







光学字符识别 photo optical character recognition (Photo OCR)
Photo OCR的machine learning pipeline 包含以下component
text detection
character segmentation
character recognition

在设计好pipeline以后,就可以对每个模块进行人员分配
sliding windows 滑动窗口
用来进行text detection,在训练的过程中,需要用到标记正负的训练集
类似的有行人检测, 行人检测的aspect ratio固定为82×36
在slide window detection 中,参数 stepsize/stride 可以设置为4 or 8 pixel
在 text detection中,还需要进行expansion,煎检测出来的text连在一起
第二阶段是character segment

第三阶段的character classification,可以用之前讲解过的监督学习,也可以用神经网络
artificial data 人造数据
artificial data synthesis 能够生成很多标记的数据来训练你的算法那,可以完全自己生成,或者在已有的数据集基础上引入distortion,例如将图像变形,或者在音频中引入背景噪声。
注意
1)不要引入无意义的噪声,比如在字符识别的训练集数据中将图像的个别像素点加深
2)不要在欠拟合的情况下扩充训练集,在扩充训练集之前,增加feature或者增加神经网络的隐藏层,确保算法是low bias的。通过话learning curve 来判断是否欠拟合
3) 将训练集扩充1倍需要多少工作量(时间)? 这是Andrew常问的问题。除了人工合成数据,还可以人工收集/标记数据,还可以寻找crowd source(e.g. Amazon Mechanical Turk)。如果代价可控,数据集的扩充对训练算法有很大的作用
ceiling analysis
estimating the errors due to each component
例如在photo OCR 中,将第一个module 的结果人工标记为百分之百正确,然后再计算overall accuracy,然后将第二个module也人工标记为百分之百正确,再计算 overall accuracy。这样可以得出哪个module值得花时间去改进,也可以知道改进某个模块带来的overall accuracy的增加的上限在哪里。
即使Andrew 也不会用gut feeling 来确认哪个模块更值得改进,也会用ceiling analysis。
summary

【review】 learning curve
诊断算法是 bias 还是variance
如果Jtrainning 和Jcv都很高: bias 欠拟合
如果Jtraning 很低,但是Jcv很高,而且远大于Jt:过拟合 variance
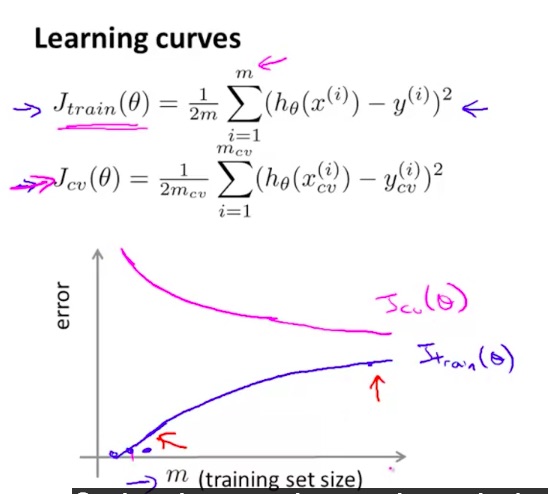
欠拟合的情况下 两个曲线很快变平 然后 非常靠近
意味着训练集合变大没有什么作用
过拟合的情况下 两个曲线之间会有很大的gap 不会互相靠近 但是训练集变大gap会变小
这种情况下 增加训练集合 有作用















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









