了许多优势,但它也有一些挑战和限制。例如,RDMA 需要特殊的硬件和适配器支持,系统之间需要预先建立连接并配置共享内存等。此外,RDMA 的部署和管理可能相对复杂,并且需要专门的技术知识。
总的来说,RDMA 是一项强大的网络技术,可以显著提高数据传输性能和降低延迟。它被广泛应用于高性能计算、存储系统、云计算等领域,为提供更快、更可靠的数据传输解决方案。
RDMA优点:
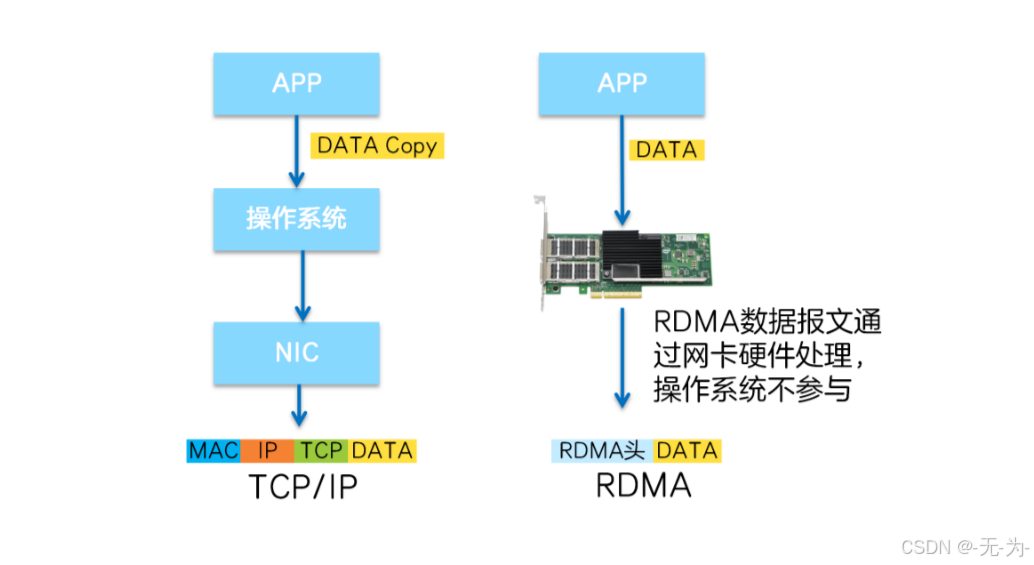
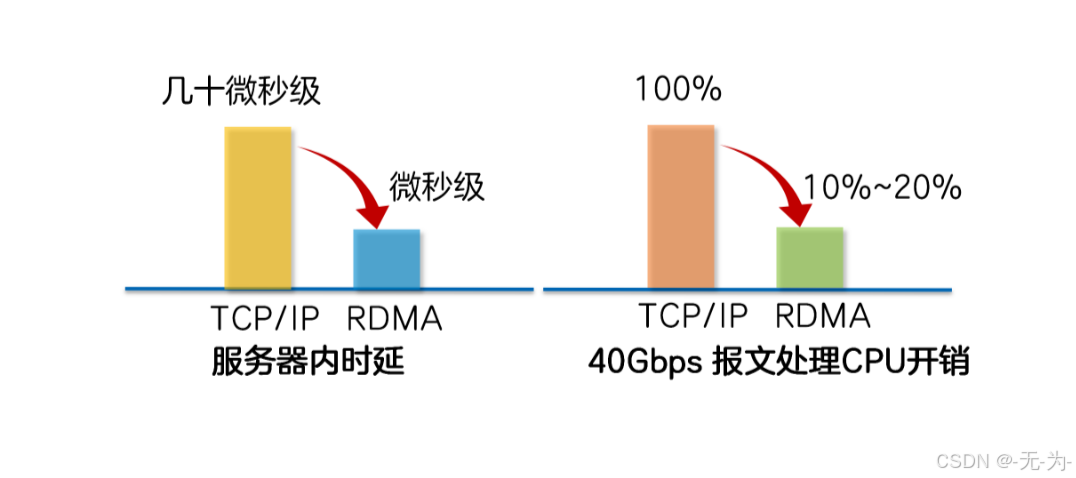
RDMA 将服务器应用数据直接由内存传输到智能网卡(固化 RDMA 协议),由智能网卡硬件完成 RDMA 传输报文封装,解放了操作系统和 CPU。
这使得 RDMA 具有两大优势:
- Zero Copy(零拷贝):无需将数据拷贝到操作系统内核态并处理数据包头部的过程,传输延迟会显著减小。
- Kernel Bypass(内核旁路)和 Protocol Offload(协议卸载):不需要操作系统内核参与,数据通路中没有繁琐的处理报头逻辑,不仅会使延迟降低,而且也大大节省了 CPU 的资源。
RDMA的挑战与限制:
尽管RDMA技术具有诸多优点,但也面临一些挑战和限制:
-
硬件依赖:RDMA需要特定的网卡硬件支持,这些网卡通常比传统的以太网网卡更昂贵。
-
安全性问题:由于RDMA允许远程节点直接访问本地内存,可能会带来一些安全性问题。
-
编程复杂性:RDMA的编程模型与传统的网络编程模型有所不同,需要开发人员具有一定的专业知识和经验。
RDMA的技术实现
科普文:软件架构网络系列之【RDMA技术实现之RoCEv2工作过程】-CSDN博客
科普文:软件架构网络系列之【RDMA技术实现:一文搞懂 RoCE v2】_rocev2-CSDN博客
科普文:软件架构网络系列之【RDMA技术实现之RoCEv2:TCP的变革者还是取而代之者】_rocev2协议-CSDN博客
科普文:软件架构网络系列之【信创:SAN 交换机“卡脖子”,RoCE V2 成破局关键】_信创交换机-CSDN博客
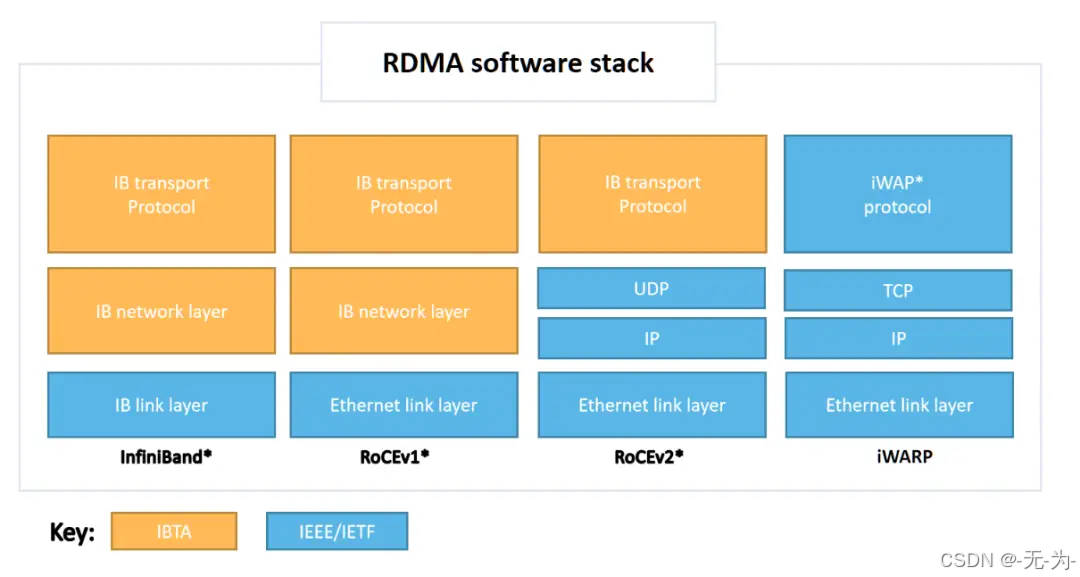
RDMA技术被三种网络协议所支持:
1.Infiniband(IB):支持RDMA的新一代网络协议。由于这是一种新的网络技术,因此需要使用RMDA专用网卡与交换机,从硬件级别全面支持RDMA。(国内信创这一关是过不了)
2.RDMA OVER Converged Ethernet(RoCE):基于现有的以太网实现RDMA,底层网络包头部是普通的以太网包头,上层网络包头部是Infiniband包头,因此RoCE只需要专有的支持RoCE网卡,就可以在标准以太网基础架构(交换机)上实现RDMA。(国内推广的是RoCE V2)
3.Internet Wide Area RDMA Protocol(iWARP): iWARP直接将RDMA实现在了TCP上,这允许在标准以太网基础架构(交换机)上使用RDMA,这种方案需要配置支持iWARP的特殊网卡。
在高性能存储、计算数据中心中采用这三类 RDMA 网络,都可以大幅度降低数据传输时延,并为应用程序提供更高的 CPU 资源可用性。
- 其中 InfiniBand 网络为数据中心带来极致的性能,传输时延低至百纳秒,比以太网设备延时要低一个量级。Infiniband 技术先进,但是价格高昂,应用局限在 HPC 高性能计算领域,随着 RoCE 和 iWARPC 的出现,降低了 RDMA 的使用成本,推动了 RDMA 技术普及。
- RoCE 和 iWARP 网络为数据中心带来超高性价比,基于以太网承载 RDMA,充分利用了 RDMA 的高性能和低 CPU 使用率等优势,同时网络建设成本也不高。
- 基于 UDP 协议的 RoCE 比基于 TCP 协议的 iWARP 性能更好,结合无损以太网的流控技术,解决了丢包敏感的问题,RoCE 网络已广泛应用于各行业高性能数据中心中。
RDMA的应用场景
RDMA技术的应用场景非常广泛,包括但不限于:
-
数据中心:服务器之间需要频繁地进行大量数据的传输和交换,RDMA的高性能与低延迟特性使得它非常适合于数据中心中的网络通信。
-
高性能计算(HPC):需要处理大量数据并进行复杂的计算,RDMA的直接内存访问和零拷贝技术可以减少数据传输的开销,提高计算效率。
-
分布式存储系统:节点之间需要频繁地进行数据读写操作,RDMA的高效数据传输和直接内存访问特性可以提高节点之间的数据读写效率。
-
云计算:虚拟机(VM)之间的通信和数据传输是常见的需求,RDMA可以用于实现VM之间的高效通信。
科普文:软件架构网络系列之【RDMA 能给数据中心带来什么】_广域rdma-CSDN博客
科普文:软件架构网络系列之【信创:SmartX产品基于RoCE v2的分布式存储构建】_信创部署架构-CSDN博客
科普文:软件架构网络系列之【RDMA 能给数据中心带来什么:数据中心网络最佳选择是RoCEv2不是InfiniBand】_华为 dcqcn-CSDN博客
科普文:软件架构网络系列之【RDMA 能给数据中心带来什么:可靠传输 RoCEv2】_ovs 结合rdma意义-CSDN博客
科普文:软件架构网络系列之【RDMA应用:一文看懂高性能网络】_rdma组网-CSDN博客
科普文:软件架构Linux系列之【信创:金融行业存储的发展趋势与选择】黄湘武-CSDN博客
那么DMA 和RDMA 又有什么区别呢?
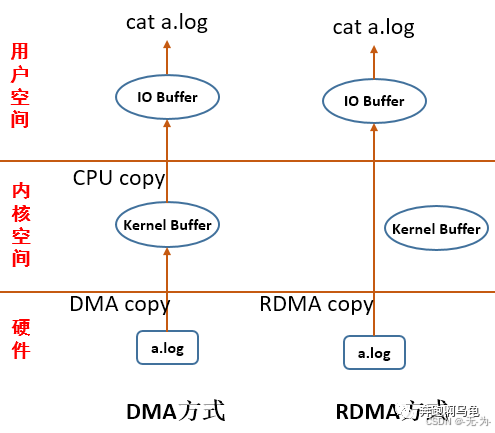
1. DMA 虽然解放了cpu 但是 他还是不能把数据之节从存储设备copy 到user 层。
硬盘->kernel space->user space->app
这其中就要cpu 参与两次 当数据完全读到kernel 层的 io buffer 时发出中断 然后cpu 把数据copy 到user 层,然后cpu 发出中断app 从睡眠中恢复 读写数据。
2. RDMA 则不然 他直接从硬盘把数据读到user 层
硬盘->user space->app
在这个过程中cpu 就参与一次。
值得注意的是DMA/RDMA的引入会导致cache 内容和RMA 中不一致的问题, 这里需要特别注意。
RoCE开发环境搭建:Soft-RoCE
至少应该准备两张 RDMA 网卡。纵观全球市场,现在做 RDMA 网卡的品牌厂商主要有三大巨头企业,分别是 Marvell、intel、Mellanox,其中 Marvell 是收购的 Qlogic 品牌,Mellanox 被英伟达收购。有条件的装在两台服务器上,没条件的装在一台服务器上。
目前高端的 RDMA 卡是 100G、200G、400G 的网卡,比如英伟达的 ConnectX-7 系列,一张卡大约 2000 美元:很明显从硬件角度入手搭建环境,财力不允许。
科普文:软件架构网络系列之【优化 RDMA 代码的建议和技巧】_rdma mtu-CSDN博客
Soft-RoCE 是 RoCE 的一种软件实现,它允许 RoCE 在任何以太网网络适配器上运行,无论它是否提供硬件加速。从 Red Hat Enterprise Linux 7.4 开始,Soft-RoCE 驱动程序已合并到内核中。用户空间驱动程序也被合并到 rdma-core 包中。Soft-RoCE 也称为 RXE。要启动、停止和配置 RXE。
参考下面操作,分别在Centos和Ubuntu下搭建RoCE开发环境,就可以基于 libibverbs API 进行RDMA 程序开发,同时RDMA 也自带了一些命令工具和网络测试工具。
Redhat/Centos 下的RoCE配置
首先安装基本的库 iproute, libibverbs, libibverbs-utils 和 infiniband-diags :
yum install iproute libibverbs libibverbs-utils infiniband-diags
使用rdma ink show查看当前的 RDMA link 情况。目前我们还没有配置 RXE,所以显示为空:
[root@test ~]# rdma link show
接下来我们配置RXE, 设备名为 rxe0, 在网卡(严谨一点叫做网络接口) xgbe0 上配置:
# modprobe rdma_rxe
# rdma link add mlx5_0 type rxe netdev xgbe0
如果 rdma link add 命令不支持,则使用rxe_cfg:
rxe_cfg add xgbe0
这个时候再使用rdma link show就能看到连接了:
# rdma link show
0/1: mlx5_0/1: state ACTIVE physical_state LINK_UP netdev xgbe0
# rxe_cfg status
rdma_rxe module not loaded
Name Link Driver Speed NMTU IPv4_addr RDEV RMTU
xgbe0 yes mlx5_core 1500 192.168.1.1
启动 rdma 服务:
# systemctl start rdma.service
或者
# rxe_cfg start
查看加载的 rdma 相关模块:
# lsmod | grep -E 'rdma|ib'
rdma_rxe 16384 0
svcrdma 16384 0
rpcrdma 16384 0
xprtrdma 16384 0
ib_isert 16384 0
ib_iser 16384 0
ib_srp 16384 0
ib_ipoib 147456 0
rdma_ucm 32768 0
ib_ucm 16384 0
ib_umad 40960 0
rdma_cm 131072 1 rdma_ucm
ib_cm 135168 2 rdma_cm,ib_ipoib
iw_cm 53248 1 rdma_cm
mlx5_ib 446464 0
ib_uverbs 155648 2 rdma_ucm,mlx5_ib
ib_core 442368 8 rdma_cm,ib_ipoib,iw_cm,ib_umad,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm
mlx5_core 2023424 1 mlx5_ib
auxiliary 16384 2 mlx5_ib,mlx5_core
mlx_compat 69632 20 rdma_cm,ib_ipoib,rdma_rxe,mlxdevm,rpcrdma,ib_srp,xprtrdma,iw_cm,auxiliary,svcrdma,ib_iser,ib_umad,ib_isert,ib_core,rdma_ucm,ib_uverbs,mlx5_ib,ib_cm,mlx5_core,ib_ucm
ipv6 610304 253 rdma_cm,ib_ipoib,udp_diag,ib_core
查看虚拟的设备:
# ibv_devices
device node GUID
------ ----------------
mlx5_0 b8cef60300e2048
# ibstat
CA 'mlx5_0'
CA type: MT4117
Number of ports: 1
Firmware version: 14.27.4000
Hardware version: 0
Node GUID: 0xb8cef60300ce2048
System image GUID: 0xb8cef60300ce2048
Port 1:
State: Active
Physical state: LinkUp
Rate: 25
Base lid: 0
LMC: 0
SM lid: 0
Capability mask: 0x00010000
Port GUID: 0xbacef6fffece2048
Link layer: Ethernet
校验这个设备(作为服务端)
# ibv_rc_pingpong -d mlx5_0 -g 0
local address: LID 0x0000, QPN 0x00015b, PSN 0x33a37e, GID fe80::bace:f6ff:fece:2048
校验这个设备(作为客户端)
# ibv_rc_pingpong -d mlx5_0 -g 0 192.168.1.1
local address: LID 0x0000, QPN 0x00015c, PSN 0x514e35, GID fe80::bace:f6ff:fece:2048
remote address: LID 0x0000, QPN 0x00015b, PSN 0x33a37e, GID fe80::bace:f6ff:fece:2048
8192000 bytes in 0.00 seconds = 15142.33 Mbit/sec
1000 iters in 0.00 seconds = 4.33 usec/iter
幸运的话,如上图所示,客户端和服务端建立的连接,并发送了数据,说明安装成功。Ubuntu 下的RoCE配置
安装相关的包:
# apt-get install libibverbs1 ibverbs-utils librdmacm1 libibumad3 ibverbs-providers rdma-core
rdma link show 没有结果,我们需要配置一个模拟卡:
# modprobe rdma_rxe
# rdma link add rxe_0 type rxe netdev enp2s0
# rdma link show
link rxe_0/1 state ACTIVE physical_state LINK_UP netdev enp2s0
查看设备:
# ibv_devices
device node GUID
------ ----------------
rxe_0 02e04ffffe290bd5
# ibstat
CA 'rxe_0'
CA type:
Number of ports: 1
Firmware version:
Hardware version:
Node GUID: 0x02e04ffffe290bd5
System image GUID: 0x02e04ffffe290bd5
Port 1:
State: Active
Physical state: LinkUp
Rate: 2.5
Base lid: 0
LMC: 0
SM lid: 0
Capability mask: 0x00010000
Port GUID: 0x02e04ffffe290bd5
Link layer: Ethernet
使用ibv_rc_pingpong进行测试,在一个窗口中打开服务端:
# ibv_rc_pingpong -d rxe_0 -g 0
local address: LID 0x0000, QPN 0x000011, PSN 0x966045, GID fe80::2e0:4fff:fe29:bd5
remote address: LID 0x0000, QPN 0x000012, PSN 0xa069a9, GID fe80::2e0:4fff:fe29:bd5
8192000 bytes in 0.04 seconds = 1770.19 Mbit/sec
1000 iters in 0.04 seconds = 37.02 usec/iter
在另外一个窗口中打开客户端:
ibv_rc_pingpong -d rxe_0 -g 0 192.168.1.5
local address: LID 0x0000, QPN 0x000012, PSN 0xa069a9, GID fe80::2e0:4fff:fe29:bd5
remote address: LID 0x0000, QPN 0x000011, PSN 0x966045, GID fe80::2e0:4fff:fe29:bd5
8192000 bytes in 0.04 seconds = 1772.73 Mbit/sec
1000 iters in 0.04 seconds = 36.97 usec/iter
幸运的话如上图所示,它们建立的连接并发送了数据。Redhat/Centos 下的RoCE的测试工具
RDMA 有一堆的管理工具和测试工具,慢慢都归集于linux-rdma/rdma-core[1]项目下,甚至这些工具都有 man 手册,比如ibv_devices[2],可以说非常友好了,你只需要知晓有哪些工具,大概是干什么的,具体使用的时候查询它的 man 手册就好了。
这些工具主要用于:
-
RDMA 设备状态检查
-
网络连接测试
-
性能测试和基准测试
-
故障排除
-
网络拓扑发现
命令安装这些工具:
# RHEL/CentOS
yum install libibverbs-utils infiniband-diags rdma-core perftest librdmacm-utils
# 对于 RHEL 8/CentOS 8
dnf install libibverbs-utils infiniband-diags rdma-core perftest librdmacm-utils
man ibstat
man ibv_devinfo
man rping
1. libibverbs-utils 包
-
ibv_devices:列出系统中所有的 IB 设备
-
ibv_devinfo:显示 IB 设备的详细信息
-
ibv_rc_pingpong:RC(Reliable Connection)模式的 ping-pong 测试工具
-
ibv_uc_pingpong:UC(Unreliable Connection)模式测试工具
-
ibv_srq_pingpong:Shared Receive Queue 测试工具
2. infiniband-diags 包
-
ibstat:显示 IB 适配器和端口状态
-
ibstatus:显示 IB 设备状态信息
-
ibhosts:显示 IB 子网中的主机
-
ibnetdiscover:发现并显示 IB 网络拓扑
-
iblinkinfo:显示 IB 网络链路信息
3. rdma-core 包
-
rdma:RDMA 子系统管理工具
-
rxe_cfg:软件 RDMA 配置工具,弃用,逐步被 rdma 命令替代
4. perftest 包
-
ib_send_bw:带宽测试工具
-
ib_read_bw:RDMA read 带宽测试
-
ib_write_bw:RDMA write 带宽测试
-
ib_send_lat:延迟测试工具
-
ib_read_lat:RDMA read 延迟测试
-
ib_write_lat:RDMA write 延迟测试
5. librdmacm-utils 包
-
rping:RDMA ping 测试工具
-
ucmatose:UC 连接测试工具
-
rdma_client/rdma_server:RDMA 客户端/服务器测试程序
RoCE开发常见libibverbs API
这些 API 覆盖了 RDMA 编程的主要流程,包括:
-
设备初始化
-
内存注册
-
完成队列创建
-
队列对管理
-
发送和接收操作
-
完成处理
-
资源清理
1.初始化阶段
// 获取设备列表
struct ibv_device **dev_list = ibv_get_device_list(NULL);
// 打开设备
struct ibv_context *context = ibv_open_device(dev_list[0]);
// 分配保护域
struct ibv_pd *pd = ibv_alloc_pd(context);
2.内存注册
// 注册内存区域
struct ibv_mr *mr = ibv_reg_mr(
pd, // 保护域
buffer, // 内存地址
buffer_size, // 内存大小
IBV_ACCESS_LOCAL_WRITE |
IBV_ACCESS_REMOTE_READ |
IBV_ACCESS_REMOTE_WRITE // 访问权限
);
3.创建完成队列
// 创建完成队列
struct ibv_cq *cq = ibv_create_cq(
context, // 设备上下文
cq_size, // 队列深度
NULL, // 上下文
NULL, // 完成通道
0 // 创建标志
);
4.创建队列对(QP)
// 定义QP属性
struct ibv_qp_init_attr qp_init_attr = {
.qp_type = IBV_QPT_RC, // 可靠连接
.send_cq = cq, // 发送完成队列
.recv_cq = cq, // 接收完成队列
.cap = {
.max_send_wr = 16, // 最大发送请求
.max_recv_wr = 16, // 最大接收请求
.max_send_sge = 1, // 发送scatter/gather元素
.max_recv_sge = 1 // 接收scatter/gather元素
}
};
// 创建队列对
struct ibv_qp *qp = ibv_create_qp(
pd, // 保护域
&qp_init_attr // QP属性
);
5.QP 状态转换
// 初始化QP
struct ibv_qp_attr attr = {
.qp_state = IBV_QPS_INIT,
.pkey_index = 0,
.port_num = 1
};
ibv_modify_qp(qp, &attr, IBV_QP_STATE | IBV_QP_PKEY_INDEX | IBV_QP_PORT);
// 切换到就绪状态
attr.qp_state = IBV_QPS_RTR; // 就绪接收
ibv_modify_qp(qp, &attr, IBV_QP_STATE);
attr.qp_state = IBV_QPS_RTS; // 就绪发送
ibv_modify_qp(qp, &attr, IBV_QP_STATE);
6.发送操作
// 准备发送工作请求
struct ibv_sge sge = {
.addr = (uintptr_t)local_buffer,
.length = buffer_size,
.lkey = mr->lkey
};
struct ibv_send_wr wr = {
.wr_id = 1, // 用户定义标识
.sg_list = &sge, // scatter/gather列表
.num_sge = 1, // scatter/gather元素数
.opcode = IBV_WR_SEND, // 操作类型
.send_flags = IBV_SEND_SIGNALED // 需要完成通知
};
// 发送请求
struct ibv_send_wr *bad_wr;
ibv_post_send(qp, &wr, &bad_wr);
7.接收操作
// 准备接收工作请求
struct ibv_sge recv_sge = {
.addr = (uintptr_t)recv_buffer,
.length = buffer_size,
.lkey = mr->lkey
};
struct ibv_recv_wr recv_wr = {
.wr_id = 2,
.sg_list = &recv_sge,
.num_sge = 1
};
// 投递接收请求
struct ibv_recv_wr *bad_recv_wr;
ibv_post_recv(qp, &recv_wr, &bad_recv_wr);
8.完成处理
// 查询完成情况
struct ibv_wc wc;
int num_comp = ibv_poll_cq(cq, 1, &wc);
if (num_comp > 0) {
// 检查操作状态
if (wc.status == IBV_WC_SUCCESS) {
// 操作成功
}
}
9.资源清理
ibv_destroy_qp(qp);
ibv_destroy_cq(cq);
ibv_dereg_mr(mr);
ibv_dealloc_pd(pd);
ibv_close_device(context);RoCE开发常用交换参数
RDMA 通信需要与对端交换关键信息,这个过程通常称为"连接建立"或"交换参数"。主要需要交换的信息包括:
-
基本连接信息
-
本地标识符(LID)
-
端口号
-
队列对(QP)编号
-
网络端口信息
-
内存访问信息
-
内存地址(Remote Virtual Address)
-
内存区域标识符(Remote Key, R_Key)
-
内存大小
-
交换方式
-
传统方法:使用 Socket
-
现代方法:
-
使用 IB 管理工具
-
使用 OpenFabrics Enterprise Distribution (OFED)
-
通过专门的服务发现机制
-
-
典型交换信息
struct connection_info {
uint16_t lid; // Local Identifier (本地子网标识)
union ibv_gid gid; // Global Identifier (全局唯一标识)
uint32_t qp_num; // Queue Pair Number
uint64_t remote_addr; // 远程内存地址
uint32_t rkey; // Remote Key
uint32_t size; // 内存区域大小
};
-
交换流程
-
一方作为服务器监听
-
另一方主动连接
-
互相发送连接所需参数
-
建立 RDMA 连接
常见交换方式
在使用 RDMA(Remote Direct Memory Access)进行通信时,交换参数是建立高效通信的关键步骤。这些参数包括队列对(QP,Queue Pair)的标识符、内存密钥、网络地址等。以下是常见的几种交换参数的方法:
1. 静态配置(Static Configuration)
-
特点:通过硬编码或配置文件预先指定通信双方的参数。
-
优点:
-
简单易用,不依赖额外的通信通道。
-
-
缺点:
-
缺乏灵活性,不适合动态或大规模系统。
-
需要手动管理配置文件,容易出错。
-
-
适用场景:小型固定拓扑的系统。
2. 通过 TCP/IP 进行参数交换
-
原理:通信双方在 RDMA 通信之前使用传统的 TCP/IP 通道(如 socket)交换必要的参数。
-
步骤:
-
建立 TCP/IP 连接。
-
通过连接发送 QP 编号、LID(Local Identifier)、GID(Global Identifier)、内存密钥等信息。
-
关闭 TCP/IP 通道,切换到 RDMA 通信。
-
-
优点:
-
通用性强,适用于各种网络环境。
-
无需复杂的额外配置。
-
-
缺点:
-
增加了一次 TCP/IP 的通信开销。
-
-
适用场景:常见的点对点或小规模分布式系统。
3. 通过分布式服务(如 etcd 或 Consul)进行参数存储与共享
-
原理:将 RDMA 参数存储在分布式键值存储中,通信双方通过查询该存储获取对方参数。
-
优点:
-
易于扩展,支持动态拓扑。
-
支持高可用和一致性。
-
-
缺点:
-
引入了分布式存储的依赖。
-
可能增加延迟。
-
-
适用场景:大规模分布式系统,如云计算平台或 HPC 系统。
4. 使用中间服务器(Parameter Exchange Server)
-
原理:通过一个专门的服务器协调通信双方的参数交换。
-
流程:
-
每一方将自己的 RDMA 参数发送到服务器。
-
服务器将对方的参数返回。
-
-
优点:
-
中心化管理,便于调试和监控。
-
适合复杂拓扑。
-
-
缺点:
-
服务器是单点故障,需设计高可用。
-
-
适用场景:需要较高控制力的分布式系统。
5. 通过共享文件系统
-
原理:通信双方将参数写入共享文件或数据库,然后互相读取。
-
优点:
-
实现简单。
-
-
缺点:
-
文件系统访问效率较低。
-
不适合高频动态更新。
-
-
适用场景:系统启动时的一次性初始化。
6. 使用 IPoIB(IP over InfiniBand)作为辅助通道
-
原理:通过 InfiniBand 的 IPoIB 技术模拟 TCP/IP 通信,在 InfiniBand 网络上交换参数。
-
优点:
-
利用现有 InfiniBand 硬件,无需额外的以太网网络。
-
-
缺点:
-
IPoIB 的性能低于原生 RDMA。
-
-
适用场景:全 InfiniBand 网络的环境。
具体选择哪种方式取决于系统的规模、性能要求和复杂性。如果是小规模系统,使用 TCP/IP 或静态配置即可满足需求;而在大规模分布式环境中,分布式服务或中间服务器更具优势。


















 2205
2205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











