







Spark01
一. Spark概述

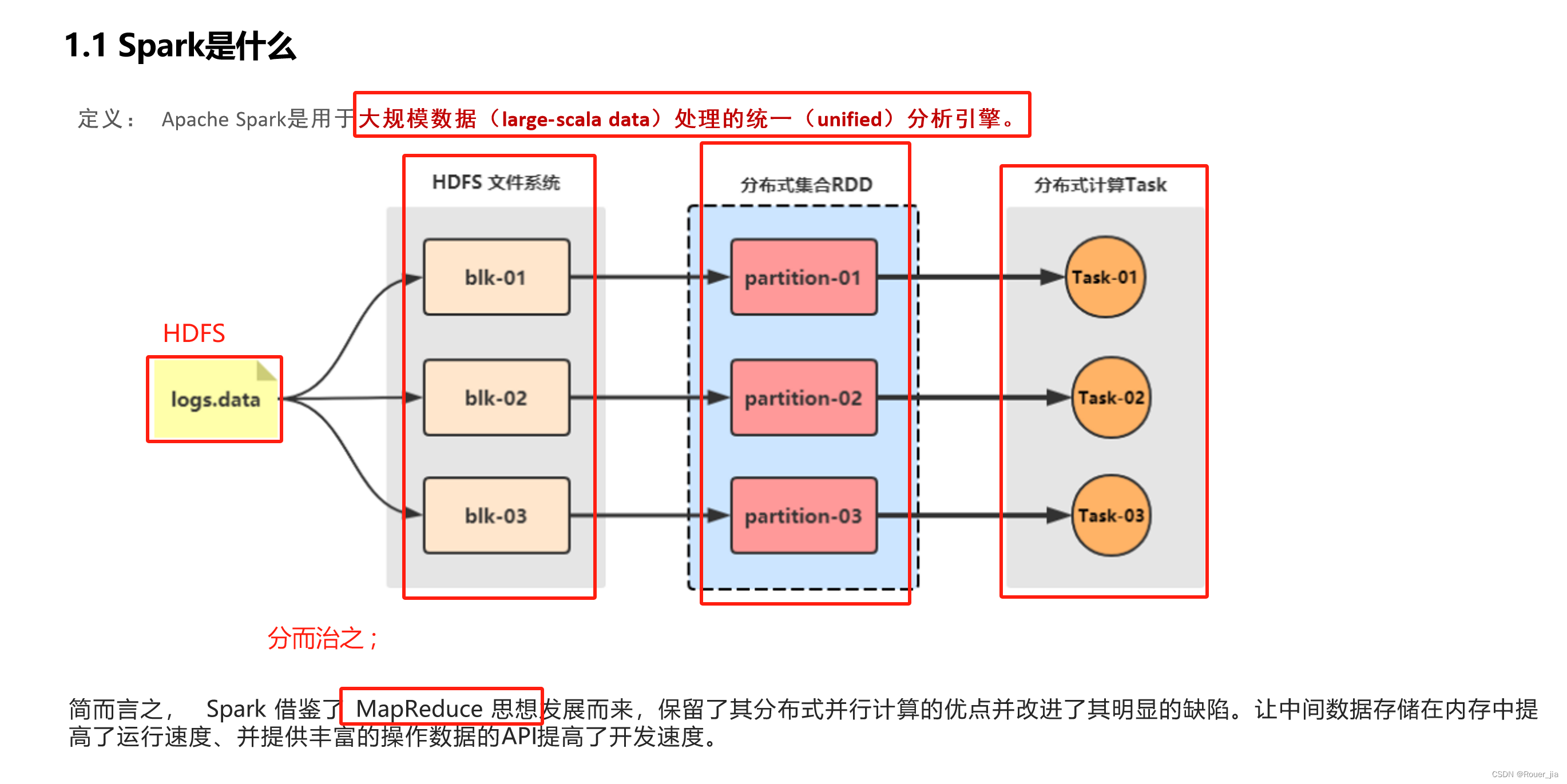
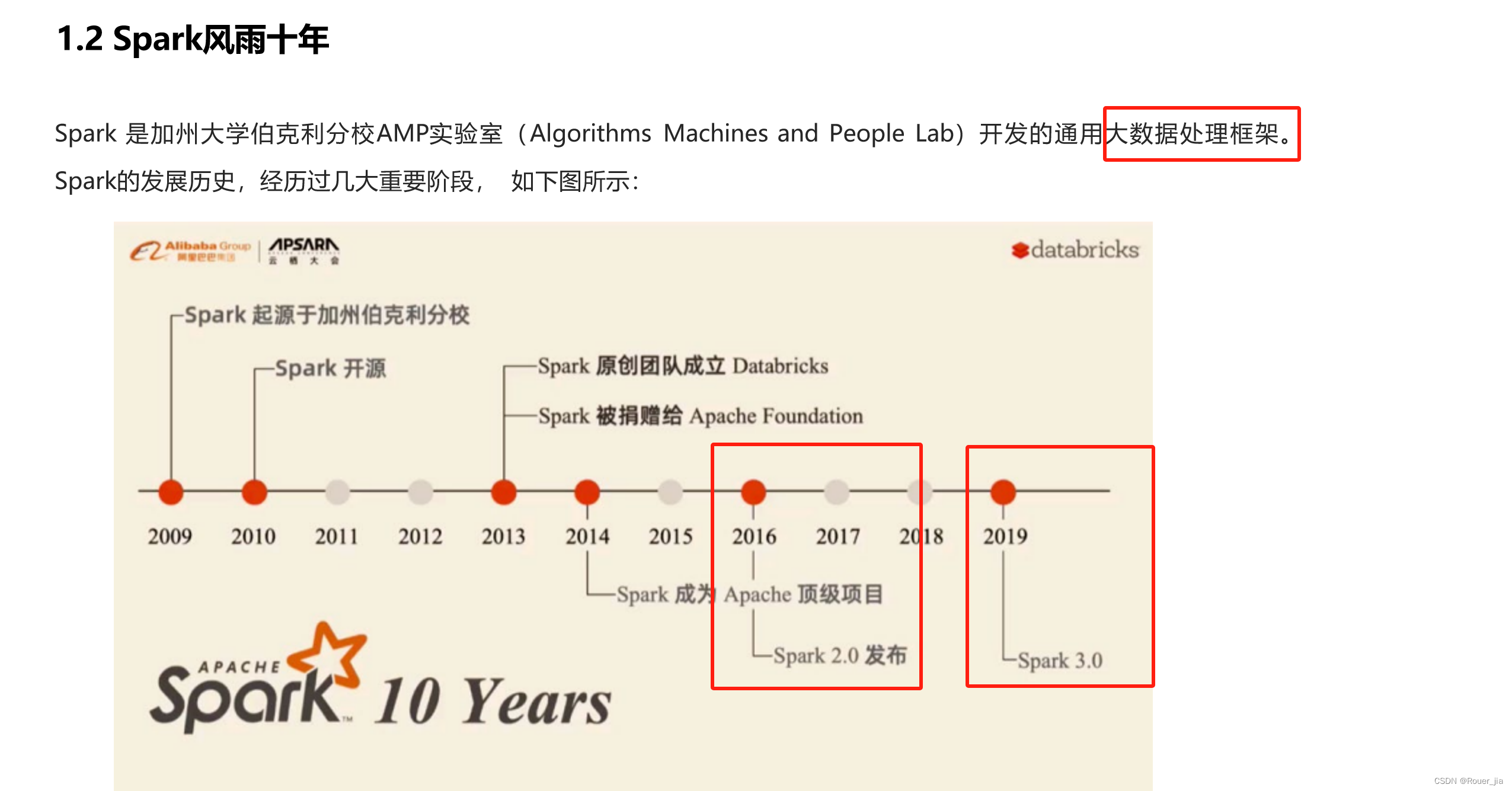
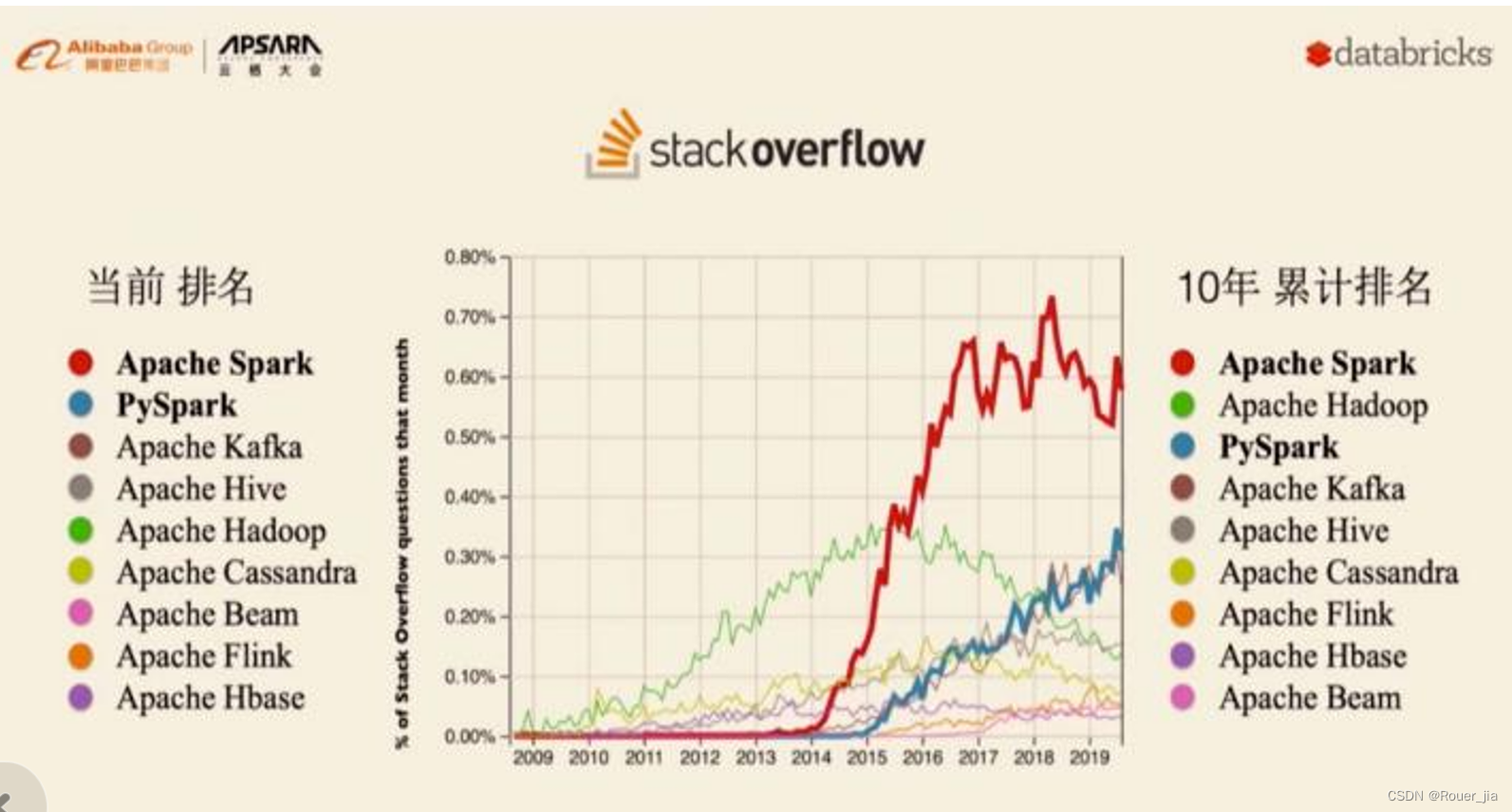
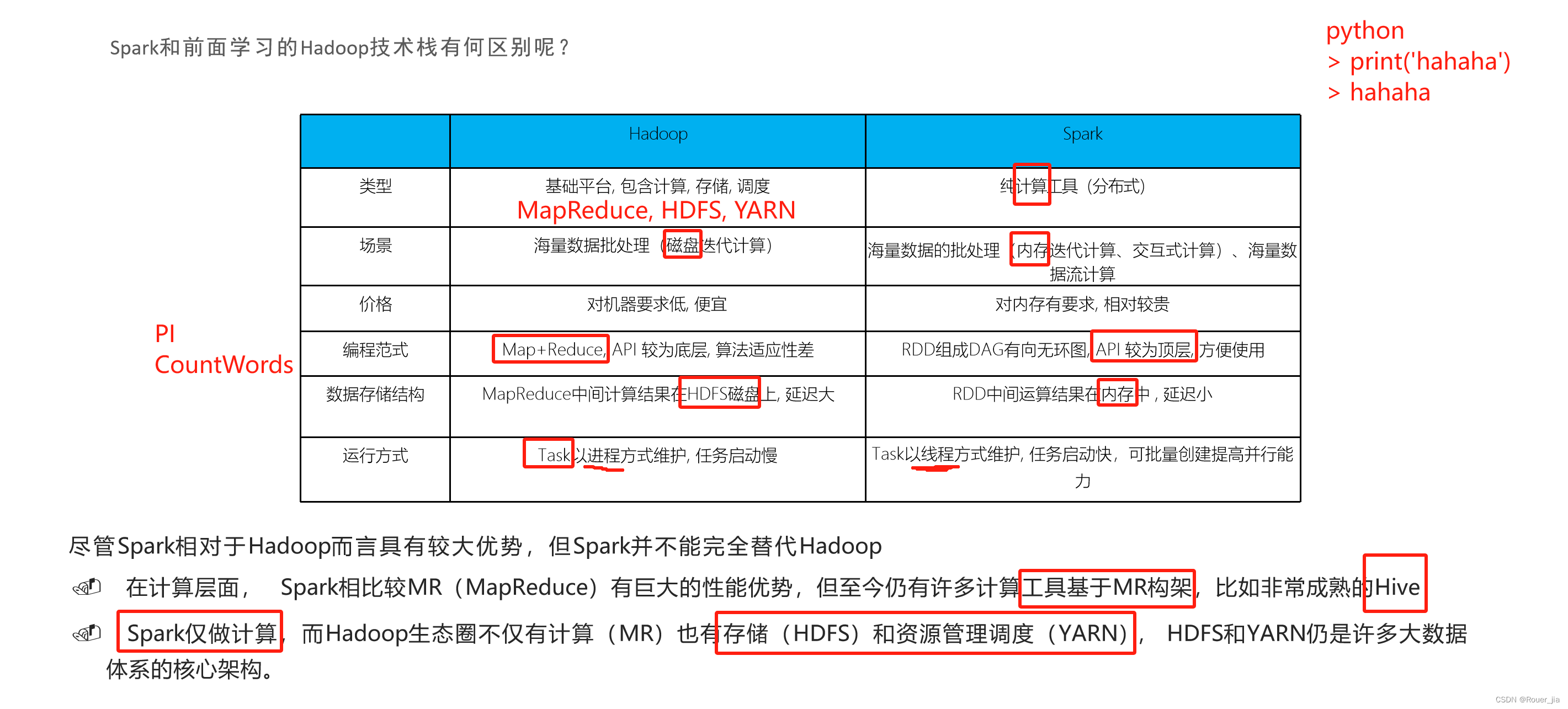


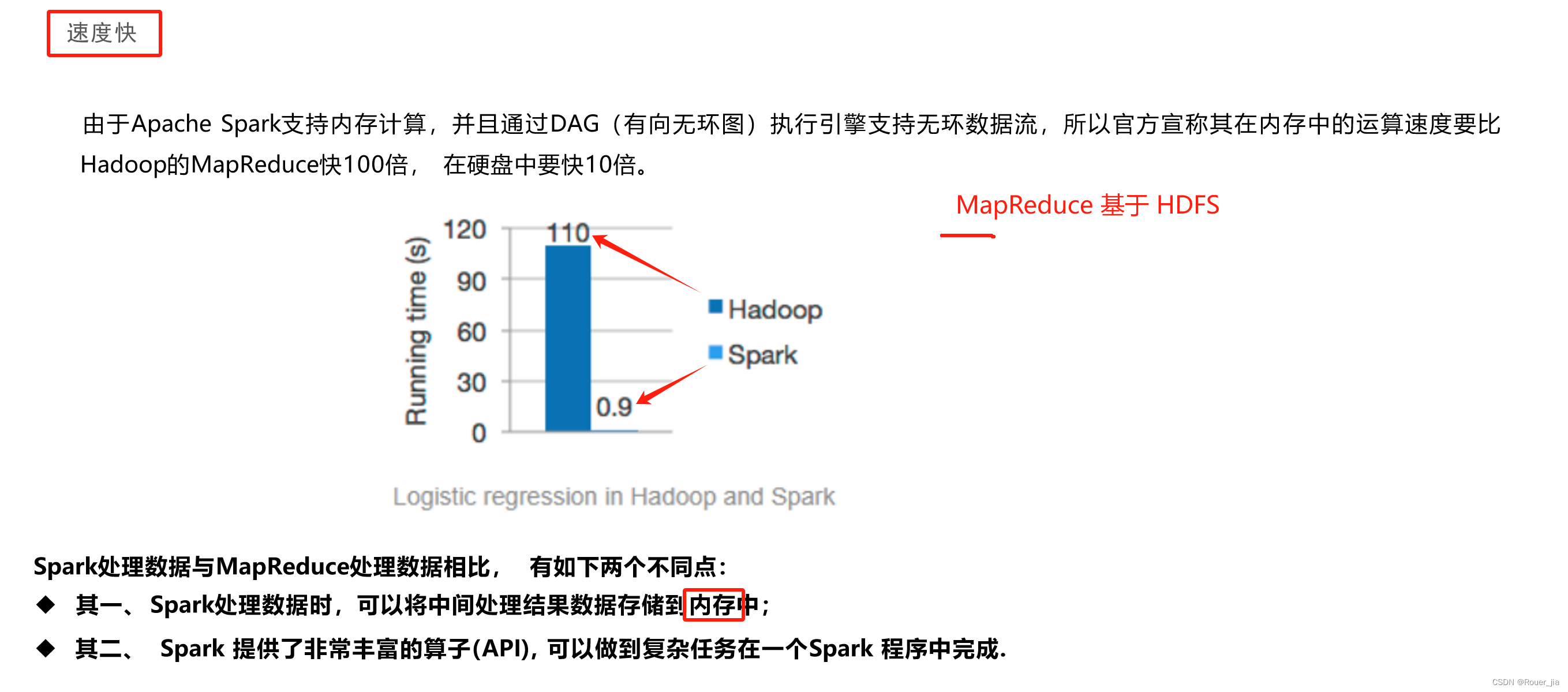

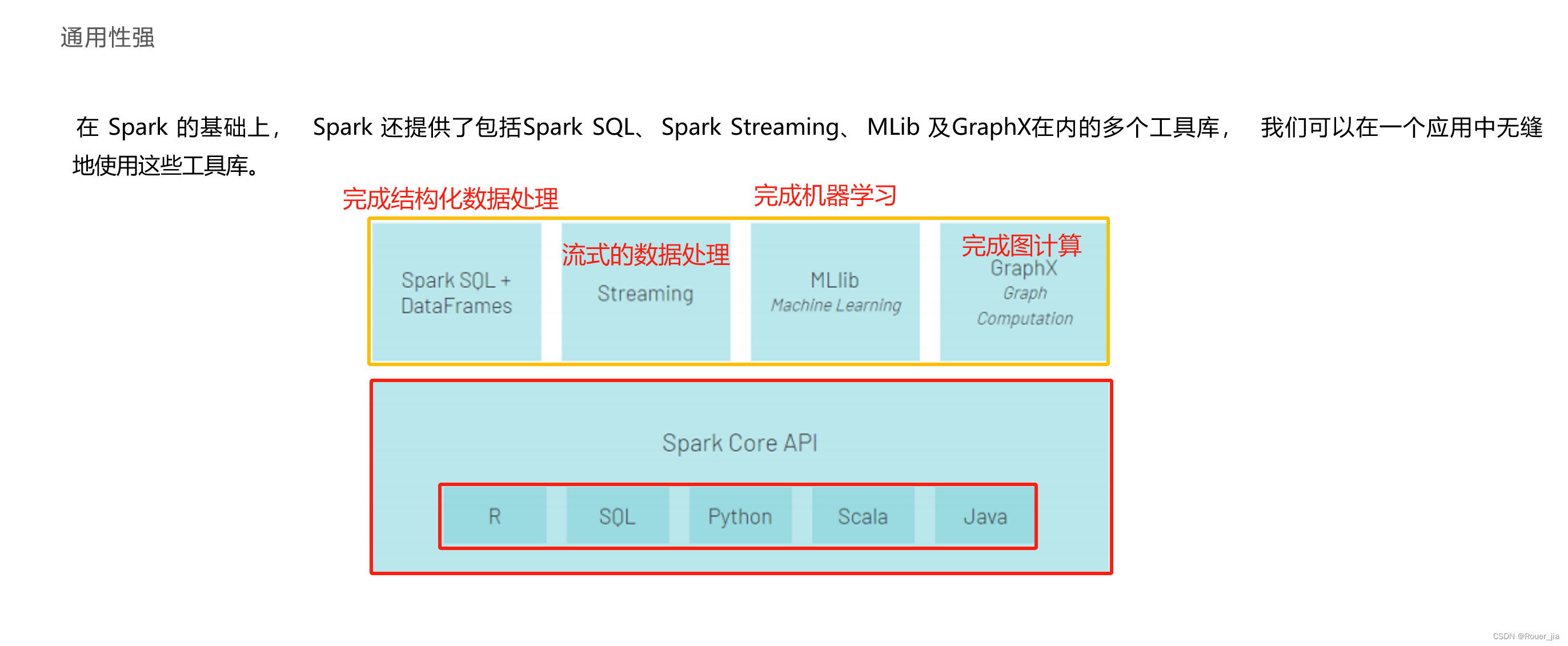
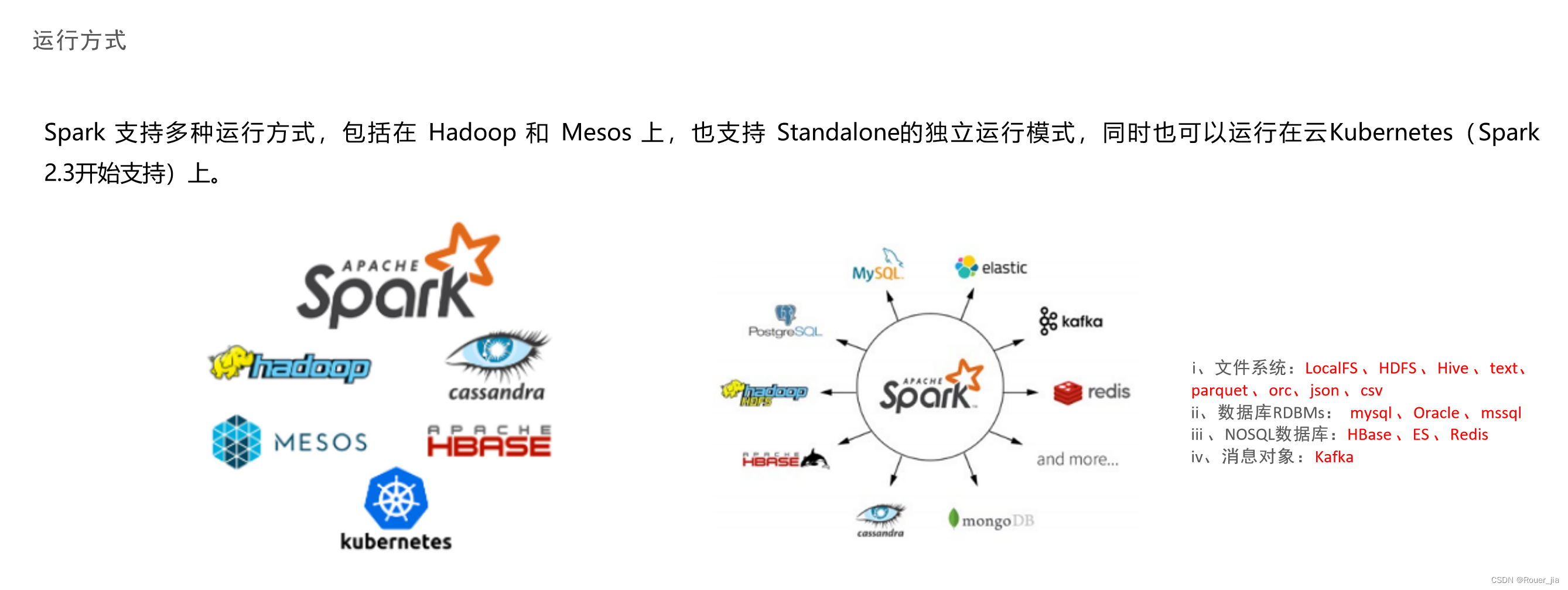
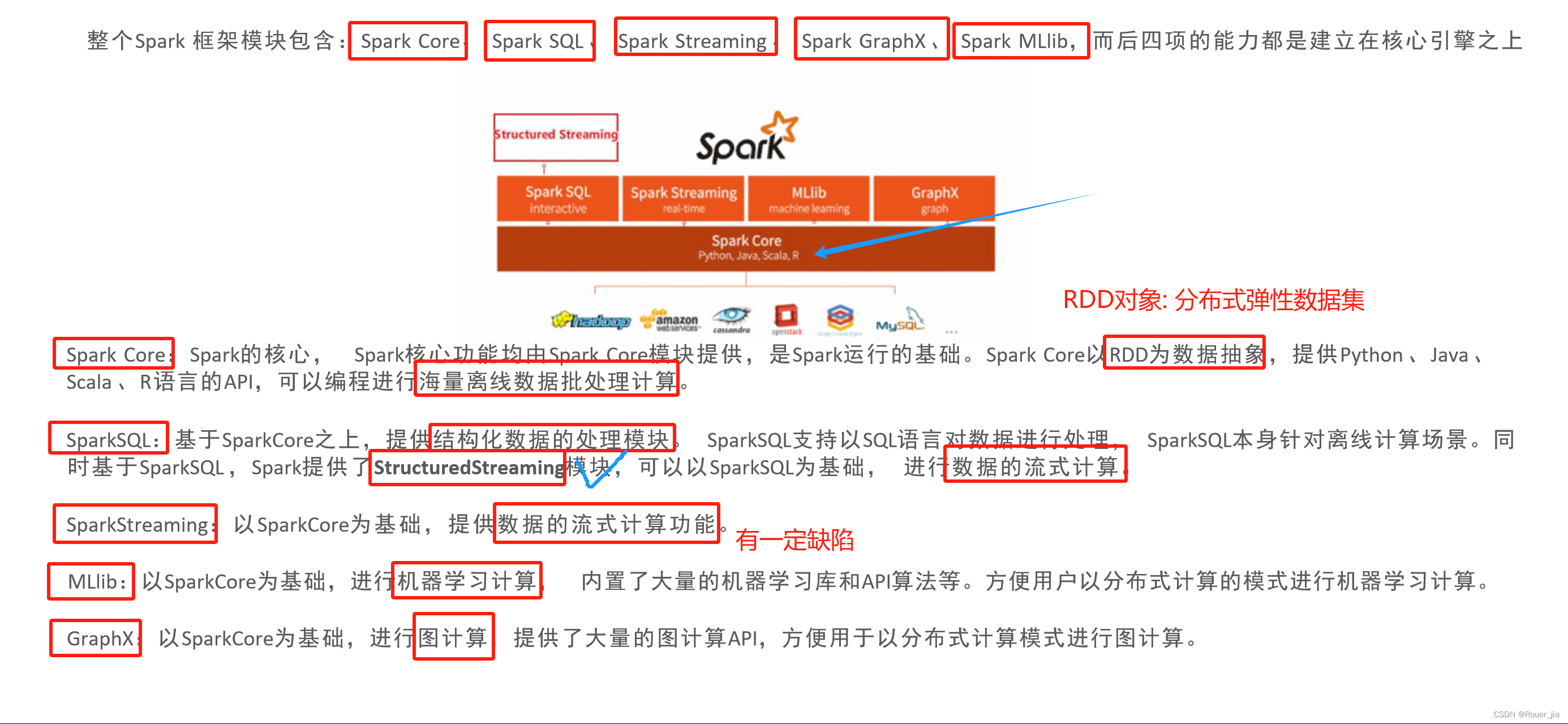
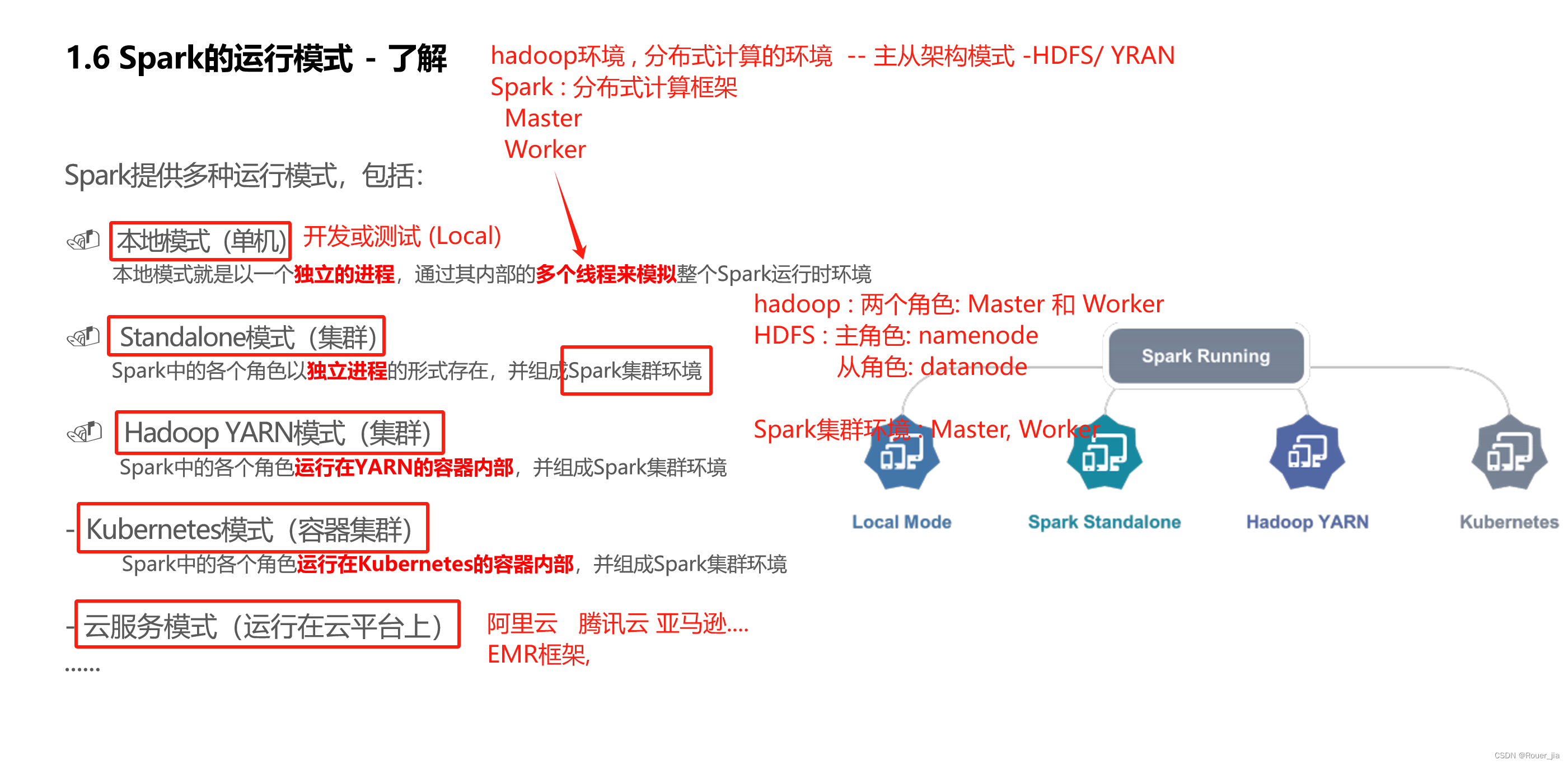
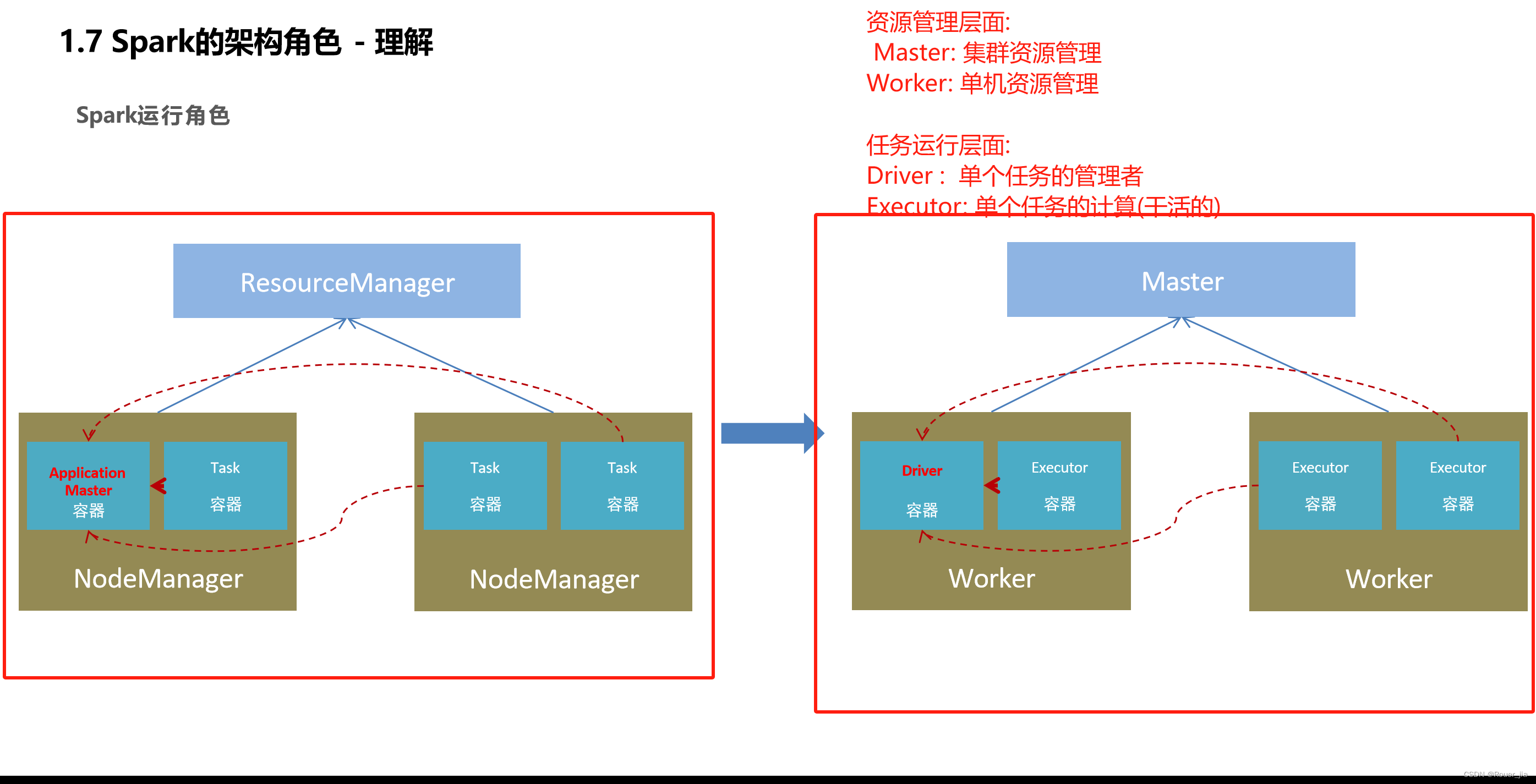
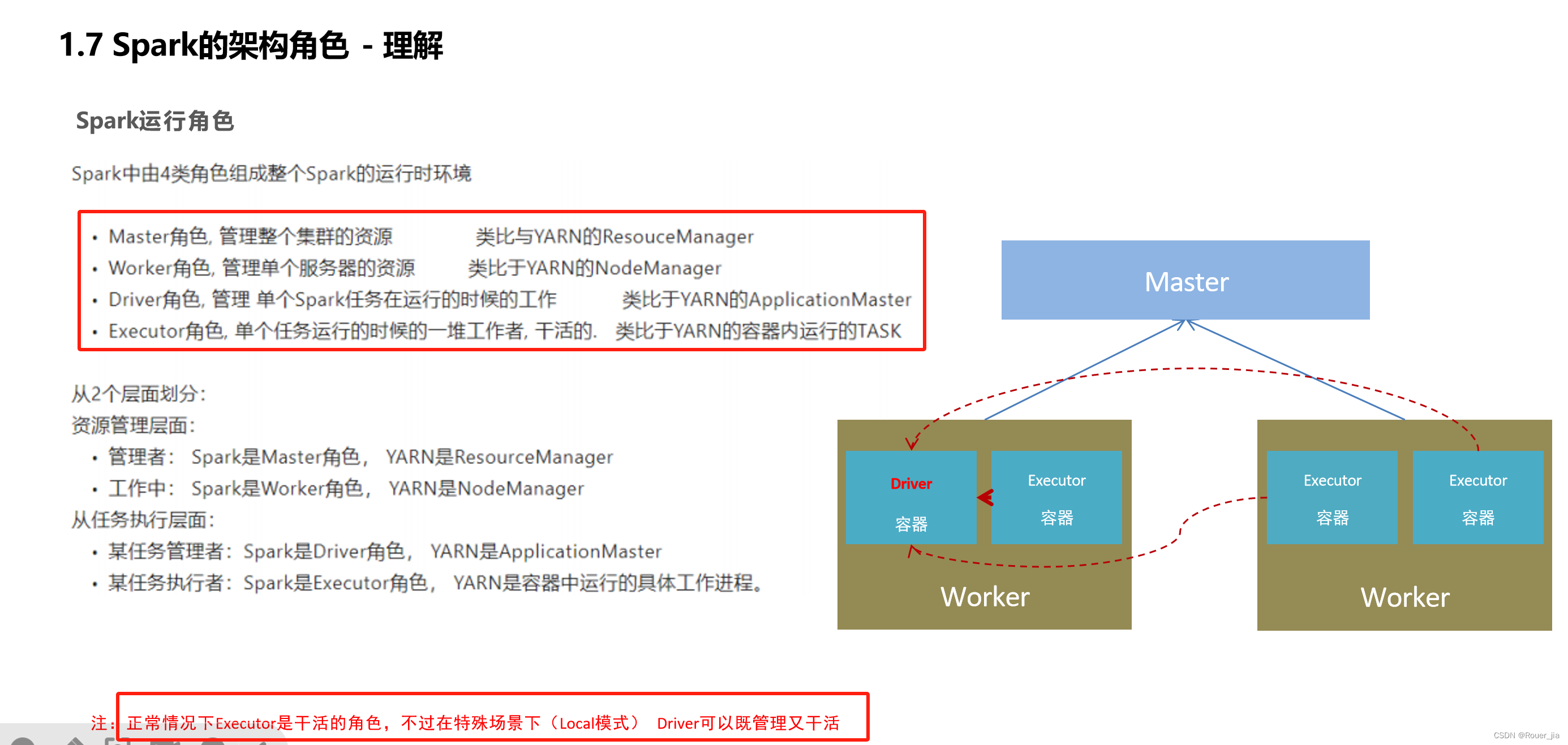
二. Spark环境部署 - Local
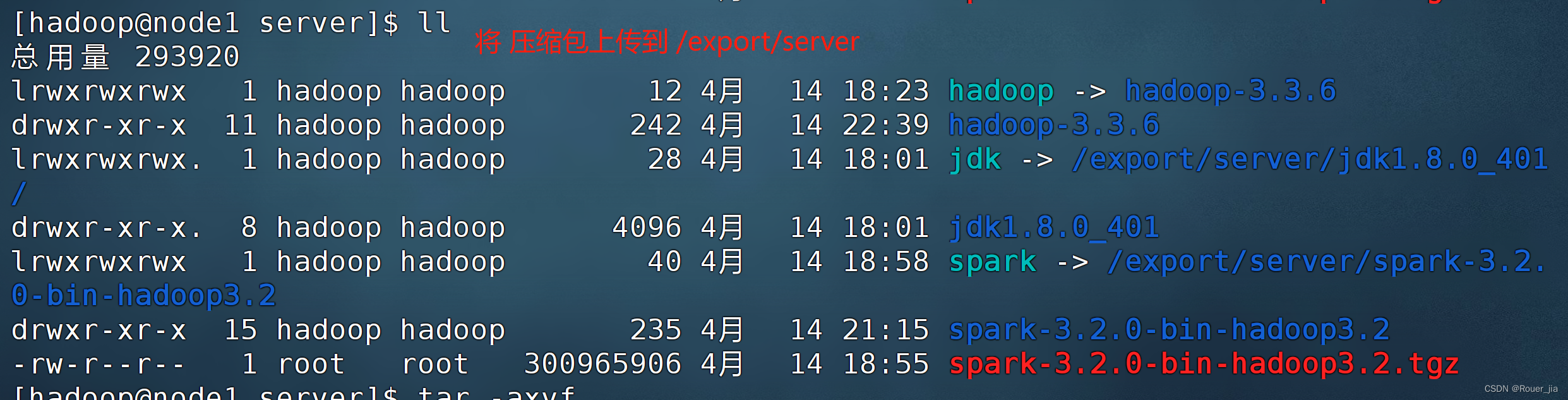
1. 上传压缩包
2. 解压缩

3. 修改用户权限 - hadoop

4. 构建软链接

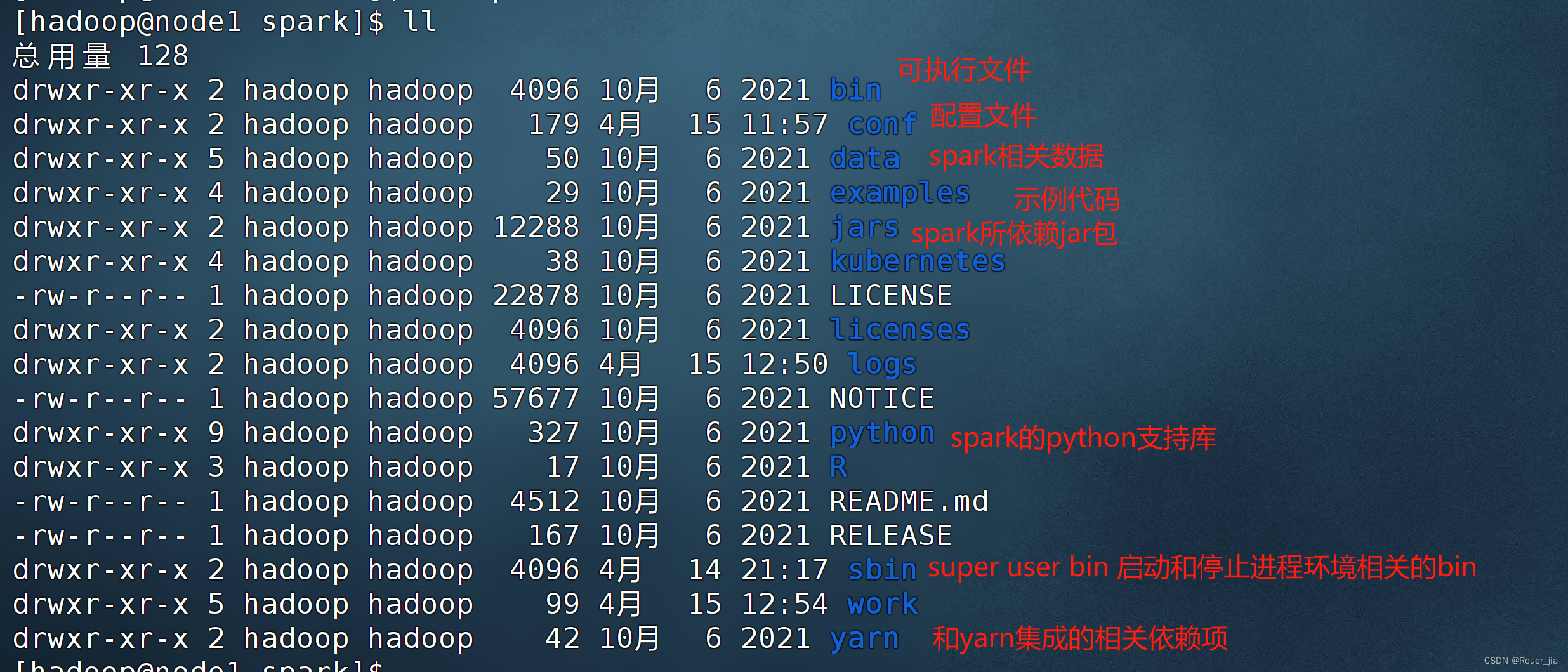
5.文件目录
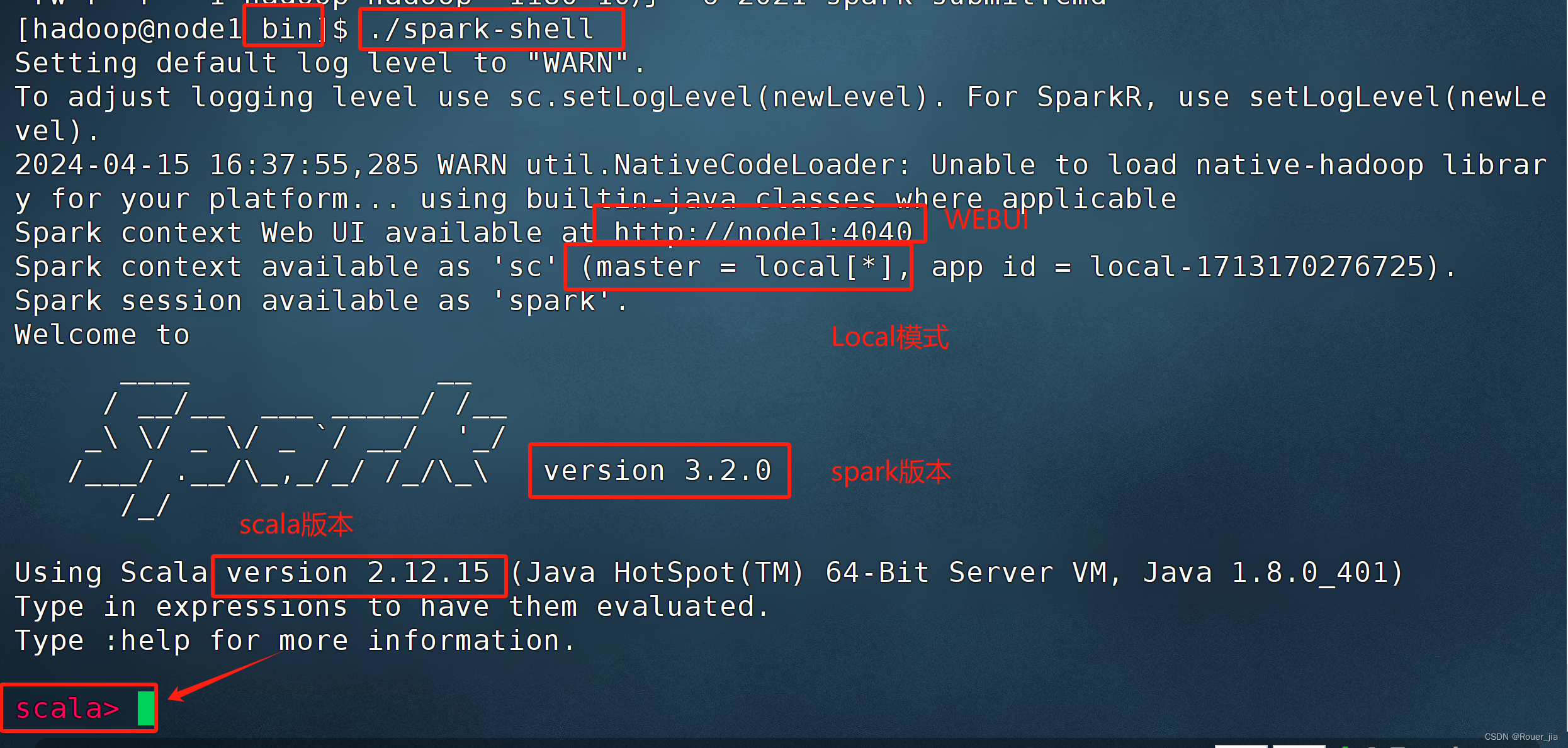
6. 启动spark-shell
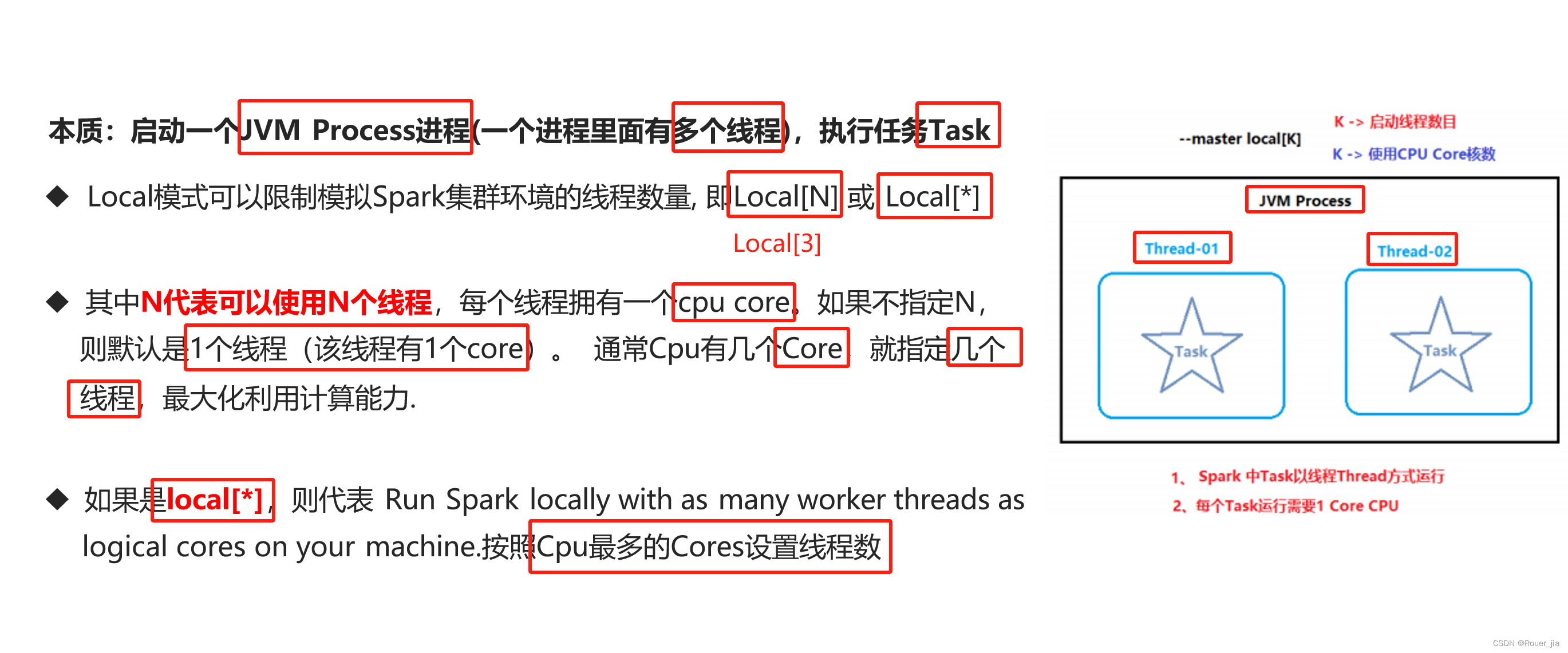

7. 测试

val textfile=sc.textFile("file:///home/hadoop/words.txt");
// val scala的声明,声明一个不可变的变量
// sc: SparkContext对象, 是Spark程序的入口,提供了连接Spark集群的方法,并且可以创建RDDs(弹性分布式数据集)
//textFile():SC对象提供的方法, 用来读取文本文件, 会将文件中的内容作为RDD[String]返回
/*textFile =
RDD[e are words]
RDD[e are words]
RDD[e are words]*/
val counts = textfile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
// flatMap(): 转换函数, 接收一个函数作为参数, 对RDD中的每个元素都应用这个函数
// 参数: '_.split(" ")' 使用空格作为分隔符将每行文本拆分成单词数组 [e are words e are words e are words]
// map(): 转换函数, 接收一个函数作为参数, 对RDD中的每个元素都应用这个函数
// (_,1): 匿名函数,
// reduceByKey(_+_)
//结果:
//Array[(String, Int)] = Array((are,2), (english,1), (e,1), (in,1), (more,1), (words,3), (these,1))
三. Spark环境部署 - Standalone
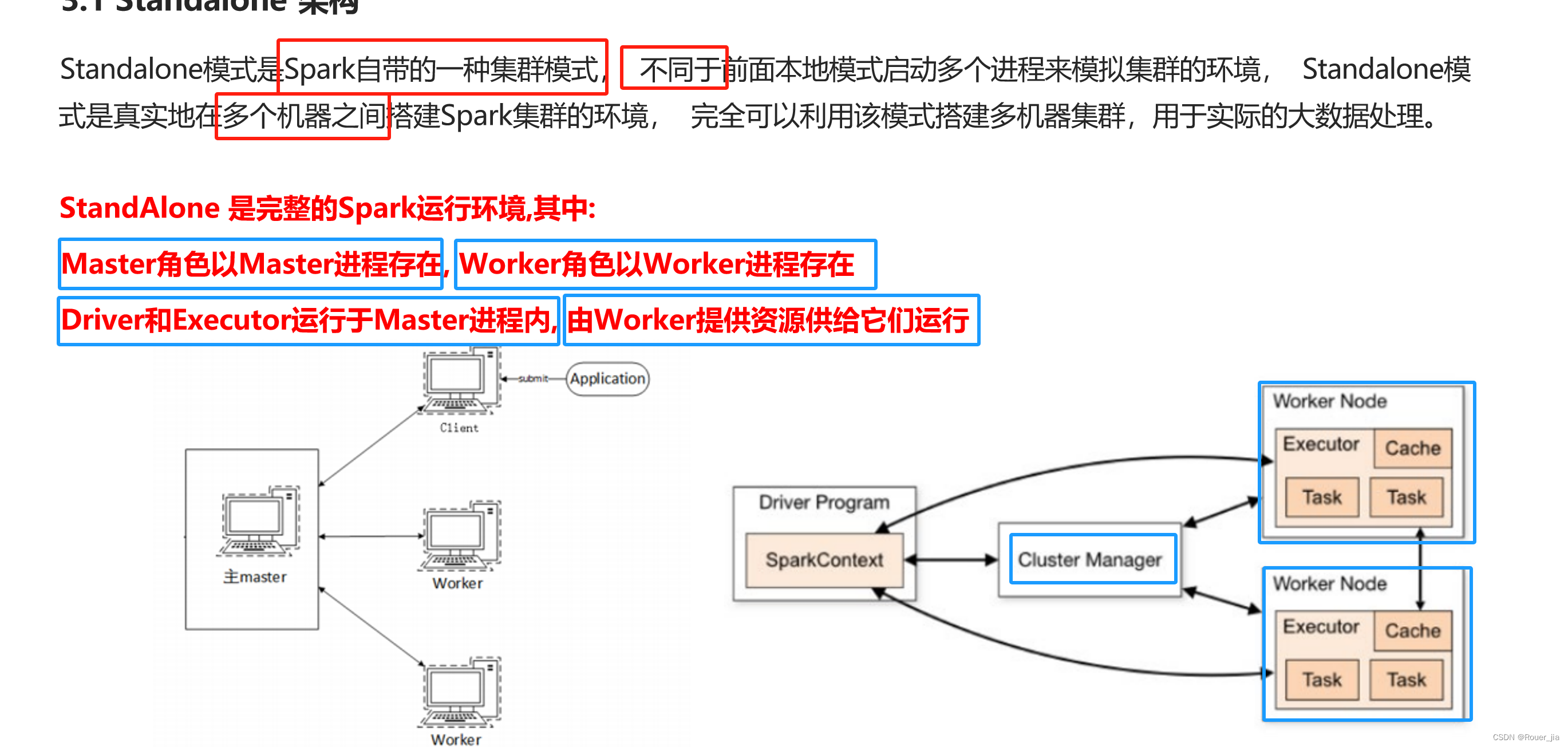
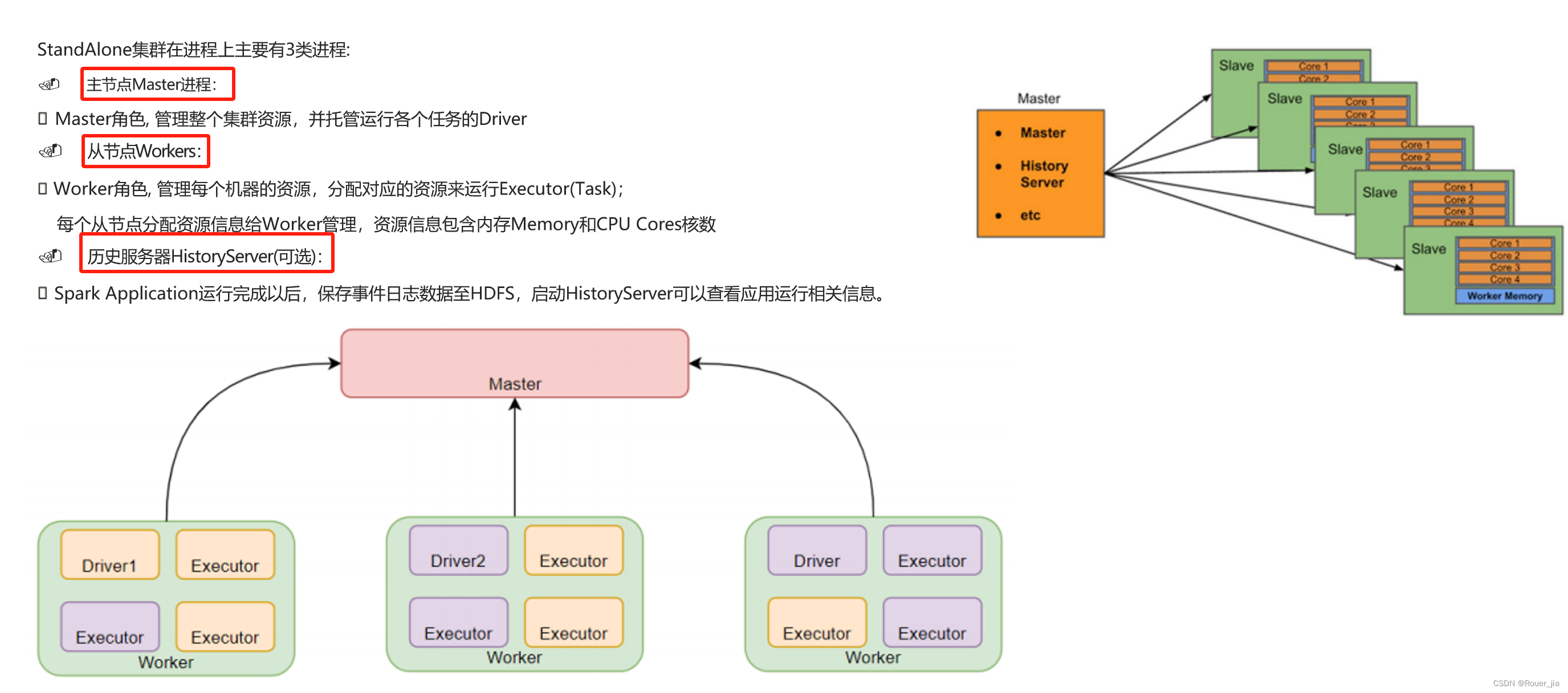
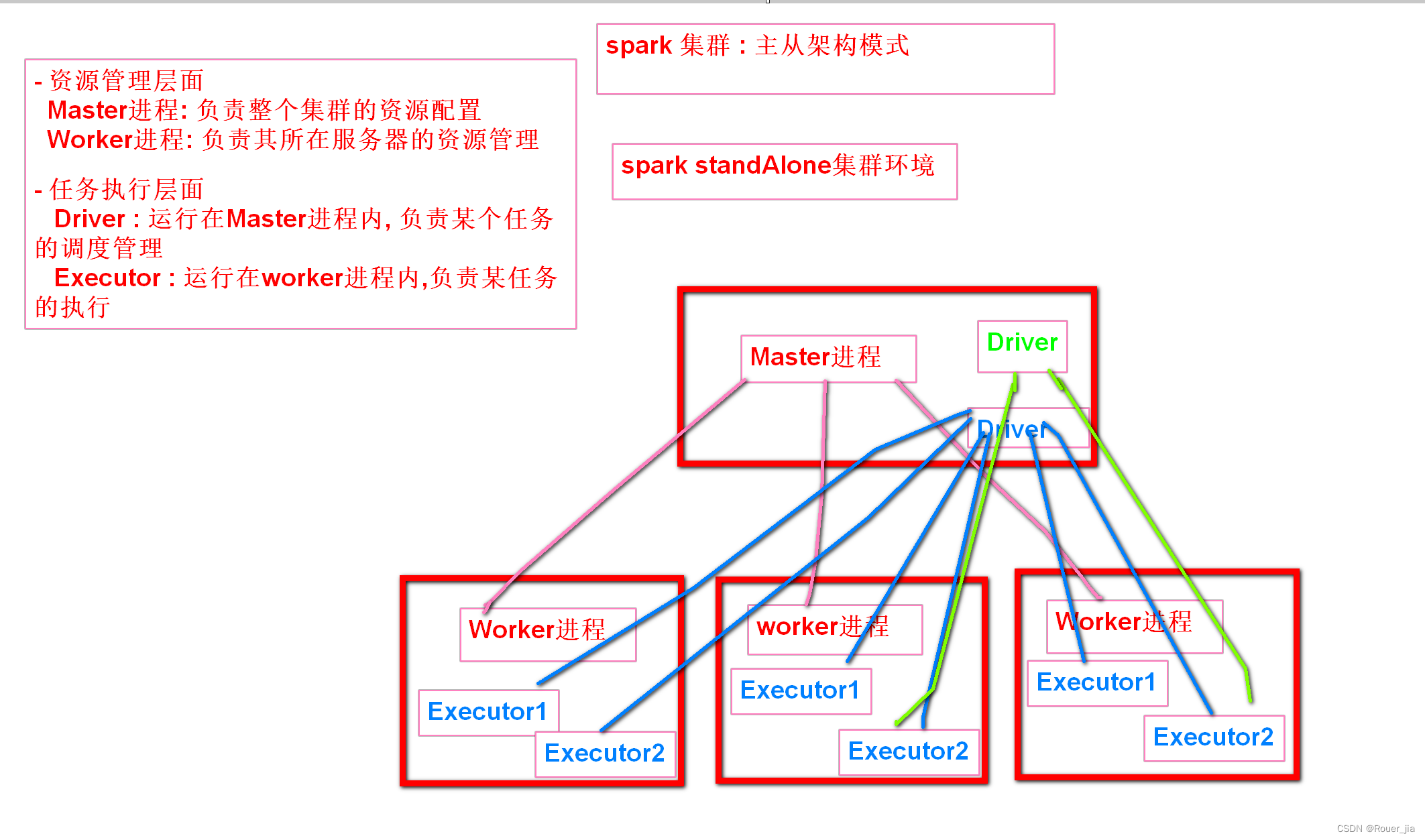
1. Standalone集群概述
2. Standalone环境部署
1. 集群规划
node1: Master /Worker
node2 : Worker
node3 : Worker
2. 配置workers
cd /export/server/spark/conf/workers
改名称
mv workers.template workers
vim workders
内容
node1
node2
node3
3. 配置Master - spark-env.sh
cd /export/server/conf/spark-env.sh
改名
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
内容
## 设置JAVA安装目录
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
# 注意, 上面的配置的路径 要根据你自己机器实际的路径来写
在HDFS下创建历史运行记录文件sparklog
hadoop fs -mkdir /sparklog
hadoop fs -ls /
hadoop fs -chmod 777 /sparklog
4.分发
scp -r spark-3.2.0-bin-hadoop3.2/ hadoop@node2:`pwd`
scp -r spark-3.2.0-bin-hadoop3.2/ hadoop@node3:`pwd`
5. 构建软连接
node2: ln -s /export/server/spark-3.2.0-bin-hadoop3.2/ spark
node3: ln -s /export/server/spark-3.2.0-bin-hadoop3.2/ spark
3. 测试环境
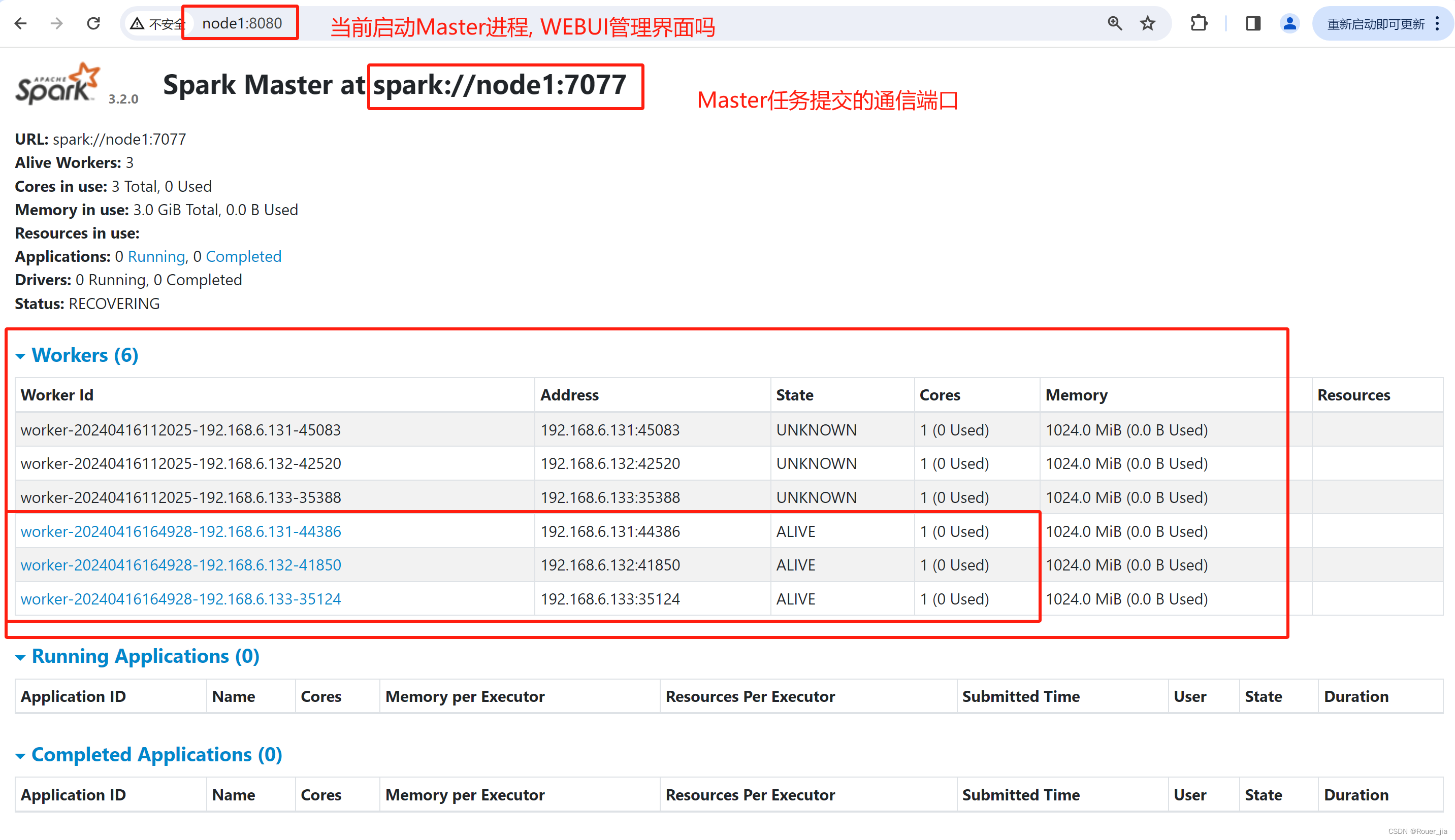
1. 启动Master进程
集群的启动和停止
在主节点上启动spark集群
/export/server/spark/sbin/start-all.sh
在主节点上停止spark集群
/export/server/spark/sbin/stop-all.sh
在主节点上单独启动和停止master
start-master.sh
stop-master.sh
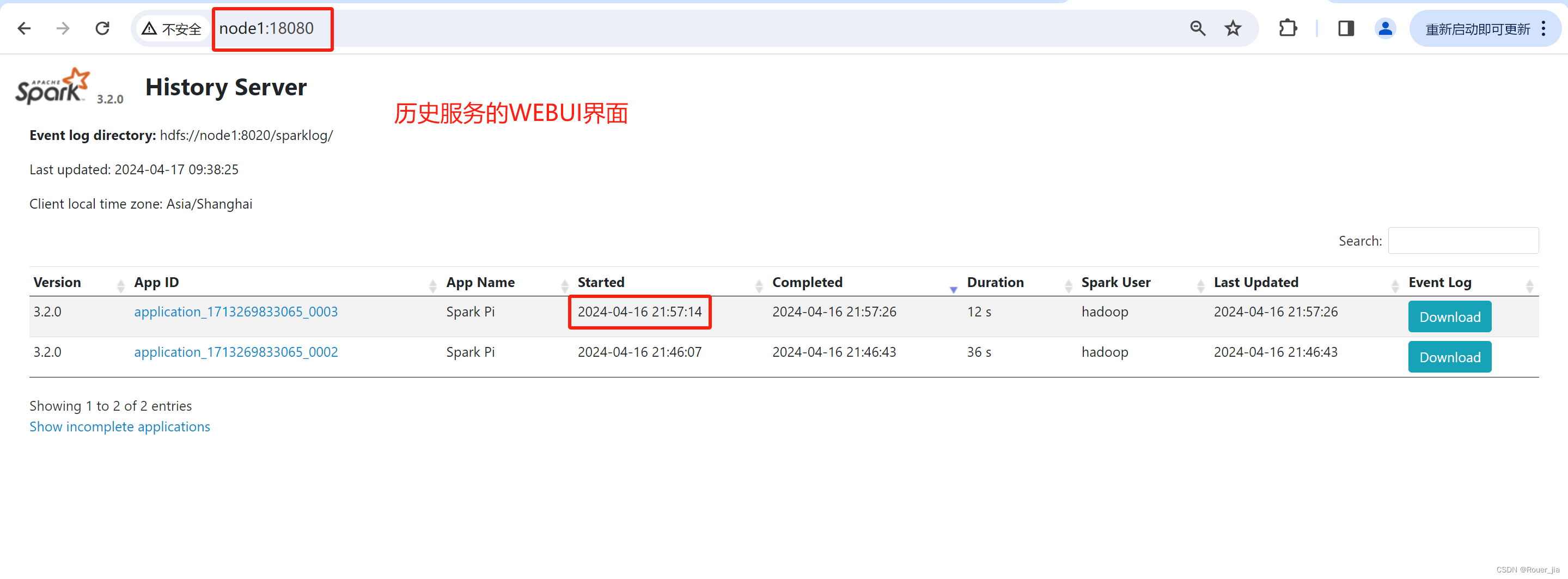
2. 启动spark-shell
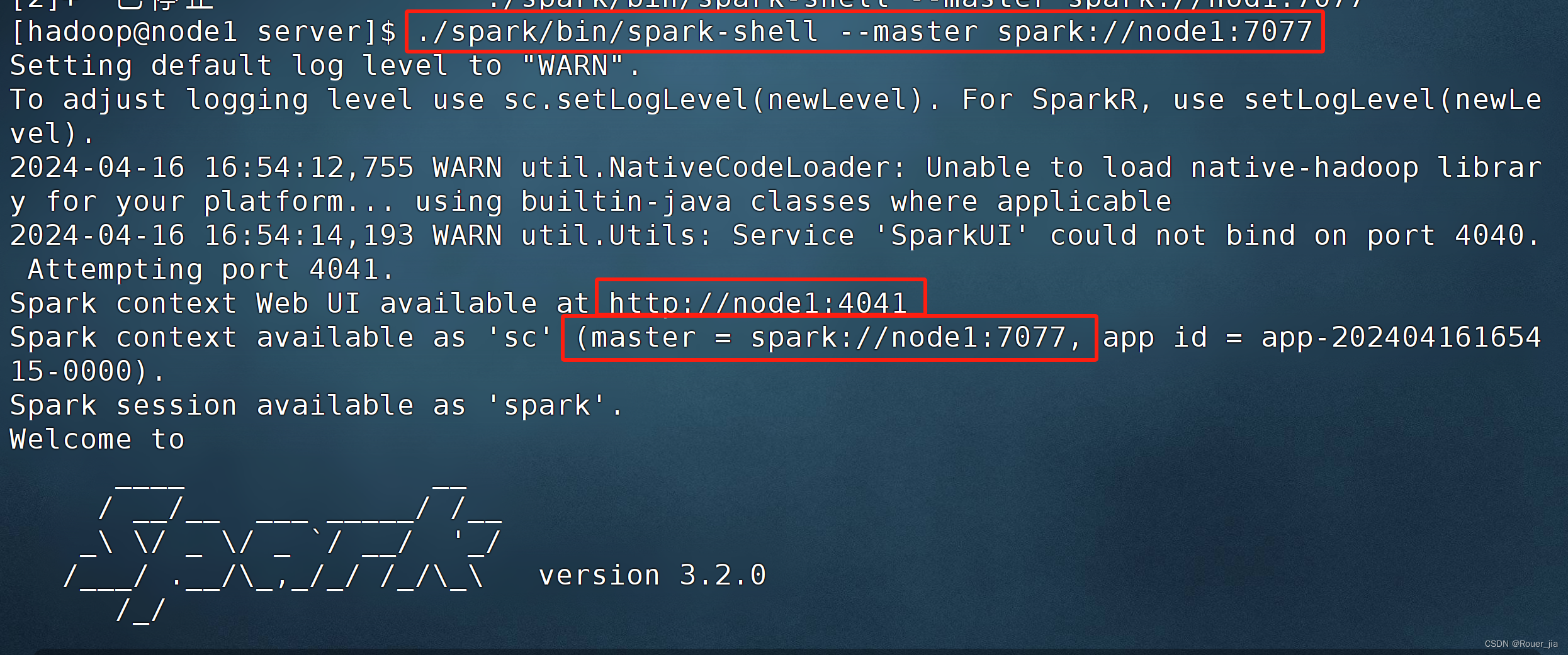
3. 测试
提交 WordCounts任务到Spark集群中
node1 : Master+Worker
node2 : worker
node3 : worker
上传文件到HDFS,方便读取words.txt文件(考虑到node2和node3没有word.txt)
hadoop fs -put /home/hadoop/words.txt /wordcount/input/words.txt
在HDFS创建
hadoop fs -mkdir -p /wordcount/input
查看是否上传成功
hadoop fs -ls /wordcount/input
val textfile = sc.textFile("hdfs://node1:8020/words.txt")
val count = textfile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
count.collect()
count.saveAsTextFile("hdfs://node1:8020/wordcount/output00")

四. Spark环境部署 - Standalone-HA
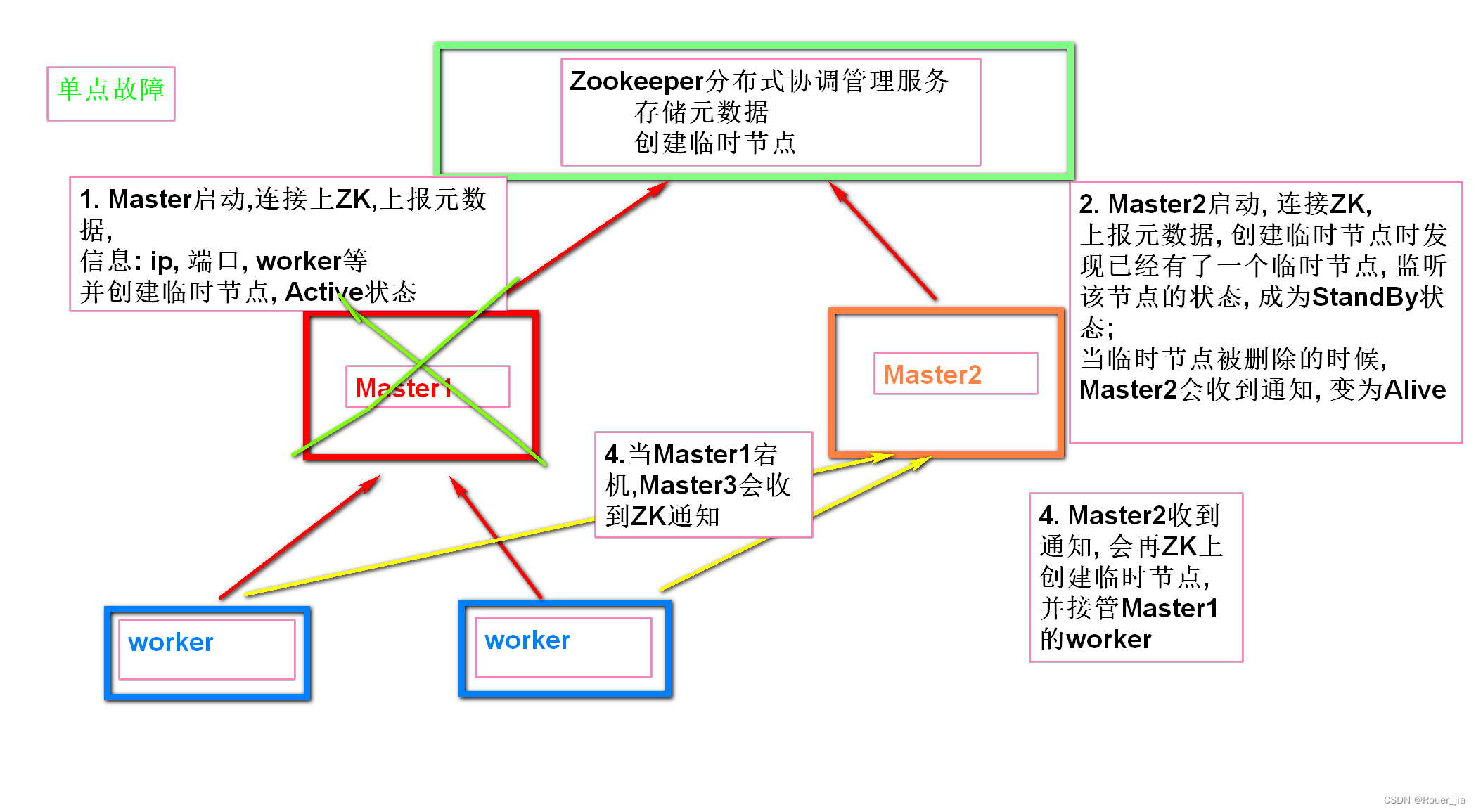
1. 安装部署Zookeeper
1. 前期准备
cd /export/server
// 解压缩
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /export/server
// 构建软链接
ln -s apache-zookeeper-3.5.9-bin zookeeper
// 查看是否成功
ll
// 删除Zookeeper的压缩包
rm -rf apache-zookeeper-3.5.9-bin.tar.gz
1. 下载
https://archive.apache.org/dist/zookeeper/
2. zookeeper安装
- zookeeper解压
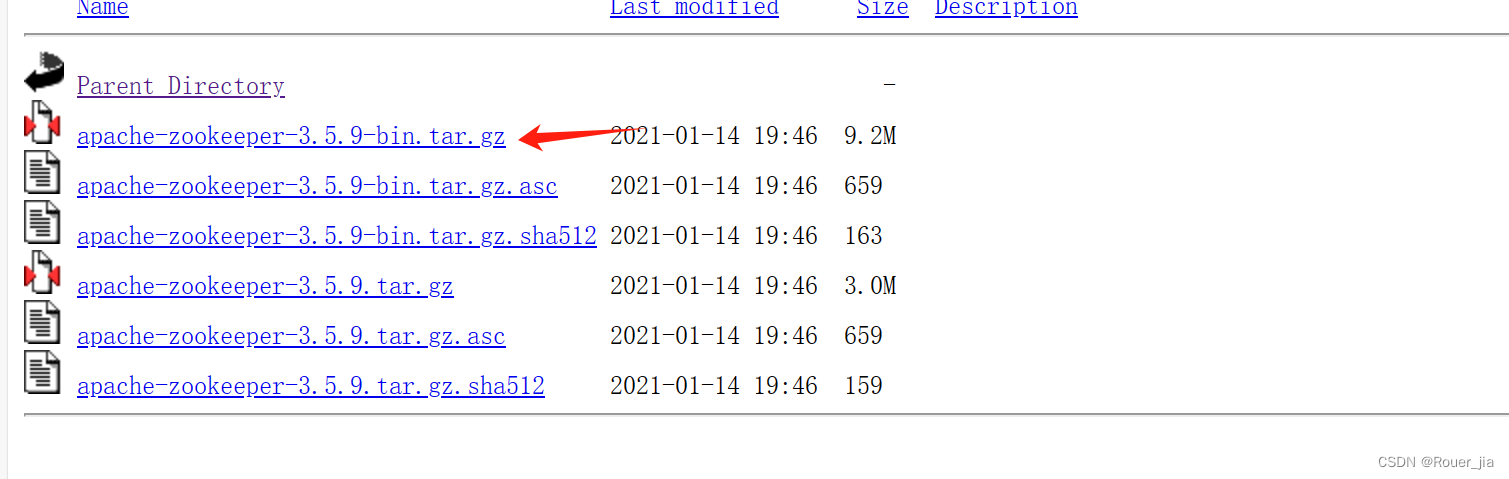
首先将下载的 apache-zookeeper-3.5.9-bin.tar.gz 上传到服务器
解压安装至 /export/server目录下
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /export/server
ln -s apache-zookeeper-3.5.9-bin zookeeper
2.zookeeper配置文件介绍
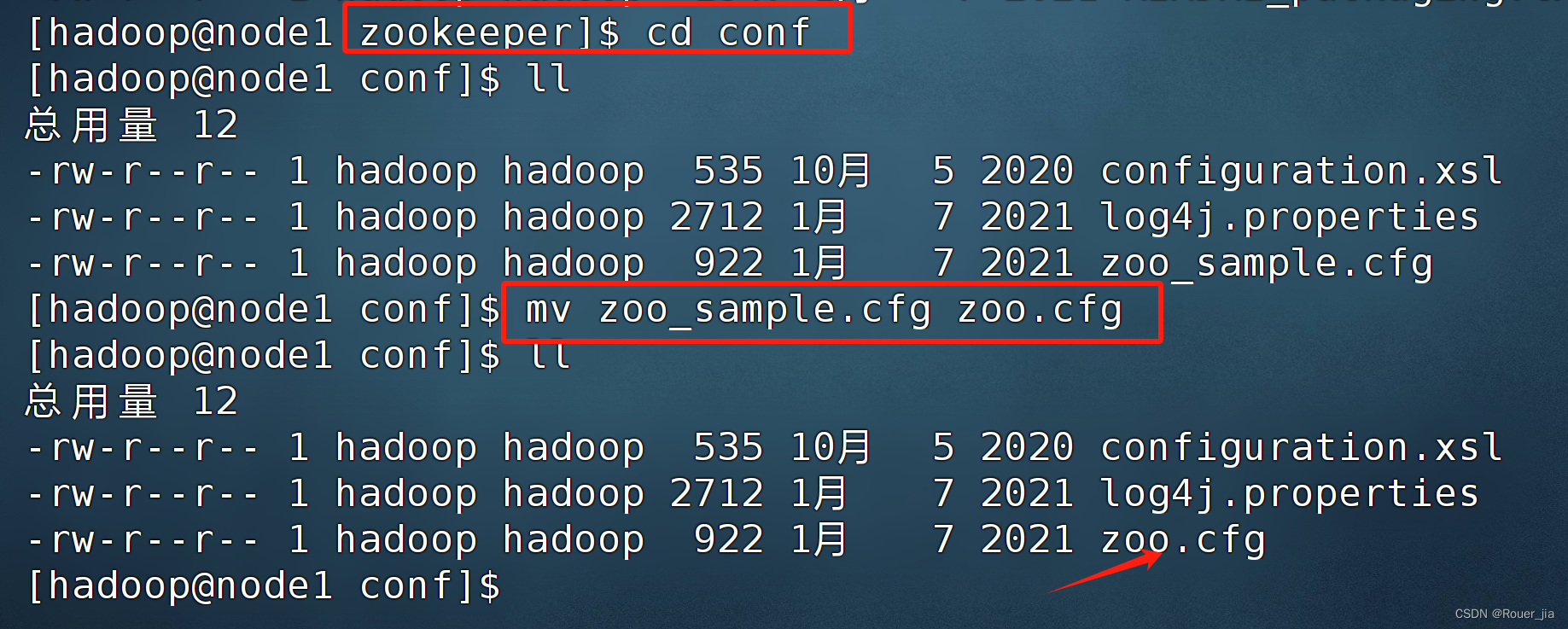
进入 zookeeper 配置文件 /export/server/zookeeper/conf/
给 zoo_sample.cfg 配置文件重命名为 zoo.cfg
配置文件介绍
# The number of milliseconds of each tick
# 用于计算基础的实际单位
# 设置tickTime,基本时间单位(毫秒),用于控制ZooKeeper的心跳间隔等参数
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# 初始化时间
# 初始化连接超时时间,单位是tickTime的倍数
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# 选举时间
# 跟随者与领导者之间同步的最大心跳数,单位是tickTime的倍数
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 配置zookeeper数据存放路径
# 指定数据目录,用于存储ZooKeeper的数据
dataDir=/export/server/zookeeper/data
dataLogDir=/export/server/zookeeper/logs
# the port at which the clients will connect
# 客户端连接端口,默认是2181
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
首先 zookeeper 目录下创建 zookeeper 数据和日志的存放目录,并且添加文件读写权限
mkdir data
chmod 777 data
mkdir logs
chmod 777 logs
集群配置
集群配置 2888:选举端口 3888:投票端口
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.1=B:C:D
- A是一个数字, 表示这个是第几号服务器
集群模式下配置一个文件 myid,这个文件在 data,目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。- B是这个服务器的地址;
- C是这个服务器Follower 与集群中的 Leader 服务器交换信息的端口;←
- D是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口

后两台机器分别写入 2、3
echo "2" > myid
echo "3" > myid
修改环境变量-切换为root用户
export ZOOKEEPER_HOME=/export/server/zookeeper
export PATH=$PATH:$ZOOKEEPR_HOME/bin
source /etc/profile
分发
scp -r apache-zookeeper-3.5.9-bin/ hadoop@node2:$PWD
scp -r apache-zookeeper-3.5.9-bin/ hadoop@node3:$PWD
启动Zookeeper
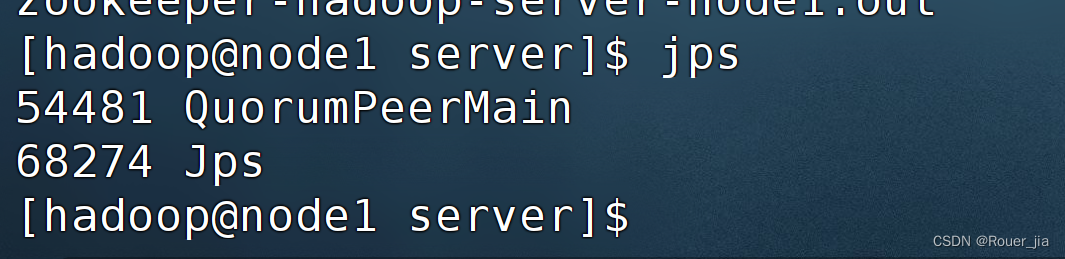

3. 配置StandAlone-HA集群
前提: 确保Zookeeper 和 HDFS 均已经启动
先在spark-env.sh中, 删除或者注释: SPARK_MASTER_HOST=node1
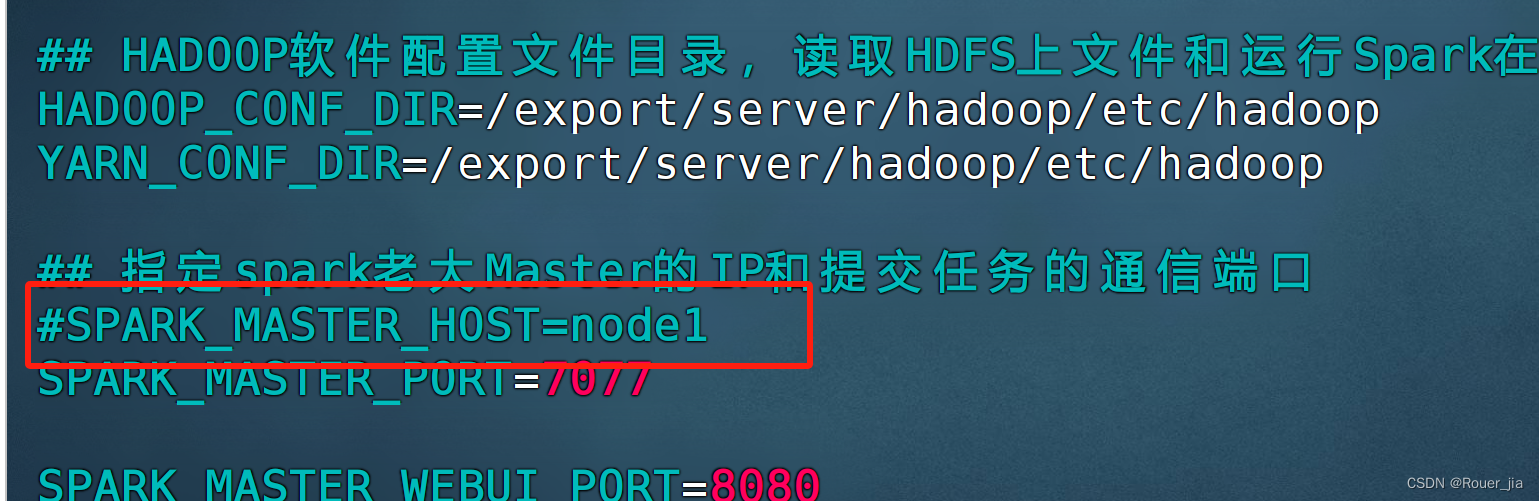
原因: 配置文件中固定master是谁, 那么就无法用到zk的动态切换master功能了.
在spark-env.sh中, 增加:
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
# spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现
# 指定Zookeeper的连接地址
# 指定在Zookeeper中注册临时节点的路径

将spark-env.sh 分发到每一台服务器上
scp spark-env.sh node2:/export/server/spark/conf/
scp spark-env.sh node3:/export/server/spark/conf/

停止当前StandAlone集群
sbin/stop-all.sh
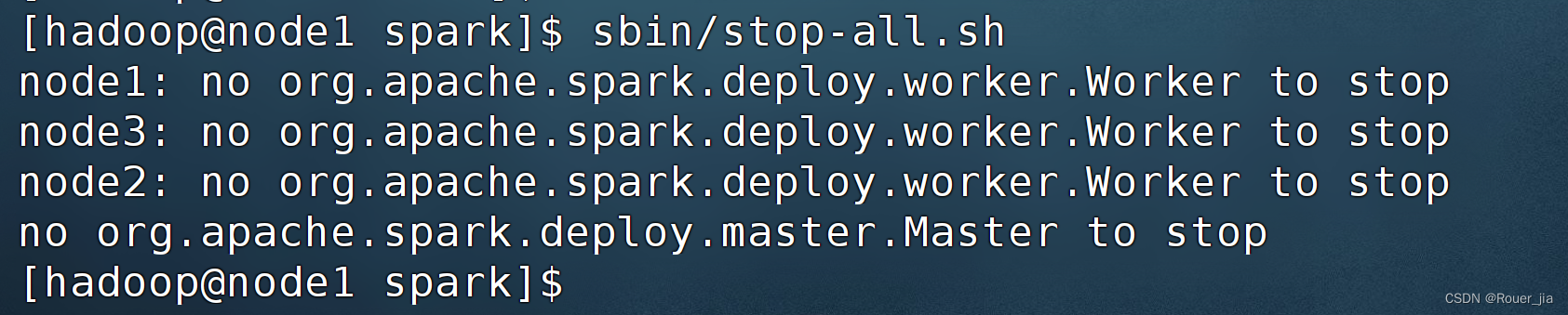
启动集群:
# 在node1上 启动一个master 和全部worker
sbin/start-all.sh
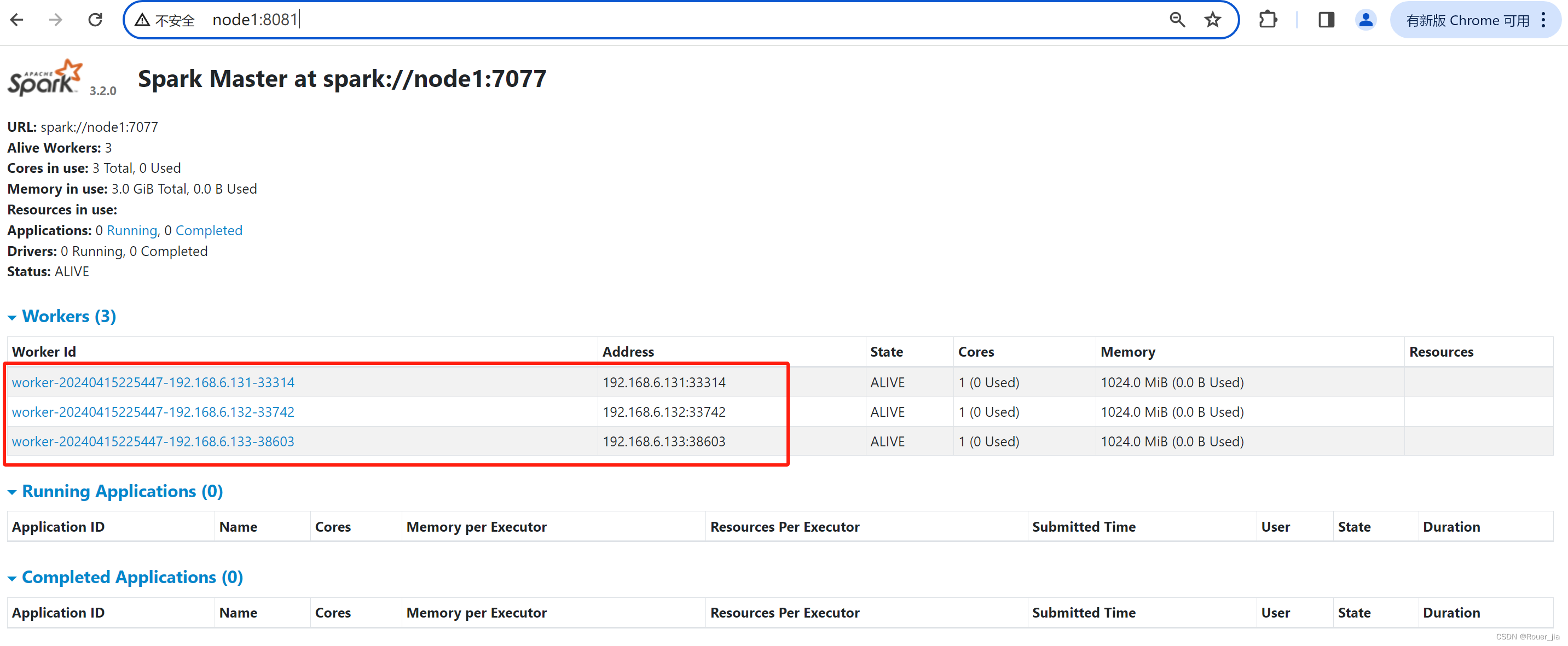
# 注意, 下面命令在node2上执行
sbin/start-master.sh
# 在node2上启动一个备用的master进程
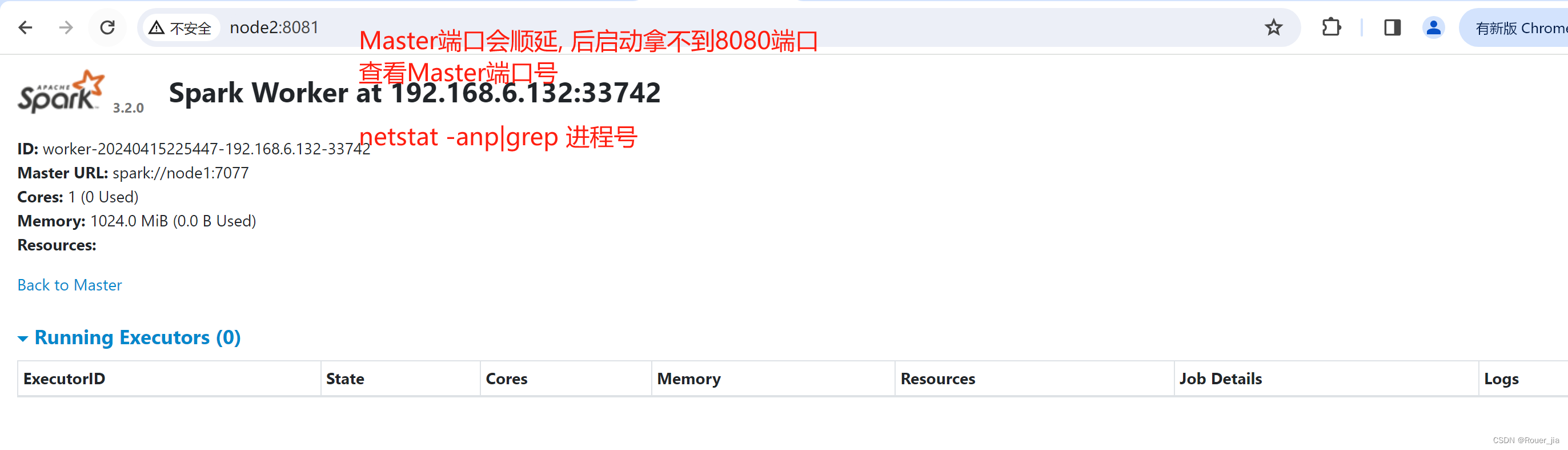
测试主备切换
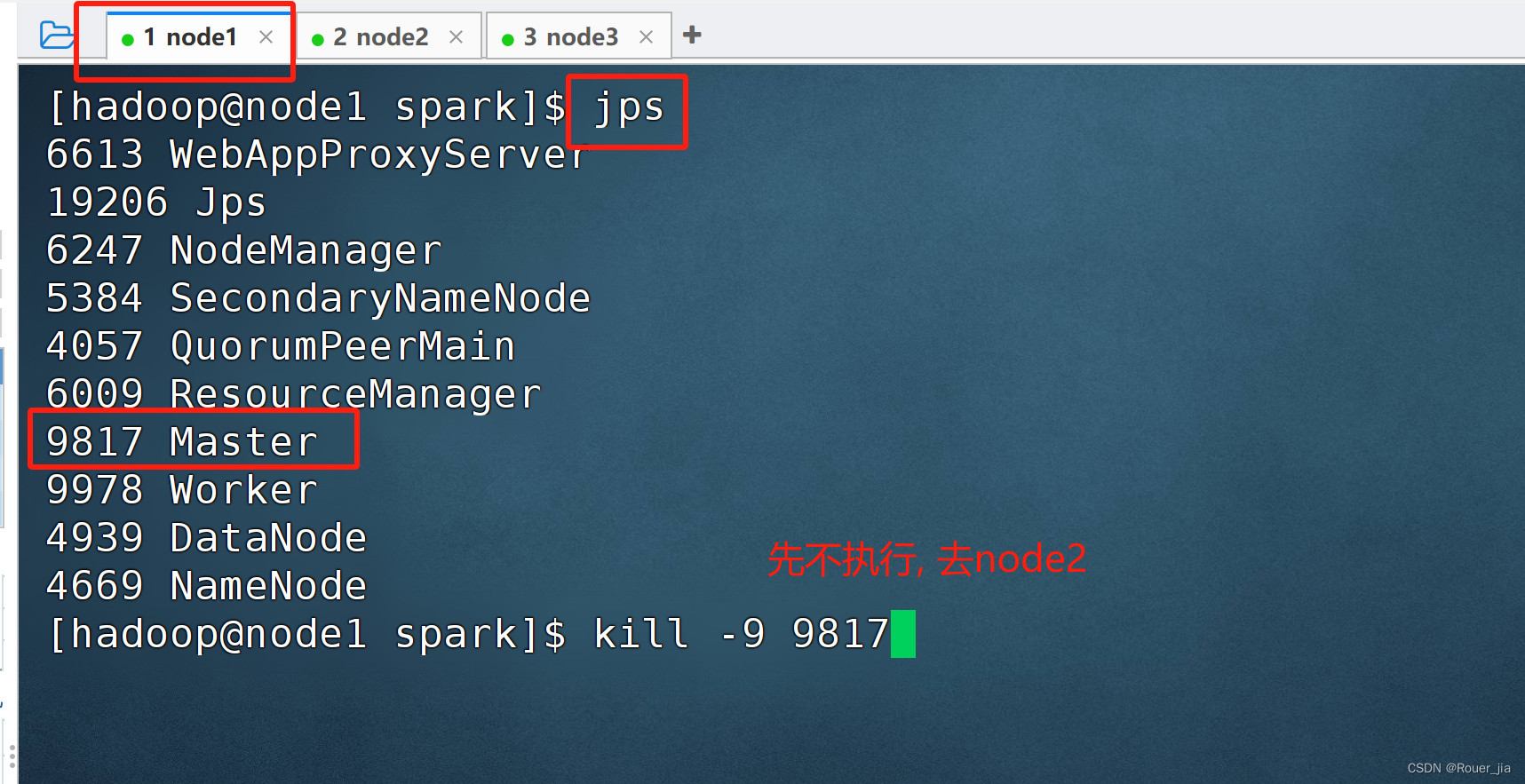
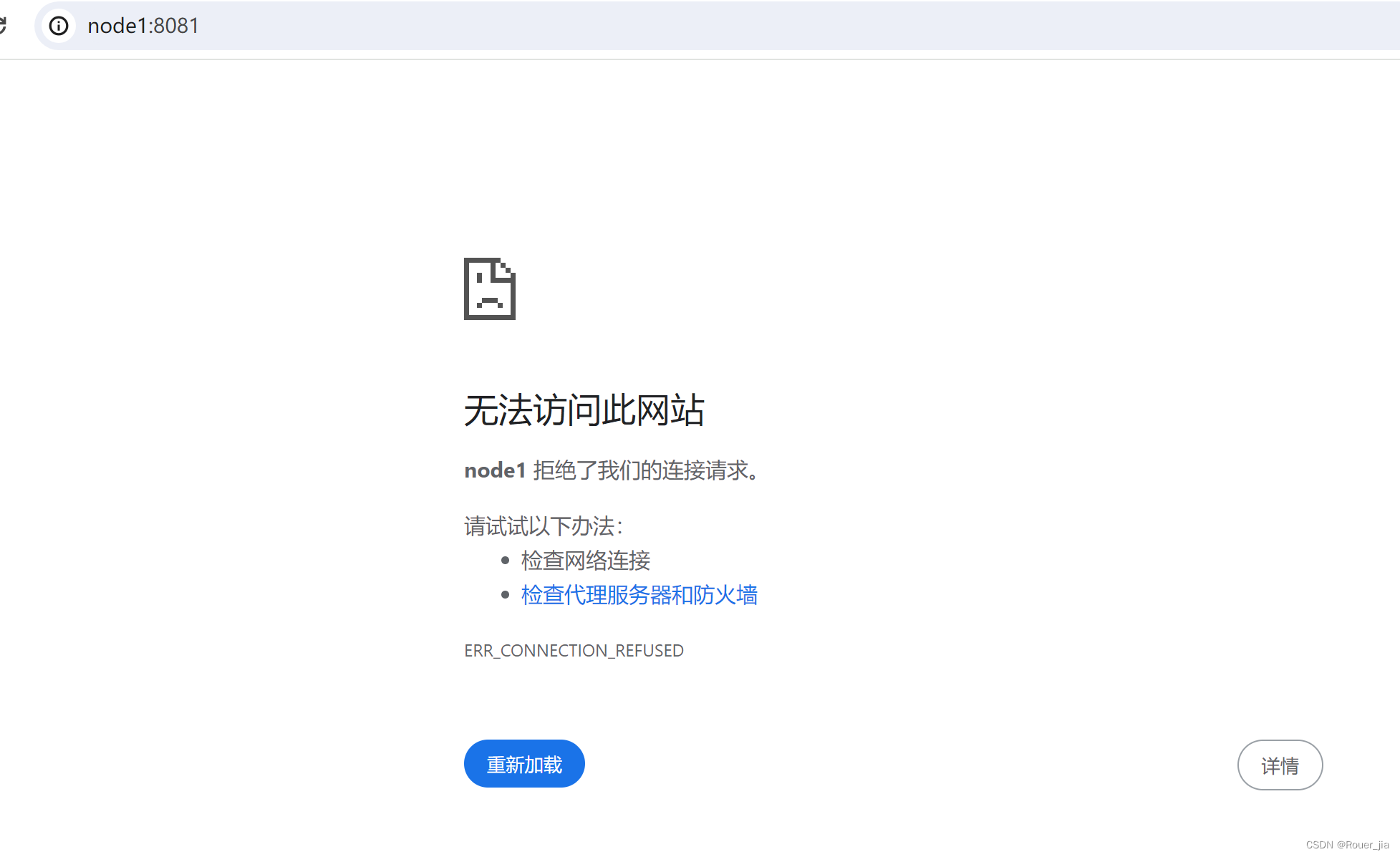
4.模拟node1宕机
jps
kill -9 进程id
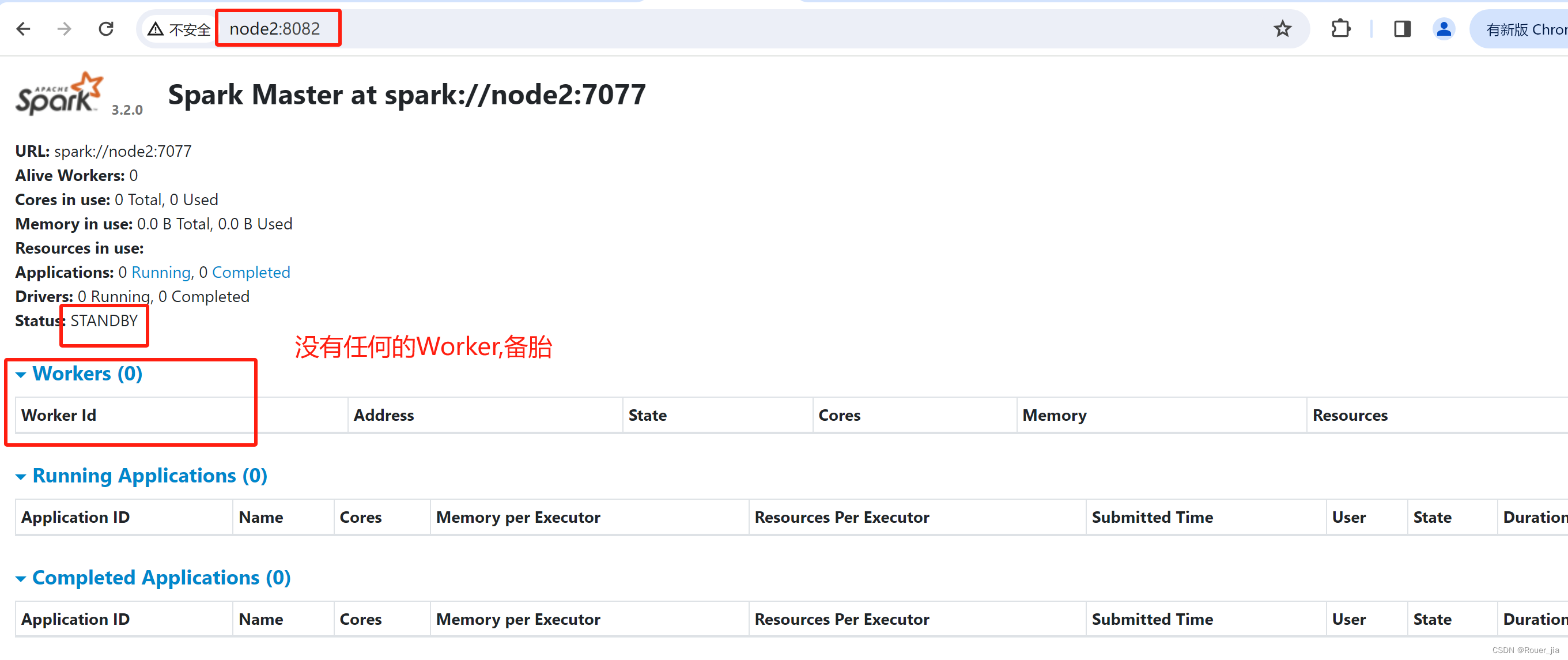
5.再次查看web-ui
http://node1:8080/
http://node2:8080/
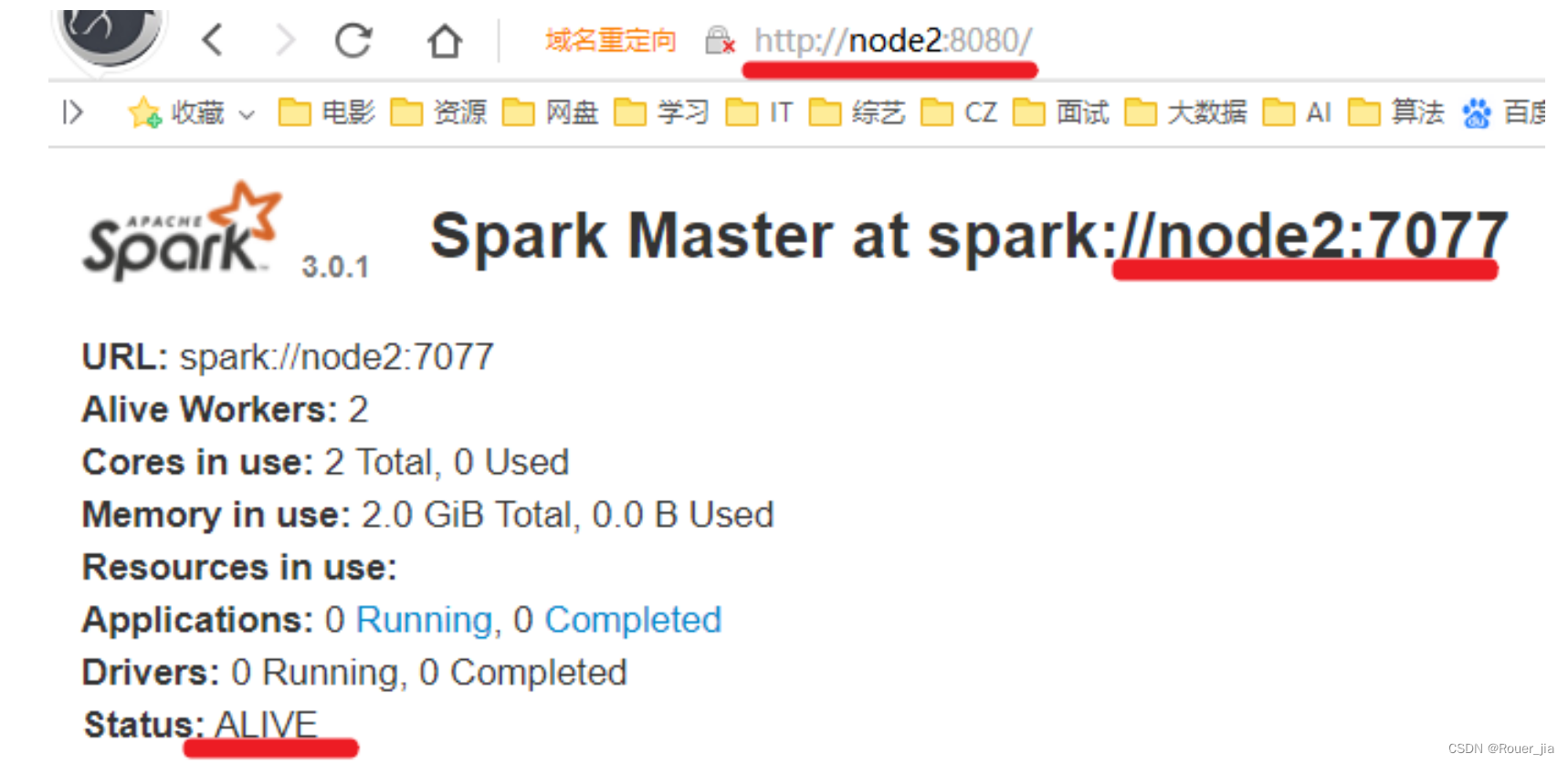
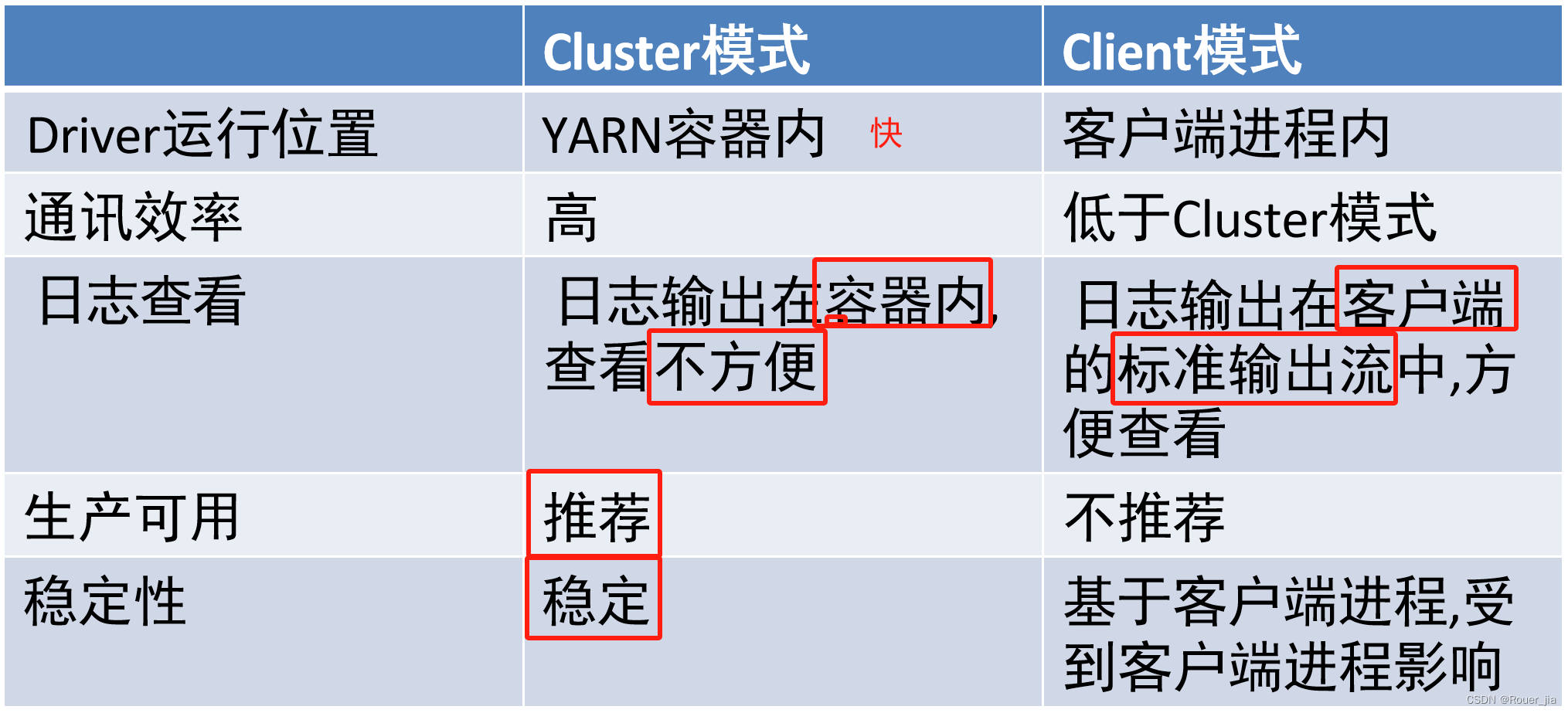
五. Spark On YARN – 重点
1. 环境搭建
1.1整合YARN集群
cd /export/server/spark/conf
vim spark-env.sh
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
1.2 配置YARN历史服务器并关闭资源检查
cd /export/server/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- 配置yarn主节点的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
配置完成要分发
cd /export/server/hadoop/etc/hadoop
scp -r yarn-site.xml node2:`pwd`
scp -r yarn-site.xml node3:`pwd`
1.3 配置Spark历史服务器与YARN整合
在YARN集群上可以看大spark的一些历史记录
- 修改
spark-default.conf
进入配置目录
cd /export/server/spark/conf
修改文件名称
mv spark-defaults.conf.template spark-defaults.conf
添加内容
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node1:18080
spark.yarn.jars hdfs://node1:8020/spark/jars/*
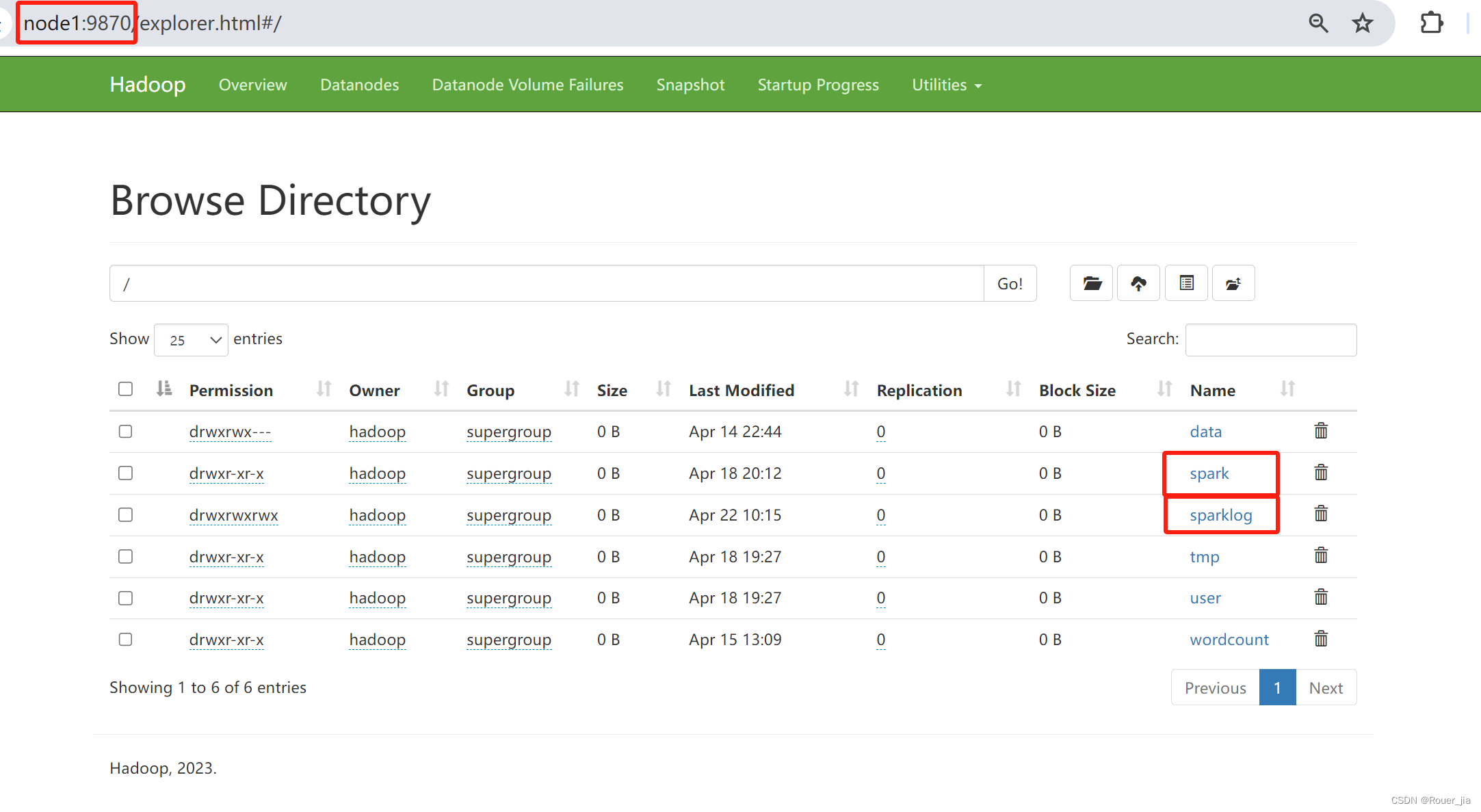
在HDFS下创建文件
创建 spark/jarhadoop fs -mkdir -p /spark/jars
创建sparkloghadoop fs -mkdir /sparklog
- 修改日志级别
修改名称
mv log4j.properties.template log4j.priperties
修改日志级别

- 分发:
scp -r spark-env.sh node2:`pwd`
scp -r spark-env.sh node3:`pwd`
scp -r spark-defaults.conf node2:`pwd`
scp -r spark-defaults.conf node3:`pwd`
scp -r log4j.properties node2:`pwd`
scp -r log4j.properties node3:`pwd`
1.4 配置Spark依赖的jar
- 在HDFS上创建存储spark相关的jar包目录
hadoop fs -mkdir -p /spark/jars
- 上传$SPARK_HOME/jars下所有的jar包到HDFS
hadoop fs -put /export/server/spark/jars/* /spark/jars
检查上传是否成功
hadoop fs -ls /spark/jars
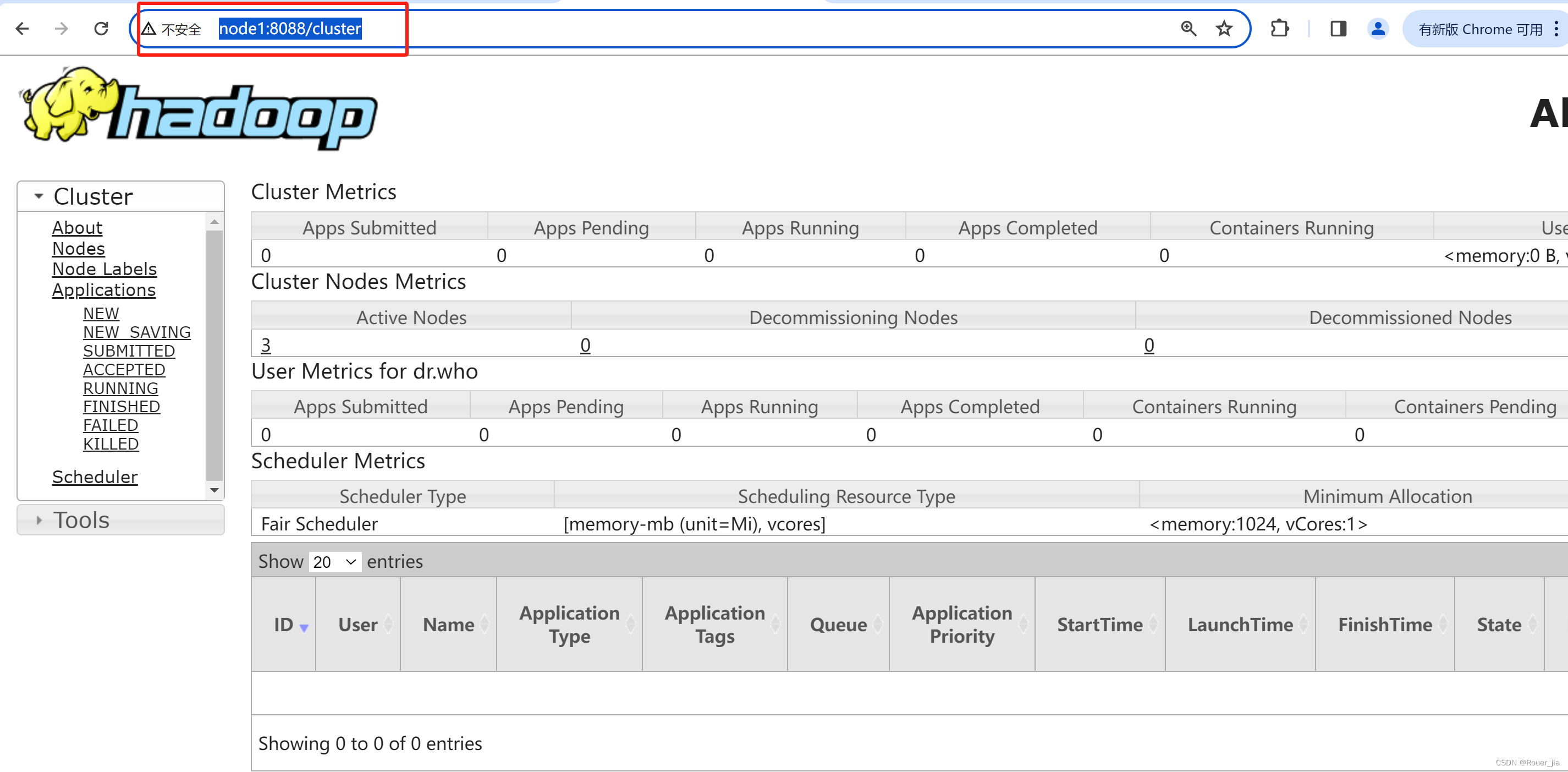
1.5 启动服务
start-dfs.sh
start-yarn.sh
jps
mapred --daemon start historyserver
启动Spark的历史服务
/export/server/spark/sbin/start-history-server.sh
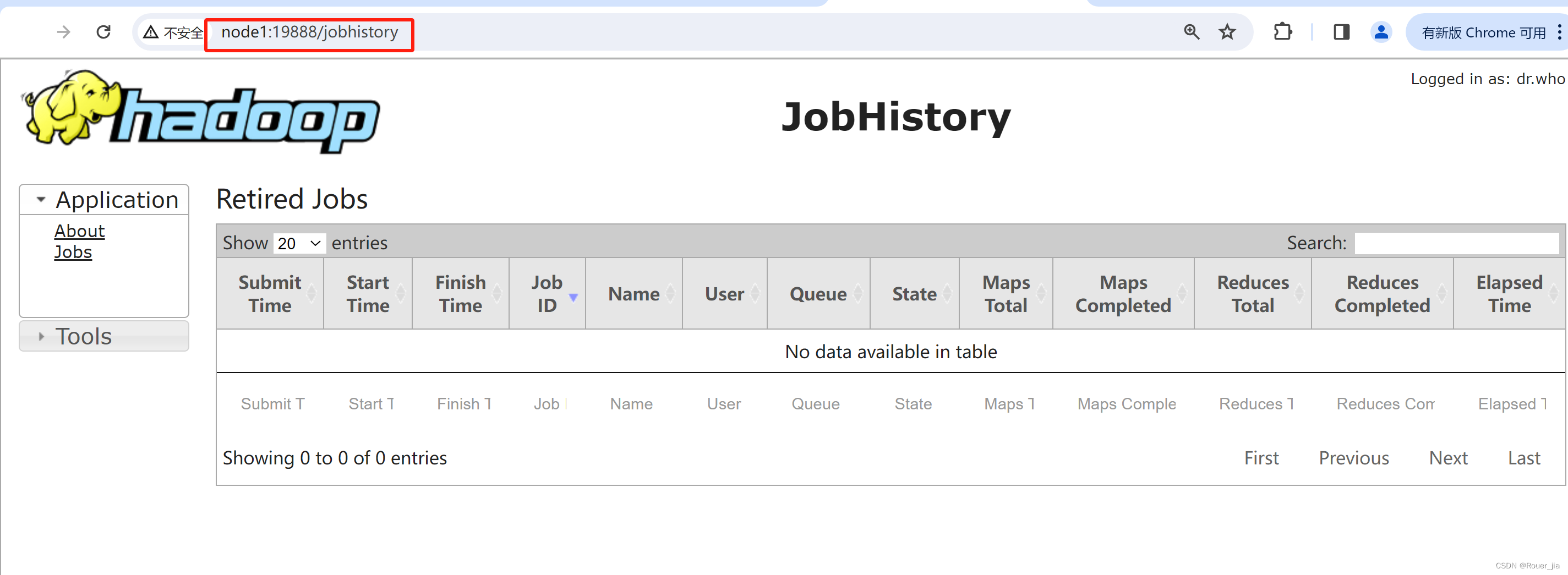
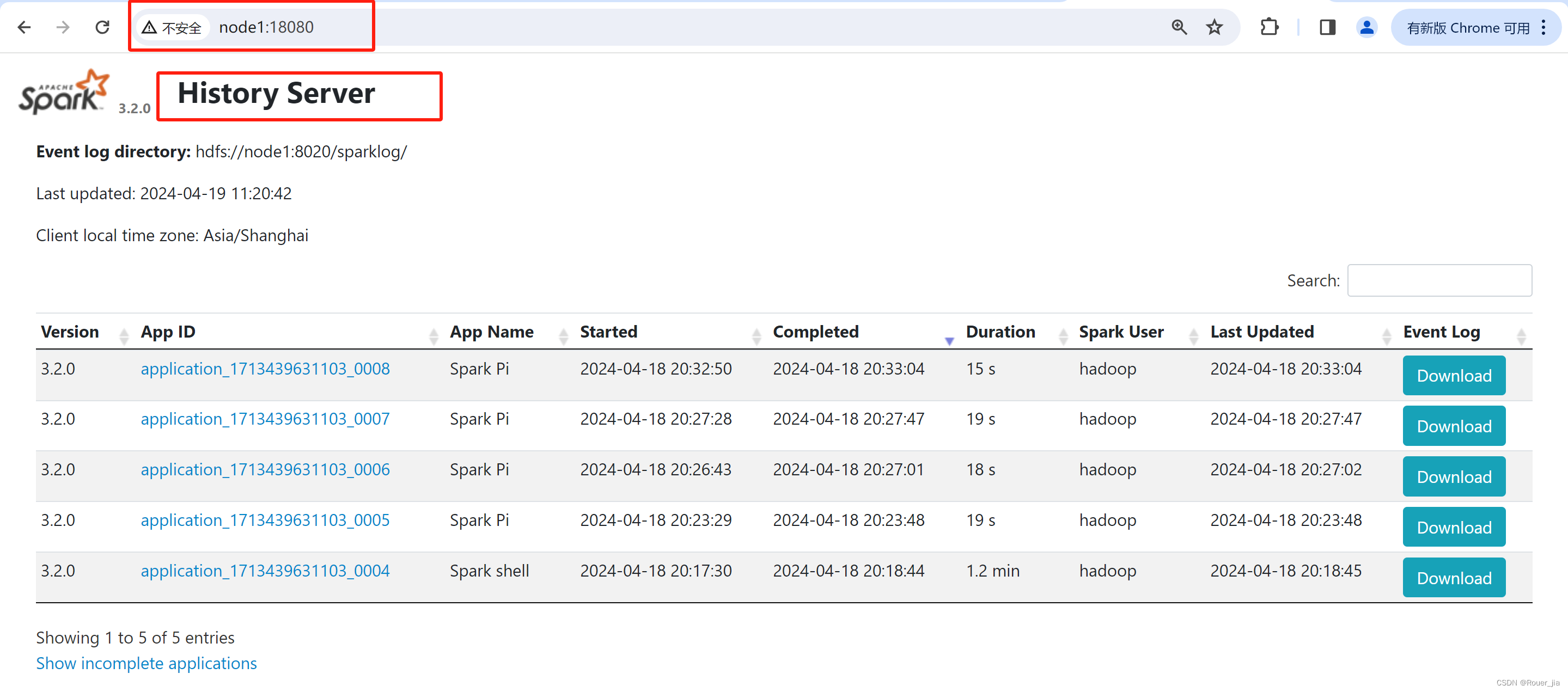
2. spark连接到YARN集群
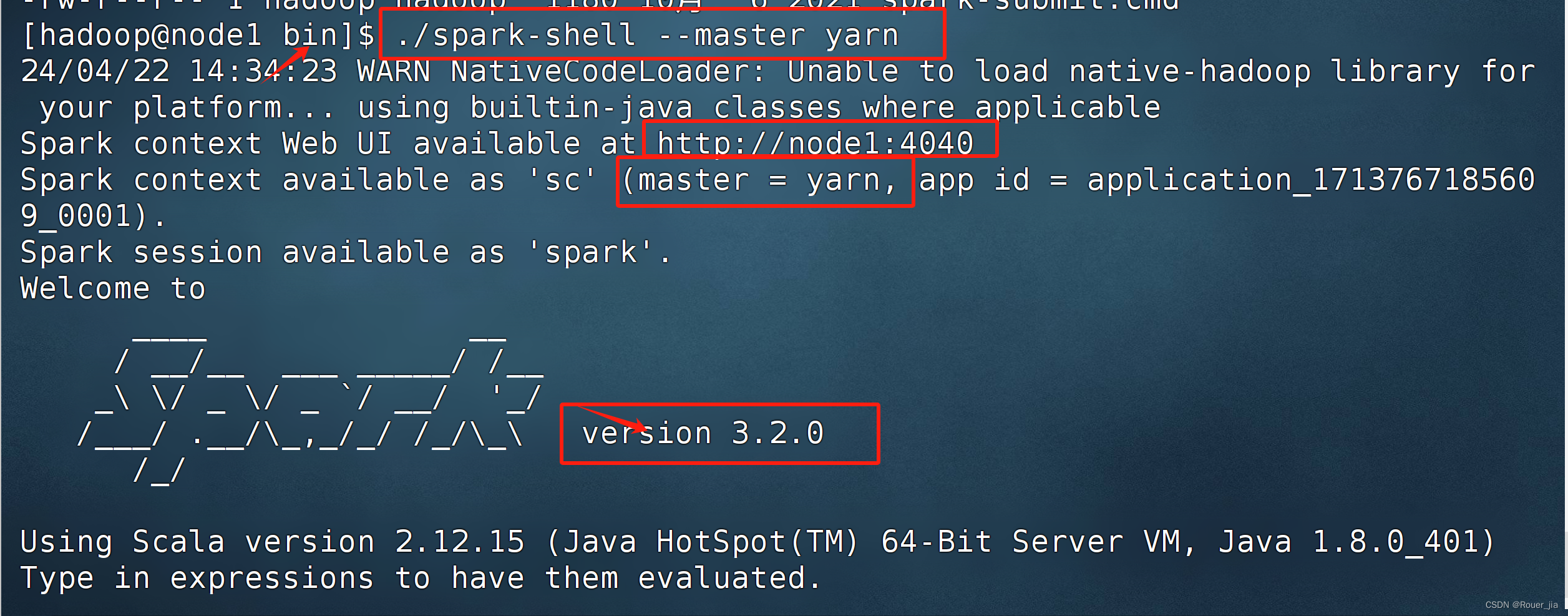
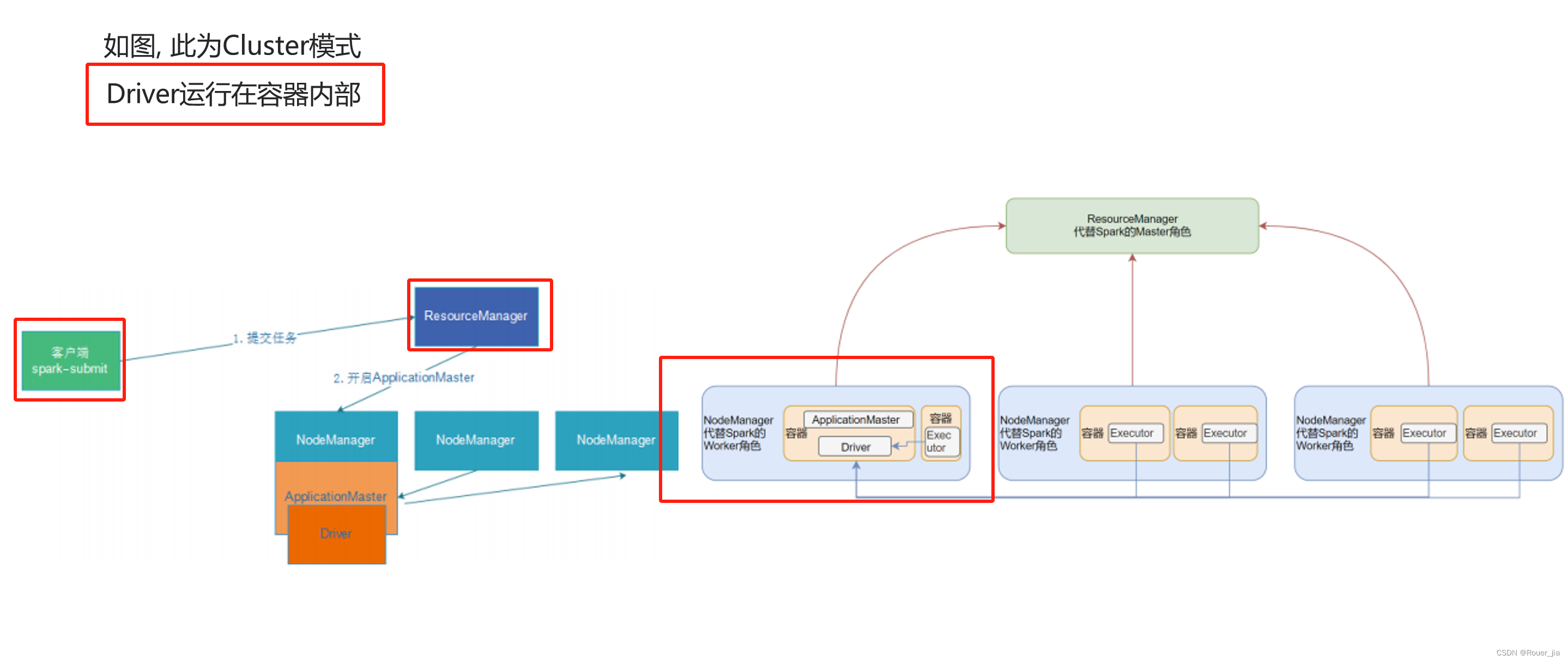
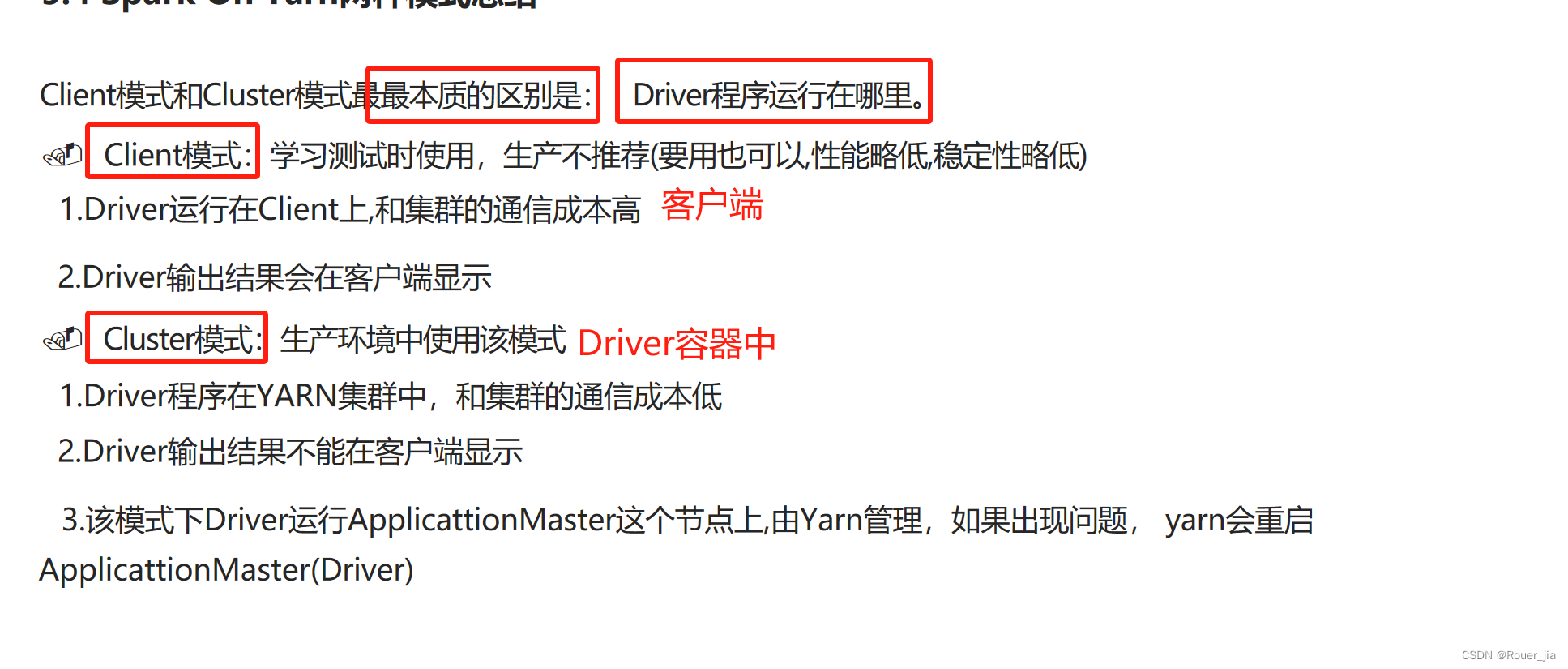
3. Spark On Yarn的运行模式

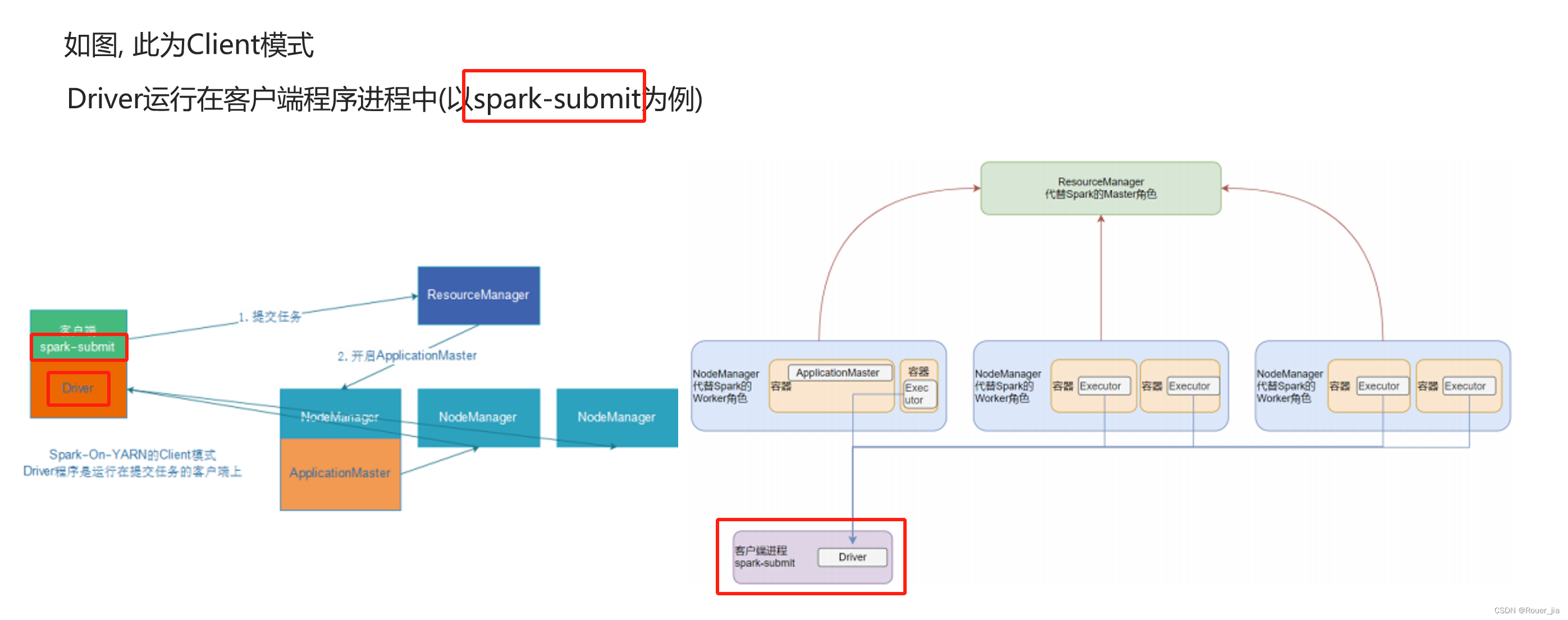
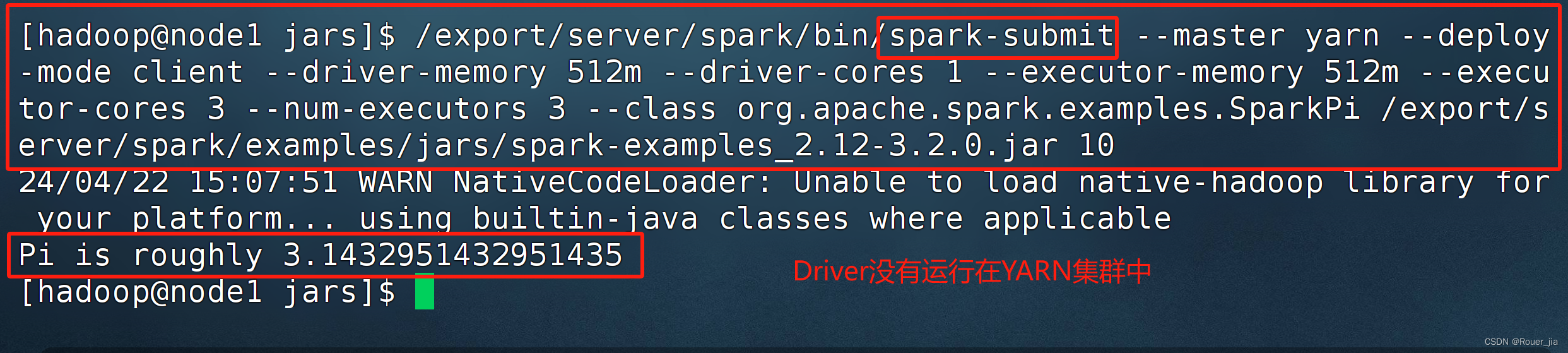
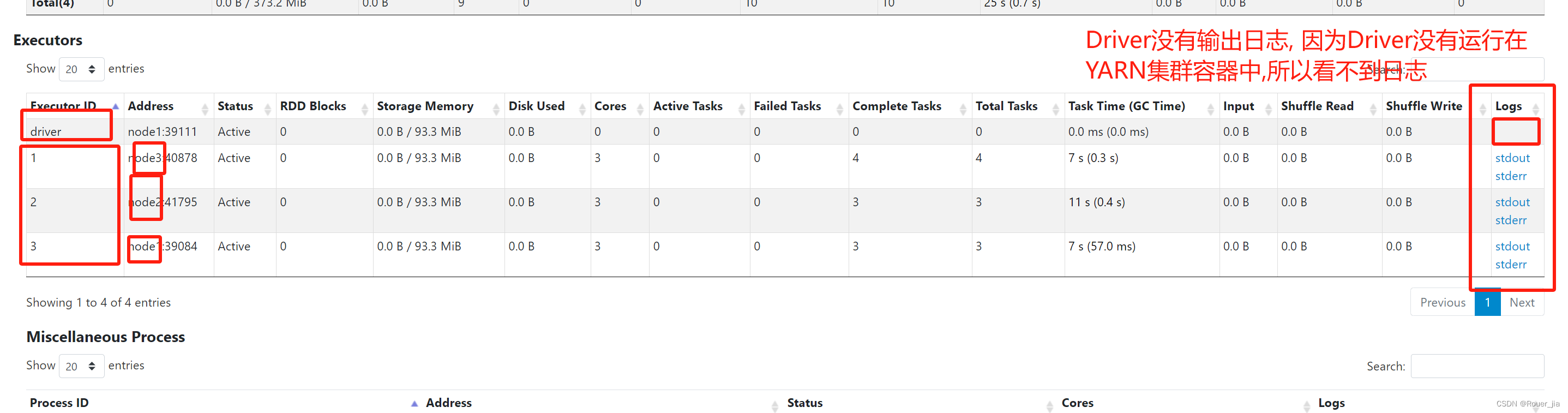
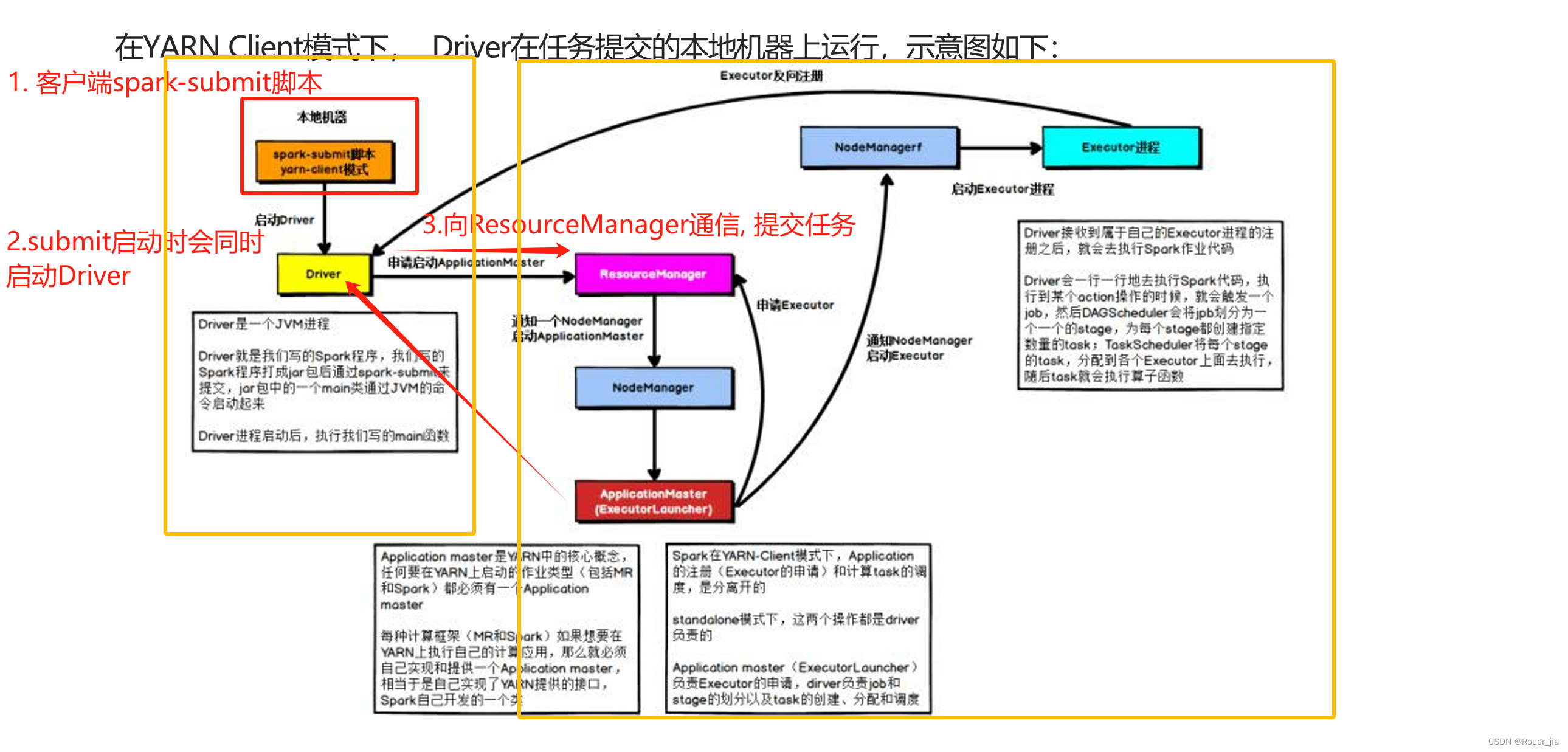
1. 提交任务 - 客户端模式
/export/server/spark/
bin/spark-submit --master yarn
–deploy-mode client
–dirver-memory 512m
–dirver-cores 1
–executor-memory 512m
–executor-cores 3
–num-executors 3
–class org.apache.spark.example.SparkPi
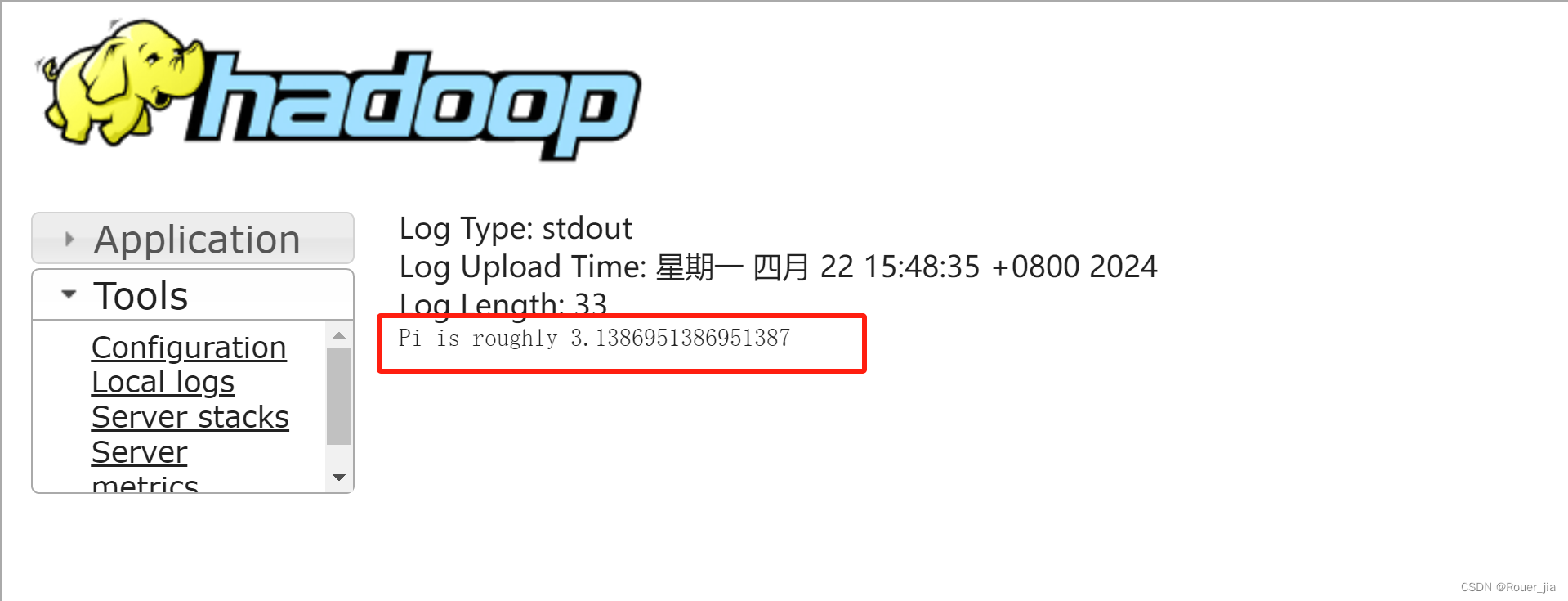
/export/server/examples/jars/spark-example_2.12-3.2.0.jar 10
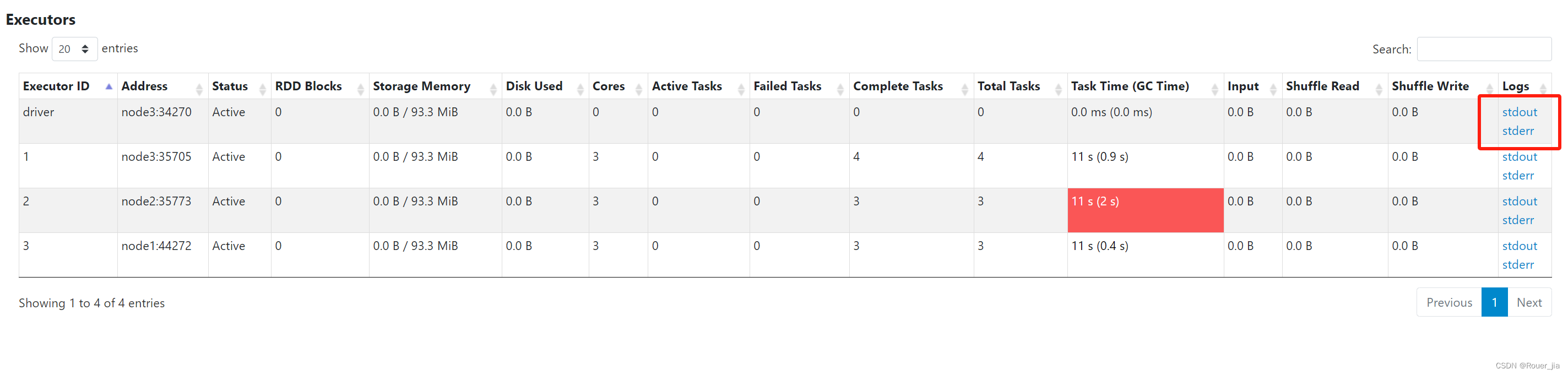
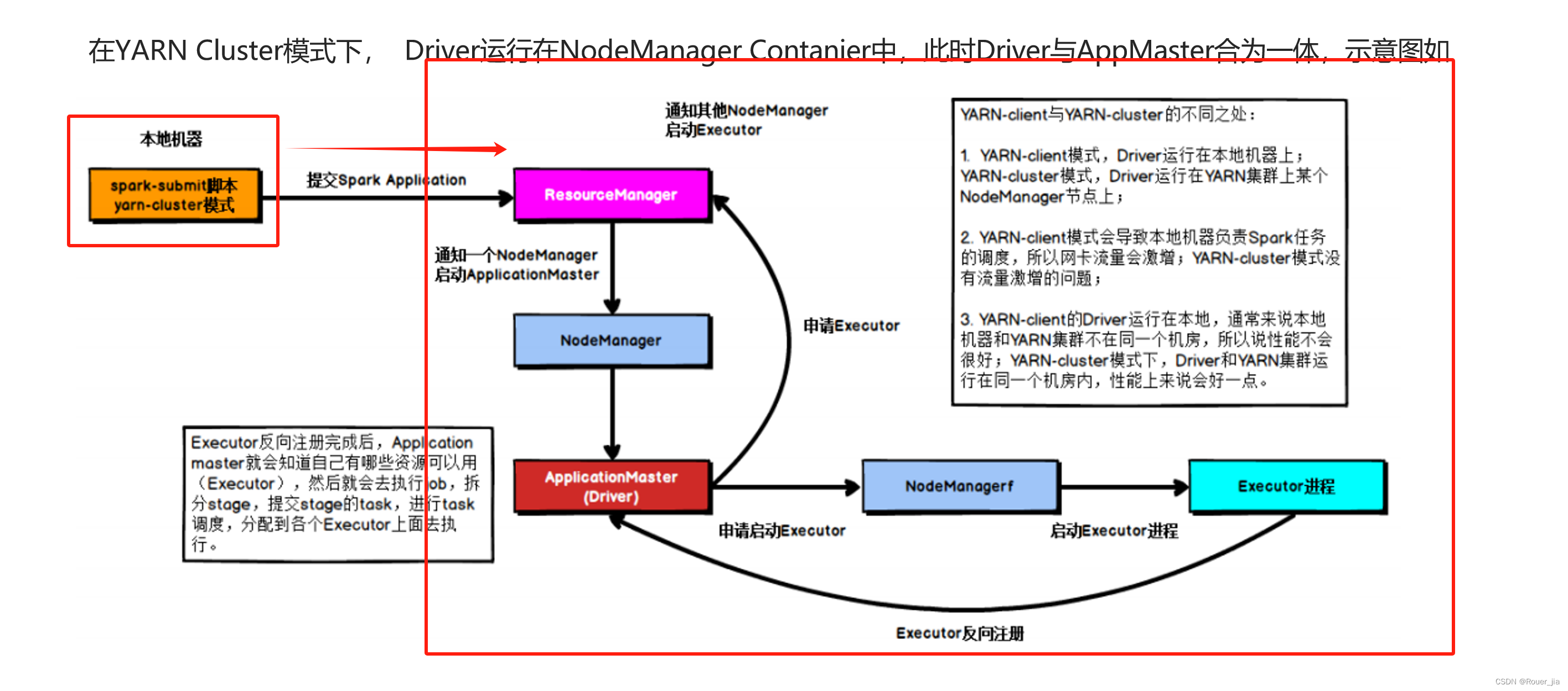
2. 提交任务 - cluster模式
/export/server/spark/
bin/spark-submit --master yarn
–deploy-mode cluster
–dirver-memory 512m
–dirver-cores 1
–executor-memory 512m
–executor-cores 3
–num-executors 3
–class org.apache.spark.example.SparkPi
/export/server/examples/jars/spark-example_2.12-3.2.0.jar 10

3. 两种模式的原理


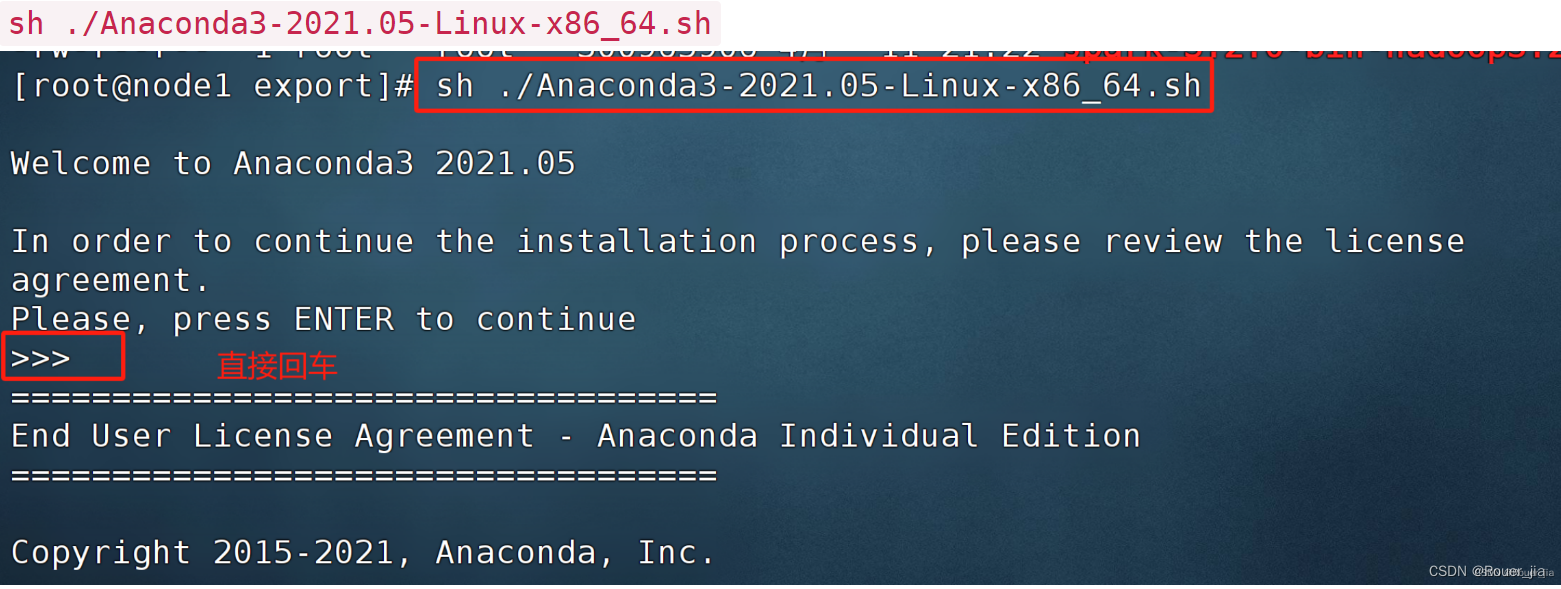
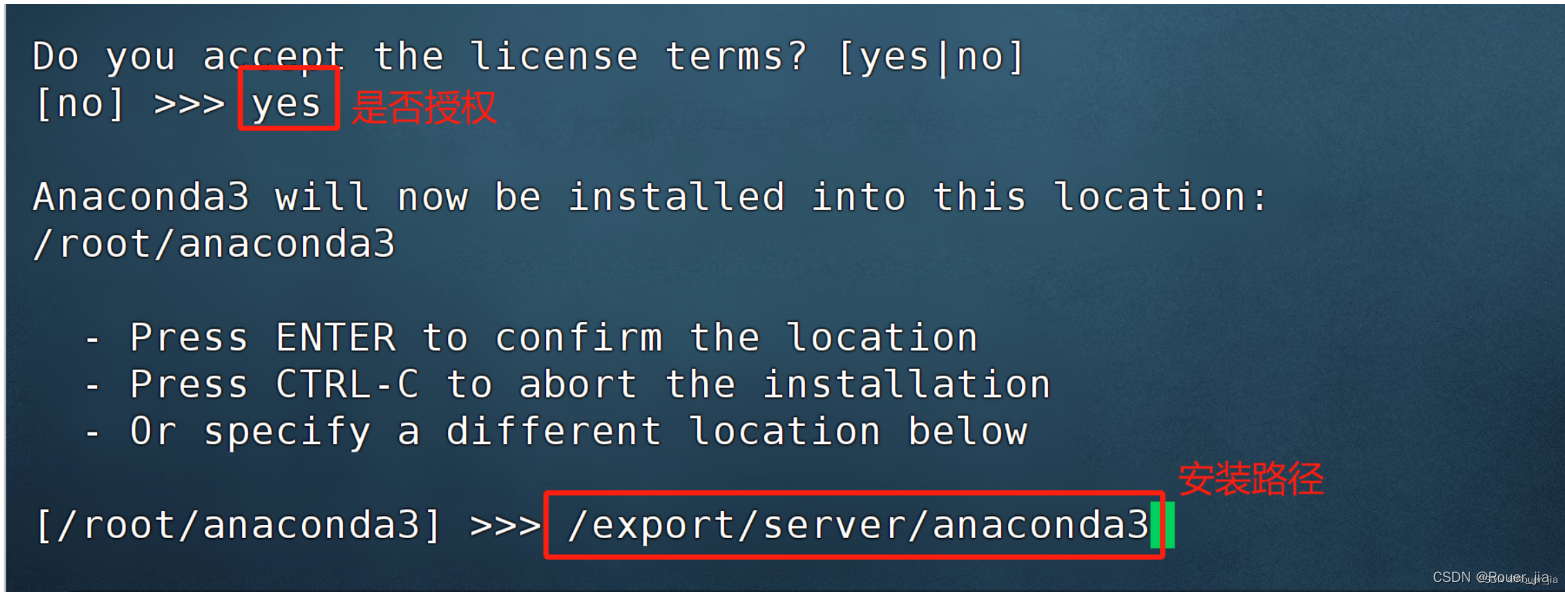
六. Anaconda3 On Linux
输入exit退出


配置国内源
vim ~/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
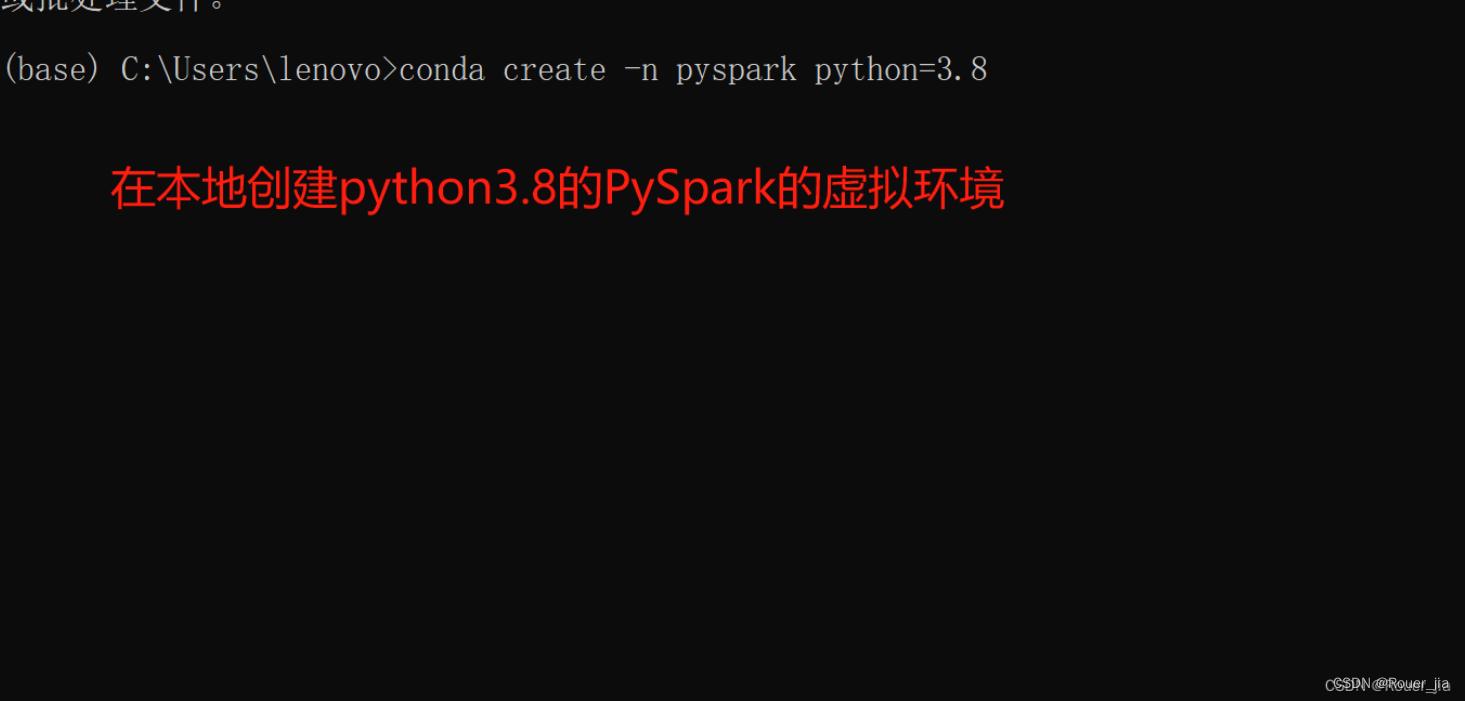
创建python的虚拟环境
conda create -n pyspark python=3.8

配置环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export ZOOKEEPER_HOME=/export/server/zookeeper
export PATH=$PATH:$ZOOKEEPR_HOME/bin
vim ~/.bashrc
export JAVA_HOME=/export/server/jdk
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
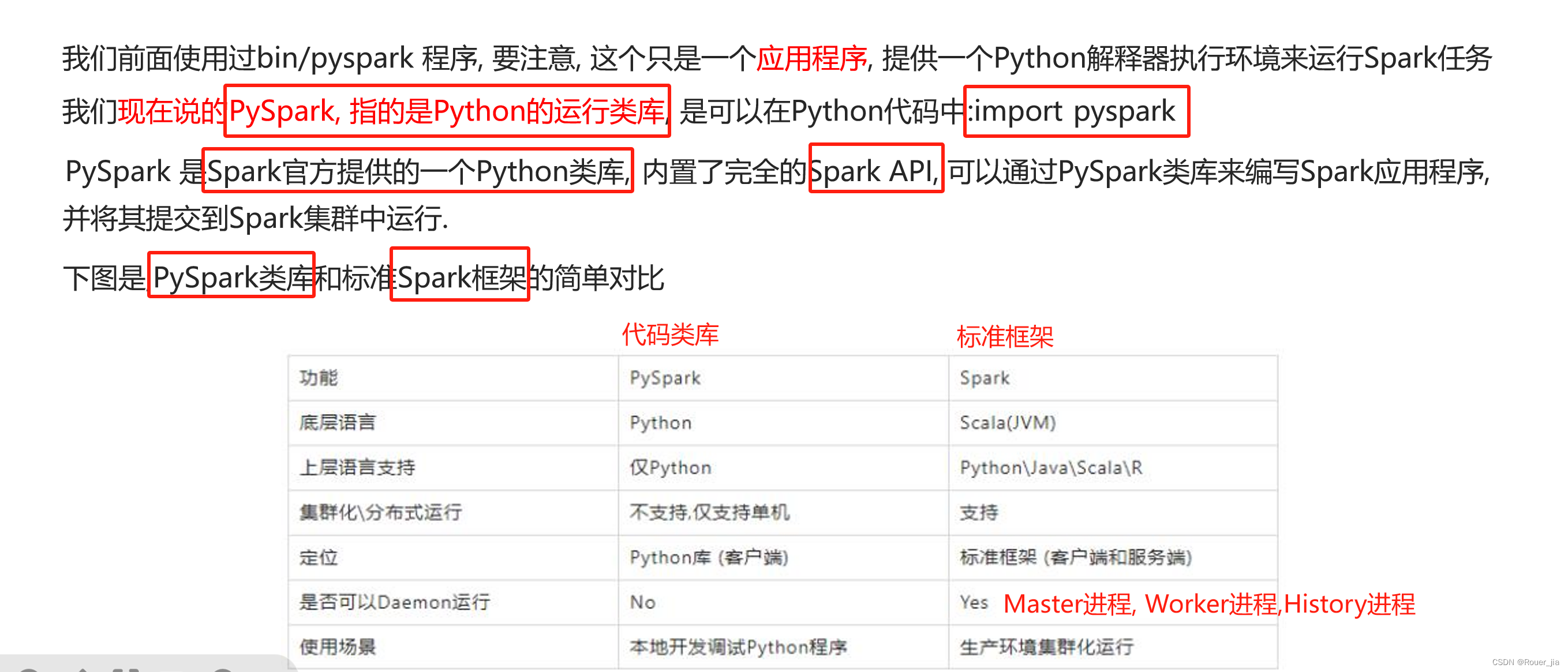
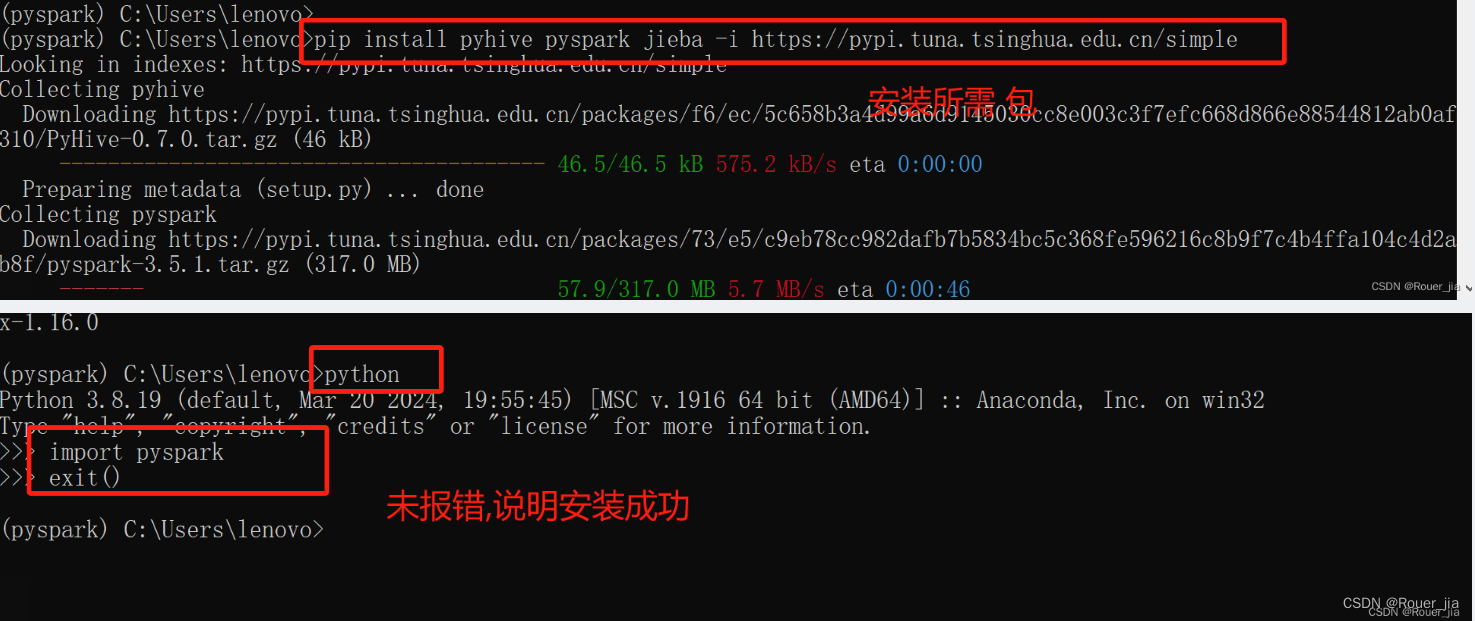
七. PySpark类库


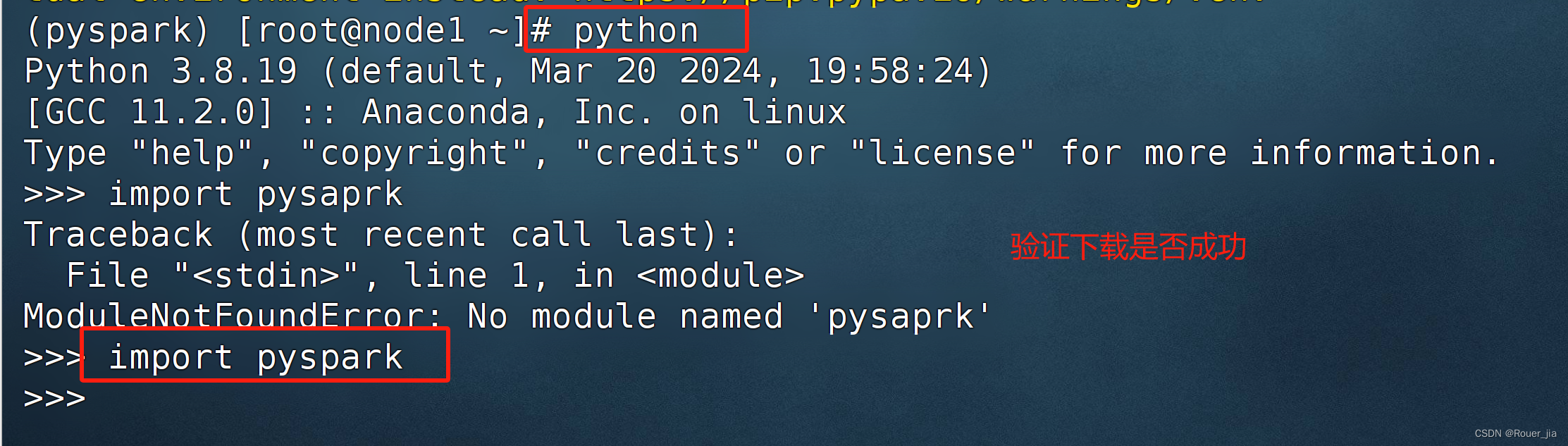
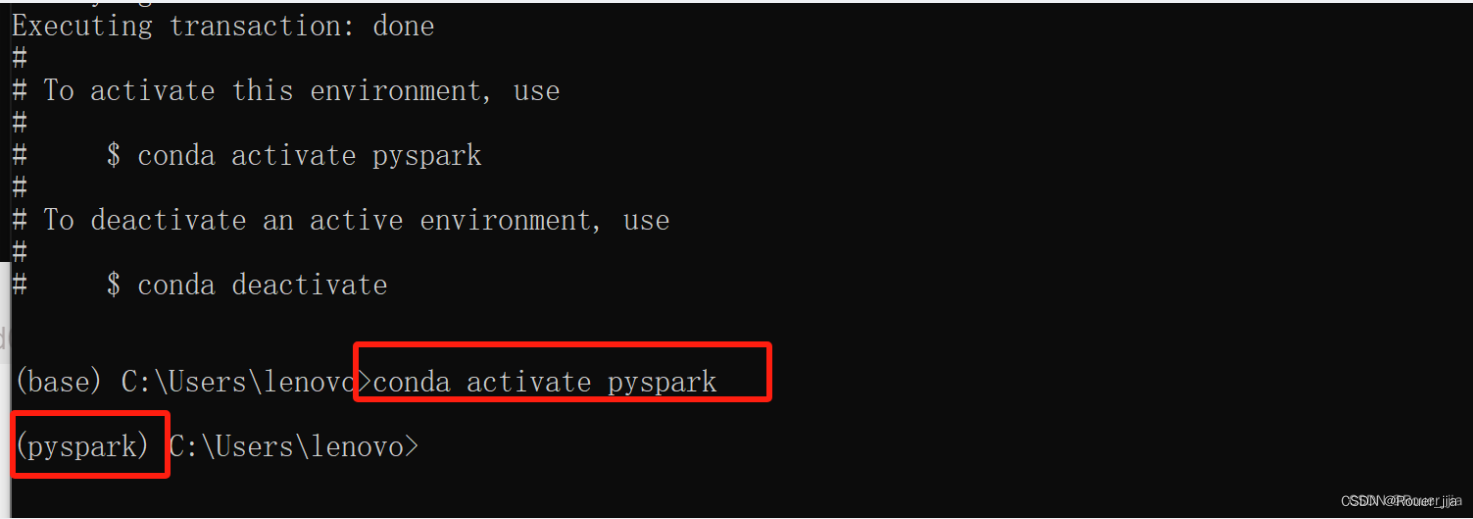
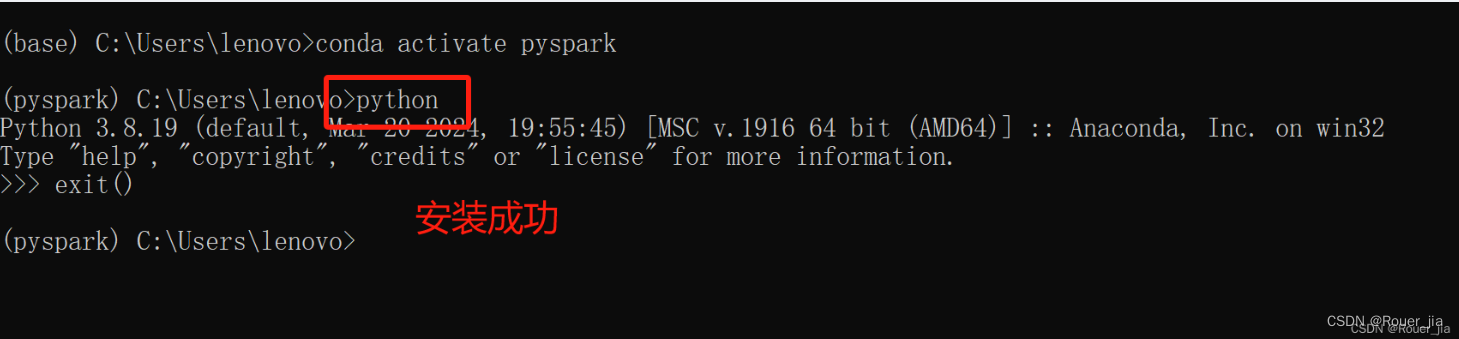
2. 本机环境安装 - windows系统
安装Anaconda
配置国内源
















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









