









一.多变量线性回归(Multivariate linear regression)
前面讨论的房屋价格问题我们认为房屋价格只与其大小有关,故定义了 hθ(x)=θ0+θ1x 这样的假设函数。
若房屋的价格
y
受到其大小
符号说明:
n→特征变量的数目 ,如这里 n=4
x(i) → 第 i 组训练数据的所有特征
此时假设函数 hθ(x)=θ0+θ1x1+θ2x2+θ3x3+θ4x4 ,我们可以令 x0=1,即x(i)0=1 ,
并把特征变量的数目扩展到
n
,得到多变量线性回归一般的假设函数
定义两个 n+1维向量 ,
则 hθ(x)=θTx 。
代价函数
J(θ0,θ1,⋯,θn)=12m∑mi=1(hθ(x(i))−y(i))2
,用上述
n+1
维向量形式表示
θ
,则
也可以写成
二.多变量回归的梯度下降
根据代价函数 J(θ) ,可以得到多变量线性回归的数学表达
重复直到收敛{
将 J(θ) 的表达式代入,可以得到
这里之所以会多乘一项 x(i)j ,是因为 hθ(x(i))=θ0x(i)0+θ1x(i)1+⋯+θnx(i)n 对 θj 求偏导时会得到 θj 项前面的系数 x(i)j 。
三.特征缩放(Feature Scaling)
多变量线性回归可能会遇到的一个问题是,如果特征变量 x1 (房屋大小)的取值范围是 0∼2000 ,特征变量 x2 的取值范围是 1∼5 (卧室数目),则画等值线图时会发现因为 x1,x2 取值差别很大,导致 θ1 变化很小,等值线图变成又高又瘦的椭圆,如下图
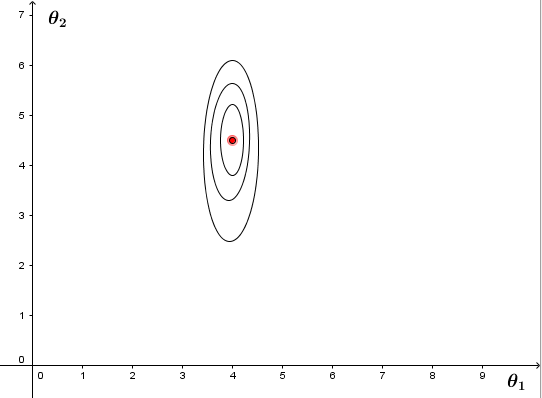
这会导致梯度下降收敛到中心最优点的速度很缓慢。为了解决这个问题,需要进行特征缩放,即将特征变量值除以其可以取到的最大值:
这样可确保让不同特征变量的取值在相近的范围内(具有可比性),等值线图变得更圆,梯度下降算法收敛更快。
进行特征缩放时,通常让每一个特征取值大概在 −1⩽xi⩽1 的范围,因为 x0 总是等于1,它也满足这个范围。但这里的范围界限 −1和1 也不是绝对的,只要范围和此范围接近就行。
四.均值归一化(Mean Normalization)
除了特征缩放外,有时候也可以进行均值归一化,即以
其中, ui 是训练数据集中 xi 的平均值, si 是 xi 的取值范围(用 xi 的最大值减最小值)。注意这里对 x0 不适用,因为 x0=1 。
例如: x1=房屋面积−10002000 , 此时 x1 就落在 −0.5⩽x1⩽0.5 这个范围。
均值归一化的目的与特征缩放一样,也是为了让梯度下降算法收敛速度更快。
五.梯度下降的两个问题
对于梯度下降 θj:=θj−α∂∂θjJ(θ) ,提出两个问题
①如何确定梯度下降是正常工作的
②如何选择学习率 α
对于梯度下降,我们的目标是 minθJ(θ) 。正常情况下,每一次迭代后,代价函数 J(θ) 都减小了。我们可以画出 J(θ) 随迭代次数增加而变化的曲线图。如下图,若 J(θ) 在一定的迭代次数后趋于平坦了,则认为梯度下降收敛了。
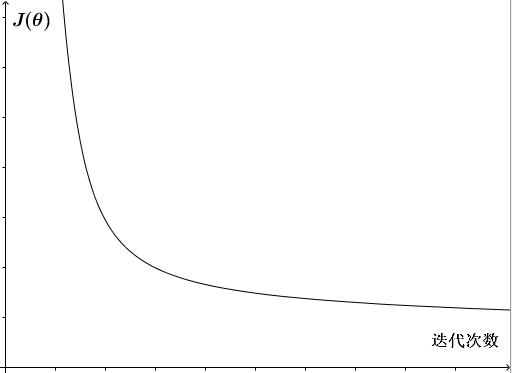
需要注意的是,对于不同的问题,梯度下降收敛所需的迭代次数也不同。
除了可以根据如上所述的 J(θ) 随迭代次数变化曲线判断是否收敛外,还可以进行自动收敛测试,即给定一个合适的较小值 ε ,如果在一次迭代后 J(θ) 减小到小于 ε ,则认为梯度下降收敛了。
但这里的 ε 怎样才能取得合适并不好定一个规则,故通过判断曲线图是否平坦可能更好。
除此之外,曲线图还可以给出梯度下降没有正常工作的警告。
如下图,随着迭代次数增加, J(θ) 却不断增大,这是因为学习率 α 太大,每次迭代后 J(θ) 都冲过了最小值,反而变得更大,这提示我们要用更小的 α 。
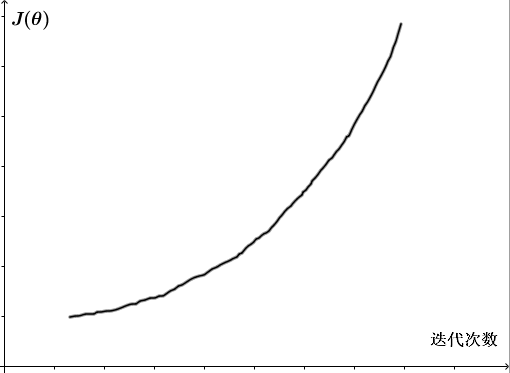
若 J(θ) 曲线图反复地下降后又上升,如下图,这也是因为学习率 α 较大,导致 J(θ) 可能不会每次迭代都减小,也提示要用更小的 α 。
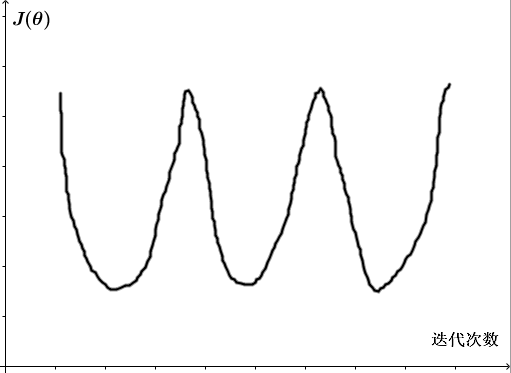
总之,若 α 太小,则收敛太慢;若 α 太大,则 J(θ) 可能不会每次迭代都减小,可能无法收敛。
实际上应该尝试一系列的 α 值,作出 J(θ) 随迭代次数变化的曲线,找到一个可以使梯度下降较快收敛的学习率 α 的值。
六.特征选择和多项式回归
仍然以房价问题为例,假设房价受街道临宽(frontage)和纵向深度(depth)共同影响,则假设函数
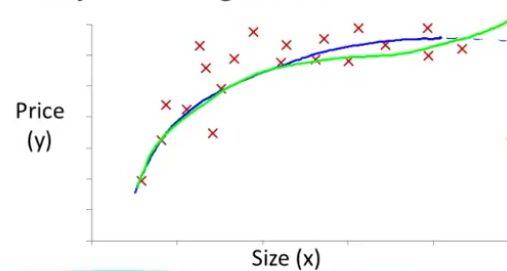
此时房价只与房屋大小(size)有关。假设有如下图所示的训练数据,为了取得较好的拟合效果,可能会想到用图中蓝线所示的二次函数去拟合,但此二次函数上升到顶点后会下降,与房价的实际情况出入较大。所以用图中绿线所示的三次函数去拟合数据可能更合适。
这时
而对于多变量线性回归
可以通过设置特征变量
需要注意的是,若房屋大小这个特征变量的取值范围是
1∼1000
,则新设置的特征变量的范围如下:
除了多项式回归之外,还有其他设计特征的选择,如:
七.正规方程(Normal Equation)
正规方程提供了一种可以一次性求解最优 θ 值的解析方法。
①对于单变量(特征)线性回归, θ∈R ,为了求解 minθJ(θ) ,需要
②对于多变量(特征)情况, θ∈Rn+1 , θj:=θj−α∂∂θjJ(θ) ,为了求解 minθ ,需要
然而,这种偏导计算可能很复杂。
若给定了
m
组训练数据
m 组训练数据的输出构成一个
对比梯度下降法和正规方程法求解
θ
,梯度下降法的劣势是需要选择学习率
α
,需要多次迭代,而正规方程法不需要。但这不意味着正规方程法就优于梯度下降,正规方程法需要计算
(XTX)−1
,当特征变量的数目
n
很大时,
通常, n 在10000以上时,多考虑用梯度下降法。
当然这里又有两个问题:
①如果
首先,这种情况并不多见;其次,Andrew Ng教授强调了Octave里的pinv()伪逆函数依旧可以求解。
②为什么 XTX 会不可逆?
<1>存在多余的特征,即有特征变量之间是线性相关的。
如:
x1
是以
英尺2
为单位的房屋大小,
x2
是以
米2
为单位的房屋大小,实际上二者是线性相关的,即
x1=3.28x2
。
针对这种情况,可删除一些特征变量直至特征变量之间没有互相线性相关的特征存在。
<2>特征变量太多( m⩽n )
针对这种情况,可删除一些特征变量或使用正则化的方法使得即使只有很小的训练集(
m
很小),也能找到适合很多特征的















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









