






目录
引言
我们知道,C++很多东西都是用来弥补C语言的不足的,像上节讲的 “命名空间、缺省参数、函数重载 及引用 ” 都是对C的补充,有兴趣的老铁可以看看我的上篇博客。
C++的命名空间、缺省参数、函数重载 及引用_SAKURAjinx的博客-CSDN博客
今天讲的四个东西也是对C的补充。
内联函数

内联函数以inline修饰,会在调用时展开。
我们可以先来观察一下:(这里我用的是VS2019平台)
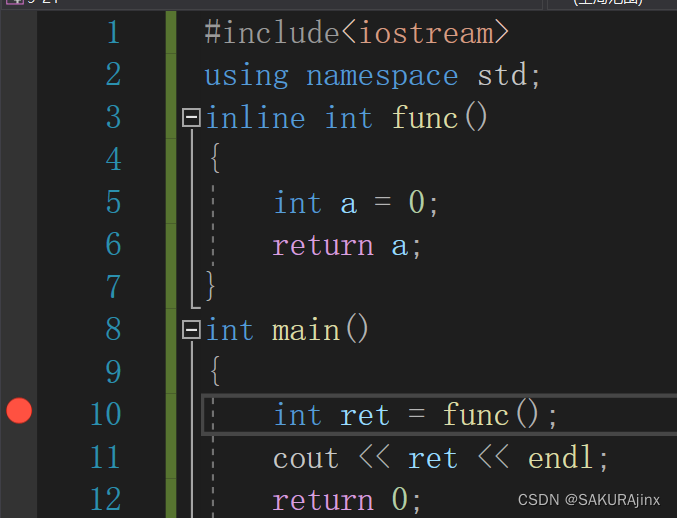
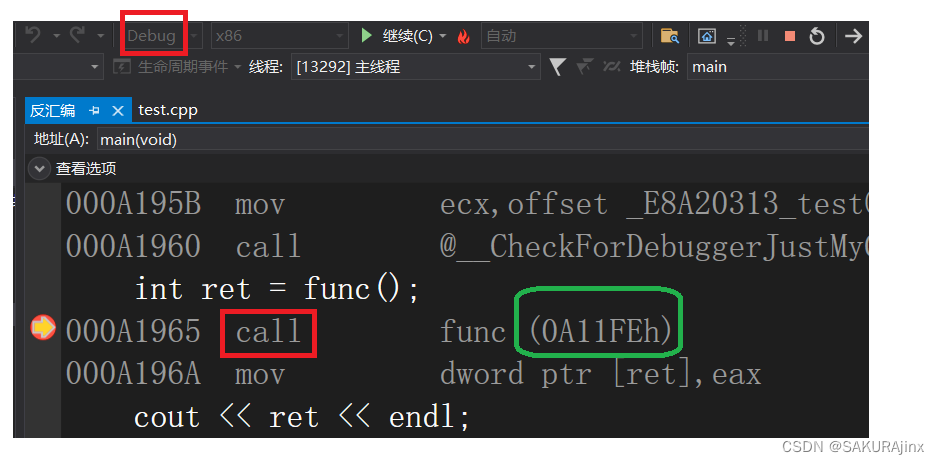
一段非常简单的代码,用inline 修饰 func函数。进入反汇编,我们发现,main函数还是调用了func函数,call了func函数的地址,没有按我们上面说的直接展开,这是因为在debug版本下,默认支持调试代码,所以不能直接展开函数(无法调试),因此,我们微调一下编译器属性,使得能看到展开情况。
一、先鼠标右击项目工程,找到属性。

二、找到C/C++常规,将调试信息格式改为程序数据库。
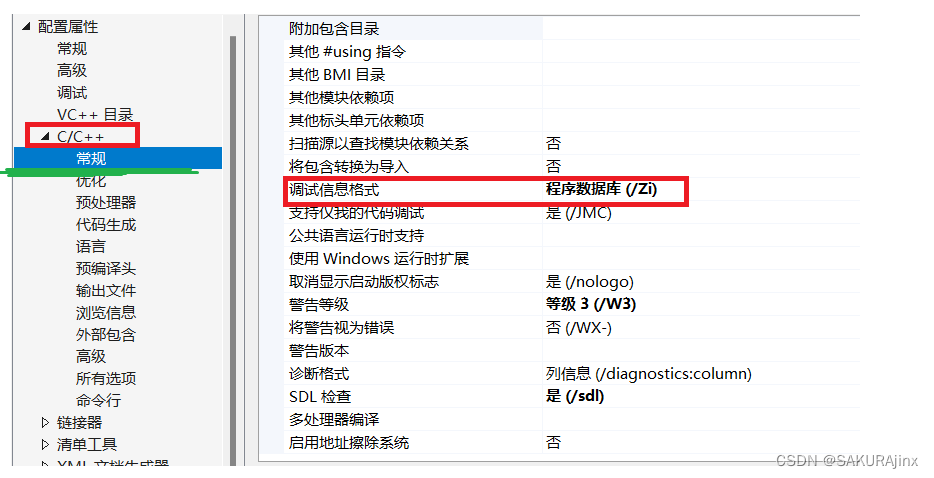
三、找到优化,将内联函数扩展改为...即可。
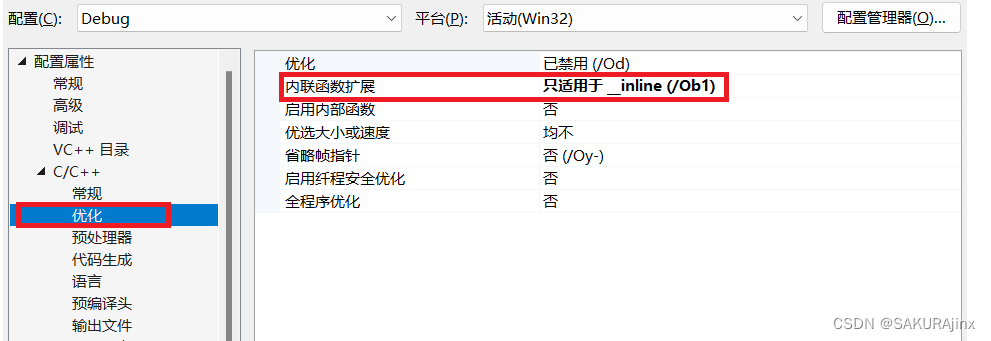
再次转到反汇编,我们可以观察到,这次没有再调用func函数,而是直接展开了。
我们看到此时func函数调用没有call它的地址,没有建立栈帧,可以说明inline修饰函数会使其直接展开,不建立栈帧。
展开是展开了,那有什么优势呢?——这样做的话可以提高程序运行效率。因为调用函数的时候需要建立栈帧及产生压栈的开销,直接展开就省去了调用栈帧的损耗。
引言里说了,C++弥补了C的不足,那C语言对函数调用这一块难道没有优化的方法吗?——
其实也有,就是宏函数。
define定义常量和宏 以及 寄存器关键字register_SAKURAjinx的博客-CSDN博客_define 数组常量
但是宏函数有它的缺陷:
1、宏不支持调试,宏是在编译的预处理过程中展开替换的,调试是编译后。
2、宏不会进行类型检查,他不知道里面的变量是int 还是 double型的。
3、宏容易写错。
至于为什么容易写错,拿一个简单的Add函数举例:
#define ADD (x,y) ((x)+(y))正确的写法如上所示,但是很多老铁在写的时候会犯三种经典错误。
1、不加外面的括号
#define ADD(x,y) x+y
int main()
{
ADD(1, 2)* 3;
return 0;
}宏类似于替换文本,将1,2带入进函数,就变成1+2*3= 7。
2、不加里面的括号
#define ADD(x,y) (x+y)
int main()
{
int a = 1, b = 2;
ADD(a & b , a | b);
return 0;
}因为+的优先级高于& 和 | ,所以带入函数会先将b和a相加,在进行&、| 的运算。
3、在宏函数后加 ;
#define ADD(x,y) ((x)+(y));
int main()
{
if(ADD(1,2))
{ }
return 0;
}也是一样,将1,2带入函数,但是此时分号也在 if 语句里面了,会报错。
综上,C语言的宏函数存在一系列问题,《effective c++》139页的一项条款解释:C++通常使用内联函数inline 、const、enum(枚举)解决这一问题。
那么内联函数是不是在所有地方都适用呢?————显然不是,有的地方使用inline也会造成巨大的负担。不是所有函数前面加inline都可以展开的。

就像递归,肯定是不能展开的,那样太过庞大了。
比如有一个100行的代码,我们调用它1000次,如果平常调用,开辟栈帧的话,是调用1000+100行指令(开辟栈帧1000行指令,原本代码100行),但如果用inline展开,就要调用100*1000行指令。这样造成了代码膨胀,会使得可执行程序 .exe文件过大。
上面图里第一行所说的inline以空间换时间,空间是指编译出来的可执行程序,也就是.exe文件或者动态库、静态库的空间,以游戏更新为例,如果将一处多次调用(假设1000次)的函数(假设100行)用inline修饰,那么编译的时候展开就使目标文件变大很多,游戏本来只要更新200MB的,结果到处有这种内联函数展开,变成更新1GB了,就是这种意思。
所以我们得出结论:inline只有非递归的短小代码(一般10行以内,具体看编译器)才能展开,如果是递归或者代码过长,就算在函数前加了inline,编译器也不会展开的。比较inline指令只是作为编译器的参考,具体执不执行,还是看编译器。
内联函数声明和定义是不能分离的。
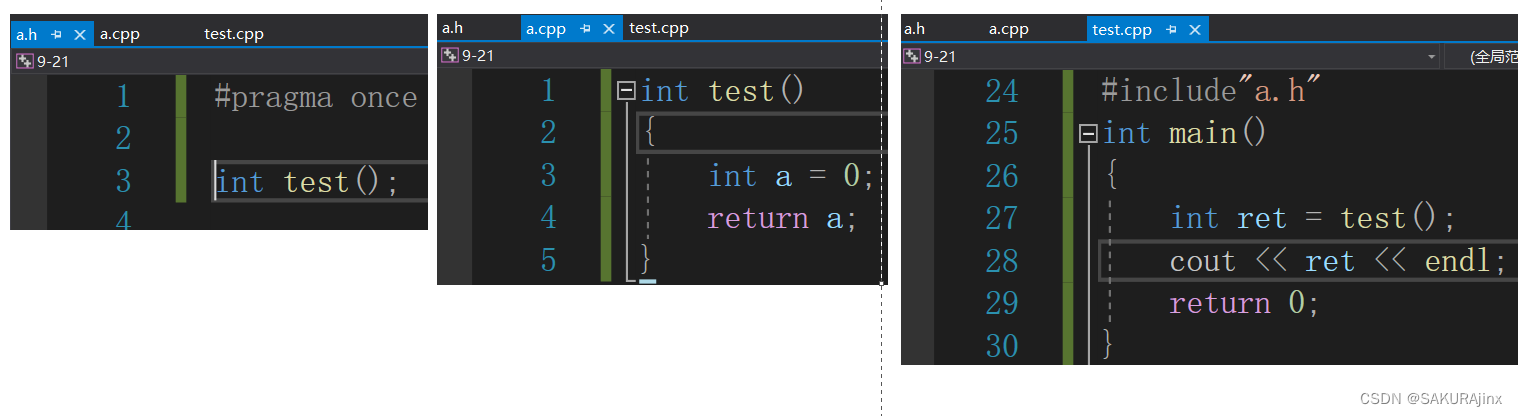
这是一个正常的test函数的调用。
如果加上inline修饰,那么就会报错,编译器不认识这个test函数。
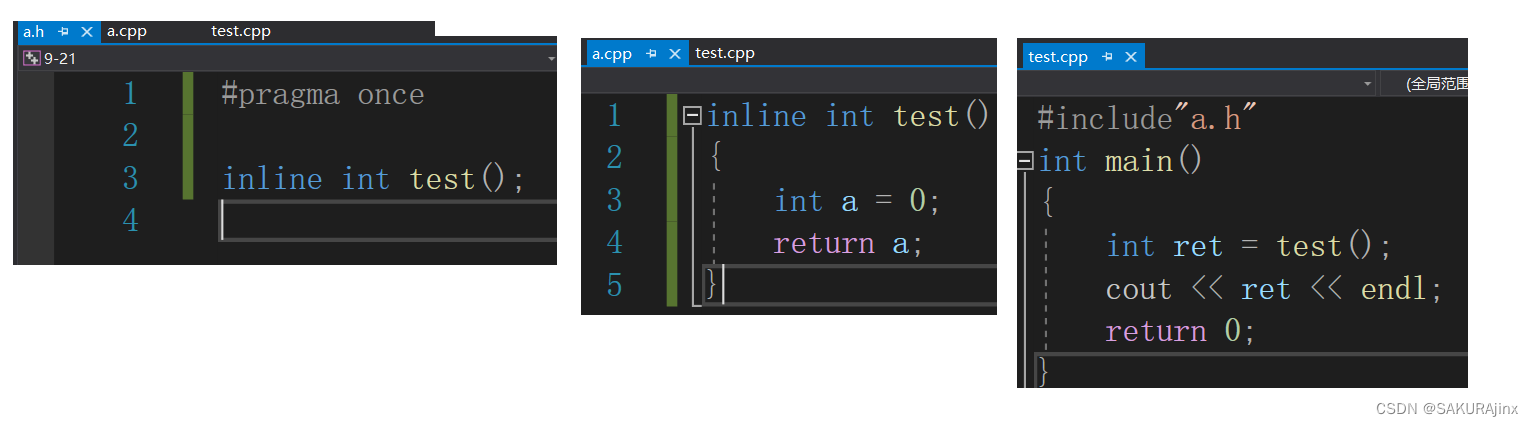
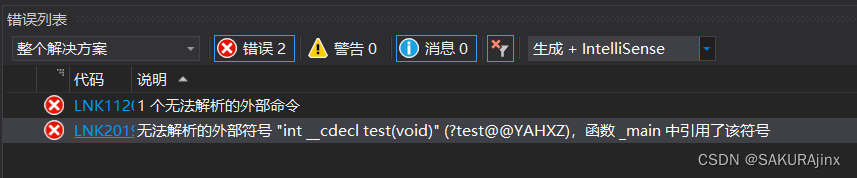
这是因为,在编译执行之前的预处理阶段,#include"a.h" 头文件就展开了,相当于在 a.cpp 和 test.cpp文件里第一句就是test函数声明,在调用test函数时,会先去找test函数的地址,而此时因为只有test函数的声明,没有定义(定义在a.cpp文件里),所以此时反汇编代码里call test函数里面保存的不是test函数的地址,而是其他符号串,也就是说找不到test的地址。
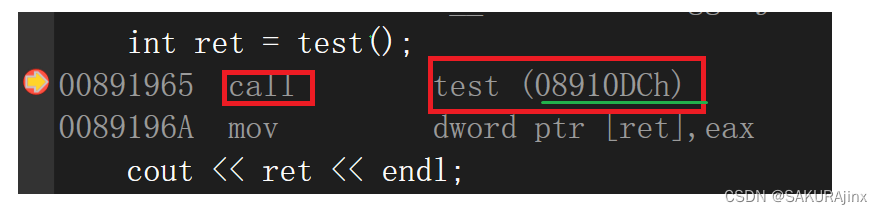
那为什么编译能通过呢?————因为编译是查看是否存在语法错误,函数定义是否存在由链接环节判定。编译器看到上面有test函数的声明,所以他会在链接的过程中去找test函数的地址。
链接过程不仅能将不同文件链接到一起,还能提供函数在其他文件的定义以便寻找地址,C语言中是用函数名到符号表里找地址,而C++是用函数名参数首字母规则到符号表找地址。于是在链接过程中,test函数的地址就在符号表里被找到了。
至于inline修饰的内联函数会在链接过程中出问题,是因为编译器知道inline函数肯定会展开,没人会调用(call地址),所以不会在符号表里保存它的地址,因此没有地址就报链接错误了。
auto关键字
C++里面有63个关键字,几乎是C语言的一倍。
今天我们来说一下auto。
一、
auto是自动识别变量的类型,然后在编译之前用相应的类型替换auto,好处是当不知道变量的类型时,可以用auto来代替,它可以自动识别。
int main()
{
int x = 0;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
return 0;
}
需要注意的是,auto识别指针,可以auto a, 也可以auto *a,两者是一样的,auto类型都是int*
但引用时,必须要写成auto&
二、

三、

解释一下auto不能作形参类型:实参传参给函数,要建立栈帧,如果不知道a的类型,就不知道要建立多大的栈帧了。
基于范围的for循环(c++)
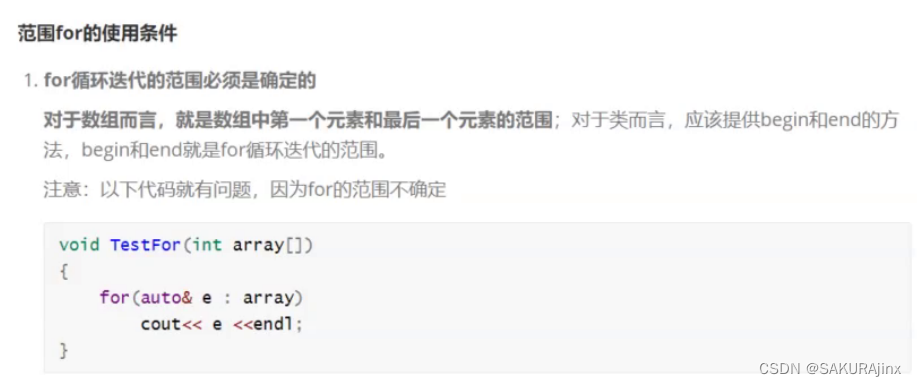
在遍历数组的时候C++也有更为简洁的方法,那就是范围for。这里就要结合上面的关键字auto了。
int main()
{
int array[] = { 1,2,3,4,5 };
for (auto& e : array)
{
e *= 2;
}
for (auto e : array)
{
cout << e << " ";
}
cout << endl;
return 0;
} 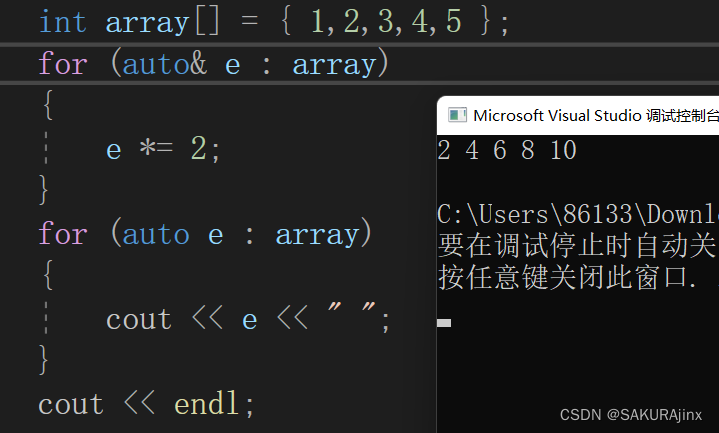
这里的e是变量名,也可以叫其它的。在数组中相当于array[i]。当需要改变数组元素的时候,要auto&,不改变仅遍历则无需。
空指针nullptr

在C++98里面出现了出现了一个bug,这是早期C++埋下的一个坑。
NULL空指针,在定义时定义成了0,并且没有强转成void*类型的,于是就会产生诸多麻烦。
有人可能会问,为什么不修改这个bug?————因为语言有个概念,向前兼容。就是语言是不断向前发展进步的,但同时它要兼容过去的东西,不管是好的还是坏的,所以即使出了bug也只能用补丁修补,而不好修改。插个题外话————
但是历史上也有一门语言摒弃了过去,实现了对过去的修改————python
Python当年放弃继续更新Python2,转投Python3,这在当年引发了轩然大波,网上骂声一片,但是也正因为这有魄力的决定,Python也有了如今的发展,成为当下极其火爆的语言。

好了,我的分享到此为止,期待我们下期见面!















 3823
3823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









