







文章目录
Paper PDF
发表年份:2019 沈春华实验室
本篇文章涉及到的其他严格相关工作:FCOS,Heat-map Learning
本文原链接
参考:https://www.jianshu.com/p/60c56806ce5b
Abstract
我们提出了第一个直接端到端多人姿态 估计框架,称为DirectPose。受到来自于最近的无锚目标检测器(直接回归目标边界盒的两个角)的启发,该框架直接从原始输入图像中预测所有实例的实例感知关键点,消除了自底向上方法中启发式分组或自顶向下方法中边界盒检测和RoI操作的需要。我们还提出了一种新的关键点对齐(Keypoint Alignment, KPAlign)机制,该机制克服了该端到端框架中卷积特征与预测之间的特征不匹配的主要困难。KPAlign在很大程度上提高了框架的性能,同时仍然保持了框架端到端可训练性。我们提出的框架利用唯一的后处理非最大抑制(NMS),可以一次性检测出带有或不带有边界框的多人关键点。实验表明,端到端范式可以实现比以往的强baseline的自下而上和自上而下的方法相当的或更好的性能。我们希望我们的端到端方法可以为人体姿态估计任务提供一个新的视角。
Introduction
多人姿态估计(又称关键点检测)是理解图像和视频中人类行为的关键步骤。以往的任务处理方法大致可以分为自下而上[1,19,21,23]和自上而下[9,26,6,3]两种。自底向上方法首先以_实例不可知_的方式检测输入图像中所有可能的关键点,然后通过分组或组装过程产生最终的实例感知关键点。分组过程通常是启发式的,为了获得良好的性能,涉及许多技巧。相比之下,自顶向下的方法首先使用一个边界框检测每个单独的实例,然后将任务减少到单实例关键点检测。虽然自顶向下方法可以避免启发式分组过程,但由于不能充分利用卷积神经网络(CNNs)的共享计算机制(why?),其代价是计算时间长。此外,自顶向下方法的运行时间取决于图像中实例的数量,这使得它们在一些即时应用(如自动驾驶汽车)中不可靠。重要的是,自下而上和自上而下的方法都不是端到端1,这与深度学习的“一起学习一切”的理念相冲突。
最近,无锚的目标检测[28,11]正在兴起,并显示出比以往基于锚的目标检测更优越的性能。这些无锚的物体检测器直接回归目标边界盒的两个角,而不使用预定义的锚盒。无锚的目标检测的直接而有效的解决方案引发了一个问题:关键点检测也可以用这样的简单框架来解决吗?很容易看出,一个实例的关键点可以看作是一个具有两个以上角点的特殊边界框,因此可以通过在目标检测网络上附加更多的输出头来解决该任务。这个解决方案很有趣,因为1)它是端到端可训练的(即,直接将原始输入图像映射到所需的实例感知关键点)。2)避免了自顶向下和自底向上两种方法的缺点,既不需要分组,也不需要边界盒检测。3)将目标检测和关键点检测统一在一个简单优雅的框架中。
然而,我们表明,这种幼稚的方法的性能并不令人满意,主要是因为这些目标检测器依靠单个特征向量回归一个实例的所有感兴趣的关键点,希望单个特征向量能够忠实地保留其感受野中的基本信息(例如,所有关键点的精确位置),如图1所示。对于简单的边界框检测,单个特征向量可以很好地携带信息,如[28],一个边界框只涉及两个角点,但对于更具挑战性的关键点检测,它很难编码丰富的信息。正如我们的实验所示,这种直接的方法产生的性能较差。
在这项工作中,我们提出了一个关键点对齐(KPAlign)机制,以在很大程度上克服上述解决方案的问题。与其使用单个特征向量回归一个实例的所有关键点,KPAlign将卷积特征与一个目标关键点(或一组关键点)尽可能地对齐,然后使用对齐特征预测目标关键点的位置。由于目标关键点和所使用的特征大致对齐,特征只需要对其邻域内的信息进行编码即可。很明显,编码邻域比编码整个感受野容易得多,从而提高了性能。此外,KPAlign模块是可微的,从而保持模型端到端可训练。此外,众所周知,学习一个基于回归的模型是困难的。然而,在这项工作中,我们发现回归任务可以很大程度上受益于基于热图的学习。因此,我们建议在训练中共同学习这两个任务。当测试时,基于热图的分支被禁用,因此不会给框架带来任何开销。
综上所述,本文提出的基于单阶段回归的关键点检测方法与以往的自顶向下或自底向上的方法相比具有以下优点。
- 提出的框架是直接的,完全端到端可训练的。为了进行预测,它直接将输入图像映射到每个单独实例的关键点,既不依赖于RoI特征裁剪这样的中间操作,也不依赖于分组后处理,这使我们的工作有别于以前的框架[9,1]的多步骤。
- 我们提出的框架可以绕过自顶向下和自底向上方法的主要缺点。例如,与自顶向下的方法相比,我们的框架可以避免先验框的问题,并将计算复杂度与输入图像中的实例数量解耦。与自下而上方法相比,我们的框架消除了将检测到的关键点组装成完整实例的启发式后处理。
- 此外,与以往的自顶向下和自底向上两种方法都需要基于热图的FCNs来检测关键点,从而存在量化误差不同,本文提出的框架直接回归了关键点的精确坐标,从而将网络的输出分辨率与关键点定位的精度解耦。它使我们的框架有可能检测非常密集的关键点(即关键点挤在一起)。
- 最后,该框架表明,关键点检测任务也可以使用与边界框检测相同的方法来解决(即直接回归所有关键点或边界框的角),从而得到两个任务的统一框架。
1.1 Related Work
Top-Down Methods
自顶向下方法[26,6,24,7,22,3,30,2]将多人姿态估计任务分解为个人检测和单人姿态估计两个子任务。人检测为输入图像中的每个实例预测一个边界框。然后,从原始图像中裁剪实例,并应用一个人的姿态估计来预测裁剪实例的关键点。此外,一些方法如Mask R-CNN[9]裁剪卷积特征而不是原始图像,提高了这些方法的效率。自顶向下的方法通常性能更好,但计算复杂度更高,因为它需要对每个实例重复运行单个人的姿态估计。此外,它还受到early commitment(此处翻译为先验框?)的影响。换句话说,如果检测结果中缺少实例,这些方法很难恢复实例。
Bottom-Up Methods
自顶向下方法首先通过检测器识别单个实例,与此相反,自底向上方法[1,23,13]首先以实例不可知的方式检测所有可能的关键点。然后,采用分组过程将这些关键点组合成全身关键点。自底向上方法可以利用共享卷积计算的优势,因此比自顶向下方法更快。然而,分组过程是启发式的,涉及许多技巧和超参数。最近,单阶段框架[20]简化了分组过程。与此相比,我们的端到端框架通过将输入图像直接映射到所需的关键点,进一步降低了人体姿态估计框架的设计复杂性。
此外,自顶向下和自底向上的方法都需要多个步骤才能得到最终的关键点检测结果。有些步骤是不可微的,这使得这些方法不可能以端到端方式训练,这是我们的方法和以前的方法的主要区别。
2 Approach
从概念上讲,我们提出的关键点检测框架是对无锚对象检测器FCOS[28]的简单扩展,为关键点检测增加了一个新的输出分支。在本节中,我们首先介绍FCOS检测器,并展示如何将其扩展到关键点检测。接下来,我们演示我们提出的KPAlign模块,它允许框架利用特征预测对齐,并在很大程度上提高性能。最后,我们提出了如何联合学习基于回归的任务和基于热图的任务来进一步提高关键点定位的精度。
2.1 End-to-End Multi-Person Pose Estimation
FCOS Dector: FCOS检测器是一种新近提出的无锚对象检测器。与之前的探测器如RetinaNet[15]或Faster R-CNN[25]不同,FCOS消除了锚盒,并直接回归bounding box。研究表明,FCOS可以取得比anchor-based的检测器(如retinaNet)更好的性能。锚点检测器将anchor box(输入图像上的滑动窗口)作为训练样本。相比之下,FCOS将输入图像上的像素(或特征图上的位置)视为训练样本,类似于语义分割。真值框中的像素被视为正样本,需要将像素(或位置)的四个偏移量回归到真值框的四个边界(或等效地,边界框的左上和右下相对于像素的坐标)。除此之外的像素都是负样本。FCOS的架构如图2所示(将关键点分支改为边界盒分支,去掉热图预测分支)。FCOS与RetinaNet共享类似的架构,但输出少了9x。
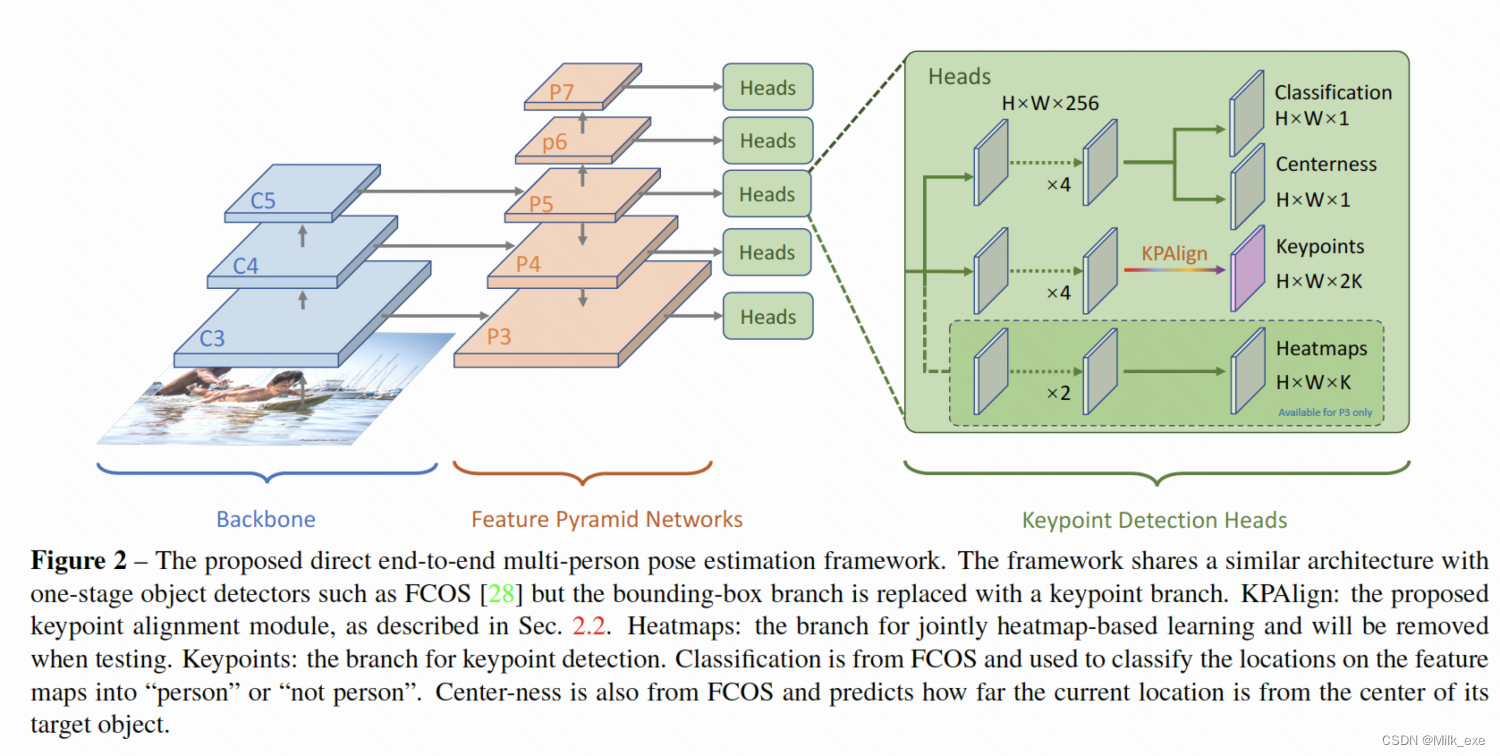
Keypoint Representation: 可以直接将FCOS的bounding box表示扩展为keypoint表示。具体来说,对于每个像素需要回归的标量,我们从4增加到2K,其中K是每个实例的关键点数量,2K的标量代表关键点相对于当前像素的相对坐标。换句话说,我们把关键点看作一个特殊的有K个角点的边界盒。
Our End-to-End Framework: 关键点表示的想法激发了我们朴素的关键点检测体系结构的产生。如图2所示,它是通过应用FPN的feature map所有层次的卷积分支实现的(P3, P4, P5, P6, P7)。这些feature mapx相对于输入图像的下采样率分别为8、16、32、64和128。注意,分支的参数在FCOS检测器的边界盒检测分支中在FPN级别之间共享。分支的输出通道是2K,其中K是每个实例的关键点数量。原bounding box分支可以被保留,同时进行关键点和bounding box检测。
(这段话没太懂原文的意思)此外,值得注意的是,对于keypoint-only的说法,是说我们只使用了关键点注释,而没有使用边界框的检测。然而,在训练过程中,FCOS需要为每个实例确定一个边界框,以确定FPN特征图上每个位置的正标签或负标签。这里,我们采用实例关键点的最小外接矩形作为计算训练标签的伪框。
需要去看一下FCOS
注解:本文模型是基于FCOS改善而来,主要改善的点在于将FCOS中最后用于目标检测的head改成了用于keypoints检测的head,输出通道数也由4变成了2K,K表示目标检测的数量,2表示每个keypoints坐标由两个标量数据构成。
具体来讲,模型结构为:backbone+FPN+Keypoints_Detections_Head(from FCOS->Objection_Detection_Head),backbone为Resnet-50/Resnet-101。
2.2 Keypoint Alignment(KPAlign) Module
我们对上述尚存在问题的关键点检测框架进行了初步实验。但是,从我们的实验中可以看出,它的性能较差。我们将性能较差的原因归结为特征与预测的关键点之间缺乏对齐。
从本质上讲,naive框架使用输入feature map上某个位置的单个特征向量来回归一个实例的所有关键点。这就意味着单个特征向量需要编码实例所需的所有信息。这是很困难的,因为许多关键点都远离特征向量感受野的中心,[18]已经表明,当输入信号偏离其感受野的中心时,特征响应的强度会迅速衰减。正如许多基于fcn的框架[9,17]所示,保持feature和prediction的一致性对于良好的性能至关重要。因此feature只需要在一个局部块中对信息进行编码就可以,这样就简单多了。
什么叫feature和prediction对齐?也许需要从9,17两篇文章中寻求答案。
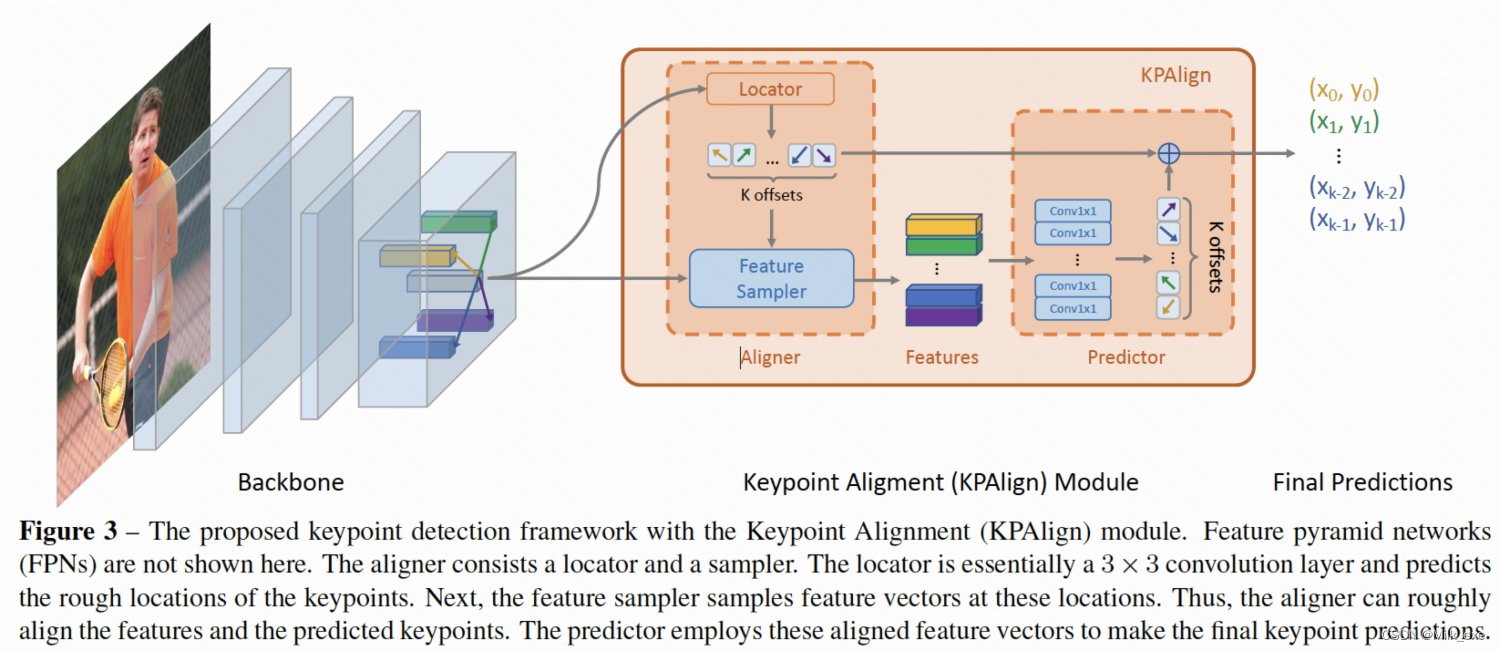
在这项工作中,我们提出了一个关键点对齐(KPAlign)模块来恢复框架中的feature-prediction对齐。在naive框架中使用KPAlign代替卷积层进行最后的关键点检测,并将相同的特征映射作为输入,表示为[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YseDNzYJ-1660271311877)(https://cdn.nlark.com/yuque/__latex/bee75b04fd3cf1597605c587a7f630cf.svg#card=math&code=F%20%5Cin%20%5Cmathbf%7BR%7D%5E%7BH%5Ctimes%20W%20%5Ctimes%20C%7D&id=nxppW)],其中C为256为特征映射的通道数。类似于卷积操作,KPAlign在feature map(F)上密集滑动。为了简单起见,我们以一个feature map(F)上的特定位置(i;j)来说明KPAlign是如何工作的。如图3所示,KPAlign由两部分组成:aligner和predictor。aligner包括locator和feature sampler,并输出对齐的特征向量。
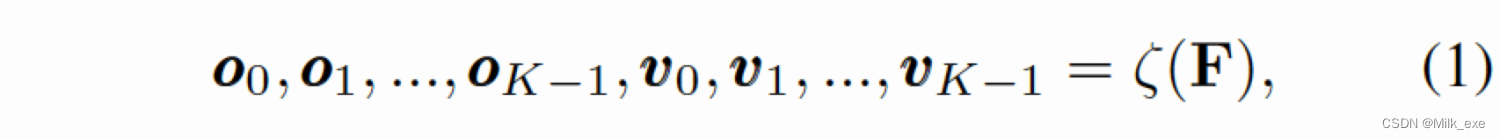
其中,由图3中的定位器产生的ot是用于预测实例第t个关键点的特征向量采样位置。vt为在该预测的位置采样后的特征向量。注意,位置ot是在正实数域上定义的,因此它可以是小数。根据[4,9]两篇文章,我们利用了双线性插值来计算分数阶位置的特征。此外,位置被编码为对于(i;j)的相对位置,因此是平移不变的。
接下来,预测器以aligner的输出作为输入,预测关键点的最终坐标。如图3所示,预测器包括K个卷积层(即每个关键点对应一个)。让我们假设我们正在寻找实例的第t个关键点,并让[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W8x6b50h-1660271311878)(https://cdn.nlark.com/yuque/__latex/8916c2173896c95404bd9f896cff28ee.svg#card=math&code=%5Cphi_t&id=YsQ0C)]表示预测器中的第t个卷积层。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u0XBUiha-1660271311878)(https://cdn.nlark.com/yuque/__latex/8916c2173896c95404bd9f896cff28ee.svg#card=math&code=%5Cphi_t&id=fJkC2)]以vt为输入,预测第t个关键点相对于vt采样位置的坐标(即ot)。最后,第t个关键点的坐标为两组坐标的和,记为xt。形式上可表达为:
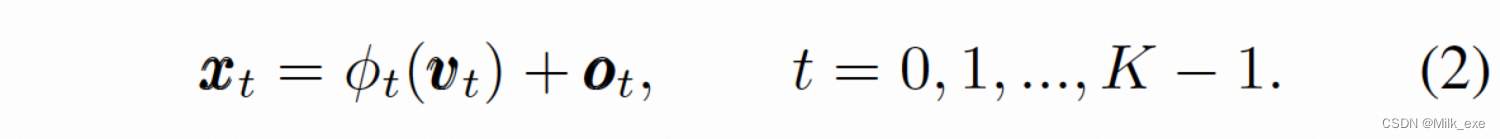
请注意,实际坐标需要通过对feature map(F)的下采样率重新缩放。为了简单起见,这里省略了重新缩放操作符。注意,KPAlign模块中的所有操作都是可微的,因此整个模型可以通过标准的反向传播以端到端的方式进行训练,这使我们的工作有别于之前自下而上或自上而下的关键点检测框架,如CMU-Pose[1]或Mask R-CNN[9]。端到端可训练也使定位器能够学习在没有明确监督的情况下定位关键点,这对KPAlign至关重要。
备注:naive framework由于feature-prediction未能对齐的缘故性能表现较差,故本文用了Aligner代替最后的卷基层进行关键点检测。Aligner的构成:locator->sampler->predictor。
对于第t个关键点来说:
locator用来粗略预测在feature map上的feature vector采样位置,sampler根据这个位置取得feature vector,之后这个vector将被真正用来预测精确的keypoint位置。
predictor由K(或者G)个卷基层构成(关键点数为K,分为G组)。
locator,sampler的结构尚不清楚。
Grouped KPAlign: 上面提到的KPAlign模块需要对K个关键点的采样K个特征向量。这实际上是不必要的,因为一些关键点(例如,鼻子,眼睛和耳朵)总是在一个地方。因此,我们提出将关键点分组,同一组中的关键点使用相同的特征向量,减少了K到G的采样特征向量的数量,达到了相似的性能,其中G为组的数量。
**Using Separate Convolutional Features: **在前面描述的KPAlign中,所有的关键点组都使用特征映射F作为输入。然而,我们发现,如果我们对G个keypoint组使用单独分开的feature map(即,使用Ft;t = 0,1,…,G-1)。这样,对单个Ft编码的信息的需求可以进一步降低。为了降低计算复杂度,我们将每个Ft的信道数设为C/4(即256 -> 64)。
**Where to Sample Features? **为了方便起见,前述aligner中的采样器对locator的输入特征图进行特征采样,因此预测器和定位器将相同的特征图作为输入。然而,由于定位器和预测器需要不同层次的特征图,因此这种方法并不合理。locator预测实例中所有关键点(或关键点组)的初始但不精确的位置,因此需要具有更大感受野的高层次特征。相比之下,predictor需要做出精确的预测,但只对局部区域的关键点进行预测,因为特征已经被aligner对齐了。因此,predictor倾向于具有较小感受野的高分辨率低层次特征。为此,我们将较低层次的特征图输入采样器。具体来说,如果定位器使用PL特征映射,而PL不是最细节的特征映射(感受野最小),那么采样器将把PL-1作为输入。如果PL已经是感受野最小的特征图,那么采样器找不到感受野更小分辨率更高的feature map,就会同locator同一层次进行采样。
注解:改进
Grouped KPAlign(由于部分关键点靠的比较近,所以其实这部分关键点可以共用特征向量,因此可以把关键点尽心分组以减少计算量)
Using Seperate Convolutional Feature(所有关键点分组共用一个大的feature vector,存在一些冗余信息,所以对不同分组使用降维的feature vector能够降低计算复杂度,且实验表明性能未有下降)
Sample Strategy(locator和predictor对输入的feature map的需求不同,因此调整它们的采样策略,locator需要高层次低分辨率大感受野的feature map,predictor需要低层次高分辨率精度高的feature map) -> 不知道具体怎么实现的。
2.3 Regularization from Heatmap Learning
众所周知,基于回归的任务学习困难[8,27],泛化能力差。这就是为什么以往几乎所有的关键点检测方法[1,9,29,26,19]都是基于热图预测,将关键点检测转化为像素对像素的预测任务。然而,由于涉及到基于热图的预测和需求的连续关键点坐标之间的不可微分转换,这种转换使得端到端训练不可行。因此,一个端到端的关键点检测框架必须是基于回归的,而不是基于热图的。
因此,我们需要寻求一种方法,使基于回归的任务更容易学习和推广。为此,考虑到基于热图的学习更容易,我们使用基于热图的预测任务作为辅助任务。因此,基于热图的任务可以作为基于回归的任务的提示,从而可以使模型更具泛化性。在我们的实验中,联合学习显著提高了基于回归的任务的性能。请注意,基于热图的任务仅用于训练期间的辅助损失。在测试时移除。
Heatmap Prediction: 如图2所示,热图预测任务以下采样比为8的FPN特征图P3作为输入。然后,在这里应用2个通道为128的3x3conv层,然后再应用一个输出通道为K的3x3conv层,用于最终的热图预测,其中K为每个实例的关键点数量。
(没太懂,这句话应该怎么解释)以前基于热图的关键点检测方法[1]生成以每个关键点为中心的非归一化高斯分布,因此以逐像素回归的方式生成热图。
相反,由于我们的框架在测试时不依赖于热图预测,为了简单起见,我们在这里执行逐像素分类。注意,我们使用了多个二进制分类器(即,1对所有),因此输出通道的数量是K,而不是K + 1。
Ground-truth Heatmaps and Loss Function: 真值热图按如下方式生成如下。在热图上,如果某个位置是距离类型为t的关键点最近的位置,则该位置的分类标签设为t,其中t \in {1, 2, …, K},否则标签设为0。最后,为了克服正负样品之间的不平衡,我们使用 focal loss(不了解) 作为损失函数。
注解:单纯的heatmap不能进行端到端的训练,但可以用来辅助DirectPose网络,提高泛化性。这部分没有太理解,因为不太理解heatmap机制。
3 Experiments
实验针对大规模基准化的COCO数据集[16]进行人工关键点检测任务。该数据集包含超过250K个person实例,其中包含17个带注释的关键点。按照惯例[1,9],我们使用COCO trainval35k split (57K图像)进行训练,并使用minival split (5K图像)作为消融实验的验证,test-dev split(20K图像)作为测试集。除非明确指定,否则我们只使用人工关键点标注而不使用边界框标注。我们采用**基于对象关键点相似度(OKS)的平均精度(AP)**算法进行性能计算。
Implementation Details: 除非指定,否则使用ResNet-50[10]作为我们的backbone。我们使用两种训练时间表。第一种是快速的,用于训练我们的模型在消融实验中的快速原型。其中,模型在8个V100 gpu上用随机梯度下降(SGD)训练25个epoch,批次为16幅图像。对于tes-dev split的主要结果,我们使用了较长的训练计划;这些模型用32张小批量图像训练了100个epoch。我们将初始学习率设置为0.01,并使用线性计划基数lr (1 iter max iter)来衰减它。权重衰减和动量分别设为0.0001和0.9。我们使用ImageNet[5]上预训练的权重初始化我们的骨干网。
3.1 Ablation Experiments
3.1.1 Baseline: the naive end-to-end framework
采用naive keypoint detection framwork做了实验,结构上同FCOS的区别仅在于把最后的bounding-box head替换成了keypoint detection head,实验结果显示性能较差;
3.1.2 Keypoint alignment(KPAlign) module
加上了KPAlign模块之后的两个实验:
- 完整的KPAlign模块:实验结果显示AP有较大提高;
- 禁用KPAlign的aligner模块:显示AP和naive framework差不多,这个实验排除了framework with KPAlign网络因为层数增多导致AP提高的可能。
由以上两者,可以很确定的说:正是因为KPAlign的存在才使得AP有大的提高。
3.1.3 Grouped KPAlign
按照之前设计,K(K=17)个关键点因为部分可能比较密集所以并不需要K个特征向量,所以这部分将KPAlign模块K个keypoints分成G组,特征向量也就只需要变成G(G=9)组,加快速度。根据实验结果发现,改进后与改进前性能相当。
These groups respectively include (nose, left eye, right eye, left ear, right ear), (left shoulder, ), (left elbow, left wrist), (right shoulder, ), (right elbow, right wrist), (left hip, ), (left knee, left ankle), (right hip, ) and (right knee, right ankle)这些组分别是(鼻子、左眼、右眼、左耳、右耳)、(左肩、)、(左肘、左腕)、(右肩、)、(右肘、右腕)、(左臀、)、(左膝、左脚踝)、(右臀、)和(右膝、右脚踝)。
3.1.4 Using separate convolutional features
这部分是模型进一步的优化,每组输入的input vector不再是一样的256 维,而是输入各自分开,且降维至64维。实验结果表明,在上一个改进的基础上,AP再次提高了0.8%。
3.1.5 Where to sample features in KPAlign?
考虑到locator需要低分辨率高层次的feature map以获得更大的感受野,predictor需要高分辨率低层次的feature map以获得更高的精度,模型在以上优化的基础上进一步改善采样策略(没有增加计算复杂度),结果表明各项性能有显著提高。
3.1.6 Regularization from heatmap learning
在上一步的基础上进一步联合heatmap prediction正则化做了3个实验
实验一以下采样率为8的输入做了heatmap训练,最后结果显示性能有大的提高;
实验二在一的基础上进一步提高了下采样率,结果显示性能没有太大差异,表明在该框架中性能对heatmap的设计并不敏感。这与其他自底向上的heatmap-based方法(性能对设计较敏感)相比有较大的差别。
实验三:出于先前的heatmap-based方法训练时用了更多的epoch,而本文的方法高度不拟合,因此通过增加训练epoch数量进行了新的对比实验,结果发现性能确实有所增长。
3.2 Combining with Bounding Box Detection
实验:通过加入bounding box head进一步验证框架具备着同时检测bounding box和keypoints的能力,且性能和Faster R-CNN,Mask R-CNN相当。尽管Mask R-CNN也能同时检测box和keypoints,但本框架将这二者统一到了同一方法论中。
3.3 Comparisons with State-of-the-art Methods
利用了前面消融实验中表现最好的模型,分别以Resnet-50/Resnet-101为backbone,在MS-COCO test-dev split测试集做了测试并和其他网络做了比对。
Compared to Bottom-Up Methods
同Bottom-Up Methods一些方法比有相当的竞争力,虽然在性能上未能完全超越Bottom-up方法,但本方法的优点胜在训练和测试上更加简单。
Compared to Top-Down Methods
性能和Mask R-CNN相当,但仍然赶不上SOTA。文中着重强调其他方法都不是single-stage方法,而本方法将raw image直接映射成keypoints这一点是非常值得肯定的,更简单,更快。
Timing
实验结果显示本网络在同样数据集/backbone情况下,推理时间上略胜于Mask R-CNN。Mask R-CNN的运行时间还和实例有关,而本网络是常数级时间。
4 More Discussions and Results
- 我们进一步比较我们提出的DirectPose与最近的SPM方法[20]。
2)展示了提出的KPAlign模块的可视化结果。
3)给出了有或没有热图学习的训练损失曲线。
4)我们给出了有或没有同时边界盒检测的最终检测结果。
4.1 Compare to SPM
SPM(Single-Stage Multi-Person Pose Machine):这里,我们强调了我们建议的DirectPose和SPM[20]之间的区别。SPM利用**层次结构姿态表示(Hierarchical Structured Pose representation, Hierarchical SPR)**来避免学习根节点和关键点之间的远程位移,这与我们提出的KPAlign有相似的动机。然而,SPM将分层SPR中的所有关键节点(包括根节点和中间节点)作为回归目标,并使用实例不可知热图对这些节点进行预测。这类似于OpenPose[1],唯一的例外是SPM预测这些节点而不是最后的关键点,因此预测的节点也是与实例无关的。因此,SPM仍然需要进行分组后处理,将检测到的节点组装成全身姿态。相比之下,我们提出的KPAlign只需要最后关键点的坐标作为监督,并且以一种无监督的方式将特征和预测关键点对齐。因此,我们提出的框架可以直接预测所需的实例感知关键点,而不需要任何形式的分组后处理。
4.2 Visualization of KPAlign
KPAlign可视化结果如图5所示。如图所示,我们提出的KPAlign可以利用关键点附近的特征来预测关键点。因此,特征向量可以避免对关键点进行远离其空间位置的编码,从而提高性能。(还是没搞懂为什么为什么是对附近的特征编码)

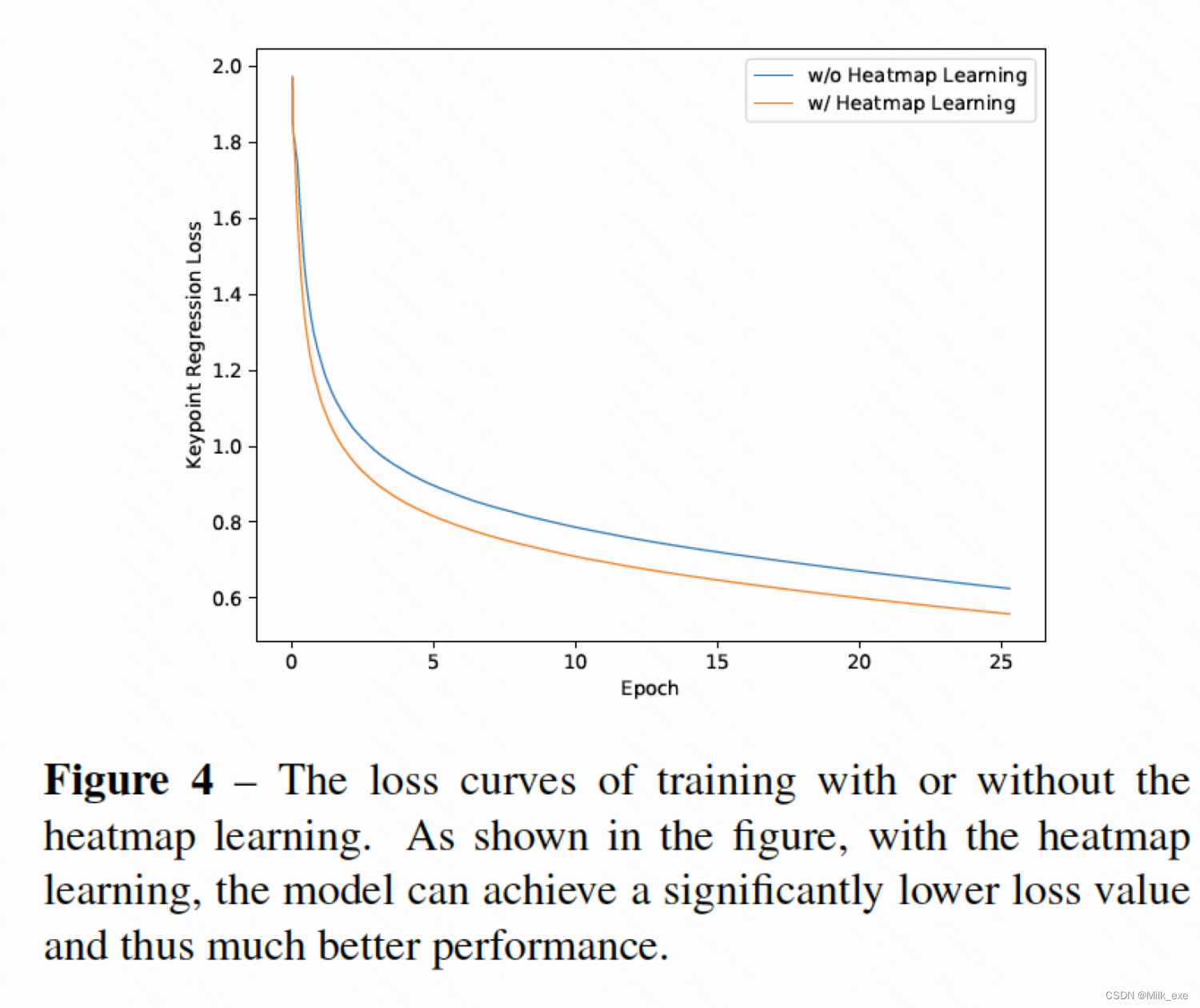
4.3 Training Losses of using Heatmap Learning
为了说明热图学习的影响,我们在图4中绘制了有热图学习和没有热图学习的训练损失曲线。如图所示,热图学习可以极大地帮助模型的训练,使模型获得更低的损失值,从而获得更好的性能。
4.4 Visualization of Keypoint Detections
我们在图6中展示了DirectPose更多的可视化结果。如图所示,本文提出的Direct- Pose可以直接检测出所有需要的实例感知关键点,而不需要进行分组后处理和边界框检测。图7还给出了同时进行边界盒检测的DirectPose算法的结果。


5 Conclusion
我们提出了第一个直接的端到端人体姿态估计框架,称为DirectPose。我们提出的模型是端到端可训练的,可以在常熟市的推理时间内直接将原始输入图像映射到所需的实例感知关键点检测,消除了自下而上方法中的分组后处理或自上而下方法中的边界框检测和RoI操作。我们还提出了关键点对齐(KPAlign)模块,以克服端到端模型中卷积特征与预测之间缺乏对齐的主要困难,显著提高了关键点检测性能。此外,我们通过与基于热图的任务共同学习,进一步提高了基于回归的任务的性能。实验结果表明,该方法比传统的自底向上和自顶向下方法具有更好的性能。
— 以下为英文总结—
Model
The model in this paper is improved based on FCOS. The main improvement is that the head used for object detection is changed into the head used for keypoints detection in FCOS, and the number of output channels is also changed from 4 to 2K. K represents the number of target detection, and 2 represents coordinate of each keypoint which is composed of two scalar data.
Keypoints Detection Head
The model structure is: Backbone->FPN->Keypoints_Detections_Head(from FCOS->Objection_Detection_Head). Backbone is resnet-50 / resnet-101. We called this changed network naive framework and further changes are made on it due to inferior performance.
Aligner
Author thinks that naive framework has poor performance due to the failure of feature-prediction alignment, so Aligner is used in this paper instead of the final convoluntional layer for key point detection. Aligner formation: Locator -> Sampler -> Predictor.
For the tth point: The locator is used to roughly predict the sampling position of the feature vector on the feature map. Sampler obtains the feature vector according to this position, and then the vector will be really used to predict the exact Keypoint location.
Predictor consists of K (or G) conv-layer (K key points, divided into G groups).
The structure of the Sampler and locator are unclear. I think I may need to read FCOS intensively. Do you think so?
Further optimization
Grouped KPAlign: Grouped keypoints are Grouped so closely that they can maybe share eigenvectors. Therefore, key points can be carefully grouped to reduce computation.
Using Seperate Convolutional Feature: all key point groups share a large feature vector, and there is some redundant information for each individual group, so using dimensionality reduced feature vector for different groups can reduce the computational complexity. And the experiment shows that the performance does not decrease.
Sample Strategy: Locator and Predictor have different requirements on the input feature map, so their sampling strategies should be adjusted. Locator requires a feature map with high level, low resolution and large receptive field. Predictor requires a low-level, high-resolution, high-precision feature map.
Now I don’t know how that works by the code. Perhaps I need to reproduce the code, but time is too short to reproduce every paper. I wonder if you could give me some advice on the priority of reproducing papers.
Experiments
Baseline-the naive end-to-end framework
Naive Keypoint detection Framwork was used to do the experiment. The only difference between FCOS and Naive Keypoint Detection Framwork is that the last bounding-box head is replaced by Keypoint Detection head, and the experimental results show low performance.
Keypoint alignment(KPAlign) module
Two experiments after adding the KPAlign module:
- Complete KPAlign module: experimental results show that AP has a great improvement;
- Disable KPAlign’s Aligner module: It shows that the AP is similar to Naive Framework. This experiment excludes the possibility that the Framework with KPAlign network has increased AP because of the increased number of layers.
From the above two, we can say with certainty that it is because of the existence of KPAlign that AP has been greatly improved.
Grouped KPAlign
According to the previous design, K (K=17) keypoints do not need K feature vectors because some parts may be dense, so in this part, K keypoints of KPAlign module are divided into G group, and the feature vectors only need to be changed into G(G=9) group to speed up the process. According to the experimental results, it is found that the performance is comparable to that before grouping.
Notes: These groups respectively include (nose, left eye, right eye, left ear, right ear), (left shoulder, ), (left elbow, left wrist), (right shoulder, ), (right elbow, right wrist), (left hip, ), (left knee, left ankle), (right hip, The groups are (nose, left eye, right eye, left ear, right ear), (left shoulder,), (left elbow, left wrist), (right shoulder,), (right elbow, right wrist), (left hip,), (left knee, left ankle), (right hip,) and (right knee, right ankle).
Using separate convolutional features
This part is a further optimization of the model. Instead of the same 256-dimensional input vector for each set of inputs, the inputs are separated and the dimensions are reduced to 64 dimensions. The experimental results show that on the basis of the previous improvement, AP is improved again by 0.8%.
Where to Sample Features in KPAlign?
Considering that a locator requires a low-resolution, high-level feature map to obtain a larger receptive field, Predictor requires a high-resolution, low-level feature map to achieve higher accuracy. Based on the above optimization, the model further improves the sampling strategy (without increasing the computational complexity). The results show that the performance has been significantly improved.
Regularization from Heatmap Learning
On the basis of the previous step, three experiments are carried out with Heatmap prediction regularization.
- Experiment 1: heatmap was training for the input with a sample rate of 8, and the final result showed that the performance improved greatly.
- Experiment 2: further improves the downsampling rate on the basis of Experiment 1, and the results show that there is no significant difference in performance, indicating that the performance is not sensitive to the design of Heatmap in this framework. This is quite different from the other bottom-up heatmap-based methods, where performance is design-sensitive.
- Experiment 3: Because the previous HeatMAP-based method used more epochs in training, while the method in this paper is highly under-fitting, a new comparison experiment was conducted by increasing the number of training epochs, and the results showed that the performance did increase.
Combining with Bounding Box Detection
The bounding box head was added to further verify the ability of the framework to simultaneously detect bounding box and keypoints, and its performance is comparable to that of Faster R-CNN and Mask R-CNN. Although Mask R-CNN can also detect both boxes and keypoints, this framework unifies both into the same methodology.
Compared With state-of-the-art Methods
The models with the best performance in the previous ablation experiments were used. Resnet-50/Resnet-101 were used as backbone, and tested in the MS-Coco test-dev split testset and compared with other networks.
- Compared to Bottom-Up Methods: Compared with some bottom-up Methods, this method is competitive. Although it does not completely surpass bottom-up Methods in performance, the advantages of this method are simpler in training and testing.
- Compared to Top-Down Methods: Performance is comparable to Mask R-CNN, but still not as good as SOTA. This paper emphasizes that other methods are not single-stage methods, but this method directly maps raw images into keypoints, which is very worthy of affirmation, simpler and faster.
- Timing: The experimental results show that the inference time of this network is slightly better than that of Mask R-CNN on the same data set /backbone. The running time of Mask R-CNN is also related to the instance, while the network is a constant time.
Discussion
The Discussion part further makes some comparisons:
- We further compared our proposed DirectPose with the SPM method [20].
- Visualization results of the proposed KPAlign module are shown.
- Training loss curves with and without heat map learning are presented.
- the final detection results with or without simultaneous bounding box detection.
My Questions:
- How does a locator work? What is Feature-Prediction Mismatch/Alignment?
- I don’t know about Headmap, which is my blind spot.
- How does KPAlign use features near key points to predict key points?
PS. Relevant model architecture diagrams and experimental results are shown below.
The above are my summary and the following are some translations and notes/questions I made during the reading.
以下是原文翻译及我的注解和疑问,以上是我的英文总结。
















 3469
3469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











