







简介
集成学习基本的理解就是对于选择出来的分类算法,求出不同训练集的概率求方差,这里的集成学习由于使用的分类算法是抉择树(和逻辑回归类似的一种分类模型),所以集成学习的时候形象的表示多个抉择树模型求方差的值,从而减低抉择树过拟合的缺点。
描述
下图的f1和f2表示的不同分类模型的算法。得到的最后的结果就是集成学习的效果。
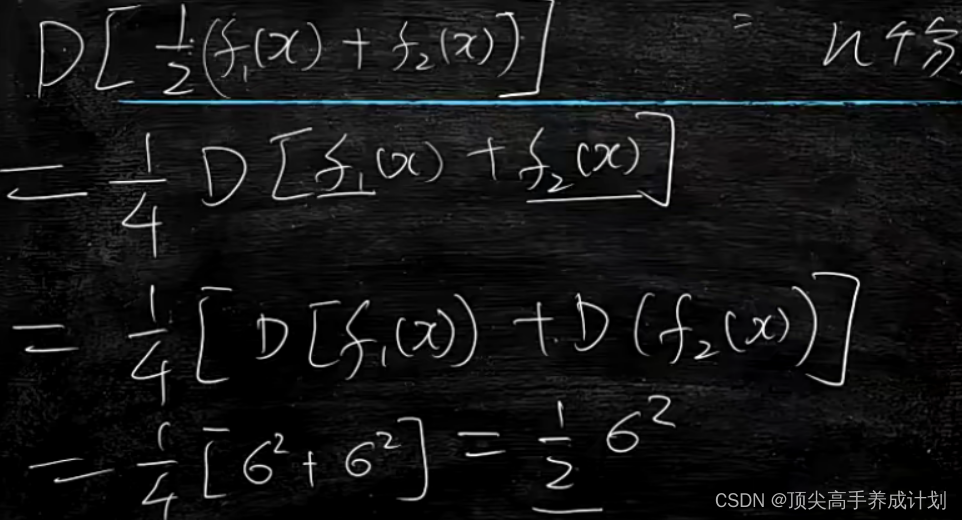
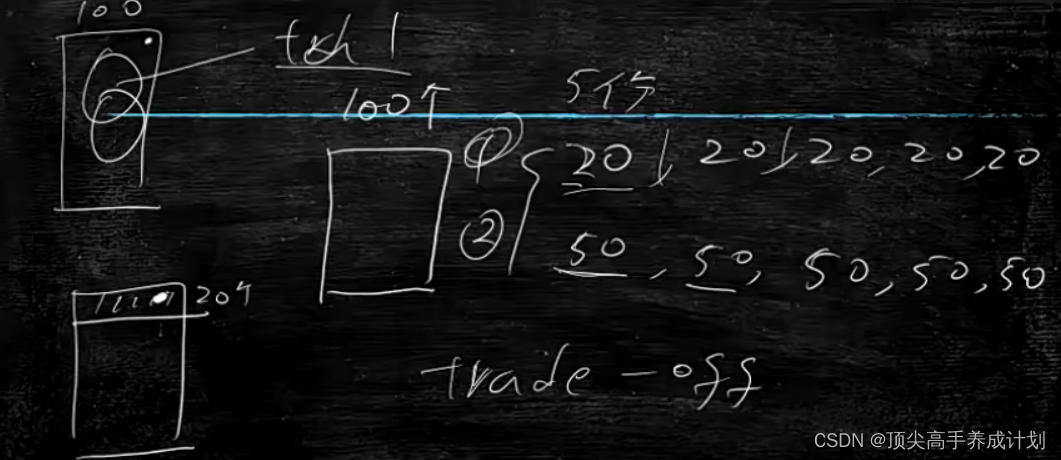
下面举一个例子,比如下面有100个训练集数据,每一个抉择树算法都选取一定的数据进行模型训练,有随机取20的情况,和分成5份,分别取20的情况。如果想训练的效果要好而且要更加的有范化性,那么首先要满足独立性,也就是随机的选20独立性要好,还有就是要想范化性好,那么随机取20的范化性要比随机每一个模型取50要好,因为取50包含了 太多其他模型训练的数据,训练结果好,但是范化能力就会减低,这也就是trade-off原理,总是会牺牲一点来提高另一边。
下面是集成树和抉择树的关系,每一个f(x)就是一个抉择树模型概率,每一个抉择树最后的方差也就是随机森林的结果。
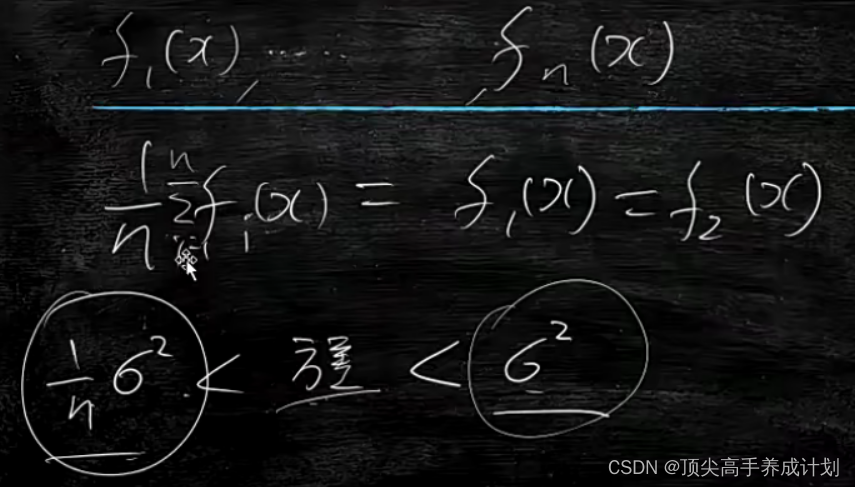
训练效果不好解决办法

















 40
40











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











