







 RDMA(Remote Direct Memory Access)是一种高效网络通信技术,通过绕过CPU直接访问远程主机内存,减少了CPU占用和内存带宽瓶颈,提供了低延迟和高带宽。RDMA支持InfiniBand、RoCE和iWARP三种实现,其中InfiniBand具有最佳性能但成本较高,RoCE和iWARP则能在标准以太网上实现。RDMA编程涉及Send和Receive两种操作模式,以及单边和双边操作。RDMA的优势在于其CPU Offload、Kernel Bypass和Zero Copy特性,广泛应用于高性能计算和深度学习等领域。
RDMA(Remote Direct Memory Access)是一种高效网络通信技术,通过绕过CPU直接访问远程主机内存,减少了CPU占用和内存带宽瓶颈,提供了低延迟和高带宽。RDMA支持InfiniBand、RoCE和iWARP三种实现,其中InfiniBand具有最佳性能但成本较高,RoCE和iWARP则能在标准以太网上实现。RDMA编程涉及Send和Receive两种操作模式,以及单边和双边操作。RDMA的优势在于其CPU Offload、Kernel Bypass和Zero Copy特性,广泛应用于高性能计算和深度学习等领域。
RDMA 架构与实践 | https://houmin.cc/posts/454a90d3/
RDMA,即 Remote Direct Memory Access,是一种绕过远程主机 OS kernel 访问其内存中数据的技术,概念源自于 DMA 技术。在 DMA 技术中,外部设备(PCIe 设备)能够绕过 CPU 直接访问 host memory;而 RDMA 则是指外部设备能够绕过 CPU,不仅可以访问本地主机的内存,还能够访问另一台主机上的用户态内存。由于不经过操作系统,不仅节省了大量 CPU 资源,同样也提高了系统吞吐量、降低了系统的网络通信延迟,在高性能计算和深度学习训练中得到了广泛的应用。本文将介绍 RDMA 的架构与原理,并讲解 RDMA 网络使用方法,测试代码在 Github 上可以找到。
技术背景
计算机网络通信中最重要两个衡量指标主要是 带宽 和 延迟,通信延迟主要是指:
-
Transmission Delay:
- The time taken to transmit a packet from the host to the transmission medium
- 计算方式:Delayt=L/BandwidthDelayt=L/Bandwidth,其中 L 是要传输的数据包 L bit,Bandwidth 为链路带宽
- 如果两端的带宽高,则传输时间短,传输延迟低
-
Propagation delay
-
After the packet is transmitted to the transmission medium, it has to go through the medium to reach the destination. Hence the time taken by the last bit of the packet to reach the destination is called propagation delay.
-
计算方法:Delayp=Distance/VelocityDelayp=Distance/Velocity,其中 Distance 是传输链路的距离,Velocity 是物理介质传输速度
1 2Velocity =3 X 108 m/s (for air) Velocity= 2.1 X 108 m/s (for optical fibre)
-
-
Queueing delay
- Let the packet is received by the destination, the packet will not be processed by the destination immediately. It has to wait in queue in something called as buffer. So the amount of time it waits in queue before being processed is called queueing delay.
- In general we can’t calculate queueing delay because we don’t have any formula for that.
-
Processing delay
- message handling time at sending/receive ends
- buffer管理、在不同内存空间中消息复制、以及消息发送完成后的系统中断
现实计算机网络中的通信场景中,主要是以发送小消息为主,因此处理延迟是提升性能的关键。
传统的 TCP/IP 网络通信,数据需要通过用户空间发送到远程机器的用户空间,在这个过程中需要经历若干次内存拷贝:
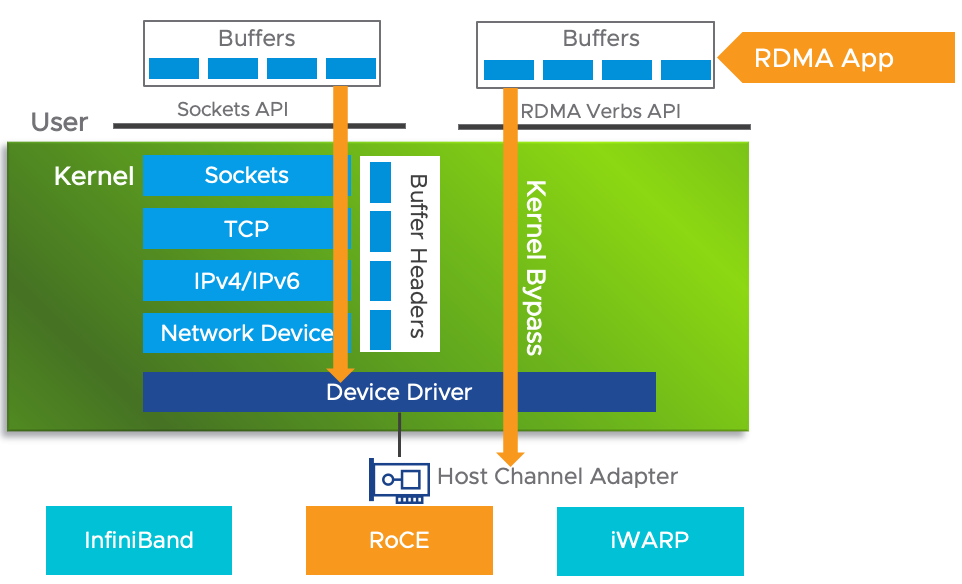
- 数据发送方需要讲数据从用户空间 Buffer 复制到内核空间的 Socket Buffer
- 数据发送方要在内核空间中添加数据包头,进行数据封装
- 数据从内核空间的 Socket Buffer 复制到 NIC Buffer 进行网络传输
- 数据接受方接收到从远程机器发送的数据包后,要将数据包从 NIC Buffer 中复制到内核空间的 Socket Buffer
- 经过一系列的多层网络协议进行数据包的解析工作,解析后的数据从内核空间的 Socket Buffer 被复制到用户空间 Buffer
- 这个时候再进行系统上下文切换,用户应用程序才被调用
在高速网络条件下,传统的 TPC/IP 网络在主机侧数据移动和复制操作带来的高开销限制了可以在机器之间发送的带宽。为了提高数据传输带宽,人们提出了多种解决方案,这里主要介绍下面两种:
- TCP Offloading Engine
- Remote Direct Memroy Access
TCP Offloading Engine
在主机通过网络进行通信的过程中,CPU 需要耗费大量资源进行多层网络协议的数据包处理工作,包括数据复制、协议处理和中断处理。当主机收到网络数据包时,会引发大量的网络 I/O 中断,CPU 需要对 I/O 中断信号进行响应和确认。为了将 CPU 从这些操作中解放出来,人们发明了TOE(TCP/IP Offloading Engine)技术,将上述主机处理器的工作转移到网卡上。TOE 技术需要特定支持 Offloading 的网卡,这种特定网卡能够支持封装多层网络协议的数据包。
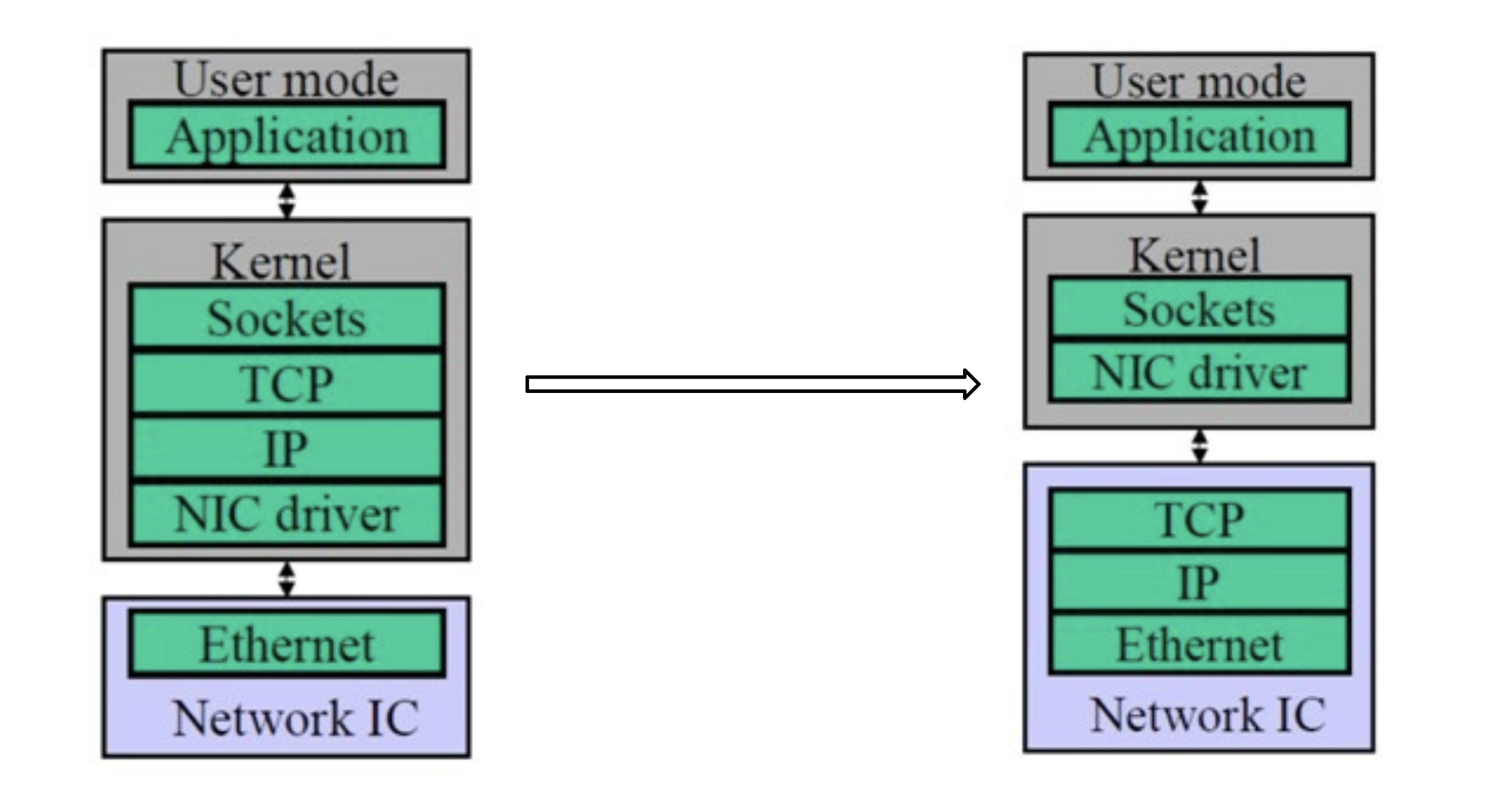
- TOE 技术将原来在协议栈中进行的IP分片、TCP分段、重组、checksum校验等操作,转移到网卡硬件中进行,降低系统CPU的消耗,提高服务器处理性能。
- 普通网卡处理每个数据包都要触发一次中断,TOE 网卡则让每个应用程序完成一次完整的数据处理进程后才触发一次中断,显著减轻服务器对中断的响应负担。
- TOE 网卡在接收数据时,在网卡内进行协议处理,因此,它不必将数据复制到内核空间缓冲区,而是直接复制到用户空间的缓冲区,这种“零拷贝”方式避免了网卡和服务器间的不必要的数据往复拷贝。
RDMA
为了消除传统网络通信带给计算任务的瓶颈,我们希望更快和更轻量级的网络通信,由此提出了RDMA技术。RDMA利用 Kernel Bypass 和 Zero Copy技术提供了低延迟的特性,同时减少了CPU占用,减少了内存带宽瓶颈,提供了很高的带宽利用率。RDMA提供了给基于 IO 的通道,这种通道允许一个应用程序通过RDMA设备对远程的虚拟内存进行直接的读写。
RDMA 技术有以下几个特点:
- CPU Offload:无需CPU干预,应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充
- Kernel Bypass:RDMA 提供一个专有的 Verbs interface 而不是传统的TCP/IP Socket interface。应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换
- Zero Copy:每个应用程序都能直接访问集群中的设备的虚拟内存,这意味着应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下,数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
下面是 RDMA 整体框架架构图,从图中可以看出,RDMA在应用程序用户空间,提供了一系列 Verbs 接口操作RDMA硬件。RDMA绕过内核直接从用户空间访问RDMA 网卡。RNIC网卡中包括 Cached Page Table Entry,用来将虚拟页面映射到相应的物理页面。
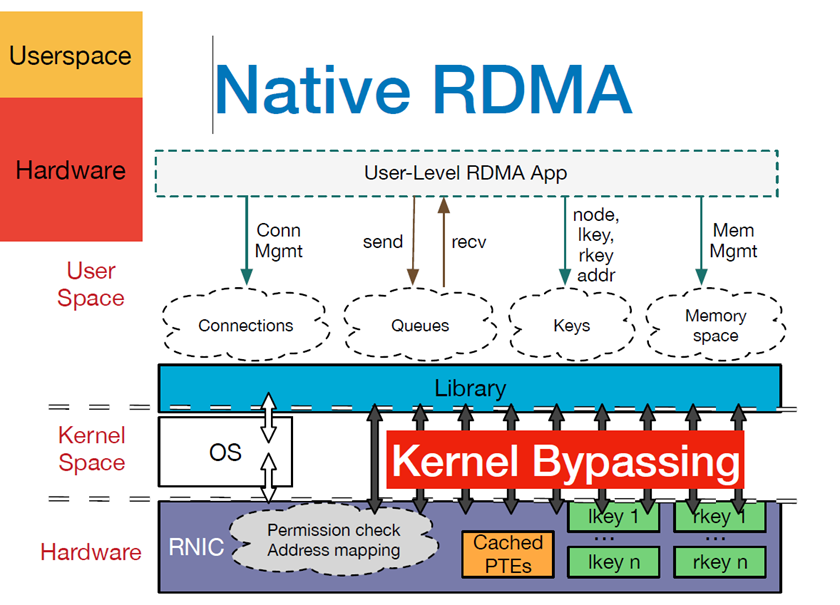
RDMA 详解
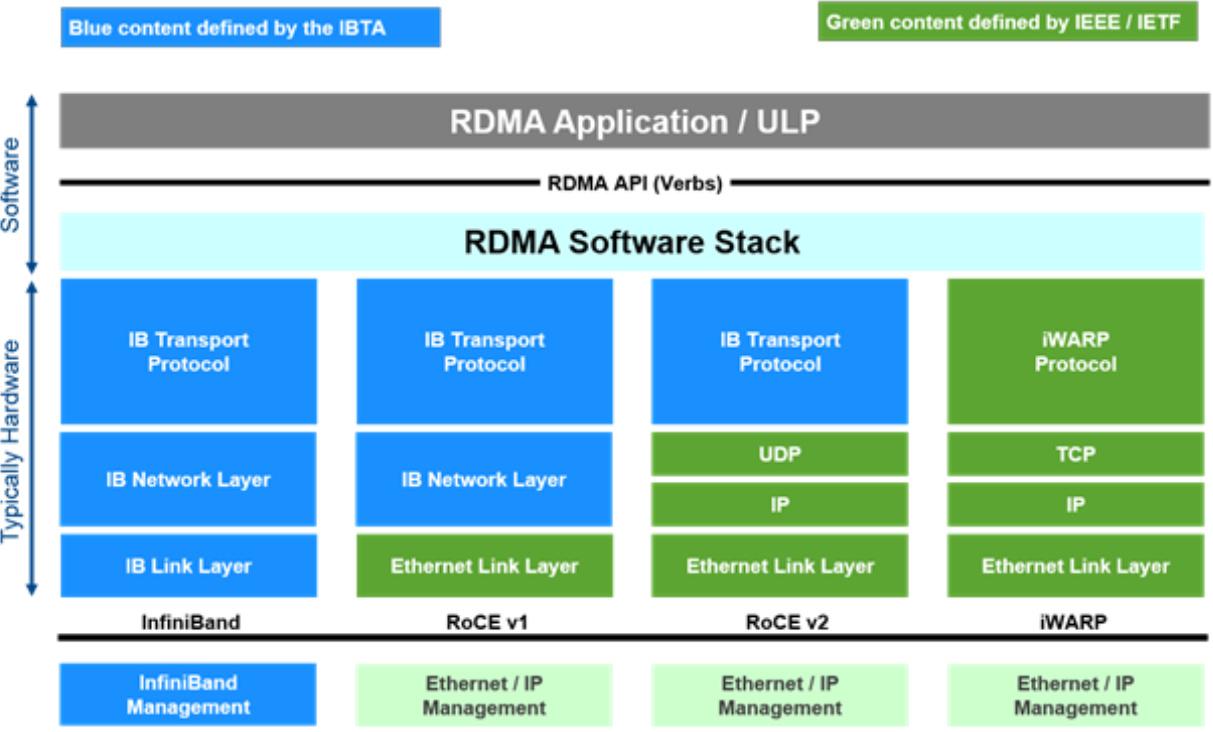
目前RDMA有三种不同的硬件实现,它们都可以使用同一套API来使用,但它们有着不同的物理层和链路层:
- Infiniband:基于 InfiniBand 架构的 RDMA 技术,由 IBTA(InfiniBand Trade Association)提出。搭建基于 IB 技术的 RDMA 网络需要专用的 IB 网卡和 IB 交换机。从性能上,很明显Infiniband网络最好,但网卡和交换机是价格也很高,然而RoCEv2和iWARP仅需使用特殊的网卡就可以了,价格也相对便宜很多。
- iWARP:Internet Wide Area RDMA Protocal,基于 TCP/IP 协议的 RDMA 技术,由 IETF 标 准定义。iWARP 支持在标准以太网基础设施上使用 RDMA 技术,而不需要交换机支持无损以太网传输,但服务器需要使用支持iWARP 的网卡。与此同时,受 TCP 影响,性能稍差。
- RoCE:基于以太网的 RDMA 技术,也是由 IBTA 提出。RoCE支持在标准以太网基础设施上使用RDMA技术,但是需要交换机支持无损以太网传输,需要服务器使用 RoCE 网卡,性能与 IB 相当。
I/O 瓶颈
时间回退到二十世纪的最后一年,随着 CPU 性能的迅猛发展,早在 1992 年 Intel 提出的 PCI 技术已经满足不了人民群众日益增长的 I/O 需求,I/O 系统的性能已经成为制约服务器性能的主要矛盾。尽管在 1998 年,IBM 联合 HP 、Compaq 提出了 PCI-X 作为 PCI 技术的扩展升级,将通信带宽提升到 1066 MB/sec,人们认为 PCI-X 仍然无法满足高性能服务器性能的要求,要求构建下一代 I/O 架构的呼声此起彼伏。经过一系列角逐,Infiniband 融合了当时两个竞争的设计 Future I/O 和 Next Generation I/O,建立了 Infiniband 行业联盟,也即 BTA (InfiniBand Trade Association),包括了当时的各大厂商 Compaq、Dell、HP、IBM、Intel、Microsoft 和 Sun。在当时,InfiniBand 被视为替换 PCI 架构的下一代 I/O 架构,并在 2000 年发布了 1.0 版本的 Infiniband 架构 Specification,2001 年 Mellanox 公司推出了支持 10 Gbit/s 通信速率的设备。
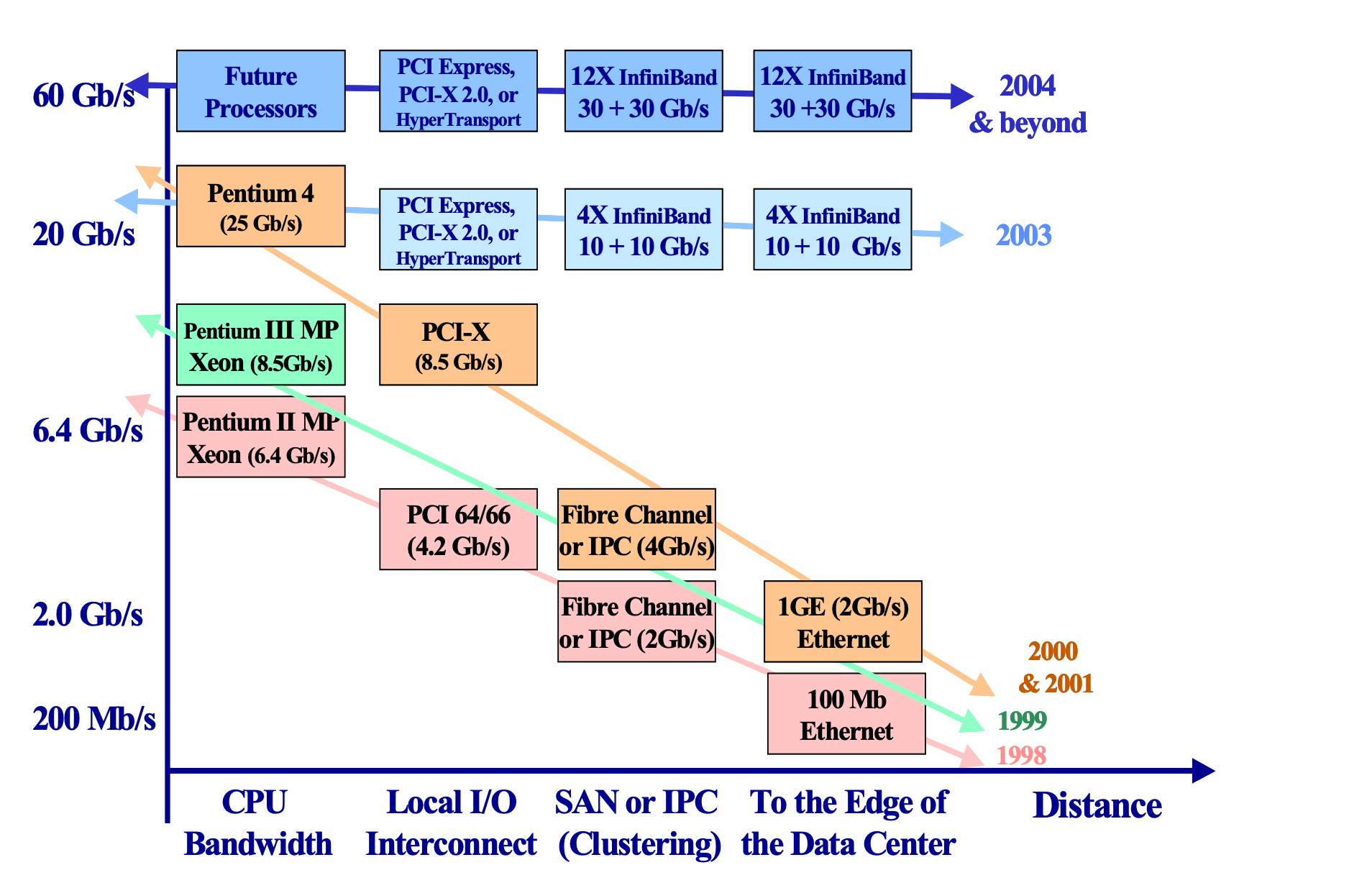
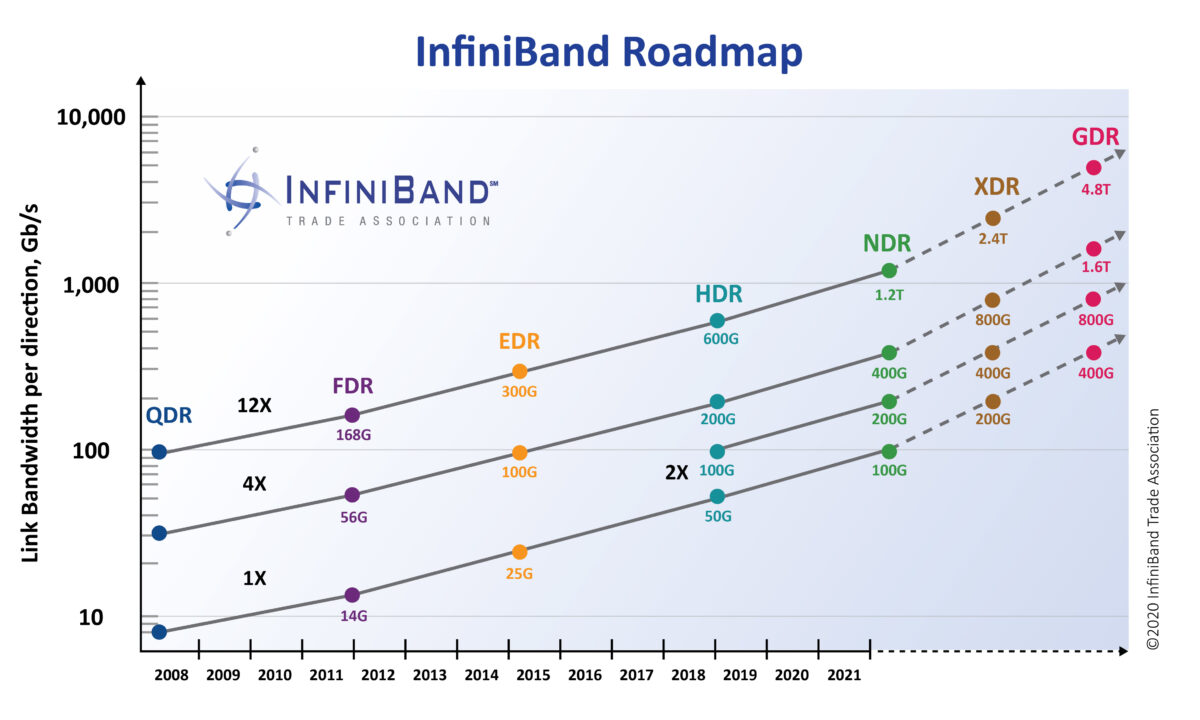
然而好景不长,2000 年互联网泡沫被戳破,人们对于是否要投资技术上如此跨越的技术产生犹豫。Intel 转而宣布要开发自己的 PCIe 架构,微软也停止了 IB 的开发。尽管如此,Sun 和 日立等公司仍然坚持对 InfiniBand 技术的研发,并由于其强大的性能优势逐渐在集群互联、存储系统、超级计算机内部互联等场景得到广泛应用,其软件协议栈也得到标准化,Linux 也添加了对于 Infiniband 的支持。进入2010年代,随着大数据和人工智能的爆发,InfiniBand 的应用场景从原来的超算等场景逐步扩散,得到了更加广泛的应用,InfiniBand 市场领导者 Mellanox 被 NVIDIA 收购,另一个主要玩家 QLogic 被 Intel 收购,Oracle 也开始制造自己的 InfiniBand 互联芯片和交换单元。到了 2020 年代,Mellanox 最新发布的 NDR 理论有效带宽已经可以达到 单端口 400 Gb/s,为了运行 400 Gb/s 的 HCA 可以使用 PCIe Gen5x16 或者 PCIe Gen4x32。
架构组成
InfiniBand 架构为系统通信定义了多种设备:channel adapter、switch、router、subnet manager,它提供了一种基于通道的点对点消息队列转发模型,每个应用都可通过创建的虚拟通道直接获取本应用的数据消息,无需其他操作系统及协议栈的介入。
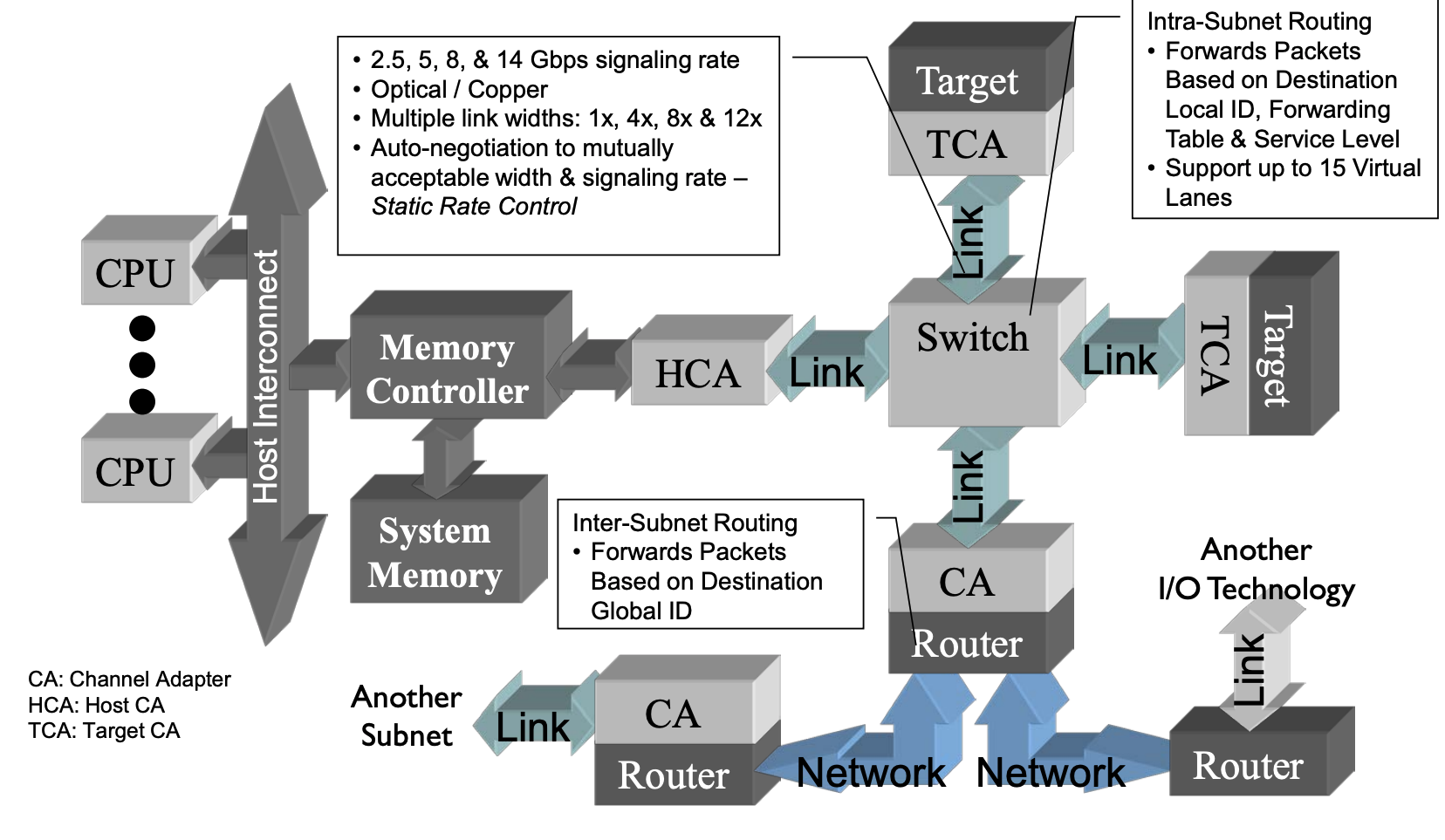
在一个子网中,必须有至少每个节点有一个 channel adapter,并且有一个 subnet manager 来管理 Link。
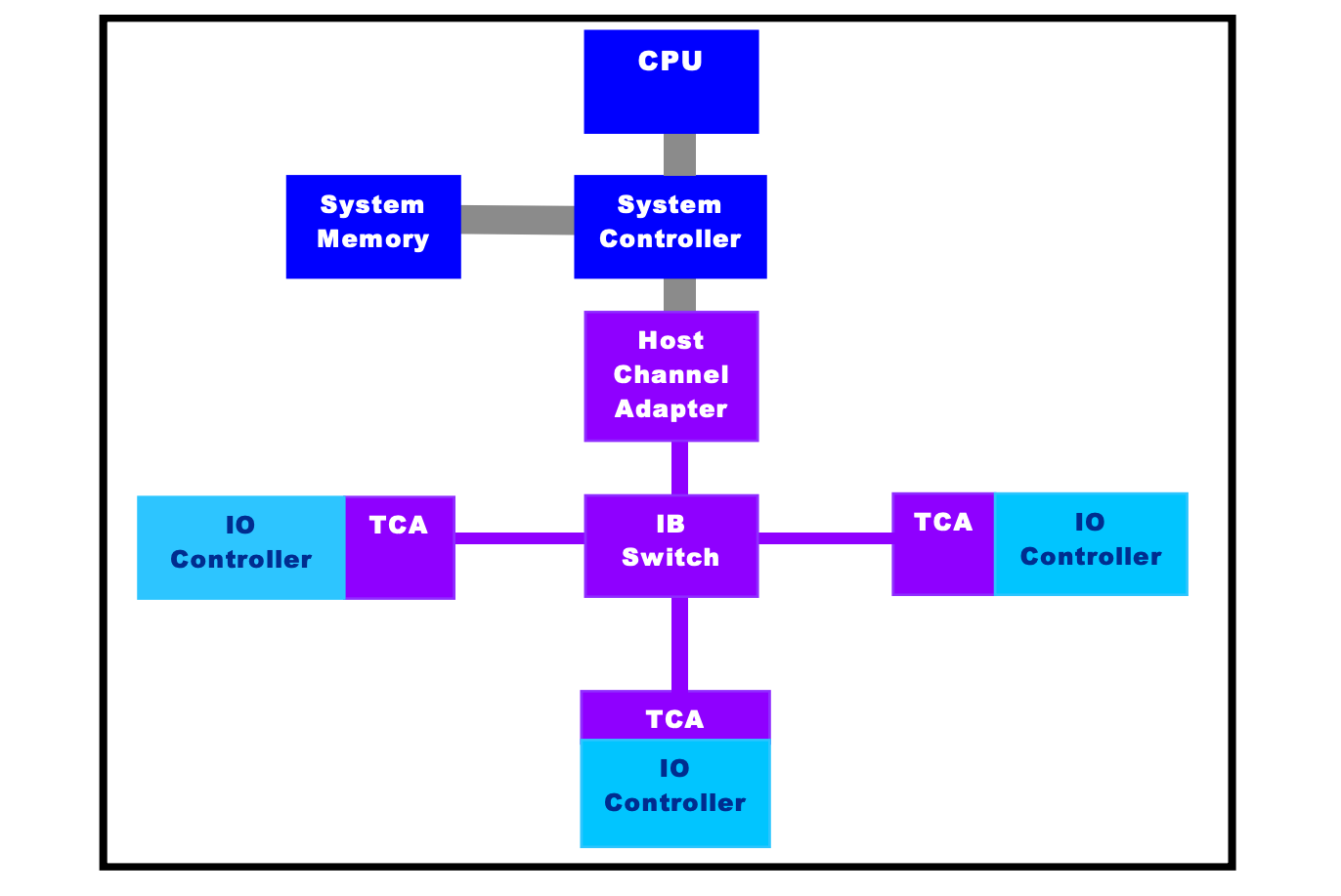
Channel Adapters
可安装在主机或者其他任何系统(如存储设备)上的网络适配器,这种组件为数据包的始发地或者目的地,支持 Infiniband 定义的所有软件 Verbs
- Host Channel Adapter:HCA
- Target Channel Adapter:TCA
Switch
Switch 包含多个 InfiniBand 端口,它根据每个数据包 LRH 里面的 LID,负责将一个端口上收到的数据包发送到另一个端口。除了 Management Packets,Switch 不产生或者消费任何 Packets。它包含有 Subnet Manager 配置的转发表,能够响应 Subnet Manager 的 Management Packets。
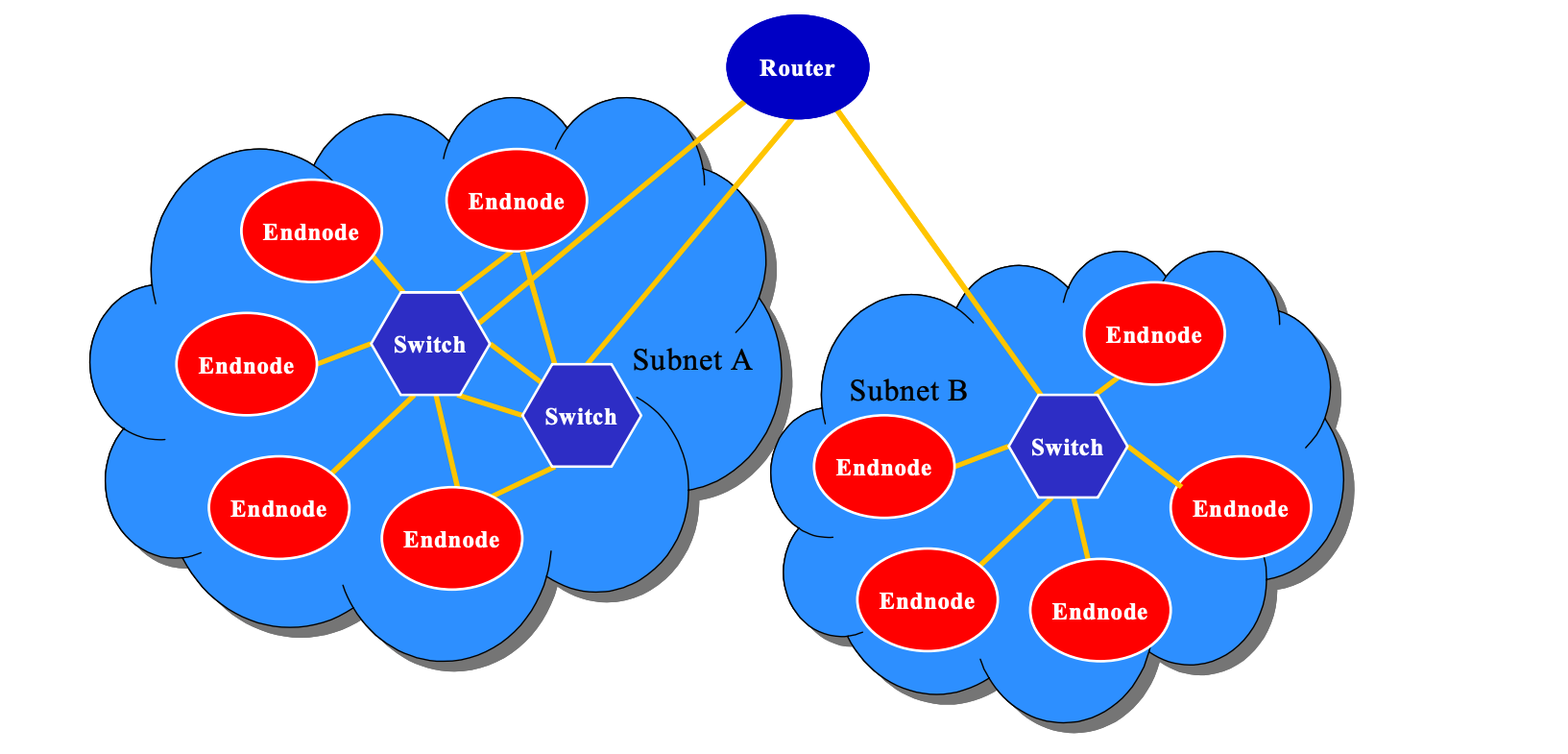
Router
Router 根据 L3 中的 GRH,负责将 Packet 从一个子网转发到另一个子网,当被转到到另一子网时,Router 会重建数据包中的 LID。
Subnet Manager
Subnet Manager 负责配置本地子网,使其保持工作:
- 发现子网的物理拓扑
- 给子网中的每个端口分配 LIC 和其他属性(如活动MTU、活动速度)
- 给子网交换机配置转发表
- 检测拓扑变化(如子网中节点的增删)
- 处理子网中的各种错误
分层设计
Infi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1632
1632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









