







一、介绍
LLaMA 3 (Large Language Model Meta AI) 是 Meta(原 Facebook)发布的一个大规模预训练语言模型系列的第三代版本。LLaMA 3 旨在推动自然语言处理(NLP)的研究和应用,其系列模型具有较强的语言理解和生成能力。
LLaMA 3-Chinese 是 LLaMA 3 系列中一个专门针对中文进行优化的版本。这个版本的模型在大量中文文本上进行训练,因此在中文文本生成、理解和对话等任务上表现优异。
它具有以下特点:
- 高性能 :LLaMA 3-Chinese 模型使用了先进的模型架构和训练技术,使其在中文处理任务上具有较高的准确性和生成能力。
- 大规模预训练:该模型在大量的中文数据上进行预训练,因此具备了强大的语言理解和生成能力。
- 适应性强 :能够用于各种中文 NLP 任务,如文本分类、情感分析、机器翻译和对话生成等。
应用场景:
- 中文对话系统 :可以用来构建聊天机器人和对话系统,支持自然流畅的中文对话。
- 内容生成 :适用于自动生成中文内容,如文章写作、新闻生成和社交媒体内容创作。
- 文本分析:用于中文文本分类、情感分析和信息提取等任务。
LLaMA 3-Chinese 实现以 Meta-Llama-3-8B 为底座,使用 DORA (https://arxiv.org/pdf/2402.09353.pdf)+ LORA(https://arxiv.org/pdf/2402.12354.pdf)的训练方法,在500k高质量中文多轮SFT数据 、100k英文多轮SFT数据和2k单轮自我认知数据训练创建的大模型。
二、部署流程
1. 环境要求
- CUDA:11.8
- PyTorch:2.0.1
- PyThon:3.8
2. 克隆仓库
git clone https://github.com/seanzhang-zhichen/llama3-chinese.git
3. 安装依赖项
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
4. 下载模型
来自 ModelScope
git lfs install
git-lfs clone https://www.modelscope.cn/seanzhang/Llama3-Chinese.git
来自 HuggingFace
git lfs install
git clone https://huggingface.co/zhichen/Llama3-Chinese

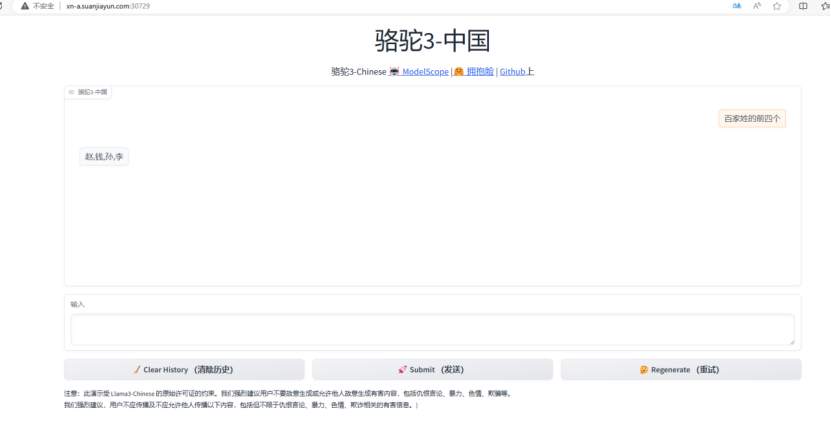
三、网页演示
python web_demo.py --model_path /llama3-chinese-main/Llama3-Chinese
进入WebUI页面如下:















 5502
5502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









