







 本文是SIGAI特邀作者陈泰红对基于单目视觉的三维重建算法的综述,涵盖SfM(Structure From Motion)的增量式、全局式和混合式方法,以及深度学习在三维重建中的应用。文章探讨了三维视觉发展趋势,指出多视觉几何与深度学习融合、多传感器融合等方向。SfM中的增量式方法在重建精度上有优势但易受图像添加顺序影响,全局式方法效率高但鲁棒性不足。深度学习在深度估计和3D shape预测方面取得进展,但仍面临挑战。
本文是SIGAI特邀作者陈泰红对基于单目视觉的三维重建算法的综述,涵盖SfM(Structure From Motion)的增量式、全局式和混合式方法,以及深度学习在三维重建中的应用。文章探讨了三维视觉发展趋势,指出多视觉几何与深度学习融合、多传感器融合等方向。SfM中的增量式方法在重建精度上有优势但易受图像添加顺序影响,全局式方法效率高但鲁棒性不足。深度学习在深度估计和3D shape预测方面取得进展,但仍面临挑战。
其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
作者:SIGAI特邀作者陈泰红
PDF地址:http://sigai.cn/paper_97.html
三维计算机视觉在计算机视觉是偏基础的方向,随着2010年阿凡达在全球热映以来,三维计算机视觉的应用从传统工业领域逐渐走向生活、娱乐、服务等,比如AR/VR,SLAM,自动驾驶等都离不开三维视觉的技术。
三维重建包含三个方面,基于SFM的运动恢复结构,基于Deep learning的深度估计和结构重建,以及基于RGB-D深度摄像头的三维重建。

SfM(Structure From Motion),主要基于多视觉几何原理,用于从运动中实现3D重建,也就是从无时间序列的2D图像中推算三维信息,是计算机视觉学科的重要分支。广泛应用于AR/VR,自动驾驶等领域。虽然SFM主要基于多视觉几何原理,随着CNN的在二维图像的积累,很多基于CNN的2D深度估计取得一定效果,用CNN探索三维重建也是不断深入的课题。
深度学习方法呈现上升趋势,但是传统基于多视几何方法热情不减,实际应用以多视几何为主,深度学习的方法离实用还有一定的距离。
本综述主要介绍基于单目monocular的三维重建方法,主要分为基于SfM三维重建和基于Deep learning的三维重建方法,另外由于多视觉几何涉及大量的矩阵、线性代数和李群等数学概念,本综述不做进一步研究,详细可参考经典多视觉几何MVG。
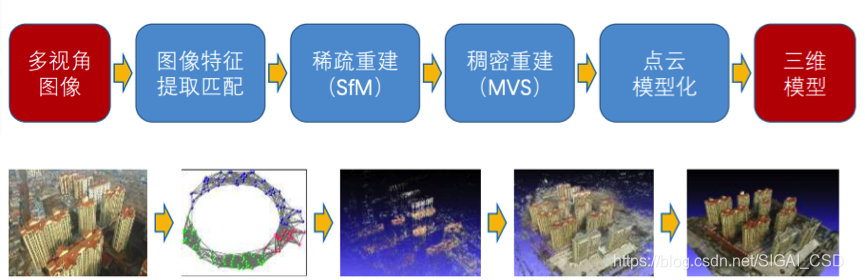
1、SfM 与三维重建
从二维图像中恢复三维场景结构是计算机视觉的基本任务,广泛应用于3D导航、3D打印、虚拟游戏等。
Structure from Motion(SfM)是一个估计相机参数及三维点位置的问题。一个基本的SfM pipeline可以描述为:对每张2维图片检测特征点(feature point),对每对图片中的特征点进行匹配,只保留满足几何约束的匹配,最后执行一个迭代式的、鲁棒的SfM方法来恢复摄像机的内参(intrinsic parameter)和外参(extrinsic parameter)。并由三角化得到三维点坐标,然后使用Bundle Adjustment进行优化。
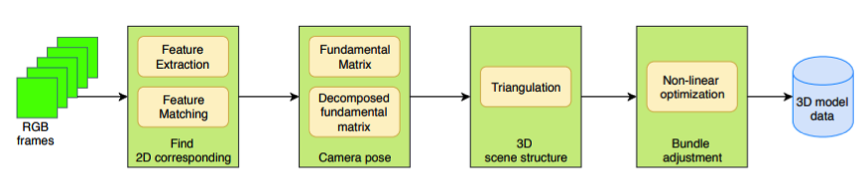
根据SfM过程中图像添加顺序的拓扑结构(图 4),SfM方法可以分为:
- 增量式(incremental/sequential SfM)
- 全局式(global SfM)
- 混合式(hybrid SfM)
- 层次式(hierarchica SfM)
- 基于语义的SfM(Semantic SfM)
- 基于Deep learning的SfM

1.1 增量式 SfM
以[1]的方法位置,增量式SfM首先使用SIFT特征检测器提取特征点并计算特征点对应的描述子(descriptor),然后使用ANN(approximate n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









