







1.为MNIST数据集构建一个分类器,并在测试集上达成超过97%的准确率。提示:KNeighborsClassifier对这个任务非常有效,你只需要找到合适的超参数值即可(试试对weightsn_neighbors这两个超参数进行网格搜索)。
如果你了解knn算法,你会清楚知道这个算法是多么的耗时,大数据量+网格搜索+交叉验证,一套下来需要十多个小时
from sklearn.model_selection import GridSearchCV
param_grid = [{'weights': ["uniform", "distance"], 'n_neighbors': [3, 4, 5]}]
knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, param_grid, cv=5, verbose=3)
grid_search.fit(X_train, y_train)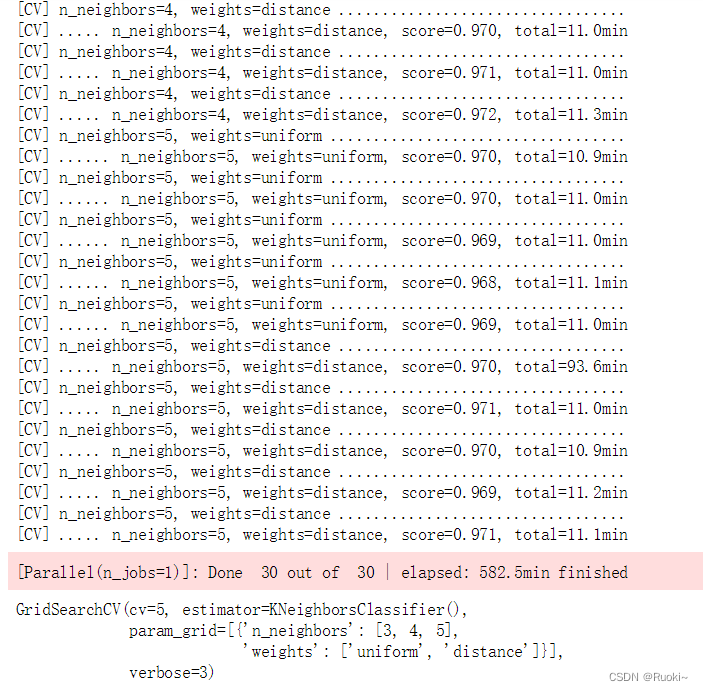
grid_search.best_params_
## {'n_neighbors': 4, 'weights': 'distance'}
grid_search.best_score_
## 0.9716166666666666
from sklearn.metrics import accuracy_score
y_pred = grid_search.pre 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5864
5864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









