







在中国大学MOOC上学习操作系统
希望看视频可以直接点击 哈工大-操作系统课程MOOC
内存使用与分段(Memory and Segmentation)
如何让内存用起来?
依然需要从计算机如何工作开始,我们只需要将程序放入内从中,让PC指向开始的地址即可。


直观想法
假设编译后main的地址相对入口(entry)偏移40,那么就可以直接call 40即可调用main了。
计算机是如何跑main的?
因为代码都在磁盘中,所以先磁盘读,然后将内容写到内存:
- entry放在内存0号地址,并写入call 40的指令
- main入口地址(或者叫第一条指令)放在40号地址
也就是说我们必须把main函数的入口地址(第一条指令)放在内存的40号地址。entry必须放在0号地址。然后PC=0,开始执行。
现在,我们的程序“应该可以”跑起来了,但是又遇到了问题:
0号地址是我们可以访问的吗?
0号地址一定是空闲的吗?
更好的方式
通过课程前面的学习,我们知道内存的0号地址是被操作系统占用的,我们显然无法将应用程序放在里面。
更好的解决方式是:我们去内存中找到一块空闲的区域,然后把指令放进去。
这里我们又遇到了问题:
还能写40号地址吗?是不是应该跳到1040去执行。
重定位

偏移(offset),用于表示相对地址(逻辑地址)。
我们使用相对地址来表示main的地址,让程序自动地计算真实地址,这就是重定向。
什么时候完成重定位?
- 编译时
不过实际上我们很难在编译时就知道哪些内存是空闲的,太硬了。一般都是嵌入式系统这样做。 - 载入时
找到一个空闲的内存区域,获取基址(base),然后base+offset。
各自的特点:
- 编译时重定位的程序只能放在内存的固定位置,不灵活但是载入时快。
- 载入时重定位的程序一旦载入内存就不能动了,灵活并且载入时慢,更适合通用设备(PC、移动设备)。
交换(swap)
但实际上,编译时重定向还是不够灵活,因为有时候程序在载入后还是需要移动。

进程如果阻塞时间很长,一直占着内存就会就是白白浪费资源,所以有了交换机制。(虚拟内存?)
重定位的最佳时机
运行时重定位才是重定位的最佳时机。

在执行指令的时候,首先取出基址(base),然后对于所有逻辑地址,我们使用base+offset的方式来处理。
也就是说,每执行一条指令时,程序都需要从逻辑地址中算出实际的物理地址:地址翻译。
这样以后无论指令入口放在哪里都能执行整个程序了。
整理一下内存的基本使用

- 编译代码并保存在磁盘中。
- 创建进程,即创建PCB。
- 在内存中找一段空闲的内存,然后把基址赋给PCB,把磁盘中的程序装载到从基址开始装载到内存中。
- 将PCB中的基址放入CPU的基址寄存器,PC置为基址。
- 取出的每一条指令都要进行地址翻译。
- 现在程序就能执行起来了
- 如果CPU切换,也要重新把PCB中的基址放入基址寄存器中。
引入分段
是将整个程序一起载入到内存中吗?
不是这样
程序员眼中的程序
一个程序分为:
- 主程序
- 变量集(数据)
- 函数库
- 动态数组(堆)
- 栈

符合用户观点:用户可以独立考虑每个段(分治)
怎么定位具体指令数据?段号 + 段内偏移
mov [es:bx],ax 意思是:将ax中的内容移动到es数据段偏移bx的位置。
显然如果我们将所有的程序都放入一个部分,就会造成整个程序非常耦合,比如:
- 想写数据段内容结果写到了主程序里面,程序直接就崩溃了,主程序应该是只读的
- 栈应该是一个单向增长的,动态数组是双向的
- 函数库中有的代码压根就不需要加载进来
所以我们应该使用段的概念,比如我们要访问主程序段的第10行代码,访问数据段的第300行,访问栈段的栈顶,访问数组段的头部或者尾部,加载函数库的第n个函数,这样设计或许更加内聚一点。
分段会造成什么样的结果?
分段的优点应该还有一个:如果不使用分段,整个程序因为“支离破碎”的内存,有可能根本就没有能容纳下这么多程序的内存,根本装载不进去,也就是说内存的利用率变低了。这就好像数组和链表之间的区别。

比如说3是一个栈,如果我们使用他的时候写了一个比如说递归的算法,造成这个栈增长得非常快,我们就可以为这个栈重新分配一个段,而无需把整个程序都移动,使用内存的效率也变高了。
不过这样又造成了我们原来的重定向逻辑不好使了:
现在我们需要使用进程段表和CS、DS寄存器来控制:
假设CS为0,DS为1,那么根据进程段表我们就能算出来mov的第一个参数是360K+100,jmpi的参数为180K+100。
题外话:
- 在这里终于理解了CS和DS到底是干什么的,CS全称是code segment register,实际就是代码段基址寄存器,用来存放当前执行的指令的代码段的基地址。DS全称是data segment register,实际就是数据段基址寄存器,用来存放数据段的基地址。(机组和操作系统的世界线合一了)
- 想起了在课程最开始讲开机时提到的jmpi 0,8指令,实际上0就是offset,8就是段号。
- 关于段表:每个进程维护一个段表,操作系统也维护了一个段表,操作系统的段表就是GDT表,进程的表就是LDT表。D:decription T:table G:global L:local

- 内存被分为一堆的“段”,程序也被分为“段”(程序的分段是编译器要做的事情),操作系统把基址放在GDT中,进程把基址放在LDT中。进程需要将程序的各个段放入内存的各个段中,然后在LDT表中记录这些段的映射,最终赋给PCB。这就是程序装入内存的过程。
(有的CPU会专门使用GDTR、LDTR来专门储存这两个表的位置) - PC指针指向PCB中LDT内保存的基址,开始取指,然后使用基址进行地址翻译后就可以执行指令了。
- 程序就在不断地取指令、执行指令中运行起来了。
内存分区与分页(Memory Partition and Paging)
如何把程序装入内存?
- 程序编译后分成多个段(编译器来做)
- 在内存中划分多个空闲区域(这节课就要讲)
- 通过磁盘读写把程序装载到内存中(装的思想就是上节课的内容,具体如何装就要在后面的课程中学)
固定分区与可变分区
已经知道程序需要分段装在内存中,但是只有知道如何分割内存才能将各个段装入这些空闲的区域中。

固定分区
直接等分,系统初始化时将内存等分为多个分区。但是显然有的段应该长,有的段应该短。
可变分区
可变分区就是将分区分成不等分的。
可变分区的管理过程
核心数据结构

两个表:
- 空闲分区表
- 已分配分区表
请求分配

100K<250K,所以可以分配一个地址从250K至350K的内存段。
然后修改空闲分区表和已分配分区表。
释放内存

在已分配分区表找到那段释放的内存,直接填进空闲分区表中。
再次申请

下面的适配没有对和错,只有好和坏,这里的最佳和最差只是一个名字:
- 首先适配:350K,150K
特点:随机
速度:快,O(1) - 最佳适配:200K,50K
特点:空闲分区会越来越小,这次分配结束后,就只剩一个10K的空闲分区了。
速度:慢一些,O(n) - 最差适配:350K,150K
特点:空闲分区会变得越来越均匀
速度:慢一些,O(n)

最差适配:因为有时候需要很大的内存块,最差适配会使得空闲分区越来越均匀,如果后来出现大的内存请求就没有能适配的内存区了,所以不是。
最佳适配:虽然最佳适配会使得空闲分区中的小分区越来越多,但是起码可以保证有大的内存请求进来可以适配,因此是正确的。
最先适配:完全随机的一个适配算法,不合适。
这道题就在告诉我们,要根据操作系统的实际情况使用内存分区的适配算法,而不是草率地决定一个算法。
不过实际上,在现有的操作系统中,基本不会只考虑内存分区的问题,因此哪个算法都不需要我们太多地考虑,最终是使用内存分页来解决物理内存的分配问题的。
内存分页
引入分页的目的是解决内存分区导致的内存效率问题。

使用可变分区造成了一段一段破碎的内存段,这就是内存碎片。
尽管有时候空闲的分区很大,但是面对进来的内存请求却找不到适配的内存分区。比如上图。
直观想法
将这些空闲分区合并,需要把上面的seg3移动到seg1上面,也就是将空闲分区紧缩起来。
尽管我们可以使用分区紧缩的方法,但是这种方法需要耗费大量的时间,此时用户将无法访问这些内存,显然应该用更高效的方法。
从连续到离散

将内存切成一页一页(打散),针对每个段的内存请求,系统将一页一页地分配给这个段。前面的课程提到过mem_map,实际上那个4K就是一页的大小。
此时就不需要内存紧缩了,并且一个段的最大的内存浪费也就是一页。
现在内存管理的逻辑:
- 用户角度:分段
- 物理内存角度:分页
计算物理内存地址

12位是一页的尺寸,4位是页表的大小,也就是16位可以表示16张4K的页。
CR3寄存器指向操作系统保存页表的地址。PCB中保存段的页表指针。
0x2240(十六进制),除以4K就是右移3位(十六进制1位等于二进制的4位,二进制右移12位,十六进制右移3位)
可以求出逻辑地址,page:0x02,offset:0x240。也就是说需要两页加一页保存0x240大小的内存。也就是第3页并偏移0x240。查表即可找到真实的内存地址0x3240。
上述的操作是CPU的MMU在处理。
多级页表与快表(Mutilevel Paging)
尽管上面的单级页表看上去已经非常完善了,但是在实际使用中还是有一些问题,因此引出多级页表。
计算页数:
比如32位,就可以表示4G个地址,如果每页映射4K个的地址,就应该是4G/4K=1M个页。
如果页变小了,那逻辑页项数就应该相应增加,相应的页表就大了。
使用逻辑地址计算物理地址:
(逻辑地址/页数)后向上取整,余数作为页内偏移。通过查表可以知道页框的位置,然后加上页内偏移就是物理地址。
为了提高内存空间利用率,页应该尽量得小,但是页小了页表就大了。

举个例子:
32位地址,也就是4G个地址,如果一页4K个地址就要有1M个页。
在页表中,一个页表项一般是4字节(这个是固定的,不是计算的),那么一个页表就要有4MB这么大。
假设100个进程并发,每个进程都要保存一张页表,就需要400MB的内存空间,太浪费内存了。
实际上大部分逻辑地址不会用到,比如上图应该有4个页表项,就用了3个项,能不能只存这3个项?
直观想法

用到的逻辑页才有页表项,也就是上面的4个项的页表只保留3个项。
但是页表中的页号不连续了,就需要比较,即使是效率较快的二分搜索,log2(2^20)也要找20次,这20次还要不断比较不断访问内存,效率太低了。
所以还是需要连续,起码查找效率是高的。
怎样既连续又让页表占用内存少呢?
考虑用书的章目录和节目录来类比:
如果只是用节目录来查询,那节目录就会很多,考虑加入章目录,这样就可以先使用章目录再找节目录,提高了查询效率。
多级页表

2^10章,2^10节。
虽然依然是连续存储,但是页目录表不需要对这些空的地址进行映射,也就是说页目录表的下一级页表不需要都保存,但页目录表还是要以4KB的形态完整保存。这样我们就既保证了查找的连续性,又保证了可以忽略掉没有用到的页项。
(可以试一下全部保存页表,就成了4K(页目录大小)+ 1K*4K=4M = 4M+4K大小的空见,还多了一个页目录需要保存。)
对于上面的例子,4KB大小的页目录表保存在内存中,并且只有3张4KB的页表保存在内存中,一共16KB,比原来的4MB要少得多。
多级页表的时间效率
虽然多级页表提高了空间效率,但是也同时降低了时间效率,增加了访问内存的次数。
如果是64位系统(64位地址,可能要5、6级页表),可能就得分好多级页表,每多一级,就需要多访问一次内存。
因此需要引出:快表(TLB)
TLB(Translation Lookaside Buffer)

TLB是一组相联快速存储,是寄存器,能快速找到最近使用的逻辑页对应的物理页号。
因为快表是一个寄存器,所以不可能把整个页表加载进来,只能保存某些页号。
快表是用硬件来实现的,因此可以实现“相联”。
以上图为例,CPU想要访问19号页,直接查快表,发现有效,直接获取到了页框号为29。此时CPU如果希望访问140号页,发现没有命中,就只能老老实实去查页表。
于是,页表和快表结合使用,使得页表项是连续的,并且在查找时较快,内存利用率也高。
TLB的效率
下面假设只有二级页表(最多2次Memory Access),并且20快表访问时间为20ns,内存访问时间为100ns。实际情况中快表的查询速度要远高于MA。

TLB的命中率应该越高越好,首先,也就是说TLB的越大越好,能保存的页表项越多越好;其次,还需要TLB的置换算法要更优秀(这些算法可以参考后面内存换入换出部分的算法)
为什么TLB条目数应当在64-1024之间
因为程序地址访问存在局限性(空间局部性,Locality in Space)。
程序的控制结构基本就是顺序+循环,换句话说就是执行顺序不会跳来跳去的,一个页有4KB,足够存一段相当长的代码了,很可能一个小的程序就在一个固定的页里面运行,极有可能向快表一直查询同一个页。(或许这也是很多高级程序设计语言摒弃goto的原因?)
段页结合的实际内存管理(Segmentation & Paging)
段页结合起来才是目前操作系统常用的内存管理策略。
段页结合:用户视角分段,内存视角分页。
段页结合
段面向用户,页面向内存

用户视角(从左向右):程序被分为段,然后装载至一个地址空间,这个地址空间就是虚拟内存。
虚拟内存视角:虚拟内存中保存了多个程序段,虚拟内存需要将其离散化(打散)后装入物理内存。
物理内存视角:内存被分成了一页一页,利用率很高。
简单来讲,段页结合的方式,使用了虚拟内存作为用户和物理内存的映射中介,这个设计非常漂亮。
段页结合时的重定位(地址翻译)

段到地址的映射出的基址,是虚拟内存中的地址,并非物理内存地址。
- 段的地址翻译
通过段表找出段号+偏移(cs:ip),计算出逻辑地址。 - 虚拟内存的地址翻译
通过逻辑地址查页表得到页号和偏移,找到物理页号和偏移,最终找到物理内存地址 - 对于用户来说,虚拟内存是透明的
一个实际的段、页式内存管理
从程序放进内存、使用内存开始

分配段,建段表;分配页,建页表。
进程带动内存使用的图谱
从进程fork中的内存分配开始
段页式内存下程序如何载入内存

- 找到一个空闲的虚拟内存段。
- 用户段映射到虚拟内存中,建立段表;这里注意,尽管在物理内存中我们最终没有使用分区,但在虚拟内存中,我们可以使用内存分区。
- 将用户段离散化,即分页,然后建立页表,映射到物理内存中。
- 最终表现为用户程序被直接分页到物理内存中,程序在运行时使用上面的映射关系进行重定位。
从fork()开始-分配虚存、建段表

fork=>sys_fork=>copy_process都已经看过了,现在来看看copy_mem(看来这个mem是memory的意思)
传入了nr(表示第几个进程)和当前进程的PCB
- 声明一个无符号长整型的的变量new_data_base(虚拟内存地址基址?)
- new_data_base = nr*64M,在虚拟内存中割出64M空间
- 申请两个新的段表,并填写,即把虚拟内存地址基址赋给当前进程的1号、2号ldt。
实际上就做了两件事:分配虚拟内存、建段表
现在进程0、1、2的虚拟地址
刚刚我们从进程2中fork了一个进程

- 每个进程的代码段、数据段都是一个段。
- 每个进程占64M的虚拟地址空间,互不重叠。
接下来的事情-分配内存、建页表

copy_page_tables使得父子进程共用一套页表:
- 定义一个无符号长整型变量old_data_base
- 获取父进程的基地址并赋给old_data_base,获得
- 在不分配内存的情况下,直接建一个页表,可以理解为内存和页目录表都可以共用,但是要有一些自己的页表(这也是多级页表的初衷)。
下面看看copy_page_tables,显然old_data_base,new_data_base,data_limit这三个值可以决定子进程的内存地址空间,从名字看来这个方法就是为了拷贝子进程所属的页表。
from_dir和to_dir是什么

右移20位?为什么不是22位?
如果右移22位就正好是获取页目录号,至于为什么右移20位,是因为右移22位并且此时还需要再乘(2^2)=4个字节。其实还是找的页目录号。
from_page_table与to_page_table是什么

进行size次循环,size就是页目录表的大小
在为子进程做页目录表到页表的映射。
- 先申请一页内存,得到页物理内存基址
- 然后赋给to_dir
接下来-复制过程

- 取里面的值然后赋值即可,拷贝操作。
- ~2?:按位取反,10=>01。让this_page和01做与操作,相当于一个清零操作。
- 把值赋给to_page
- 把值赋给from_page
- mem_map的这一项要累加,增加一个对其的引用(引用-计数回收?)
现在的程序-虚存-内存的关系

*p=7如何工作(父进程7,子进程8)

只要我们建好段表和页表,CPU中的MMU会处理它们的寻址过程。
MMU是一个硬件单元,因为写程序来控制内存的读写就太慢了,所以CPU采用硬件实现了MMU。
*p=8时,在新建页表以后,将原来部分的页目录号占据,指向这些页目录下的页,页目录表和父进程共用,页表重新拷贝。这样就做到了父子进程虽然共享一段内存,但是互不影响。
内存换入-请求调页(Swap in)
段页同时存在

- 无论物理内存如何分配,对于用户来说,内存就是规整的4G大内存,只要没满就能用,可以随便切割、分段,比如char *p ; p =3G,就是在使用地址。
- 用户随意使用这个“内存”,就像单独拥有4G的内存
- 这个“内存”如何映射(必须映射)到物理内存,对用户来讲是透明的
用换入换出实现“大内存”

如果出现逻辑内存大于物理内存的情况怎么办?比如左边4G,右边1G。
- 访问p(=0G~1G)时,将这部分直接映射到物理内存
- 访问p=(3G-4G)时,再映射这一部分
类比:
内存是门店,虚拟内存是仓库,店面比仓库小得多,仓库中的物品不能直接出售,客户需要买只能在门店买,如果门店中没有这个物品,就去把仓库中的拿出来售卖。
请求调页

逻辑地址(段号+偏移方式),算出虚拟内存中的地址,MMU查询这个地址有没有映射到物理内存中,如果没有,就去调页。
当调页请求进来时:
- load[addr] 如果有就载入,没有就触发页错误处理程序
- 页错误处理程序实际上需要触发一个中断
- 程序从磁盘中找到对应的页然后去找一个空闲的内存,将磁盘中的内容保存到内存中。
- 恢复中断时的场景,这里注意硬件可能需要判断一下如果是缺页造成的中断,就不需要PC+1的操作。
对于用户来讲,部分操作会让用户感到“慢了一点”。
一个实际系统的请求调页
从缺页中断的中断处理开始

上面两行代码在设置中断处理对应的中断处理函数
处理中断page fault

mov1 %cr2, %edx?
页错误线性地址就在%cr2里。线性地址就是虚拟地址。
push1 %edx, push1 %eax
把那个错误的线性地址压栈,为了给后面参数。
call 操作就是来调用C语言程序。
do_no_page
两个参数是压栈进来的,所以先压的错误线性地址在第二个参数上,后压的错误码在第一个参数。显然这个函数就是向内存中调页,肯定得有申请内存、读磁盘、装页的操作。

- address &= 0xfffff000,为了抹掉后12位的offset(那个32位地址表示)
- get_free_page,获得空闲页
- bread_page,磁盘读block read
- put_page,装载
put_page
应该是为了修改页表。

page参数应该是读到的物理页,然后把这个物理页放在page_table,这个函数就是为了向页表追加一个映射关系。
内存换出(Swap out)
有换入就应该由换出。
当我们调用get_free_page时,不可能总是有内存,所以就要有内存换出算法,但是具体要换哪页出来,是需要我们仔细斟酌的。

直观想法:FIFO,这是最容易想到的,但是如果刚换入的页马上又要换出,就会影响效率,应该怎么办?
最优淘汰:MIN
最优的近似:LRU
FIFO页面置换

A:放入页框
B:放入页框
C:放入页框
A:命中
B:命中
D:请求换页,换出A,换入D
A:请求换页,换出B换入A
D:命中
B:请求换页,换出C,换入B
C:请求换页,换出D,换入C
B:命中
评价准则:缺页次数,本实例FIFO导致缺页7次,前3次不可避免。
如果我们先看了一下整个序列,会发现把C换出,D换入是一个最优解,总体缺页次数只有5次。这就引出了MIN算法
MIN页面置换
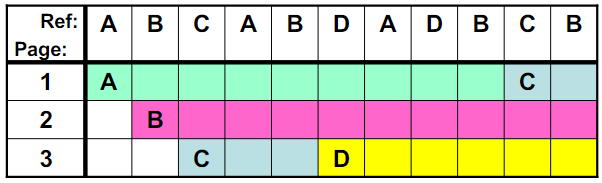
选最远将使用的页淘汰,是最优方案。
A:放入页框
B:放入页框
C:放入页框
A:命中
B:命中
D:请求换页,换出C,换入D(找C的逻辑,DADBC,显然AB出现过了,找C)
A:命中
D:命中
B:命中
C:请求换页,换出A,换入C(找A的逻辑,后面有B,所以不能换B,可以换A或D)
B:命中
一共就5次缺页。
虽然算法很好,但是需要知道将来要发生的事情,这个有些超出了现实。
LRU页面置换(Least Recently Used)
选择最近最长一段时间没有使用的页淘汰(最近最少使用)
还是因为空间局部性原理。
并使用频率估计概率,只能用历史来预测未来。

A:放入页框
B:放入页框
C:放入页框
A:命中
B:命中
D:请求换页,换出C,换入D(找C的逻辑,历史中,A出现过2次,B出现过2次,C出现过1次)
A:命中
D:命中
B:命中
C:请求换页,换出A,换入C(B出现过3次,A出现过2次,D出现过2次,可以换A或D)
B:命中
缺页5次。
不要认为这串序列是随意写的,在现实中由于局部性规律,就会经常出现对内存的使用会集中在某几页。
LRU的准确实现-用时间戳

- A:放入页框,记为1
- B:放入页框,记为2
- C:放入页框,记为3
- A:命中,记为4
- B:命中,记为5
- D:请求换页,换出C,换入D(找C的逻辑,A=4,B=5,C=3,选时间戳最小的C),D记为6
- A:命中,记为7
- D:命中,记为8
- B:命中,记为9
- C:请求换页,换出A,换入C(A=7,B=9,D=8,选时间戳最远的A),记为10
- B:命中,记为11
虽然这个实现从算法角度来讲很好实现,但是让硬件来出来却非常麻烦:比如找最小值、维护时钟、维护时间戳都相当麻烦。
LRU的准确实现-用页码栈(双向栈)
页码栈栈顶永远保留最近使用的页,栈底永远保存最久使用的页。

A:放入页框,压栈
B:放入页框,压栈
C:放入页框,压栈
A:命中,A调到栈顶
B:命中,B调到栈顶
D:请求换页,删除栈底的C,D压栈
A:命中,A调到栈顶
D:命中,D调到栈顶
B:命中,B调到栈顶
C:请求换页,删除栈底的A,C压栈
B:命中,B调到栈顶
每次地址访问都需要修改栈(修改10次栈指针),实现的代价仍然很大,看来LRU很难准确地实现。
LRU的近似实现-将时间计数变为是或否
这是对LRU的近似实现,不再记录时间戳,而是看最近是否访问过。

- 每个页增加一个引用位(reference bit):
- 每次访问一页时,硬件自动设置该位(为1)
- 选择淘汰页:扫描该位,是1则清0,并继续扫描;是0则淘汰。
- 选择淘汰页的算法被称为Second Chance Replacement或二次淘汰算法
- 一般页需要被循环队列组织。
- SCR算法的实现被称为Clcok Algorithm
也就是最近没使用的就扔出去
Clock算法的分析与改造
使用“最近没有使用”来近似“最近最少使用”

如果缺页很少,也就意味着很少有从1置成0。如果被一直访问,总会有整个循环队列都是1,那就意味着无法换出内存。
转了一圈以后,再开始清除,这就退化成了FIFO。
一个思路
定时清除R位:
使用一个扫描指针来实现。这个扫描指针移动得很快,用来清除R位。此时算法就需要两个指针,一个淘汰指针,一个扫描指针。扫描指针在时钟中断时使用,淘汰指针在缺页时使用。
给进程分配多少个页框

分配多了,内存利用率就下来了;
分配少了,CPU利用率就下来了。
颠簸(thrashing)
随着多道程序程度变高,CPU利用率在某一阈值后急剧下降。
颠簸原因
系统内进程增多=>每个进程的缺页率增加=>进程总是在等待调页完成=>CPU利用率越来越低=>进程数进一步增加=>系统缺页率再次增加……
怎么办?
分配的时候至少要覆盖一个“局部”,例如工作集算法等。(这里就不讲了)。
尽管一些算法可以帮助操作系统来较好地分配页,但是一旦进程并发得多了,内存依然会不够用,缺页率依然会变高,因此我们还需要限制进程的个数。
换入换出结合

- 发现缺页,缺页中断
- 换出算法,选出一个页写出到磁盘
- 换入算法,从磁盘读取一个页出来然后写入内存
(注意上面的swap分区,这个就是Linux的swap分区,原来在学Linux的时候老师说过不要动这个文件夹,就是因为这个分区非常重要)
现在,一个基本的操作系统的轮廓已经很清晰了,多进程图像已经画完了。















 1561
1561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









