







0 准备工作
1)Hadoop集群部署,详细参照前两篇博文Hadoop集群安装配置教程 + Hadoop-2.7.3集群搭建中遇到的问题总结
2)Scala安装:ubuntu系统直接–>”sudo apt-get install scala”,系统会帮你直接安装,如果出现”no package found”,那就需要修改ubuntu的软件服务器站点(即System Settings–>Software&Update–>Ubuntu Software–>Download from–>改为其他站点里的中国服务器站点,然后sudo apt update一下),最后就是配置环境变量,就不赘述了
3)Java安装:”sudo apt-get install openjdk-8-jre openjdk-8-jdk”,配置环境变量
4)下载Spark2.0.0,解压,配置环境变量($SPARK_HOME/bin)
1 配置Spark文件
1)进入Spark安装目录中的conf目录

注:一开始spark-env.sh和slaves是不存在的!需要执行:
cp ./spark-env.sh.template ./spark-env.sh
cp ./slaves.template ./slaves2)配置spark-env.sh文件:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SCALA_HOME=/usr/share/scala-2.11
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_MASTER_IP=10.100.3.88
export SPARK_WORKER_MEMORY=1g
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)JAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录
3)配置slaves文件:
Master
Slave1
Slave2即Master节点既是主节点也是Worker节点,其余两个都是Worker节点
2 启动Spark集群
1)启动Hadoop集群:
全局输入:
start-all.sh
mr-jobhistory-daemon.sh start historyservermaster节点
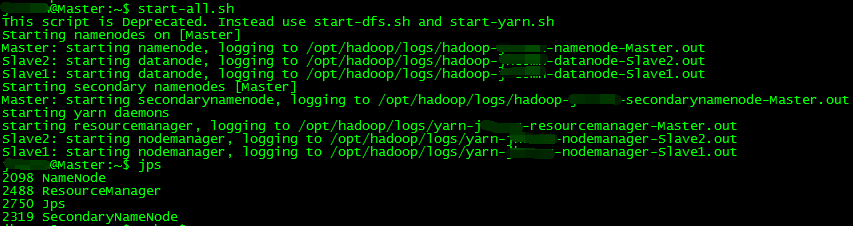
slave1节点
slave2节点同slave1
2)启动Spark集群:
在master节点输入:
$SPARK_HOME/sbin/start-all.sh
jps后发现多了两个新进程Master和Worker
在Slave1和Slave2查看进程
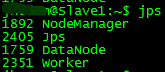
多了Worker进程,说明Spark集群已经启动成功啦~
此时,可通过web页面访问查看,http://master:8080
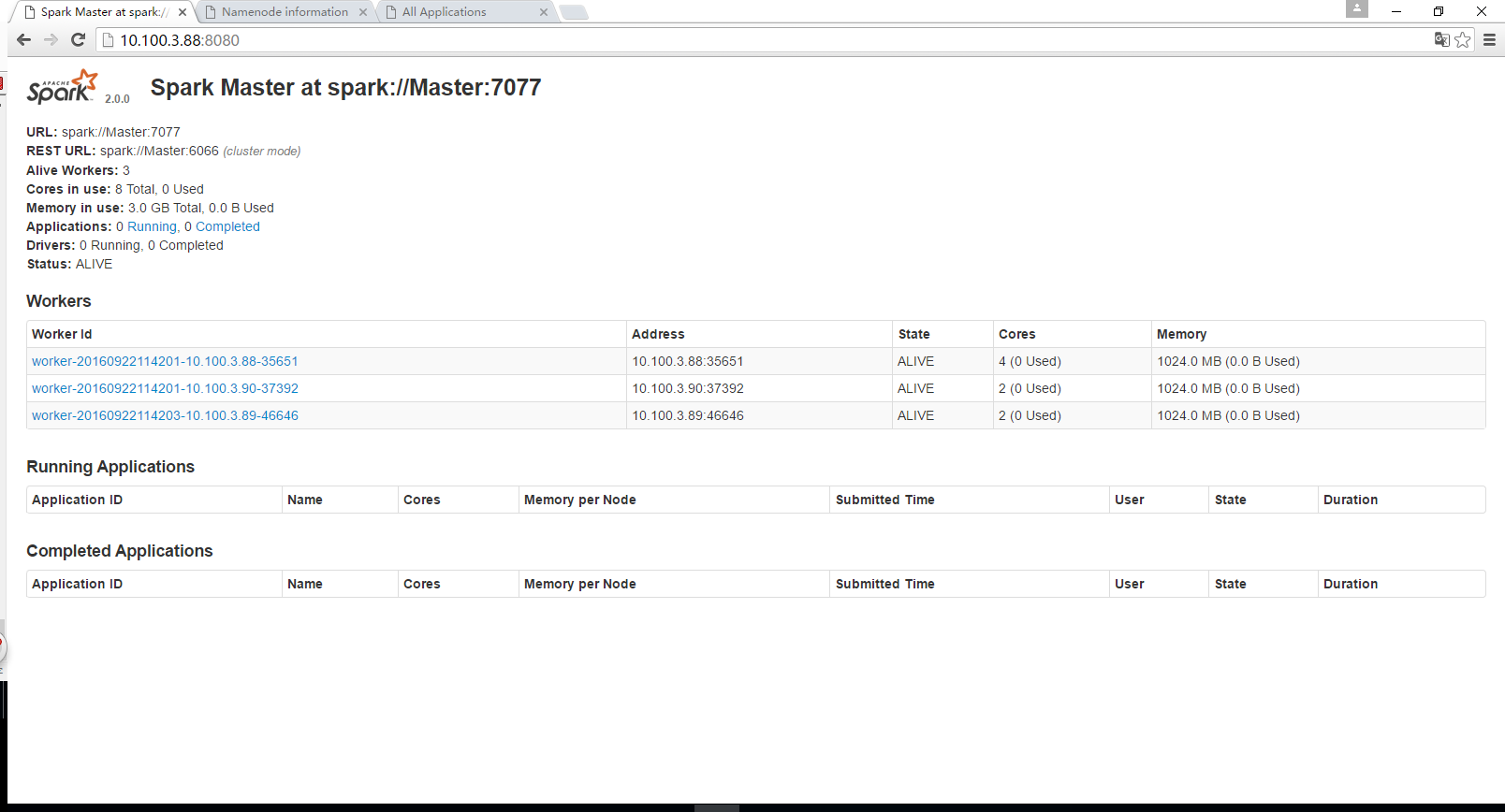
3 运行spark-shell,跑跑例子
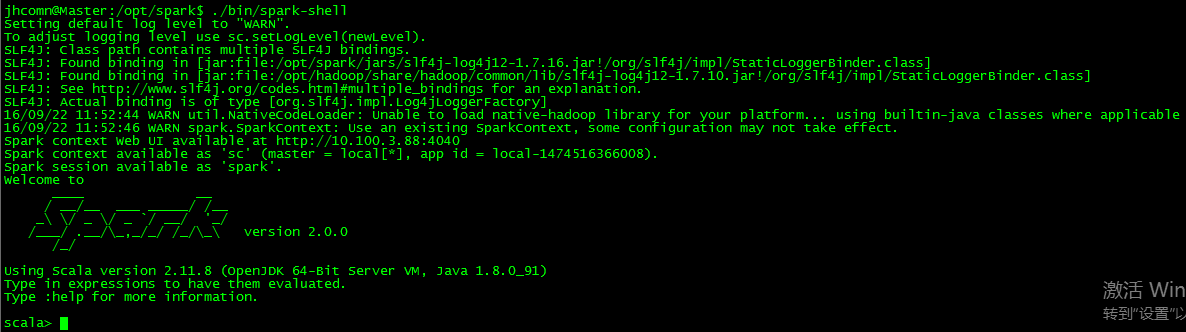
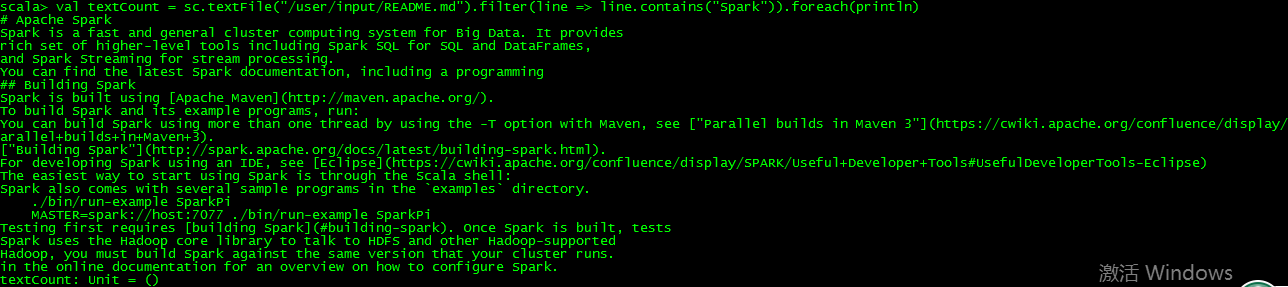
跑跑例子:















 1631
1631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









