







由于从事Linux工作中需要,补充了一下GUN语法的汇编,虽然以前接触8051汇编,但是经过实践后,重新学习,确实效果完全不一样,在学习的过程中,脑海中能与实践中的一一对应起来,会让人有种“顿悟”的感觉,果然,学习工科的黄金法则:理论->实践->再理论->再实践的过程才能快速进步,写下这篇笔记总结一下。
参考书籍主要有以下:
1、杜春雷 ARM体系架构与编程 – 个人认为学习ARM与汇编编程比较全的书籍,很多书籍都对汇编与ARM架构泛泛而谈,一带而过。遗憾的是书本上的例程都是需要在windows ADS / CodeWarrior环境上跑,并且是intel格式的,跟在Linux gcc / arm-linux-gcc支持的AT&T格式有区别。
2、韦东山 嵌入式Linux应用开发完全手册-- 这本偏应用书,背景是韦老大实践后写的手册,开发涉及到的知识基本都有 境界高。。
3、还有开发者少不了的网络论坛 – 个人觉得学习新知识不能只依靠论坛博客(零散、质量也参差不齐,很容易把人绕晕),只能作为知识遗忘参考,还是手握一本书籍好,权威而系统;
注:实践的环境是ubuntu+gcc+x86,没有选择linux+arm+arm-linux-gcc是因为入门的资料太少(可能我没有找到,有资料的同学也可以安利一下我。),实践起来也麻烦一些。想着先熟悉一下x86的,再来深入arm的,对比着学习,可以给你更多的体会。
末尾还会附上学习过程中收集的资料以及可以直接运行的3个简单例子。
一、汇编的作用地位
在出现C语言等高级语言后,完全使用汇编写程序几乎不存在了,因为移植性太差并且编写枯燥,见过一个老前辈完全用汇编写一个单片机工程,C语言大概是一万行的规模,对比C语言,汇编占用空间很小,运行速度也较快;对于Linux内核底层开发来说,主要以C语言为主,上层业务会使用C++/Java,一些插件模块偶尔会使用Python,需要汇编的地方很少但对于系统运行来说都是重要的,无论是Linux系统还是其他操作系统,有些开源代码亦是如此,常见的有如下几个:
a、启动代码:初始化硬件资源,建立C语言运行环境,任何一个系统都有汇编启动代码(单片机/ARM/x86),ps:C语言做不到;
b、执行特定机器指令:如ARM在切换CPU模式/线程切换,将会执行设置寄存器,保存上下文(寄存器环境)等操作,ps:C语言做不到;
c、效率要求很高的场合,比如一条汇编指令能处理的事情,C语言需要多条指令才能完成,可能对于程序员来说差别是极小的时间数量级,但是对于系统来说极其重要;
d、对于底层内核开发者来说,定位问题有时需要汇编阅读能力(分析反汇编文件追踪出问题的代码段位置);
二、汇编的分类
从CPU体系来划分,常见的汇编有两种:IBM PC汇编和ARM汇编。汇编语言和CPU息息相关,但是不能把汇编语言完全等同于CPU的机器指令。不同架构的CPU指令并不相同,如x86,powerpc,arm各有各的指令系统;甚至同一种架构的CPU有几套指令集,典型的如arm除了有32位的指令集外,还有一套16位的thumb指令集。但是作为开发语言的汇编,本质上是一套语法规则和助记符的集合,它可以包容不同的指令集。
存在两种体系汇编的差异是因为IBM 最早推出PC机,后来的体系很多都要和它兼容,所以也使用了相同的汇编语言。ARM压根没考虑过兼容,它的指令集和x86完全是两个体系,所以汇编语言也独立发展出一套。
从汇编格式分,还有Intel格式和AT&T格式的区别,前者是Intel的,windows平台常见,后者最早由贝尔实验室推出,用于Unix中,GUN汇编器的缺省格式就是AT&T。不过GNU的汇编器和调试器gdb对这两种格式都支持,可以随便切换。MASM只支持Intel格式。Intel格式和AT&T格式的区别只是符号系统的区别,这与x86和arm的区别可不一样,后者是CPU体系的区别。
为什么汇编要区分格式? CPU只是限定了机器码,作为开发语言的汇编,其实还和编译器息息相关。汇编语言出现的早,没有像C语言一样定义出标准,所以编译器的厂商各搞一套。到现在,最有名的也是两家:MASM和GNU ASM。前者是微软的,只支持x86,用在DOS/Windows平台中;后者是开源产品,主要用在Linux中,基本上支持大部分的CPU架构。这两者的区别在于伪指令的不同,伪指令是用来告诉编译器如何工作的,和编译器相关,和CPU无关。其实汇编的编译相当简单,这两套伪指令只是符号不相同,含义是大同小异,明白了一种,看另一种就很容易了。
总的一句,在不同硬件平台,不同的开发环境编写汇编是有差异的,先抛开其他的8051/AVR等等,光是X86 / ARM + windows/linux你就需要掌握2种体系的汇编指令(PC汇编、ARM汇编),以及2种汇编格式(intel格式、AT&T格式),虽说可能在某种程度上是互通的,但也太难为程序员了。
工具支持的汇编格式:1、AT&T ( GAS : Gnu ASembler GNU汇编器 )支持 :gcc、arm-linux-gcc等linux工具; 2、intel格式支持:VS、ADS、RealView等windows工具;
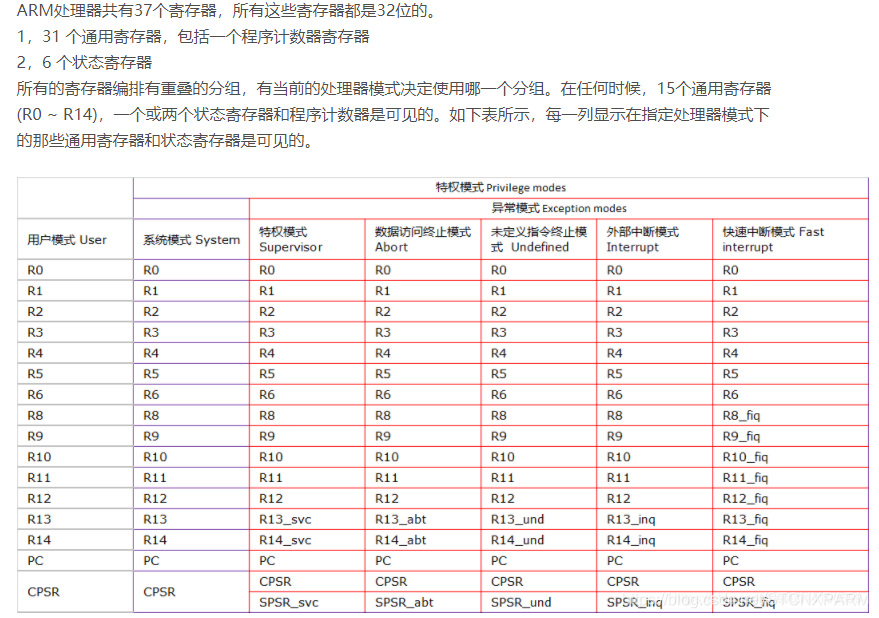
三、认识寄存器
汇编编程中基本都在操作寄存器,寄存器就是一个特殊的内存,机器所有的运算都产生在CPU(执行单元)与寄存器(暂存单元)之间,因此必须熟悉掌握,以下不详述 贴图简介:
借用几个ARM寄存器名词(其他类似):
a、通用寄存器:可以当作普通的4字节内存操作;
b、栈指针寄存器(sp):指向程序栈空间;
c、连接寄存器(lr):存放子程序返回地址;
d、程序计数器寄存器(pc):指向当前运行的程序指令;
e、程序状态寄存器(cpsr):指示当前处理器的状态:条件标志位、中断禁止位等等;
本质都是一块4字节内存,不同的就是某种状态下,cpu会自动把某些数据存取在某个寄存器上。
x86寄存器分类:
x86详解参考:

ARM寄存器分类:
四、基本汇编
1、汇编与CPU架构、硬件资源息息相关(工作模式、指令集、寄存器);ARM、X86、MCS-51、AVR…
2、汇编语言的程序入口默认为 _start(也可以通过链接脚本重新指定),C语言的程序入口默认为main( 当然main函数是启动汇编代码指定跳转的,可以修改 );
3、汇编语言是以段(Section)为单位组织源文件,段是相对独立的、具有特定名称、不可分割的指令或者数据序列,简单理解:一个生成好的bin文件,由许多段组成,每一个段相当于一个功能函数,这个是由编译器负责帮我们去排放的,处理就是按照这个顺序去执行指令的,所以说汇编更接近机器~;
4、段属性的基本分类:.text .data、.bss、以及程序员自定义段属性;(段属性十分重要,大多数段的排序由编译器自动排放,一些操作系统的启动部分经常需要程序员自己去组织段的顺序,以达到人为控制初始化的目的,这个需要了解连接脚本lds);
5、汇编语句基本由CPU指令、伪操作和宏指令;
伪操作,就是为了简化程序员对指令的处理而引入,在编译阶段会最终被编译器解析分解为指令;
比如mov(指令)、ldr(伪操作):
a、mov r0, #1 #1位置的数必须是立即数,并不是所有32位数都是立即数(符合一定规则):由一个8位的常数循环右移偶数位得到,右循环是一个4位二进制的两倍表示,这是因为任何一句cpu指令(指令+操作数)都是占4字节空间,那么一个操作数值只能占据其中某些位来储存,不能用完32个Bit;
b、ldr r0, =任意值 伪操作ldr则可为任意值,就不需要去算立即数,编译器会按照规则自动处理;
6、ARM寻址方式:
a、寻址方式是指处理器根据指令中给出的地址信息(常量、寄存器、变量、偏移等方式),找到真实操作数地址内容的方式;
b、CPU读取值两种方式:
1、寄存器:CPU<->寄存器;
2、内存(复杂耗时):CPU<->MMU<->内存控制器<->内存
7、寻址表达式(目的就是为了方便程序的编写) – 相当于C语言的各种指针表达式:
访问内存时在指令中可以用多种方式表示内存地址。内存寻址在指令中可以表示成如下的通用格式:
ADDRESS_OR_OFFSET(%BASE_OR_OFFSET,%INDEX,MULTIPLIER)
它所表示的地址可以这样计算出来:
FINAL ADDRESS = ADDRESS_OR_OFFSET + BASE_OR_OFFSET + MULTIPLIER * INDEX
其中ADDRESS_OR_OFFSET和MULTIPLIER必须是常数,BASE_OR_OFFSET和INDEX必须是寄存器。在有些寻址方式中会省略这4项中的某些项,相当于这些项是0。
直接寻址:只使用ADDRESS_OR_OFFSET寻址,例如movl ADDRESS, %eax把ADDRESS地址处的32位数传送到eax寄存器。
变址寻址:movl data_items(,%edi,4), %eax就属于这种方式,用于访问数组很方便
间接寻址:只使用BASE_OR_OFFSET寻址,例如movl (%eax), %ebx,把eax寄存器的值看作地址,把这个地址处的32位数传送到ebx寄存器。
基址寻址:只使用ADDRESS_OR_OFFSET和BASE_OR_OFFSET寻址,例如movl 4(%eax), %ebx,用于访问结构体成员比较方便,例如一个结构体的基地址保存在eax寄存器中,其中一个成员在结构体内偏移量是4字节,要把这个成员读上来就可以用这条指令。
立即数寻址:就是指令中有一个操作数是立即数,例:movl $3, %eax。
寄存器寻址:就是指令中有一个操作数是寄存器。在汇编程序中寄存器用助记符来表示,在机器指令中则要用几个Bit表示寄存器的编号,这几个Bit与可以看做寄存器的地址,但是和内存地址不在一个地址空间。
8、一个最基本的汇编程序例子(包含.text .data段):
```c
#数据段,定义数据
.section .data
.align 4 # 4字节对齐
msg : .string "Huawei co,Ltd!\n" # 要输出的字符串,msg为该字符串的地址
#程序入口,编译器默认指定_start
.section .text # 代码段声明
.global _start # 指定入口函数,汇编程序的默认入口()
_start:
movl $0, %ebx # 参数一:退出代码
movl $1, %eax # 系统调用号(sys_exit)
#触发异常
int $0x80 # 调用内核功能
.end #源文件结束
相当于C语言程序:
```c
char msg[] = "Huawei co,Ltd!\n"
int main(void)
{
exit(0);
}
9、子程序调用的三种参数传递方式:
a、寄存器方式:就是把寄存器当作全局变量来使用;
b、栈传递:按照一定顺序去存放,然后子程序按照相反方向取出来即可;
c、全局变量;
10、调用其他源文件的函数:
由于汇编没有头文件,整个工程只有源文件,可以通过声明函数符号为全局(用关键字.global进行声明):
.global function #声明为全局符号
function:
#函数实现
过多的语法知识就不详述了,这里只是引导 了解基本概念以及大体的程序框架,这样可以编写一个简单的汇编程序(文章末尾提供三个简单例程),再深入的话必须动手实践,往框架里填充,千万要动手练习,即使很看懂明白了,但实质上只停留在印象阶段(过会就忘),无法成为你脑海里的知识,但是经过手敲代码,可以加深印象,增强编写/读懂汇编代码的自信心;嵌入式这东西,要学的知识内容实在太多,单靠脑子印象记忆根本无法驾驭,请放下你的自信,踏实地重复练习,很多编程知识,是无法用文字一一表述的(描述的只是理论),更多的内在知识需要你在动手编程后才会被发现挖掘;在实践过程中,主要还是参照C语言的编程思维走的,所有编程的本质都是一样,只是在于技巧方式的不同。
五、其他
这里介绍一些杂类的汇编编程知识;
一、ATPCS:
a、ATPCS:一种协议,为了让各种不同的程序可以互相交织,因为不同程序对于使用硬件资源的规则是不完全一致的,不遵循统一的规则,混用程序会导致硬件资源被不适当使用;
b、基本规则包括:寄存器的使用、数据栈的使用、参数的传递;
二、C/C++以及汇编语言的混合编程:
1、C/C++调用汇编三种方式:
a、__asm{ } b、asm(" "); c、asm(“instructment” : output : input : modify)
第三种GNU内联汇编比较复杂,详细看附件资料教程:AT&T_GCC_ASM.pdf
2、汇编调用C/C++:
a、直接调用C程序;
b、调用C++
1、C++源文件需要声明:extern “C” void func(void)
2、汇编源文件需要:伪操作:IMPORT func
3、C++调用C程序:
a、调用部分需要 extern “C” { } 进行声明
三、汇编文件可以使用C/C++预处理,比如#define #include #if 等等,gcc识别 ".S"文件结尾(大写字母S),决定是否采用预处理机制,小写则不会预处理。
四、汇编( .asm/.S )与反汇编( .dis )的关系:
1、汇编工程文件是程序员,根据语法规则自由组织的文件集合;
2、反汇编由可执行文件(经过连接器连接的),解析而来;是按照实际内存分布来排布的;
3、汇编与反汇编文件的差异:
a、反汇编使用十六进制;
b、汇编与反汇编操作寄存器或存储器的地址有所不同;
4、反汇编片段:
第一列是汇编指令在内存的地址,第二列为汇编指令对应的CPU机器码,后面为汇编指令。
08048074 <_start>:
8048074: ba 10 00 00 00 mov $0x10,%edx
8048079: b9 98 90 04 08 mov $0x8049098,%ecx
804807e: bb 01 00 00 00 mov $0x1,%ebx
8048083: b8 04 00 00 00 mov $0x4,%eax
8048088: cd 80 int $0x80
804808a: bb 00 00 00 00 mov $0x0,%ebx
804808f: b8 01 00 00 00 mov $0x1,%eax
8048094: cd 80 int $0x80
五、x86与ARM跳转与返回的差别对比:
1、 x86:jmp:直接跳转,不保存现场 ; call:保留现场,返回地址入栈,ret伪指令返回; 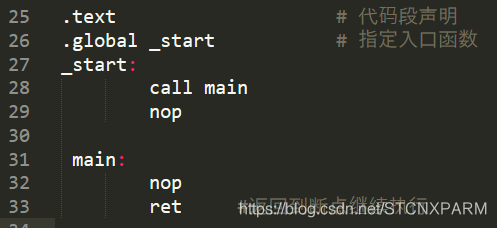
2、 ARM:b:直接跳转,不保存现场 ; bl:保留现场,返回地址入栈,mov pc. lr; 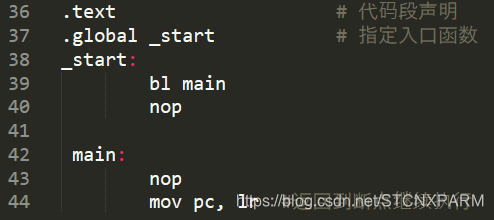
参考资料大全:https://download.csdn.net/download/STCNXPARM/12112051
三个汇编例子:https://download.csdn.net/download/STCNXPARM/12112044
makefile&lds链接文件:https://download.csdn.net/download/STCNXPARM/12112353














 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









