









一.机器学习的定义(Definition)
定义:是一门在不需要很明显很复杂的计算机编程的情况下让计算机具有学习能力的学科。
更现代化的定义:给计算机程序提供一个任务T和一种性能测量方法P,在经验E的影响下测量方法P对任务T的测量结果得到了改进。(该程序从E中学习)
二.机器学习的种类(Type)
(1)监督学习:用于训练的数据提供了一组“标准答案”。
监督学习又可细分为①回归问题(regression)②分类问题(classification)
①回归问题:需要预测的变量是连续的(consecutive)
例:采集一组房屋面积和对应价格的数据,预测要买一套指定面积的房屋需要多少钱。这里的标准答案指的是给出了采集的那组数据中房屋面积对应的价格,要预测的变量即房屋的价格是连续的,故属于监督学习中的回归问题。
②分类问题:需要预测的变量是离散的(discrete)
例:给定一组肿瘤大小和对应性质(良性/恶性)的数据,预测一特性大小的肿瘤是良性还是恶性。标准答案指的是训练数据给出了肿瘤大小对应的性质,要预测的变量即肿瘤的性质要不为良性,否则就为恶性(只有0/1这种二值选择),是离散变量,股属于监督学习中的分类问题。
(2)无监督学习:与监督学习相反,没有提供“标准答案”,预测结果无反馈,也称为聚类问题(clustering)。
例:网页将每天发生的各类新闻分类,相似的新闻会归到一类;多话者同时说话的情况下,将语音按照不同的说话人分开提取。
另:associative memory也是一种非监督学习。如医生根据以往相似病人联想出现在的病人可能患有的疾病。
三.单变量线性回归(Univariate linear regression)
以房价预测问题为例,首先给出一些符号说明:
m → 训练数据的数目
y → 输出变量(target)
(x(i),y(i)) → 第 i 个训练数据
①假设函数(hypothesis function)
房屋面积
假设函数是变量 x到y的映射 ,学习算法主要是根据训练数据集求出合理的假设函数。
对于单变量的线性回归,假设函数为 hθ(x)=θ0+θ1x,其中hθ(x)可简写为h(x) 。
②代价函数(cost function)
有了假设函数,接下来的问题就是如何选择 θ0和θ1的值,让hθ(x) 在训练数据集上尽可能地接近 y
以一种均方差的形式去评估这种接近程度,即
定义代价函数 J(θ0,θ1) ,
其中 hθ(x)=θ0+θ1x ,因为代价函数类似于均方差的形式,故也称为方差函数。
即,我们的目标就是
minimizeθ0,θ1J(θ0,θ1)
。找到使代价函数最小的
θ0和θ1
,也就是找到了在训练数据集上最接近
y
的假想函数
一种简化的形式是假设 θ0=0 ,此时 hθ(x)=θ1x , J(θ0,θ1)=12m∑mi=1(θ1x−y(i))2 。
例如,给定的三组训练数据,我们可以在 (x,y)坐标系中做出不同θ1对应的hθ(x)的图像 ,如下 θ1分别取1,0.5,0 ,红色叉点为训练数据。
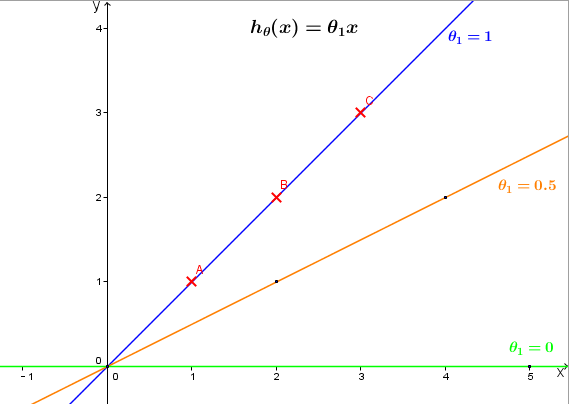
分别计算代价函数 J(θ1),J(1)=12∗3(02+02+02)=0,J(0.5)≈0.58,J(0)≈2.3 ,可大致画出 J(θ1)关于θ1的图像
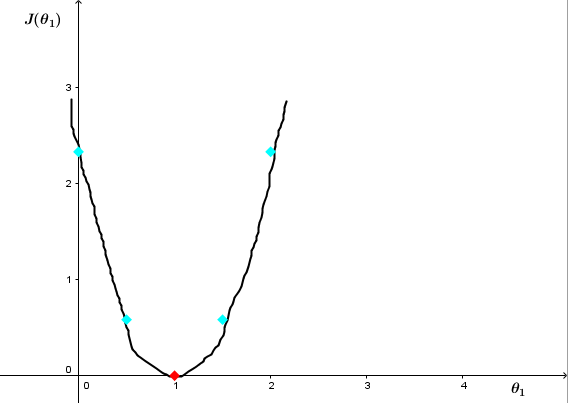
可以很明显地看出 θ1=1时,J(θ1)最小 。
四.梯度下降(Gradient descent)
梯度下降可用来最小化代价函数,除了最小化单变量线性回归的代价函数,还可用于最小化更一般的代价函数,即 minimizeθ0,θ1,...θnJ(θ0,θ1,...θn) 。
仍以单变量线性回归为例,该过程主要有以下两点:
①给
θ0,θ1赋初始值,可以都是0
②不断更新
θ0,θ1让J(θ0,θ1)减小到期望的最小值
更数学化的表达,即,重复直到收敛:
其中 j取0和1。α称为学习率, 可以理解为更新 θj 的步距。
需要注意的是,这里是同时更新 θ0和θ1 ,也就是课程中一直强调的simultaneously update。
假设分别以
temp0和temp1作为θ0,θ1更新过程中的中间变量
,同时更新意味着按下列①的顺序操作,而不是②的顺序操作(注意,:=是赋值运算符,不是等于号),
①
temp0:=θ0−α∂∂θ0(J(θ0,θ1))
temp1:=θ1−α∂∂θ1(J(θ0,θ1))
θ0:=temp0
θ1:=temp1
②
temp0:=θ0−α∂∂θ0(J(θ0,θ1))
θ0:=temp0
temp1:=θ1−α∂∂θ1(J(θ0,θ1))
θ1:=temp1
简而言之,就是不能将此次已经更新过的 θ0的值用于此次θ1的更新 。
那梯度下降为什么能够实现最小化代价函数呢?为了简化分析,仍假设
θ0=0
,则
其中ddθ1J(θ1)即为点(θ1,J(θ1))处切线的斜率。 根据 θ1的当前位置可分为三种情况:
1.若θ1在局部最优解的右边,如下图
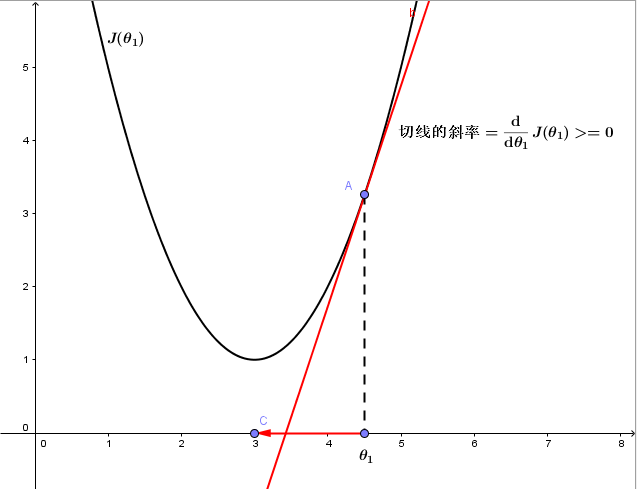
由于该点 切线的斜率=ddθ1J(θ1)>=0,且α始终为正值,故θ1将减小 ,确实是朝着正确的方向更新,即,向代价函数 J(θ1)更小的方向更新。
2.若θ1在局部最优解的左边,如下图
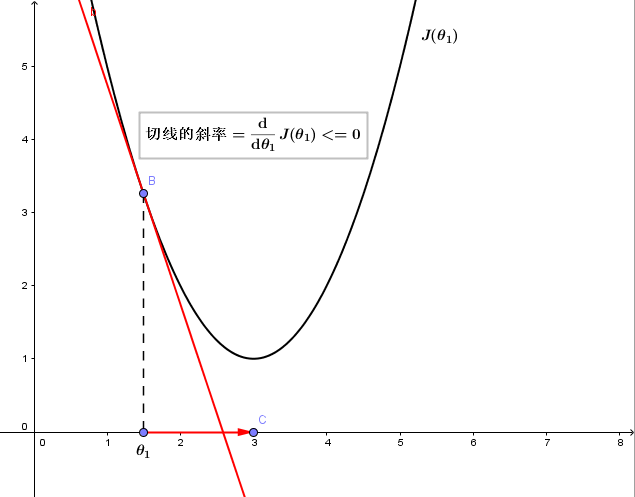
由于该点 切线的斜率=ddθ1J(θ1)<=0,且α始终为正值,故θ1将增大 ,也会朝着正确的方向更新,即,向代价函数 J(θ1)更小的方向更新。
3.若θ1已经处于局部最优位置,由于该点切线的斜率=ddθ1J(θ1)=0,故θ1将保持不变,此时即使还存在其他θ1的值使代价函数更小,也只能收敛于该局部最小值,而无法收敛于全局最小值。
再来看学习率 α ,如果 α 太小,则因为每次更新 θj 的幅度太小导致梯度下降收敛很慢,如图①
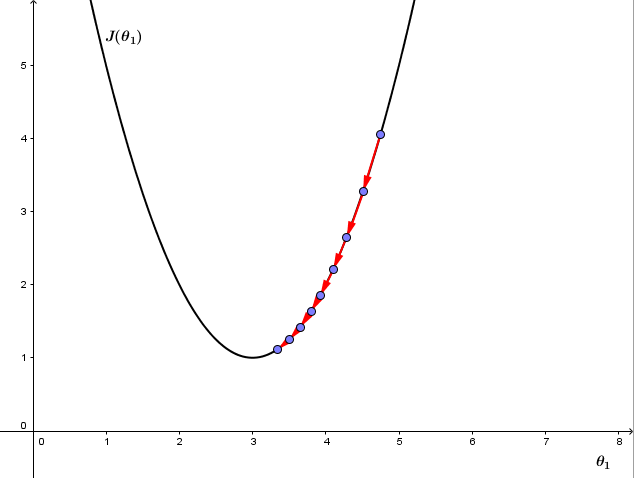
但如果 α 太大,则梯度下降可能会跨过最小值不能收敛,甚至离收敛点越来越远,如图②
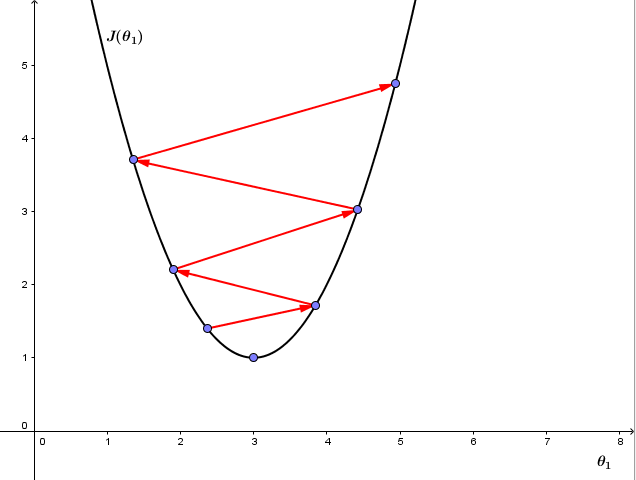
有趣的是,我们并不需要改变 α的值 ,即使 α 值固定,梯度下降也能收敛到一个局部最小值。原因是代价函数在接近局部最小值的过程中,切线的斜率越来越小,即 ddθ1J(θ1) 越来越小,即使 α 固定,梯度下降的步距也会越来越小,最终也能收敛到局部最小值。
将梯度下降用于最小化方差代价函数,因为代价函数
由梯度下降的数学表达
j取0和1 ,可得单变量线性回归的梯度下降算法,如下:
重复直到收敛{
}
同理这里也务必是同时更新,其中 hθ(x)=θ0+θ1x ,这也是造成对 θ1 求偏导多出了 x(i) 这一项的原因。
前面为了简化表达,让
θ0固定取0
,实际上单变量线性回归中代价函数
J
是
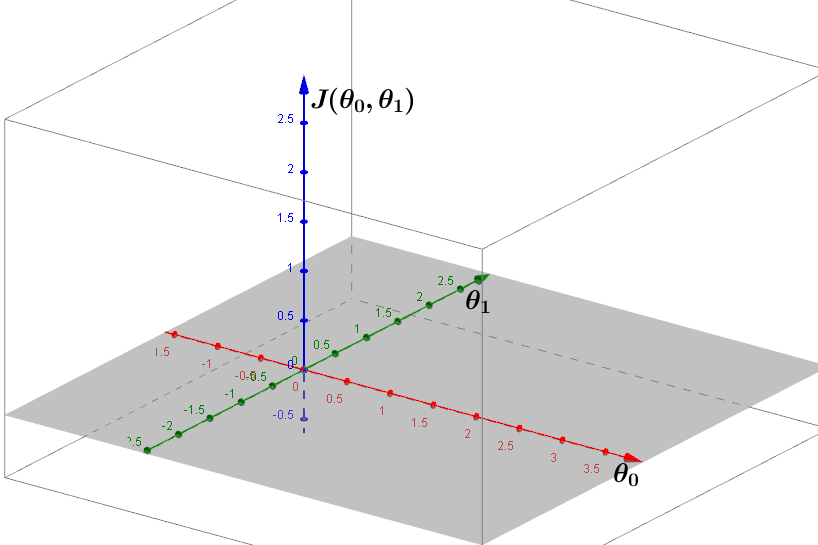
同理,这些点构成的曲面也有局部最小点和全局最小点之分,梯度下降的意义就是从曲面上任意一点一步步走到局部最小或全剧最小。
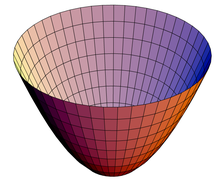
代价函数 J(θ0,θ1) 的一种特殊形式是凸面函数(convex function),更形象地说是一种碗形曲面(如下图),这时没有局部最小,只有全局最小,将梯度下降用于这种线性回归,总会收敛到全局最优。
以上数据多可在二维或三维空间中表示出来,当所需学习的特性越来越多时,扩展到多维甚至无限维,该如何表示?支持向量机(SVM)可解决此类问题,SVM可以把数据映射到无限维。















 7072
7072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









