







1 问题描述
布尔可满足性问题是给定一个合取范式(CNF),即一系列析取形式的子句(clause)的合取式,问是否存在一组赋值使得整个式子为真。给出满足条件的赋值(说明是satisfied的),或者证明不存在这样的赋值(说明是unsatisfied的)。显然如果要整个CNF为真,则需要每个子句都为真。而对于每个子句内部是析取,所以需要至少有一项为真子句才能为真。
2 不完备算法
一类SAT求解算法是不完备(incomplete) 的,即对于给出的CNF算法只能证明可满足,或者算法只能证明不可满足,没办法对于可满足和不可满足的输入都证出。
2.1 Local Search
初始时随机给出一组赋值,然后带进去看看是否满足,如果有冲突,那就翻转变量取值,再冲突就再在里面翻转,并规定一个最大循环次数。
Local Search无法证明一个CNF是不满足的,能找到赋值的CNF显然就是满足的,但是没找到赋值的CNF也未必就是不满足的。
2.2 其它不完备算法
还有Genetic Algorithm、Simulated Annealing等,老师也没讲应该也用的不多,这里就记个名字吧。
3 完备算法
另一类SAT求解算法是完备(complete) 的,即给出任何CNF,都能证明它是满足的还是不满足的。
3.1 完备算法基本策略
完备算法中涉及两个基本策略(Basic Rules),在完备算法中重点使用了这些策略。
3.1.1 纯字母(Pure Literals)
如果CNF中某个字母 x i x_i xi的所有出现都是同一种形式,即要么都是 x i x_i xi,要么都是 ¬ x i \neg x_i ¬xi,则说字母 x i x_i xi是纯的。
这条规则意在说明如果CNF里发现了纯字母,所有带纯字母的子句都可以直接从CNF里删掉,因为可以直接让这个纯字母导出"真"而不会引起冲突,然后这些带纯字母的子句自然就都是"真"了。
例如:
φ
=
(
¬
x
1
∨
¬
x
2
)
∧
(
x
1
∨
¬
x
2
)
∧
(
x
2
∨
x
3
)
∧
(
x
1
∨
x
3
)
\varphi = (\neg x_1 \vee \neg x_2) \wedge (x_1 \vee \neg x_2) \wedge (x_2 \vee x_3) \wedge (x_1 \vee x_3)
φ=(¬x1∨¬x2)∧(x1∨¬x2)∧(x2∨x3)∧(x1∨x3)
这个CNF里
x
3
x_3
x3就是纯字母,所以包含它的后两个子句可以直接删除,化简下来
φ
=
(
¬
x
1
∨
¬
x
2
)
∧
(
x
1
∨
¬
x
2
)
\varphi = (\neg x_1 \vee \neg x_2) \wedge (x_1 \vee \neg x_2)
φ=(¬x1∨¬x2)∧(x1∨¬x2)
然后 ¬ x 2 \neg x_2 ¬x2又是纯字母,这两个子句又可以直接删掉,那么整个CNF就是可满足的了,知 x 3 = ¬ x 2 = ⊤ x_3=\neg x_2=\top x3=¬x2=⊤即可让整个CNF为真。
3.1.2 单元子句传播(Unit Propagation)
这个是在尝试赋值的过程中的一个规则。如果一个子句里面,其它字母都导出"假",只剩一个字母了,这个子句叫单元子句(unit clause),这时候这个字母就必须设置为"真"了,不然就会产生冲突。
而"传播"是在说这样的过程是一步步递进的,因为刚刚给一个字母指派为"真"了,又可能会导致其它子句成为单元子句,那么就可以继续应用这条规则。
例如:
φ
=
(
x
1
∨
¬
x
2
∨
¬
x
3
)
∧
(
¬
x
1
∨
¬
x
3
∨
x
4
)
∧
(
¬
x
1
∨
¬
x
2
∨
x
4
)
\varphi = (x_1 \vee \neg x_2 \vee \neg x_3) \wedge (\neg x_1 \vee \neg x_3 \vee x_4) \wedge (\neg x_1 \vee \neg x_2 \vee x_4)
φ=(x1∨¬x2∨¬x3)∧(¬x1∨¬x3∨x4)∧(¬x1∨¬x2∨x4)
假设到了某一步已经设置 ¬ x 2 = ¬ x 3 = ⊥ \neg x_2 = \neg x_3 = \bot ¬x2=¬x3=⊥,那么第一个子句就成了单元子句,所以必须有 x 1 = ⊤ x_1 = \top x1=⊤,这又导致后面两个子句成了单元子句,所以必须有 x 4 = ⊤ x_4=\top x4=⊤,这时候发现整个CNF是可满足的,知 x 1 = x 4 = ⊤ x_1=x_4=\top x1=x4=⊤即可让整个CNF为真。
当然,也可能会导致其它子句出现冲突,这时候就要根据具体的SAT求解算法的策略来回退了。
例如,对上面的例子,修改末尾的
x
4
x_4
x4变成
¬
x
4
\neg x_4
¬x4:
φ
=
(
x
1
∨
¬
x
2
∨
¬
x
3
)
∧
(
¬
x
1
∨
¬
x
3
∨
x
4
)
∧
(
¬
x
1
∨
¬
x
2
∨
¬
x
4
)
\varphi = (x_1 \vee \neg x_2 \vee \neg x_3) \wedge (\neg x_1 \vee \neg x_3 \vee x_4) \wedge (\neg x_1 \vee \neg x_2 \vee \neg x_4)
φ=(x1∨¬x2∨¬x3)∧(¬x1∨¬x3∨x4)∧(¬x1∨¬x2∨¬x4)
还是设置 ¬ x 2 = ¬ x 3 = ⊥ \neg x_2 = \neg x_3 = \bot ¬x2=¬x3=⊥,然后知 x 1 = ⊤ x_1=\top x1=⊤,再执行一次单元子句传播,发现剩下两个单元子句既要 x 4 = ⊤ x_4=\top x4=⊤又要 ¬ x 4 = ⊤ \neg x_4=\top ¬x4=⊤,这就发生冲突了。
3.2 消解法(Resolution)
该方法关注于将CNF里的某些子句消解成新子句,利用
(
x
∨
α
)
∧
(
¬
x
∨
β
)
⊢
(
α
∨
β
)
(x \vee \alpha) \wedge (\neg x \vee \beta) \vdash (\alpha \vee \beta)
(x∨α)∧(¬x∨β)⊢(α∨β)
如果CNF中同时出现了形如 ( x ∨ α ) (x \vee \alpha) (x∨α)和 ( ¬ x ∨ β ) (\neg x \vee \beta) (¬x∨β)的子句,就把它们替换成 ( α ∨ β ) (\alpha \vee \beta) (α∨β)。
当消解出
⊥
\bot
⊥子句时,说明原公式是不可满足的,如:
(
x
1
∨
x
2
)
∧
(
¬
x
1
∨
x
3
)
∧
(
¬
x
2
)
∧
(
¬
x
3
)
⊢
(
x
2
∨
x
3
)
∧
(
¬
x
2
)
∧
(
¬
x
3
)
⊢
(
x
3
∨
⊥
)
∧
(
¬
x
3
)
⊢
(
x
3
)
∧
(
¬
x
3
)
⊢
⊥
\begin{aligned} & (x_1 \vee x_2) \wedge (\neg x_1 \vee x_3) \wedge (\neg x_2) \wedge (\neg x_3) \\ \vdash & (x_2 \vee x_3) \wedge (\neg x_2) \wedge (\neg x_3) \\ \vdash & (x_3 \vee \bot) \wedge (\neg x_3) \\ \vdash & (x_3) \wedge (\neg x_3) \\ \vdash & \bot \end{aligned}
⊢⊢⊢⊢(x1∨x2)∧(¬x1∨x3)∧(¬x2)∧(¬x3)(x2∨x3)∧(¬x2)∧(¬x3)(x3∨⊥)∧(¬x3)(x3)∧(¬x3)⊥
是不可满足的。
当消解出的公式中所有字母都是纯字母时,说明原公式是可满足的,如:
(
x
1
∨
¬
x
2
∨
¬
x
3
)
∧
(
¬
x
1
∨
¬
x
2
∨
¬
x
3
)
∧
(
x
2
∨
x
3
)
∧
(
x
3
∨
x
4
)
⊢
(
¬
x
2
∨
¬
x
3
)
∧
(
x
2
∨
x
3
)
∧
(
x
3
∨
x
4
)
⊢
(
¬
x
3
∨
x
3
)
∧
(
x
3
∨
x
4
)
⊢
⊤
∧
(
x
3
∨
x
4
)
⊢
(
x
3
∨
x
4
)
\begin{aligned} & (x_1 \vee \neg x_2 \vee \neg x_3)\wedge (\neg x_1 \vee \neg x_2 \vee \neg x_3) \wedge (x_2 \vee x_3) \wedge (x_3 \vee x_4) \\ \vdash & (\neg x_2 \vee \neg x_3) \wedge (x_2 \vee x_3) \wedge (x_3 \vee x_4) \\ \vdash & (\neg x_3 \vee x_3) \wedge (x_3 \vee x_4) \\ \vdash & \top \wedge (x_3 \vee x_4) \\ \vdash & (x_3 \vee x_4) \end{aligned}
⊢⊢⊢⊢(x1∨¬x2∨¬x3)∧(¬x1∨¬x2∨¬x3)∧(x2∨x3)∧(x3∨x4)(¬x2∨¬x3)∧(x2∨x3)∧(x3∨x4)(¬x3∨x3)∧(x3∨x4)⊤∧(x3∨x4)(x3∨x4)
是可满足的,只要 x 3 = ⊤ x_3=\top x3=⊤或 x 4 = ⊤ x_4=\top x4=⊤。
3.3 Stalmarck’s Method
这个就是在搜索解空间树的时候用3.1中的基本规则进行剪枝,每次固定一个变量看其它的变量,如果出现了单元子句,则可以剪掉使解空间树矛盾的那一分支。该方法用来求解common assignments,即必须为
⊤
\top
⊤或者必须为
⊥
\bot
⊥的变量。
例如,对于:
φ
=
(
a
∨
b
)
∧
(
¬
a
∨
c
)
∧
(
¬
b
∨
d
)
∧
(
¬
c
∨
d
)
\varphi = (a \vee b) \wedge (\neg a \vee c) \wedge (\neg b \vee d) \wedge (\neg c \vee d)
φ=(a∨b)∧(¬a∨c)∧(¬b∨d)∧(¬c∨d)
先设置 a = ⊥ a=\bot a=⊥,则发现 ( a ∨ b ) (a \vee b) (a∨b)是单元子句(因此可以剪掉 b = ⊥ b=\bot b=⊥的分支),必须有 b = ⊤ b=\top b=⊤,然后进行传播,发现 ( ¬ b ∨ d ) (\neg b \vee d) (¬b∨d)是单元子句,因此 d = ⊤ d=\top d=⊤,推理至此无法继续进行。
再设置对立面 a = ⊤ a=\top a=⊤,则发现 ( ¬ a ∨ c ) (\neg a \vee c) (¬a∨c)是单元子句,必须有 c = ⊤ c=\top c=⊤,发现 ( ¬ c ∨ d ) (\neg c \vee d) (¬c∨d)是单元子句,因此 d = ⊤ d=\top d=⊤,推理至此无法继续进行。
合之,知 d = ⊤ d=\top d=⊤是一条common assignment,将这个真值指派代入原公式,再继续应用此方法求解。
这个例子不是很好,因为这个例子里 d d d是纯字母,实际上后两个子句一开始就可以直接扔掉。
3.4 Recurive Learning
Recurive Learning和Stalmarck’s Method一样也是求解common assignments的,只不过Stalmarck’s Method是固定一个变量的正反两面,而Recurive Learning则是让一个子句内的每个字母分别取 ⊤ \top ⊤。
例如,还是对于:
φ
=
(
a
∨
b
)
∧
(
¬
a
∨
c
)
∧
(
¬
b
∨
d
)
∧
(
¬
c
∨
d
)
\varphi = (a \vee b) \wedge (\neg a \vee c) \wedge (\neg b \vee d) \wedge (\neg c \vee d)
φ=(a∨b)∧(¬a∨c)∧(¬b∨d)∧(¬c∨d)
取第一个子句 ( a ∨ b ) (a \vee b) (a∨b),要让整个公式满足,这个子句内至少有一个字母要满足。
先设置 a = ⊤ a=\top a=⊤,则 ( ¬ a ∨ c ) (\neg a \vee c) (¬a∨c)是单元子句,知 c = ⊤ c=\top c=⊤,则 ( ¬ c ∨ d ) (\neg c \vee d) (¬c∨d)是单元子句,知 d = ⊤ d=\top d=⊤,至此无法继续传播。
再设置 b = ⊤ b=\top b=⊤,则 ( ¬ b ∨ d ) (\neg b \vee d) (¬b∨d)是单元子句,知 d = ⊤ d=\top d=⊤,至此无法继续传播。
合之,知
d
=
⊤
d=\top
d=⊤是一条common assignment,将这个真值指派代入原公式,再继续应用此方法求解,或者3.3和3.4一起用也可以。
3.5 回溯法(DPLL)
DPLL就是标准的子集树回溯,在每步搜索的时候也要去应用3.1中的基本规则进行剪枝,并检查是否有发生冲突的子句,发生冲突时就立即回溯。当找到一个到叶子结点的路径时就说明这个CNF是可满足的,如果回溯完也没找到,就说明是不可满足的。
这里核心就在冲突检查上,例如,下面是DPLL搜索中的某一步:
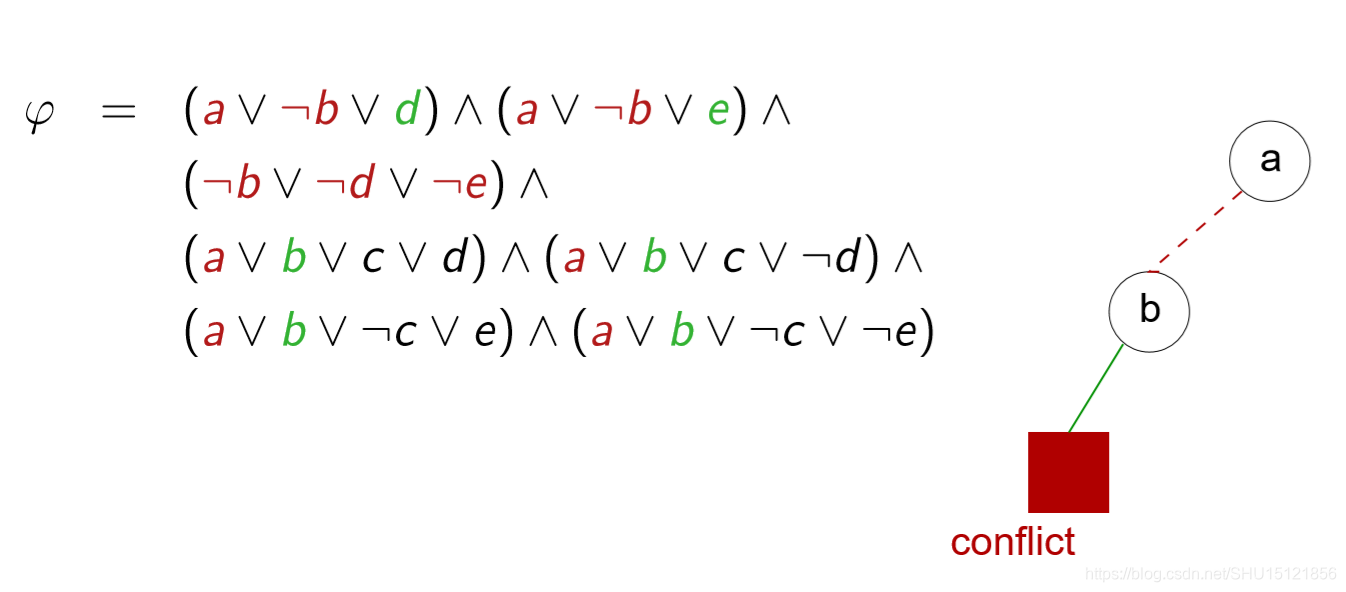
这时是在
a
=
⊥
a=\bot
a=⊥这一分支上尝试
¬
b
=
⊥
\neg b=\bot
¬b=⊥这一分支,这使得第一个子句和第二个子句成为单元子句,所以
d
=
e
=
⊤
d=e=\top
d=e=⊤,而这导致第三个子句为假,因此这时要立即回溯,转而搜索
¬
b
=
⊤
\neg b=\top
¬b=⊤这一分支。
3.6 Conflict-Driven Clause Learning
CDCL直译过来就是冲突驱动子句学习,是在DPLL基础上进行改进得到的。
当在回溯搜索过程中发生冲突时,即可从"当前的搜索路径会导致冲突"这一事实,依据路径上的变量赋值,学习出一个子句项。例如,对于:
φ
=
(
a
∨
b
)
∧
(
¬
b
∨
c
∨
d
)
∧
(
¬
b
∨
e
)
∧
(
¬
d
∨
¬
e
∨
f
)
.
.
.
\varphi = (a \vee b) \wedge (\neg b \vee c \vee d) \wedge (\neg b \vee e) \wedge (\neg d \vee \neg e \vee f)...
φ=(a∨b)∧(¬b∨c∨d)∧(¬b∨e)∧(¬d∨¬e∨f)...
在搜索路径决策为 c = ⊥ c=\bot c=⊥且 f = ⊥ f=\bot f=⊥时,下一步尝试 a = ⊥ a=\bot a=⊥会导致 ( a ∨ b ) (a \vee b) (a∨b)是单元子句,所以 b = ⊤ b=\top b=⊤,进而导致 ( ¬ b ∨ e ) (\neg b \vee e) (¬b∨e)是单元子句,从而 e = ⊤ e=\top e=⊤,进而导致 ( ¬ d ∨ ¬ e ∨ f ) (\neg d \vee \neg e \vee f) (¬d∨¬e∨f)产生冲突。
这时可以学习到 ( ¬ c ∧ ¬ f ∧ ¬ a ) = ⊥ (\neg c\wedge \neg f \wedge \neg a) = \bot (¬c∧¬f∧¬a)=⊥,所以可以在原CNF中析取一个子句 ( c ∨ f ∨ a ) (c \vee f \vee a) (c∨f∨a)。
CDCL的另一个特点是,发生冲突时,应当按照导致冲突的子句进行回溯,而不必按照变量的决策顺序(不必按照时间序)仅回退到上一层。
例如,某个决策顺序是 c = ⊥ c=\bot c=⊥, f = ⊥ f=\bot f=⊥, h = ⊥ h=\bot h=⊥, i = ⊥ i=\bot i=⊥。接下来在搜索 a = ⊥ a=\bot a=⊥时发生冲突,冲突的子句是 ( a ∨ c ∨ f ) (a \vee c \vee f) (a∨c∨f),而在此基础上搜索 a = 1 a=1 a=1时仍然发生冲突。这时不必回退到 i = ⊤ i=\top i=⊤,而是根据刚刚的子句 ( a ∨ c ∨ f ) (a \vee c \vee f) (a∨c∨f),接下来去搜索 c = ⊤ c=\top c=⊤或 f = ⊤ f=\top f=⊤,而 c c c的拓扑序在 f f f前面,因此接下来搜索 c = ⊥ c=\bot c=⊥且 f = ⊤ f=\top f=⊤的情况,即直接回溯到 f f f这一层。

















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









