






简介
期望最大化(Expectation-Maximization)算法最初是由Ceppellini等人1950年提出的,目前引用的较多的是1977年Dempster等人的工作。其主要用于从不完整的数据中计算最大似然估计,是一个在含有隐变量的模型中常用的算法,比如最大似然估计(MLE)和最大后验估计(MAP)。在GMM、HMM、PCFG、机器翻译对齐模型以及K-Means聚类方法中均有它的影子。
预备知识
为了理解便利,复习以下最大似然,Jensen不等式相关概念。
最大似然
假设通过抽样调查学校男生的身高分布,我们随机挑选100个男生统计他们的身高。假设身高服从高斯分布 p(x|μ,σ) ,但是这个分布的参数(均值 μ 和方差 σ2 )事前是不知道的。
那么这两个参数该如何确定呢?这个问题先放一放。我们先看另一个问题,取到这100个男生身高的概率是多少?
首先,假设每个抽取到的男生身高是独立地从高斯分布 p(x|μ,σ) 中抽取出来的(记 θ=[μ,σ]T ),则高斯分布为 p(x|θ) ),那么抽到这100个男生的概率则为:
L(θ)=L(x1,⋯,xn;θ)=∏i=1np(xi;θ),θ∈Θ
其中
xi
表示第
i
个男生的身高,
这个函数反映的是在不同的参数 θ 取值下,取得当前这个样本集的可能性。我们称这个函数为参数 θ 相对于样本集X的似然函数(likehood function)。
我们让抽到这100个男生身高出现的概率最大,即需要找到一个参数 θ ,使似然函数 L(θ) 最大(符号描述为 θ^=argmaxl(θ) )。为了便于求解对似然函数取对数:
H(θ)=lnL(θ)=ln∏i=1np(xi;θ)=∑i=1nlnp(xi;θ)
要使 θ 的似然函数 L(θ) 极大化,也就是通过函数求导令导数为0,构建关于 θ 的方程组,最后对方程组进行求解(前提是 L(θ) 连续可微)。当 θ 是包含多个参数的向量时,求 L(θ)的梯度 。
求最大似然函数估计值的一般步骤:
1. 定义分布(分布的函数形式),写出似然函数;
2. 对似然函数取对数,并整理;
3. 求导数,令导数为0,得到似然方程;
4. 解似然方程,得到的参数即为所求。
Jensen不等式
设
f
是定义域为实数的函数,如果对于所有的实数
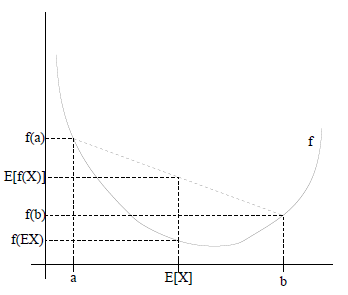
图中,实线
f
是凸函数,
EM算法的实例描述
接着上面学生身高的例子,我们将问题再复杂一点。现在我们随机挑选100个男生100个女生,我们将他们混在一起,不知道每个样例是男生还是女生,这是我们需要估计:1. 男生身高正态分布的参数; 2. 女生身高正态分布的参数; 3. 样例是男是女的概率分布。
当估计两个正态分布的参数时,需要将样例划分为男生身高集合和女生身高集合,然后在男生集合和女生集合分别利用最大似然估计来估计参数。
当在划分样例到男生集合和女生集合时,我们需要将样例身高分别代入到分布中,比较在两个分布中该样例出现的概率大小以确定样例是男是女。
这就成了一个先有鸡还是先有蛋的问题了,即要估计两个分布参数,需要先判定所有样例是男是女。要知道是男是女,先要知道分布的参数。EM算法针对这样的问题给出了解决方案。
对于上面的例子,首先随便猜两个正态分布的参数,每个样例就可以进行男女判定,这是Expectation步骤。每个样例有了性别归属后,根据之前说的极大似然,分别用男生身高样例估计男生身高正态分布参数,女生身高样例估计女生身高正态分布参数,这个是Maximization步骤。然后,当我们更新了这两个分布的时候,身高样例是男是女的概率又变了,那么我们就再需要调整E步……如此往复,直到参数基本不再发生变化为止。下面给出EM算法的推导过程。
EM算法推导
假设:
{x(1),x(2),⋯,x(m)} 为样例集合(上标表示第 i 个样例),且样例间相互独立, 每个
x(i)为一个随机变量 。{z(1),z(2),⋯,z(m)} ,其中 z(i) 表示第 i 个样例的隐含类别,也是一个随机变量。
Q 为样例的隐含类别分布, Q 满足的条件是∑z(i)Q(z(i))=1,Q(z(i))≥0 (如果 z(i) 是连续性的,那么 Q 是概率密度函数,需要将求和符号换做积分符号。)
由上述描述可得:
从等式到不等式利用了jensen不等式:
a. log(x) 是凹函数(二阶导 −1x2<0 ),则有 E[log(X)]≤log(EX)
b. 令 p(k)=Q(z(i)) , g(z(i))=p(x(i),z(i);θ)Q(z(i))
c. 则log∑z(i)Q(z(i))p(x(i),z(i);θ)Q(z(i))==log∑z(i)g(z(i))p(k)log(E(g(z(i))))
d. 由log(E(g(z(i))))≥=E[log(g(z(i)))]∑z(i)Q(z(i))logp(x(i),z(i);θ)Q(z(i))e. 故得 log∑z(i)Q(z(i))p(x(i),z(i);θ)Q(z(i))≥∑z(i)Q(z(i))logp(x(i),z(i);θ)Q(z(i))
现将不等式改写为 L(θ)≥J(z,Q) ,那么可以通过不断的最大化下界 J(z,Q) ,来使得 L(θ) 不断提高,最终达到它的最大值。
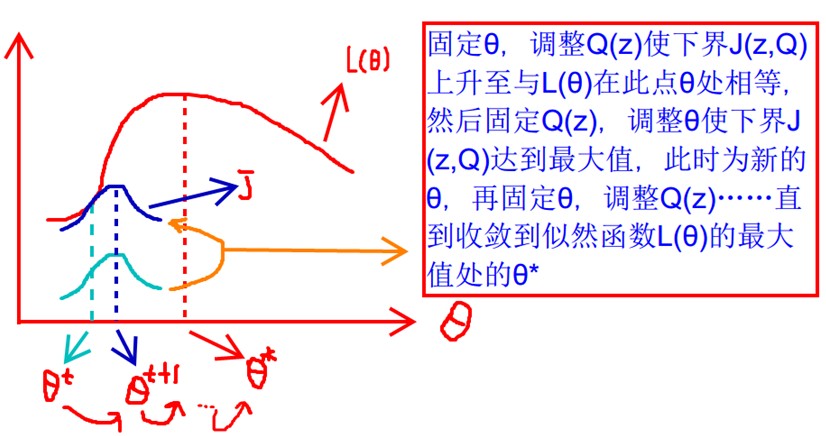
首先固定 θ (对应于上例就是确定两个分布的参数),调整 Q(z) 使下界 J(z,Q) 上升至与 L(θ) 在此点 θ 处相等(绿色曲线到蓝色曲线),这个过程对应Expectation步骤。
然后固定 Q(z) ,调整θ使下界 J(z,Q) 达到最大值( θt 到 θt+1 ),这个过程对应于Maximization步骤。
然后再固定 θ ,调整 Q(z)⋯ 直到收敛到似然函数 L(θ) 的最大值处的 θ∗ 。
那么每次迭代什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价 L(θ) ,按照这个思路,我们要找到等式成立的条件。在Jensen不等式中说到,当自变量X是常数的时候, E[log(X)]=log(EX) 等式成立。而在这里, X=g(z(i))=p(x(i),z(i);θ)Q(z(i))=c 。
再推导下,由于 ∑zQ(z(i))=1 ,则得到分子的和等于c。
p(x(i),z(i);θ)=c⋅Q(z(i))
∑zp(x(i),z(i);θ)=∑zc⋅Q(z(i))=c∑zQ(z(i))=c
则:
Q(z(i))====p(x(i),z(i);θ)cp(x(i),z(i);θ)∑zp(x(i),z(i);θ)p(x(i),z(i);θ)p(x(i);θ)p(z(i)|x(i);θ)
至此,我们推出了在固定参数 θ 后,使下界拉升的 Q(z) 的计算公式就是后验概率,解决了 Q(z) 如何选择的问题,这就是Expectation步骤,建立了 L(θ) 的下界。
接下来的Maximization步骤,就是在给定
Q(z)
后,调整
θ
,去极大化
L(θ)
的下界
J
(在固定
EM算法的流程
1、初始化分布的参数
θ
2、E步骤:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:
Q(z(i))=p(z(i)|x(i);θ)
3、M步骤:将似然函数最大化以获得新的参数值:
θ=argmaxθ∑i∑z(i)Q(z(i))logp(x(i),z(i);θ)Q(z(i))
4、这个不断的迭代,就可以得到使似然函数L(θ)最大化的参数θ了。
EM的收敛性说明
感性的说,因为下界不断提高,所以极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。理性分析的话,就会得到下面的东西:
参考资料:
http://blog.csdn.net/zouxy09/article/details/8537620
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
http://www.tuicool.com/articles/Av6NVzy
http://wenku.baidu.com/link?url=sp9YuoMsTErNUW6lHmnt2P5frnrMYbUQiLvuGo9R4qKDMgiYqUTPTOJIBNCjb5emAJc7WNhbyLFemCXX2F4lc2y90QjUVdtGcs7VexHbEei
http://luowei828.blog.163.com/blog/static/3103120420120142193960/
http://www.cnblogs.com/zhengyuhong/articles/3461639.html
http://www.52nlp.cn/tag/em%E7%AE%97%E6%B3%95
http://www.cnblogs.com/tornadomeet/archive/2012/07/14/2591685.html
http://blog.csdn.net/abcjennifer/article/details/8198352
http://blog.163.com/huai_jing@126/blog/static/17186198320119231094873/















 1627
1627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









