







机器学习笔记系列
可以从上至下按顺序看喔
- 回归笔记:机器学习-回归算法笔记
- 分类笔记:机器学习-分类算法笔记
- 神经网络笔记:机器学习-神经网络算法笔记
朴素贝叶斯
介绍
- 首先从名字开始解释,朴素贝叶斯中的“朴素”二字突出了这个算法的简易性。朴素贝叶斯的简易性表现该算法基于一个很朴素的假设:所有的变量都是相互独立的,假设各特征之间相互独立。
- 啥是条件独立性假设呢,用公式来说就是如果 P ( A , B ∣ C ) = P ( A ∣ C ) P ( B ∣ C ) P(A,B|C)=P(A|C)P(B|C) P(A,B∣C)=P(A∣C)P(B∣C),那么A,B之间就是在C这个条件下独立的,举个例子
- A:熬夜
- B:上课迟到
- C:赖床
- 在赖床的条件下想使得熬夜通过赖床来影响到上课迟到的概率为0,这就表示熬夜和上课迟到他俩之间是条件相互独立的,这就叫做A与B相互独立
- 贝叶斯呢就是贝叶斯公式啦
条件概率
- 条件概率: P ( B ∣ A ) P(B|A) P(B∣A)
- 意思就是在A的条件下,B发生的概率
先验概率与后验概率
-
假设有一个事件B,他是由事件A引起的,那么P(A)就是我们的先验概率
-
即在事件B发生之前,我们对事件A的概率的一个最初的判断
-
好,现在我们已知道事件B的概率,想知道事件A的概率,也就是条件概率P(A|B)
-
即在事件B发生后,我们重新对A的概率进行评估,这就是后验概率
-
举个例子
- 我们出去买西瓜,在没摸到西瓜前,我们只看到了西瓜的外表,于是我们判断该瓜是不是好瓜的概率就是先验概率
- 而当我们摸到西瓜后,我们通过敲击西瓜等一系列方法判断出了该瓜是好瓜或坏瓜后,我们再用我们已经得到的经验来判断该瓜是好瓜的概率,这就是后验概率
全概率公式与贝叶斯公式
- 全概率全概率,说的就是一个事件全部的概率加在一起的公式,我们可以用一个模型来推导出来
-
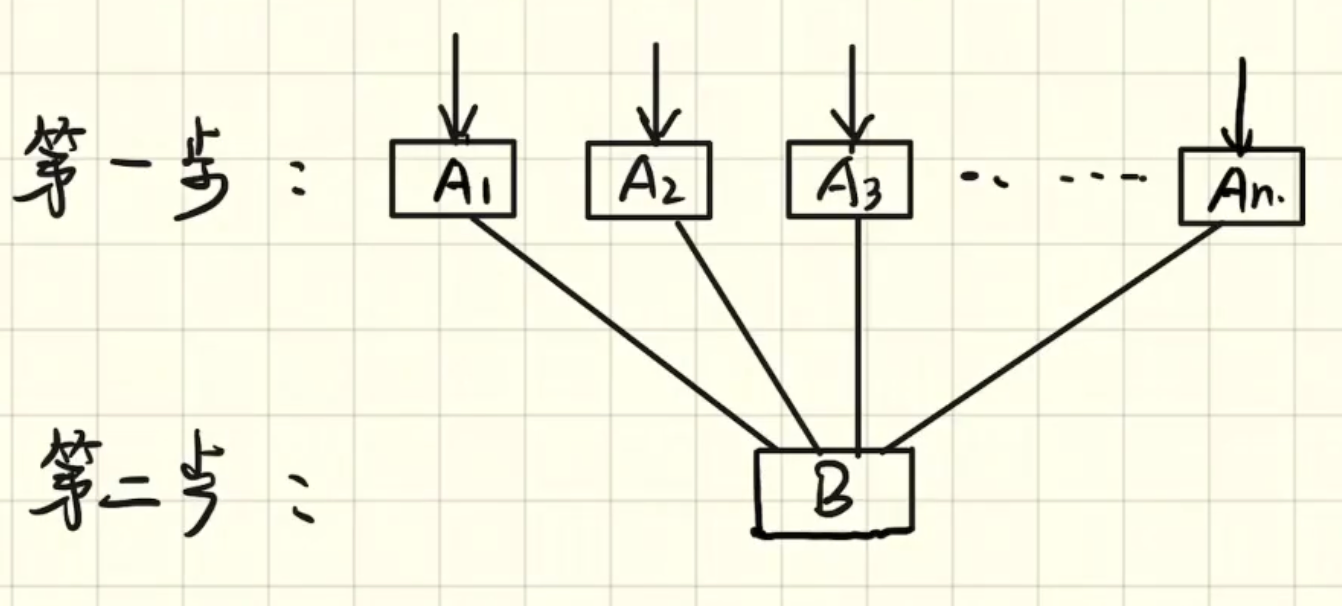
- 这是一个两步式模型,也就是第二步是由第一步得来的,可以看到有很多条路径A1、A2、、、An可以到达B
- 第一步我们取A1的概率就是P(A1),第二步我们取B的概率就是P(B|A1),也就是在A1完成的条件下B的概率
- 那么从A1这条路径完成B的概率是不是就是P(A1)P(B|A1),那么第二条第三条路径也是同理
全概率公式
- 于是 P ( B ) = P ( B ∣ A 1 ) P ( A 1 ) + P ( B ∣ A 2 ) P ( A 2 ) + … + P ( B ∣ A n ) P ( A n ) P(B)=P\left(B \mid A_{1}\right) P\left(A_{1}\right)+P\left(B \mid A_{2}\right) P\left(A_{2}\right)+\ldots+P\left(B \mid A_{n}\right) P\left(A_{n}\right) P(B)=P(B∣A1)P(A1)+P(B∣A2)P(A2)+…+P(B∣An)P(An)
- 将各个通往B的路径的概率全部加在一起,这就是全概率公式
- 那贝叶斯公式是什么呢?贝叶斯是已知B,我们来求A1、A2或者An的概率,也就是用后验概率来推理先验概率,也就是求P(A1|B)或者P(A2|B)等等
贝叶斯公式
- 于是 P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) ∑ j = 1 n P ( A j ) P ( B ∣ A j ) = P ( A i ) P ( B ∣ A i ) P ( A 1 ) P ( B ∣ A 1 ) + … + P ( A n ) P ( B ∣ A n ) P\left(A_{i} \mid B\right)=\frac{P\left(A_{i}\right) P\left(B \mid A_{i}\right)}{\sum_{j=1}^{n} P\left(A_{j}\right) P\left(B \mid A_{j}\right)}=\frac{P\left(A_{i}\right) P\left(B \mid A_{i}\right)}{P\left(A_{1}\right) P\left(B \mid A_{1}\right)+\ldots+P\left(A_{n}\right) P\left(B \mid A_{n}\right)} P(Ai∣B)=∑j=1nP(Aj)P(B∣Aj)P(Ai)P(B∣Ai)=P(A1)P(B∣A1)+…+P(An)P(B∣An)P(Ai)P(B∣Ai)
- 贝叶斯公式也就是用一条路径的概率去除于所有路径的概率,举个例子
- 我们有十条道路回家,那么随机选到第一条道路的概率是不是就是十分之一,也就是用这一条路的概率去除上所有回家的道路
- 最后我们将全概率公式与贝叶斯公式结合起来,就是:
- P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) P ( B ) P\left(A_{i} \mid B\right)=\frac{P\left(A_{i}\right) P\left(B \mid A_{i}\right)}{P(B)} P(Ai∣B)=P(B)P(Ai)P(B∣Ai)
概率因子(可能性函数)
-
我们现在已经知道了贝叶斯公式: P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) P ( B ) P\left(A_{i} \mid B\right)=P\left(A_{i}\right)\frac{ P\left(B \mid A_{i}\right)}{P(B)} P(Ai∣B)=P(Ai)P(B)P(B∣Ai
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









