







Week7:Support Vector Machine(SVM) 支持向量机
SVM又称为大间距分类器(Large Margin Classifier)
SVM以及其目标函数
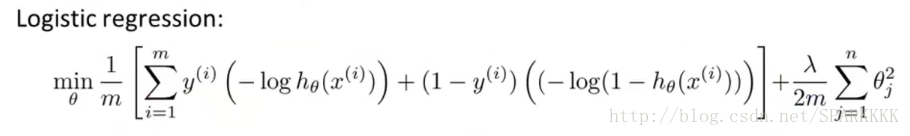
与逻辑回归不同的是把
1m
这个常数项舍去,因为其对最后的结果(即代价函数取
min
时
θ
的值)没有影响
而且令
C=1λ
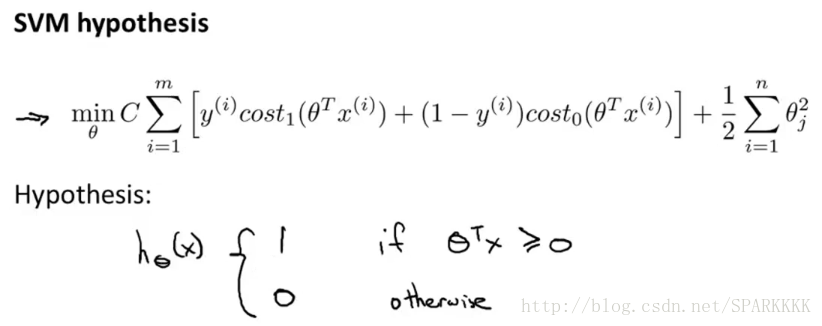
这就是SVM的数学表达式,Cost函数不一定就是
log
那种类型的


为了使
min
函数前面一项为0,须有
θTx(i)≥1
if
y(i)=1
或
θTx(i)≤−1
if
y(i)=0
这样就有SVM函数
minθ12∑j=1nθ2j

注意margin(一般取1,即
θTx≥1
和
θTx≤−1
中的1和-1),而且一般是有方向性的,即线的一边为y=1,线的一边为y=0
SVM的数学原理
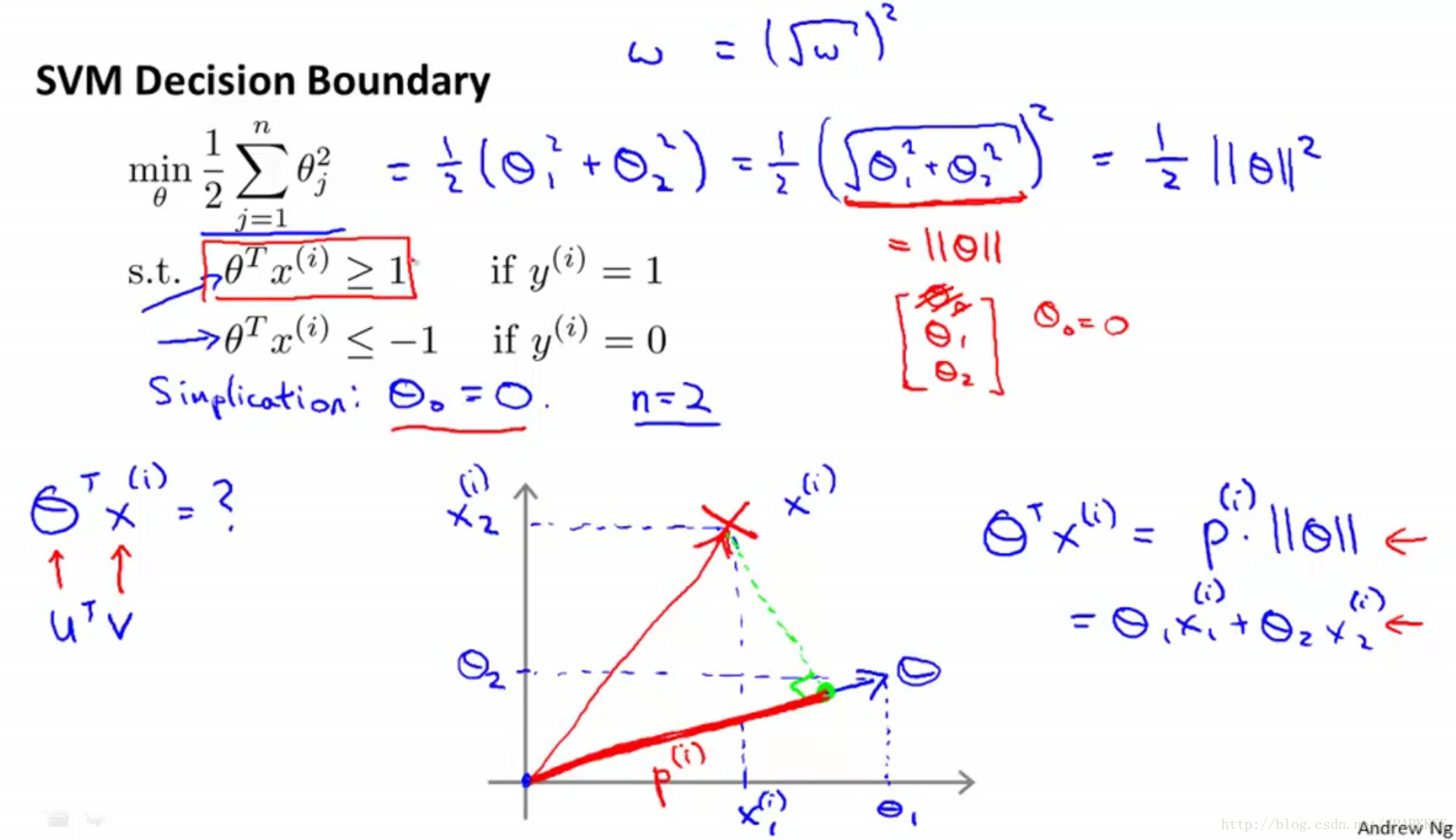
对于
θTx(i)
可以认为是范数
||θ||
和投影
p(i)
的乘积

对于上图中的绿色线为SVM决策边界,蓝色线
θ
向量的方向与决策边界垂直
对于上图中的左下图
p(2) 同理
这个时候说明这个决策边界选择不合适,我们要实现的应该是使得 p(i) 更大,令 ||θ|| 更小
对于上图中的右下图
Margin其实就是训练样本到决策边界的距离,其实也就是 p(i)
对于SVM,它产生Large Margin的原因在于选择了最合适的决策边界使得 p(i) 极大化,进而极小化 ||θ|| ,这也是SVM中最小化目标函数 12∑j=1nθ2j 的意义所在
Kernels核函数

上图中是非线性决策边界
K(x,l(i))
称为核函数
在下图中为高斯核函数

Gaussian Kernel:高斯核函数
fi=exp(−||x−l(i)||22σ2),where l(i)=x(i)Need to choose σ2

最高点函数的值必为1
下图中
f1
、
f2
、
f3
的定义均与上图类似,本质上是
fi=similarity(x,l(i))
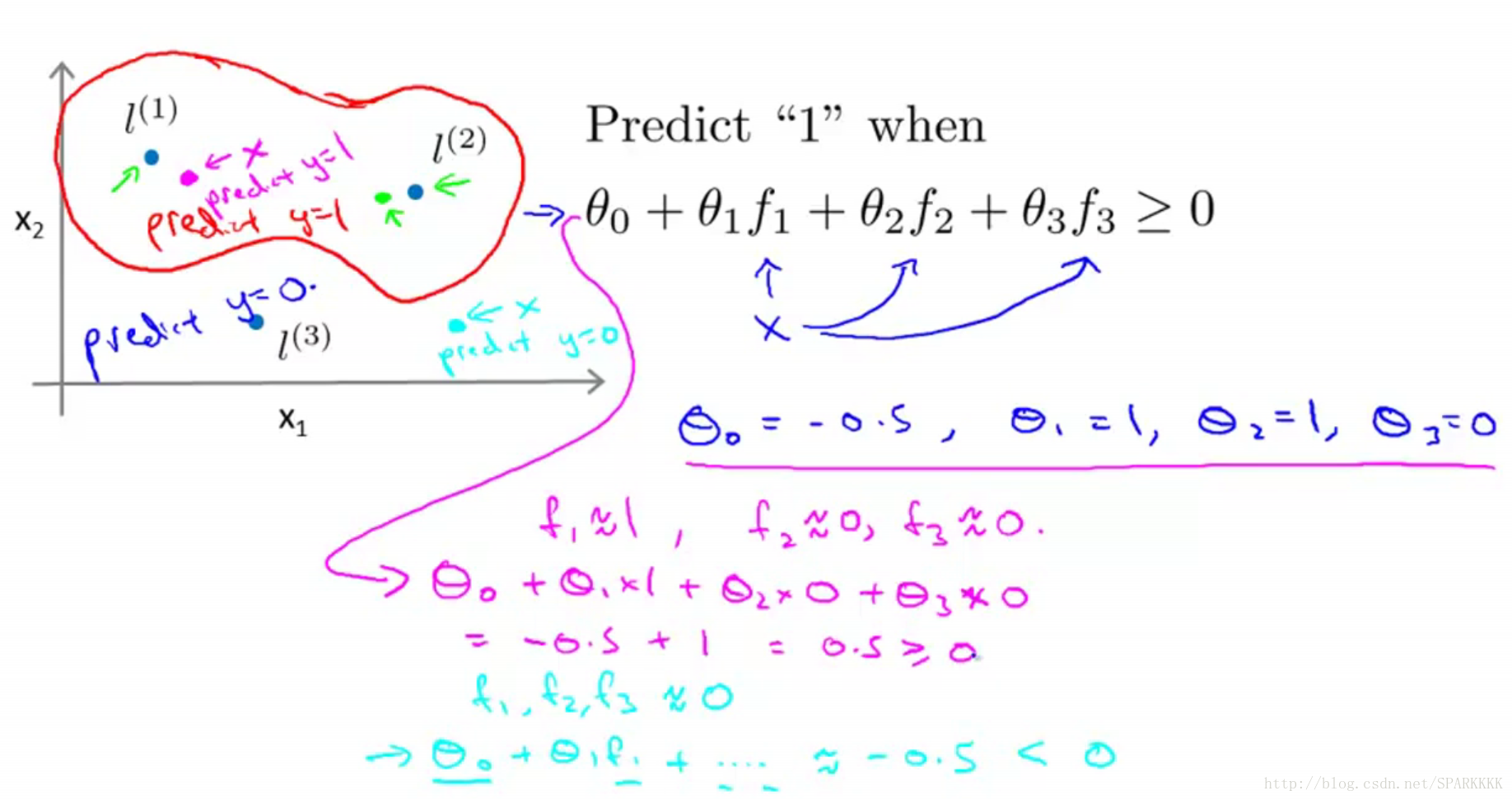
对于上图中靠近
l(1)
、
l(2)
的点,根据
fi
和
θi
的值预测结果为y=1,对于远离
l(1)
、
l(2)
的点预测结果为y=0
所以我们可以用landmark标记点和KernelsFunction核函数来训练出非常复杂的非线性边界

f(i)
是一个特征向量,与
x(i)
有关

使用Kernel的时候将cost函数中的
θTx(i)
替换为
θTf(i)
,然后根据Kernel修改正则项为
θTMθ
,M取决于Kernel,以用更高计算效率适应超大训练集。
但是需要提到的一点是,如果把逻辑回归和Kernel结合,那运行效率很低
SVM参数选择

No Kernel(“linear Kernel”)为 θTx
使用Linear Kernel的时候一般是x的变量数多但是样本总数少
使用Gaussian Kernel的时候一般是x的变量数少但是样本总数多
不是所有的SimilarityFunction
similarity(x,l)
是有效的Kernel,必须遵循Mercer’s Theorem ,使SVM正确地收敛
一般用的比较多的Kernel是高斯和线性,但也有其他的一些例如
* PolynomialKernel
(xT+constant)degree
* String Kernel
* chi-square Kernel
* histogram intersection kernel
* …
Multi-class classification
可以用one-vs.-all method(用对K个类用K个SVM然后每个类用一个SVM)
或者使用SVM包内置的多类别分类器
逻辑回归 vs. SVMs
逻辑回归 与 SVM without Kernel 是十分相似的算法
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









