






 文章介绍了轻量化网络在深度学习中的重要性,特别是在资源有限的移动和嵌入式设备上。轻量化网络通过结构优化和模型压缩技术,如知识蒸馏、剪枝、量化,来减少参数和计算量,以实现更高性能与更低功耗的平衡。文中提到了MobileNet、ShuffleNet等代表性模型,并讨论了网络模型结构搜索(NAS)的发展。此外,文章还指出,尽管轻量化网络取得进展,但仍面临如何在保持性能的同时进一步优化结构的挑战。
文章介绍了轻量化网络在深度学习中的重要性,特别是在资源有限的移动和嵌入式设备上。轻量化网络通过结构优化和模型压缩技术,如知识蒸馏、剪枝、量化,来减少参数和计算量,以实现更高性能与更低功耗的平衡。文中提到了MobileNet、ShuffleNet等代表性模型,并讨论了网络模型结构搜索(NAS)的发展。此外,文章还指出,尽管轻量化网络取得进展,但仍面临如何在保持性能的同时进一步优化结构的挑战。
一、轻量化网络的为何诞生
深度神经网络模型被广泛应用在图像分类、物体检测,目标跟踪等计算机视觉任务中,并取得了巨大成功。随着时代发展,人们更加关注深度神经网络的实际应用性能,人工智能技术的一个趋势是在边缘端平台上部署高性能的神经网络模型,并能在真实场景中实时(>30帧)运行,如移动端/嵌入式设备,这些平台的特点是内存资源少,处理器性能不高,功耗受限,这使得目前精度最高的模型根本无法在这些平台进行部署和达到实时运行。由于存储空间和算力资源限制,神经网络模型在移动设备和嵌入式设备上的存储与计算仍然是一个巨大的挑战。该方向的矛盾在于资源和性能的平衡,即在有限的资源下使性能最大化。
轻量化网络旨在保持模型精度基础上近一步减少模型参数量和复杂度,逐渐成为计算机视觉中的一个研究热点。
轻量化网络既包含了对网络结构的探索,又有例如知识蒸馏,剪枝等模型压缩技术的运用,推动了深度学习技术在移动端,嵌入式端的应用落地,在智能家居,安防,自动驾驶,视频监控等领域都有重要贡献。轻量化的网络模型在移动端上的部署的迫切需求如自动驾驶、机器人视觉、无人机、人脸识别、目标识别检测等领域。
当前物体检测结构大都依赖使用卷积网络进行特征提取,即 Backbone,比如AlexNet的8层、VGGNet的19层,GoogleNet的22层,乃至于ResNet的152层 等优秀的基础网络,随着网络深度的不断提升,网络模型性能的确是提高了,但是这些网络往往计算量巨大,依赖这些基础网络的检测算法很难达到实时运行的要求,尤其是在 ARM、FPGA、RISC-V以及 ASIC 等计算力有限的移动端硬件平台。逐渐呈现了一种在移动设备平台上“算不好”,穿戴设备上“算不了”,数据中心“算不起”的无奈场面,如下图所示因此如何将物体检测算法加速到满足工业应用要求,一直是关键性问题。

二、轻量化网络结构介绍
2.1 轻量化网络的结构
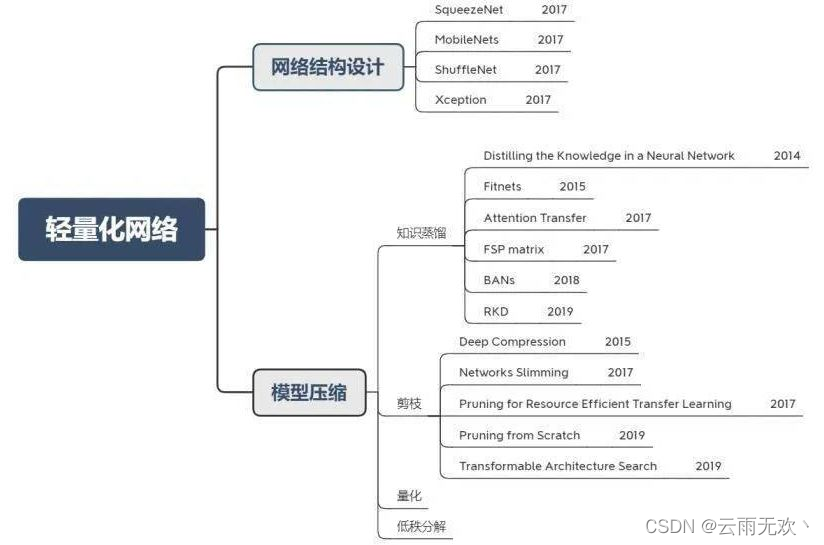
从轻量化网络结构定义来看,我们可以将轻量化网络分为轻量化网络结构设计和模型压缩两大类,其中模型压缩又可细分为知识蒸馏、剪枝、量化、低秩分解四个小类别。如下图所示:
2.2 轻量化网络的发展
轻量化网络是指在计算资源受限的环境下,运行高效的神经网络。它们的发展历程可以分为以下几个阶段:
在2014年,Hinton等人提出了一种基于知识蒸馏的神经网络压缩方法,通过训练一个学生网络来学习一个已训练好的教师网络的知识,从而达到减少参数和加速推理的效果。此后,一系列的神经网络压缩算法相继被提出,例如深度可分离卷积、通道剪枝、权重剪枝等等。
2017:squeezeNet、MobileNet、ShuffleNet、Xception等网络模型被提出在移动设备上实现了高效的图像分类和目标检测。
2018:MobileNetv2、ShuffleNetv2
2019:MobileNetv3、MixNet、ThunderNet
2020:GhostNet、MoGA
代表性论文的发表时间:
1、MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (2017)
2、ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (2018)
3、MobileNetV2: Inverted Residuals and Linear Bottlenecks (2018)
4、ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation (2018)
5、FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search (2019)
6、EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (2019)
7、EfficientDet: Scalable and Efficient Object Detection (2019)
8、RegNet: Designing Network Design Spaces (2020)
9、GhostNet: More Features from Cheap Operations (2020)
10、RepVGG: Making VGG-style ConvNets Great Again (2021)
综上所述,轻量化网络在过去几年中不断地迭代和创新,为移动设备上的深度学习提供了更好的解决方案。未来,随着计算资源的不断提升和深度学习技术的不断发展,轻量化网络将会有更广泛的应用场景。
三、模型压缩
3.1 模型的评价指标
我们常常从以下两个评价指标来衡量网络模型的轻量级,一个是网络参数量、另一个是浮点运算数(floating point operations),也就是计算量,可以用来衡量模型的复杂度。
Params——网络参数量

FLOPs——浮点运算数

要注意的是:一般来说,网络模型参数量和 浮点运算数越小,模型的速度越快,但是衡量模型的快慢不仅仅是参数量、计算量的多少,还有内存访问的次数多少相关,也就是和网络结构本身相关。
3.2 模型压缩的方法
轻量化设计: 从模型设计时采用一些轻量化的思想,例如采用深度可分离卷积、分组卷积等轻量卷积方式、减少卷积过程的计算量,此外采用全局池化来取代全连接层、利用 1 x 1 卷积实现特征的通道降维,也可以降低模型的计算量,这两点在众多网络中得到应用。
迁移学习: 一种机器学习方法,是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。 教师–学生网络和知识蒸馏就用到了迁移学习。
教师–学生网络: 对于教师–学生网络,教师网络往往是一个更加复杂的网络,具有非常好的性能和泛化能力,可以用这个网络来作为一个soft target来指导另外一个更加简单的学生网络来学习,使得更加简单、参数运算量更少的学生模型也能够具有和教师网络相近的性能,也算是一种模型压缩的方式。
知识蒸馏: 大的模型拥有更强的拟合能力和泛化能力,而小的模型拟合能力较弱,且容易造成过拟合,使用大模型指导小模型训练保留大模型的有效信息,实现知识蒸馏。通过学习一个蒸馏模型,训练一个更紧凑的神经网络来重现一个更大的网络的输出。
网络剪枝: 在卷积网络成千上万的权重中,存在着大量接近 0 的参数,这些属于冗余的参数,去掉后模型也可以基本达到相同的表达能力,因此众多众多研究者从此为出发点,搜索网络中的冗余卷积核、将网络稀疏化,称之为网络裁剪。具体讲,网络剪枝有训练中稀疏与训练后剪枝两种。
量化: 是指将网络模型中高精度的参数量化为低精度的参数,从而加速计算的方法。高精度的模型参数拥有更大的动态变化范围,能够表达更丰富的参数空间,因此训练中通常使用 32 位浮点数 (单精度) 作为网络参数模型。训练完后成为了减小模型大小,通常将 32 未浮点数量化为 16 位浮点数的半精度,甚至 int8的整型,0 与 1 的 二值类型。
例如在yolov5官方代码的detect.py中的代码块采用Half用半精度提高了检测速度。

低秩分解: 由原始网络参数中存在大量冗余,除了剪枝的方法外,我们还可以利用 SVD 分解和 PQ 分解,将原始张量分解为低秩的若干张量,以减少卷积的计算,提升前向速度。
自动模型压缩的轻量化方法: 基于AutoML的模型压缩为了避免在模型压缩过程中过分依赖人工设计的启发式策略和基于规则的策略,西安交通大学与Google 于 2018 年提出基于自动机器学习的模型压缩(AutoML for Model Compression,AMC)方法。AMC方法的性能明显优于基于规则的压缩策略,压缩模型能在保证准确性的同时大幅减少人工成本。
四、轻量化网络
4.1 轻量级网络模型
轻量化网络设计
除了一些模型压缩的方法,研究人员更加重视手工设计轻量高效的卷积神经网络架构,能有效保证模型精度的同时大大减少参数,一直是在嵌入式平台和移动端应用最为广泛的一种方法。近几年来也逐渐提出了很多优秀的轻量化网络。
MobileNetv1将常规卷积替换为深度可分离卷积,包含了深度卷积(depth-wise)和点态卷积(point-wise),假设采用的是3x3的卷积核,一般可达到8-9倍的加速,而精度不会损失太多。
MobileNetv1采用的是类似VGG的简单堆叠的方式,更为先进的方法是加入ResNet的shortcut的链接方式,MobileNetv2就借鉴了这种思想,应用了invered residual block,与Residual block相比,有如下的区别:1)、通道数:两边窄中间宽;2、3x3卷积改成了Depthwise Conv;3、去掉了最后的ReLU(ReLU会使得一些神经元失活,而高维的ReLU可以保留低维特征的完整信息,同时又不失非线性。所以采用中间宽+ReLU的方式来保留低维输入的信息)。MobileNetv3采用了网络结构搜索(NAS)的方法,得到一个高效的网络结构,先通用NAS算法,优化每一个block,得到大体的网络结构,然后使用NetAdapt 算法来确定每个filter的channel的数量,此外并结合一些必要的trick,包含1)、引入SE(squeeze and excitation)结构,并将SE结构放在了depthwise之后;2)、对网络结构的尾部部分进行了简化修改;3)、修改了channels;4)、非线性激活的改变,使用h-swish替换swish。
SqueezeNet是公认的轻量级模型设计最早期的工作之一,通过堆叠包含了squeeze部分和expand部分在内的fire module大大减少了参数。ShuffleNet利用group convolution 和channel shuffle两个操作设计卷积神经网络模型,使得模型参数得到大大的较少,加速了模型的推理。Xception与MobileNet同样采用了深度可分离卷积,主要是在Inception v3的基础上引入了depthwise separable convolution。GhostNet通过廉价且高效的线性变换操作生成了更多的Ghost feature map,Sandglass(MobileNeXt)翻转了逆残差模块(inverted residual block) ,缓解了信息的丢失。GhostNet是出自于华为诺亚方舟实验室的一篇2020 CVPR的工作,是一篇不可多得的轻量级高效网络架构,其实现原理简单,效果确极好,正所谓大道至简,如此简单高效的方式也只是我如此青睐它的一个原因。
MobileNetv3(2019)
ShuffleNetv1(最早公布时间:2016.06,发表情况:CVPR-2017)
ShuffleNetv2(2018)
Xception(最早公布时间:2016.10,发表情况:N/A)
GhostNet(CVPR-2020)
4.2 轻量级目标检测算法
4.2.1 YOLO Nano
4.2.2 Micro-YOLO
4.2.3 NanoDet
4.2.4 YOLOX-Nano
4.2.5 华为GhostNet
4.2.6 YOLOv5
4.2.7 YOLO-Fastest
这些算法在目标检测领域都很优秀,但是当把这先算法部署到算力不强的终端上,还需要我们对模型做出优化,例如用上述的轻量级目标检测网络与mobilenet的一些创新方法进行结合,从而更加减少我们的网络参数,使得模型在终端上的效果更好。
4.3 网络模型结构搜索
网络模型结构搜索(Neural Architecture Search,NAS) 是指自动化地在给定的任务和数据集上搜索最优的神经网络结构。
背景
手动设计神经网络结构是一项非常耗时和繁琐的任务,需要对网络结构和超参数进行不断的试错和调整。而且,不同的任务和数据集需要不同的网络结构,因此手动设计的网络结构往往不能达到最优性能。
为了解决这个问题,研究人员提出了网络模型结构搜索的方法,通过自动化地搜索网络结构,可以减少人工设计的工作量,并且获得更好的性能。
方法
- 网络模型结构搜索的方法根据搜索空间的不同可以分类为基于离散空间的搜索和基于连续空间的搜索。
- 基于离散空间的搜索方法通常使用强化学习算法来搜索最优的网络结构。在搜索过程中,强化学习算法通过不断试错来调整网络结构,最终得到最优的网络结构。其中,策略梯度算法和进化算法是比较常用的强化学习算法。
- 基于连续空间的搜索方法则使用了优化算法来搜索最优的网络结构。在搜索过程中,优化算法通过不断地调整网络结构的超参数来优化网络结构,最终得到最优的网络结构。其中,梯度下降算法和贝叶斯优化算法是比较常用的优化算法。
应用
网络模型结构搜索已经被广泛应用于图像分类、目标检测、语音识别、自然语言处理等领域。在这些领域,网络模型结构搜索已经取得了一些重要的进展,可以大大提高模型的性能和效率。
结论
网络模型结构搜索是一种自动化地搜索最优神经网络结构的方法,可以减少人工设计的工作量,并且获得更好的性能。它已经被广泛应用于各种领域,并且取得了一些重要的进展。
五、挑战
- 依赖于原模型,降低了修改网络配置的空间,对于复杂的任务,尚不可靠;
- 通过减少神经元之间连接或通道数量的方法进行剪枝,在压缩加速中较为有效。但这样会对下一层的输入造成严重的影响;
- 结构化矩阵和迁移卷积滤波器方法必须使模型具有较强的人类先验知识,这对模型的性能和稳定性有显著的影响。研究如何控制强加先验知识的影响是很重要的;
- 知识精炼方法有很多优势,比如不需要特定的硬件或实现就能直接加速模型。个人觉得这和迁移学习有些关联。
- 多种小型平台(例如移动设备、机器人、自动驾驶汽车)的硬件限制仍然是阻碍深层 CNN 发展的主要问题。相比于压缩,可能模型加速要更为重要,专用芯片的出现固然有效,但从数学计算上将乘加法转为逻辑和位移运算也是一种很好的思路。
- 轻量化网络的发展趋势主要包括以下几个方面:
模型压缩和量化:模型压缩和量化是轻量化网络发展的重要方向之一。这种方法通过对模型进行剪枝、量化、分组卷积等技术来减少模型参数和计算量,从而达到减小模型大小、提高模型运行速度的效果。
网络结构设计:轻量化网络结构的设计是轻量化网络发展的重要方向之一。一些研究人员通过设计轻量级的网络结构来减少模型参数和计算量,例如MobileNet、ShuffleNet等。
跨平台移植:随着物联网和移动设备的普及,将深度学习应用到移动设备上变得越来越重要。因此,跨平台移植是轻量化网络发展的重要方向之一。一些研究人员正在开发一些跨平台的深度学习框架,以便在不同设备上运行相同的轻量化网络。
自适应计算:自适应计算是轻量化网络发展的重要方向之一。这种方法允许轻量化网络在不同的硬件平台上自适应计算,从而达到更好的性能和能耗比。
总的来说,轻量化网络的发展趋势主要是在不断地探索如何在减小模型大小和提高模型运行速度的前提下,尽可能地保持较高的准确率和性能,以满足不同场景下的需求。
参考文献
终端移植
网络模型加速——轻量化网络
轻量化网络
目标检测–轻量级网络(截至2022-04-21)
轻量级目标检测算法整理
看了几十篇轻量化目标检测论文扫盲做的摘抄笔记
【移动端最强架构】LCNet吊打现有主流轻量型网络(附代码实现)
[1]王军,冯孙铖,程勇.深度学习的轻量化神经网络结构研究综述[J].计算机工程,2021,47(08):1-13.DOI:10.19678/j.issn.1000-3428.0060931.
[2]易振通,吴瑰,官端正,陶俊.轻量化卷积神经网络的研究综述[J].工业控制计算机,2022,35(10):109-111+114.
[3]杨玉敏,廖育荣,林存宝,倪淑燕,吴止锾.轻量化卷积神经网络目标检测算法综述[J].舰船电子工程,2021,41(04):31-36.


















 9583
9583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











