







Week10:Large Scale Machine Learning
Stochastic Gradient Descent随机梯度下降
当常规的Gradient Descent在巨大的Training Set即m值很大的时候,因为算法中有
∑
,所以计算速度比较慢,这个时候就需要使用随机梯度下降
之前的Gradient Descent因为需要对m个数据进行多次处理,又称为Batch Gradient Descent批量梯度下降
- 预处理:将数据打乱(即重排列)
- 扫描m中所有样本,依次得到 (x(i),y(i))(i=1,2,3...)
- 一次对一个样本 (x(i),y(i)) 的Cost Function进行梯度下降,然后使函数更好地拟合 (x(i),y(i)) ,然后再对 (x(i+1),y(i+1)) 的Cost Function进行梯度下降
- 以此类推,直到完成循环
预处理的目的,是为了在扫描训练集的时候,对样本的访问是随机的,这样有利于加快Cost Function收敛速度
与Batch Gradient Descent不同的是,Stochastic Gradient Descent不用等到对所有m个样本求和之后才得到梯度项,而是只需对单个训练样本求出这个梯度项
Stochastic Gradient Descent一点点使 θ 慢慢往全局最小值靠近
批量梯度下降和随机梯度下降的收敛形式是不同的,随机梯度下降的最后是在全局最小值的附近徘徊,而批量梯度下降是直接逼近全局最小值最后停留在那里
用随机梯度下降最后也能够得到一个接近全剧最小值的参数,虽然不一定特别特别精准,但也够用了
Repeat的次数一般是1次,正常情况下不会超过10次


Mini-Batch Gradient Descent 小批量梯度下降
Mini-Batch Gradient Descent 是一种介于随机梯度下降和批量梯度下降的算法
b的值在[1,m],一般取[2,100]之间的数

这种算法可以在扫描10个样本之后就开始处理参数,进行梯度下降,下降速度有时候会比随机梯度下降快
我觉得这是因为一次有扫描10个数据,下降到全局最小值相对随机梯度下降更有方向性
小批量梯度下降有个缺点就是选取b的时候需要做一定的尝试
使用向量化有助于提高小批量梯度下降的运算速度,有时候比随机梯度下降和批量梯度下降都要快

检测随机梯度下降是否收敛
这种检测思想是算法对N个样本进行梯度下降之后,把最后N个样本的costfunction计算出来,然后画出曲线去分析(批量梯度下降是把一次迭代中所有样本的costfunction计算出来,然后画出曲线去分析)
图像噪声太大的时候增大要平均的样本数目
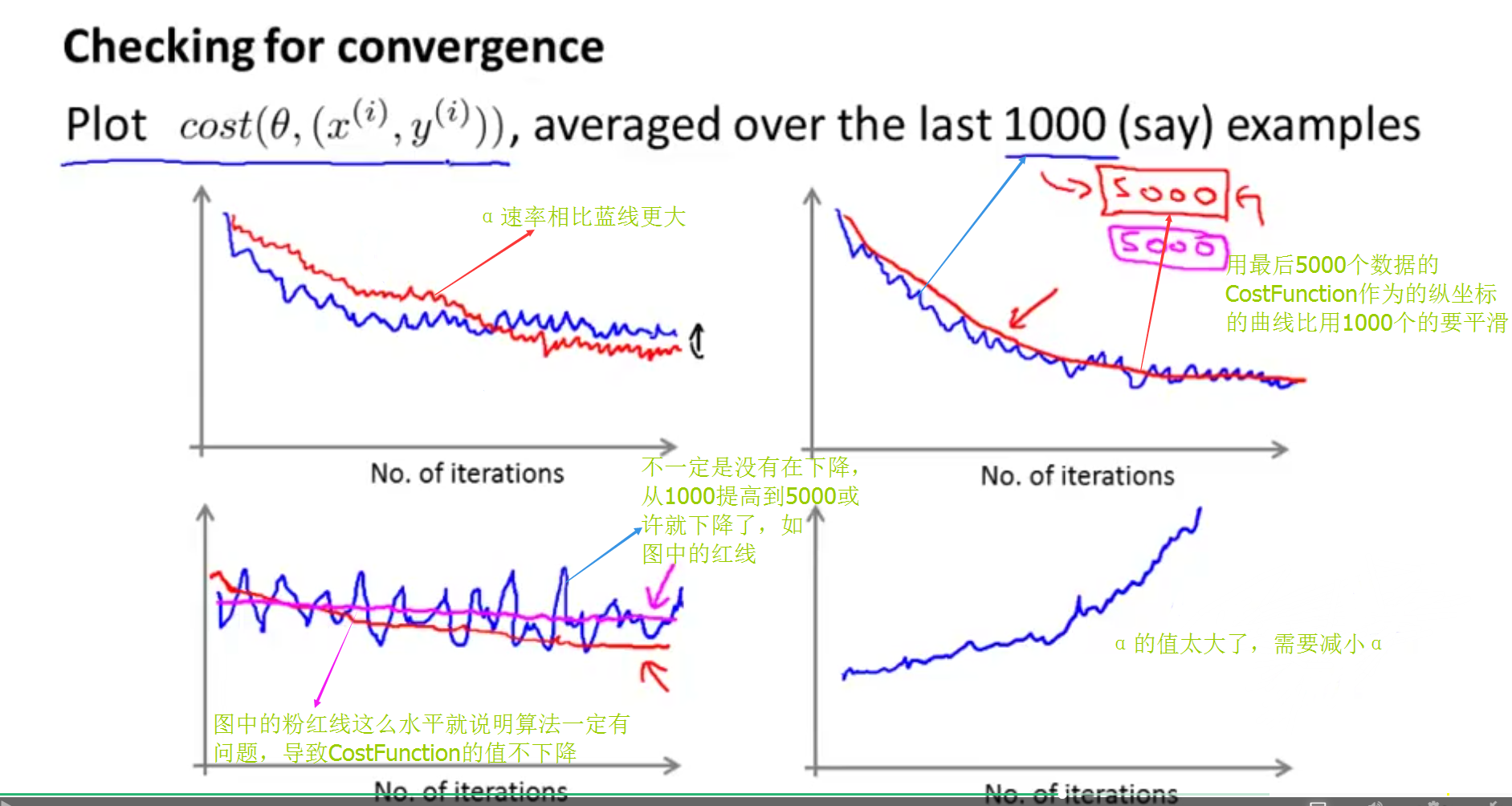
正常情况下,学习速率
α
是一个不变的值,而随机梯度下降的结果是收敛到接近全局最小值,如果我们希望
θ
的值更逼近全局最小值,那么我们可以让
α=const1iterationnumber+const2
,这样子的话
α
的值就会随着迭代次数的增加而减小,有利于
θ
收敛到更加接近全局最小值(因为是随机梯度下降,所以只能接近,仍无法像批量梯度下降那样收敛到全局最小值)
(但这种随着迭代次数改变
α
的方法,可能会多一个步骤去选取const量)
Online Learning在线学习机制
根据线上用户的信息去更新自己的算法,使用完数据就丢弃
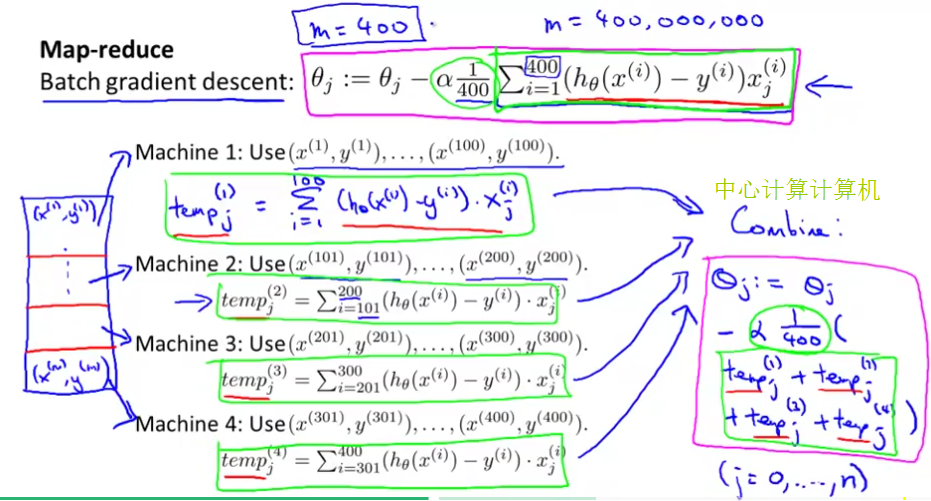
Map Reduce 映射约减
这是进行大规模机器学习的一种方法,通过将数据分配到多台计算机(多核处理器)的方式来并行化机器学习算法
具体为把Training Set分成N份,然后用N台计算机分别计算
temp(i)j
最后再把数据放到中心运算计算机算出
∑
的结果,这个结果与
在下面这个例子中,把Training Set分成了四份,这样子可以提高运算的速度,(理论上可以有四倍运算速率,但是有网络延迟和数据汇总等时间,所以实际会小于四倍)
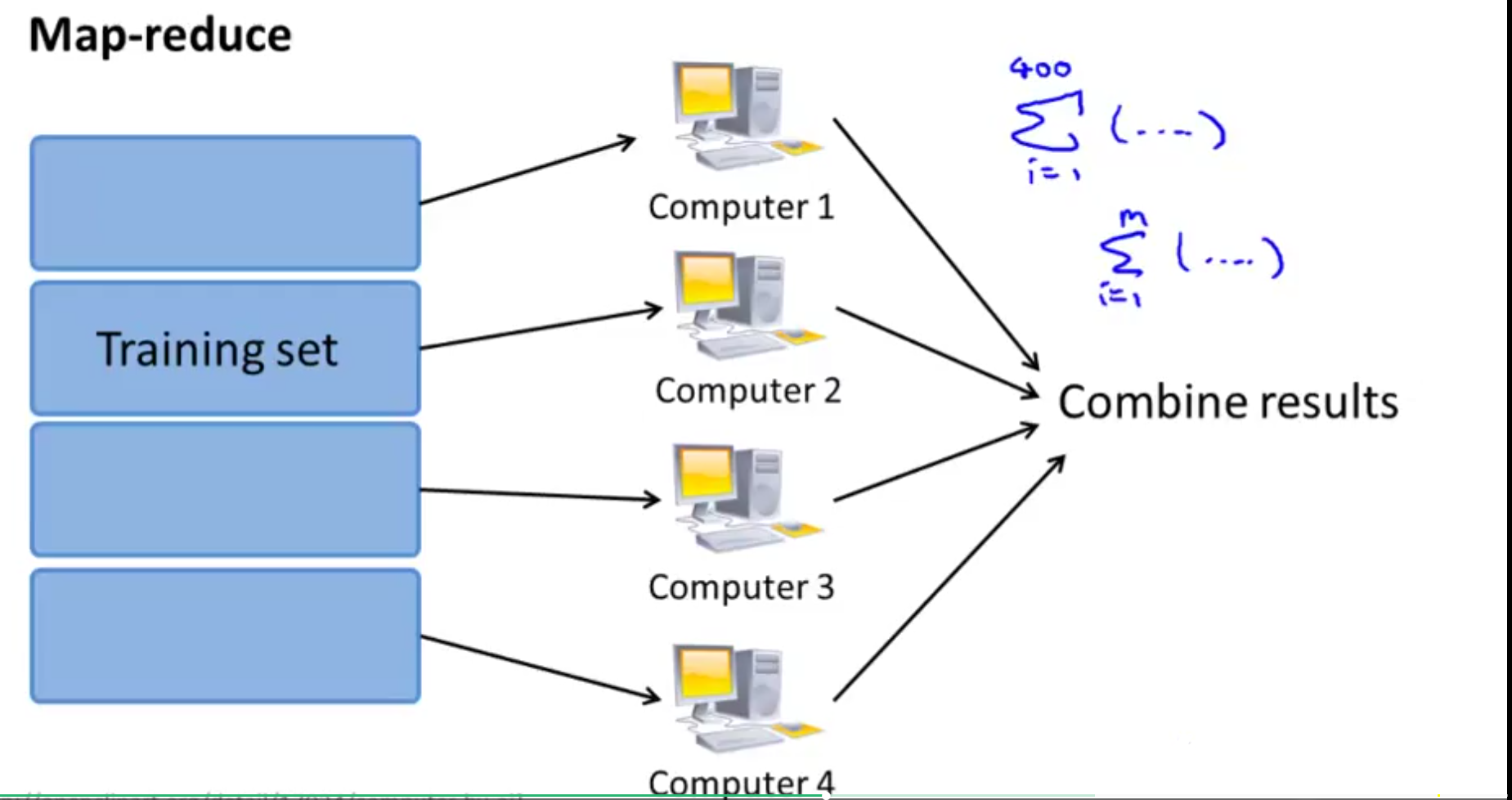
映射约减最重要的在于机器学习算法最后能否表现为训练样本的一种求和的形式
Week11
Ceiling Analysis上限分析可以帮助我们找到改进的重点















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









