





Reinforced Feature Extraction and Multi-Resolution Learning for Driver Mobility Fingerprint Identification
Mahan Tabatabaie, Suining He, and Xi Yang. 2021. Reinforced Feature Extraction and Multi-Resolution Learning for Driver Mobility Fingerprint
Identification . In 29th International Conference on Advances in Geographic
Information Systems (SIGSPATIAL ’21), November 2–5, 2021, Beijing, China.
ACM, New York, NY, USA, 12 pages. https://doi.org/10.1145/3474717.3483911
Group: University of Connecticut
1. 背景和问题
Driver mobility fingerprint (DMF) identification --驾驶员移动性指纹识别,从历史轨迹等数据中获取用户画像。
主要解决两类问题:
(1)确定生成的轨迹是否属于某个特定驾驶员;
(2)根据驾驶员的历史数据检测轨迹是否异常。
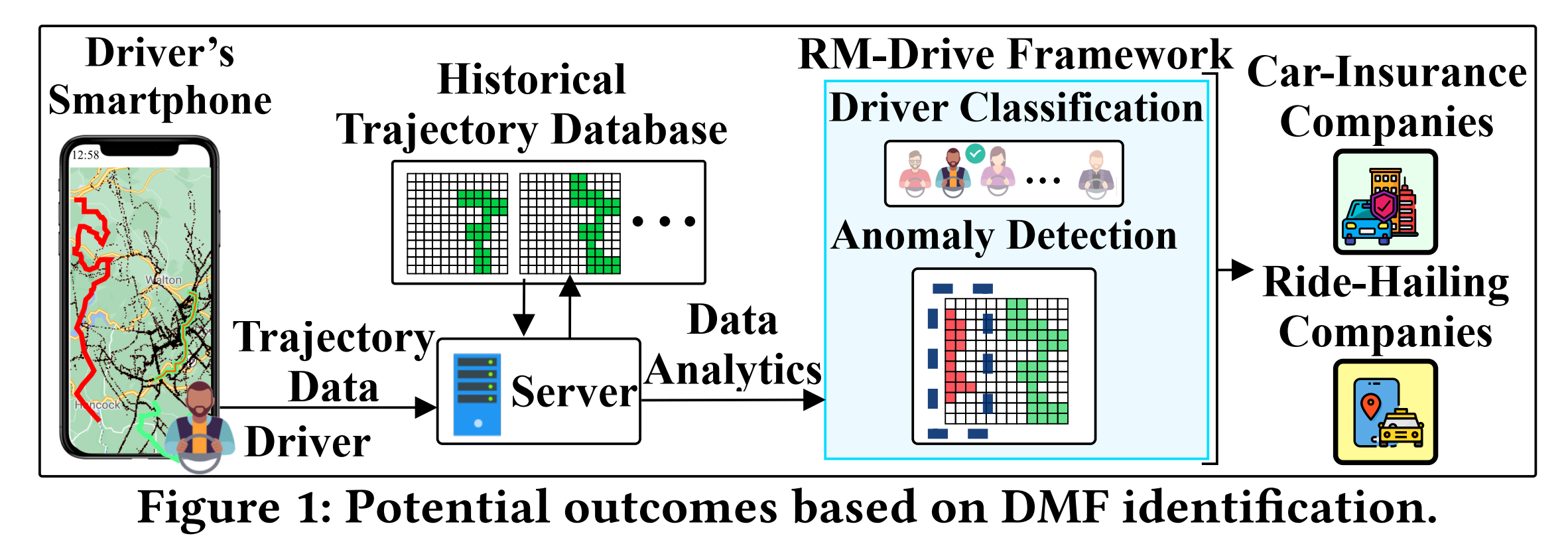
DMF识别问题仍然存在如下技术阻碍:
1)驾驶员轨迹和出行行为具有复杂的移动特性;
2)时空特征与环境因素融合不足;
3)缺少多分辨率驾驶员移动性建模。
为此,本文提出RM-Drive (Reinforced feature extraction and Multiresolution learning for DMF identification).主要贡献如下:
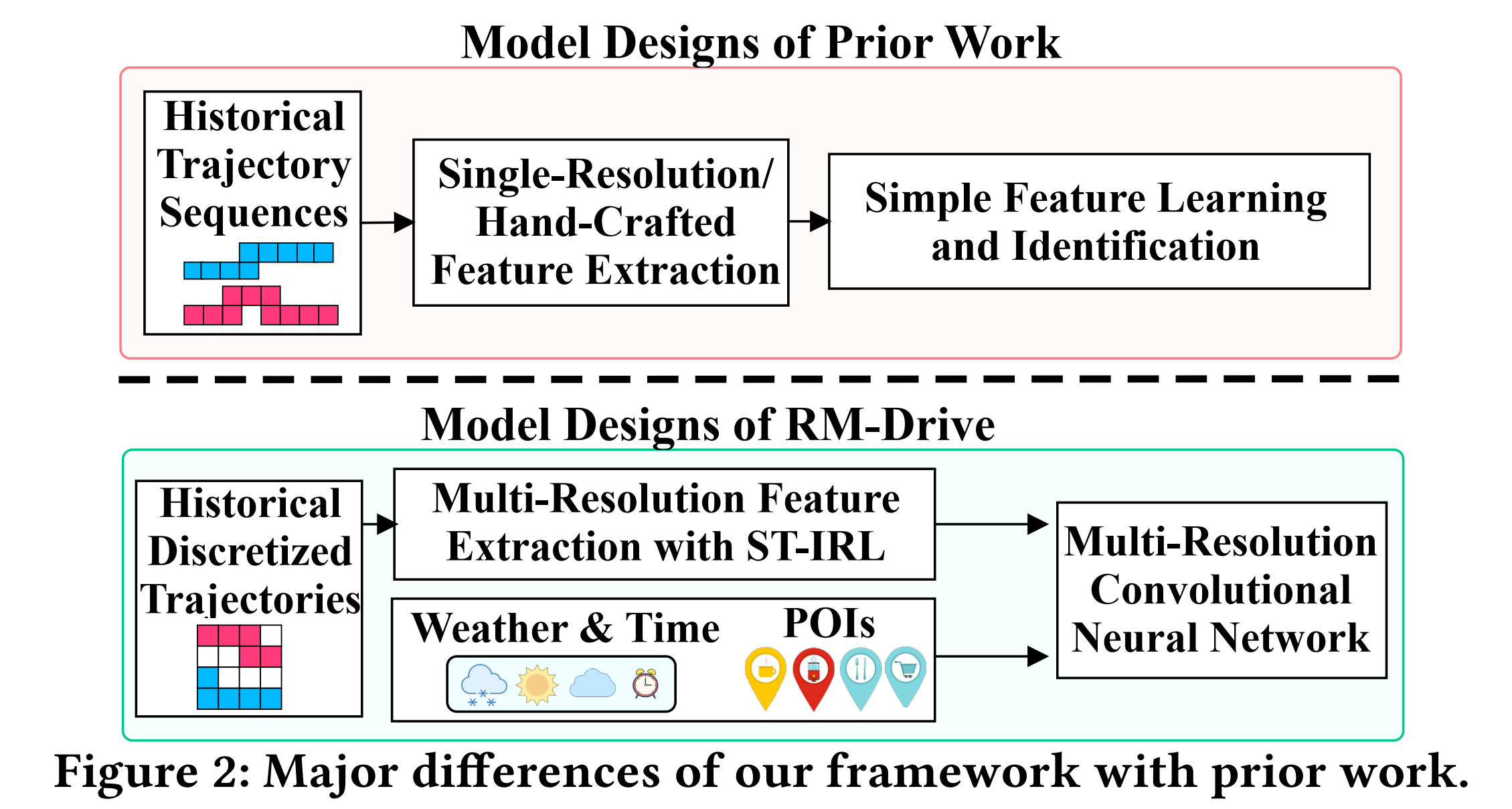
(a)利用时空逆强化学习,从历史轨迹中提取隐藏的DMFs,而不用手工选择特征工程;
(b)多分辨率下的深度DMF学习,融合时空特征和上下文因素(天气和POI等),实现总体准确度和鲁棒性的增强;
(c)在两份真实数据集上进行了分析和实验,与最先进的驾驶员分类和异常检测模型相比,RM-Drive的平均得分分别提高了21%和11%。
2. 方法介绍
2.1 系统结构
RM-Drive包含三个阶段
(1)预处理阶段:轨迹去噪后,先进行时间离散化,将每天划分为T个等长的时间间隔。然后进行空间离散化,用 H l \mathcal{H}_{l} Hl和 W l \mathcal{W}_{l} Wl表示在 l l l-th空间分辨率下的高度和宽度,由此为每个时间间隔生成空间网格图。
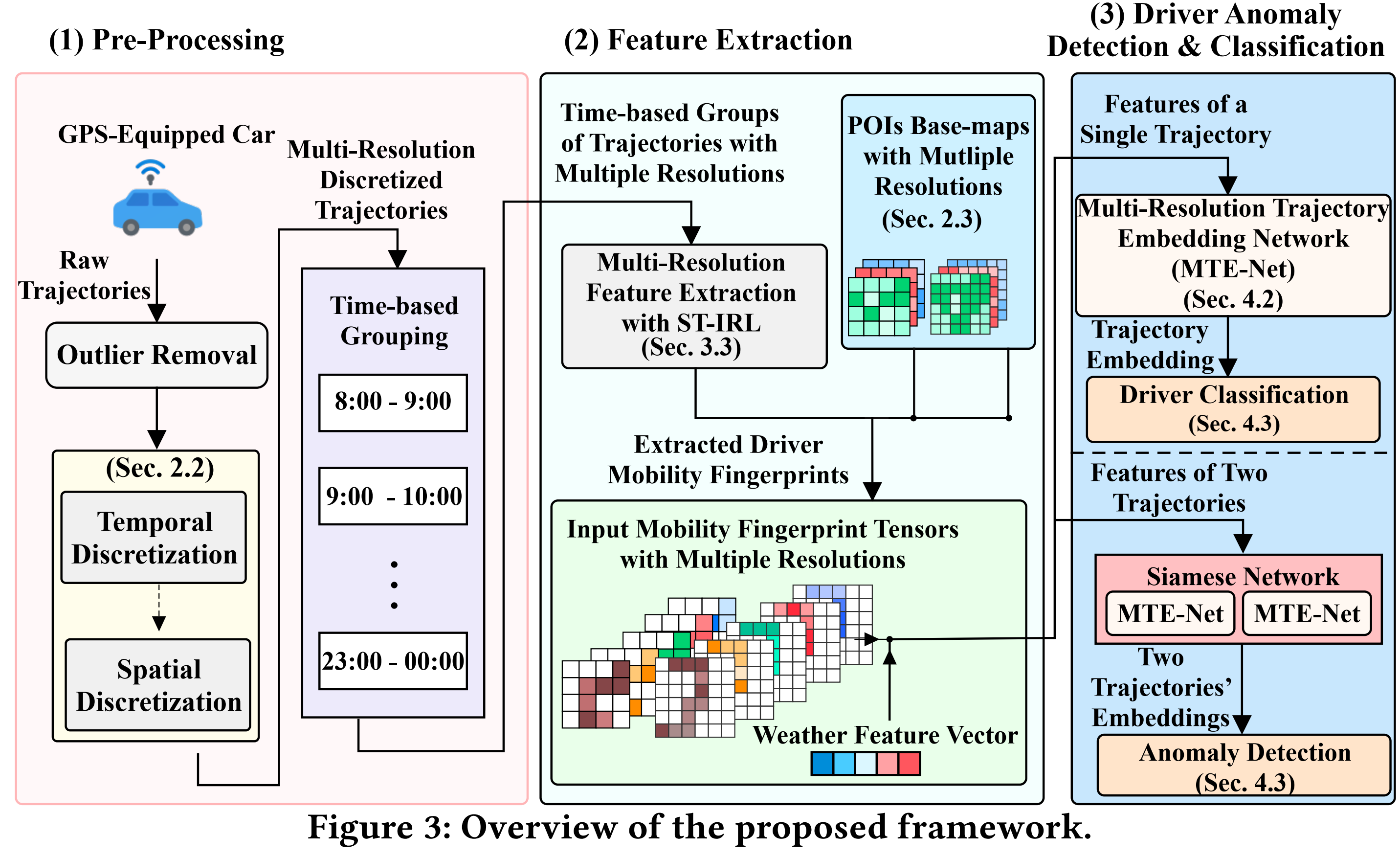
(2)特征提取:将每组轨迹转化为状态-动作对,以构造时空逆强化学习问题(ST-IRL),基于时间间隔和轨迹分辨率提取时空DMFs,构造驾驶员reward和policy的base map,以及反映POI密度的heat-map和天气向量。
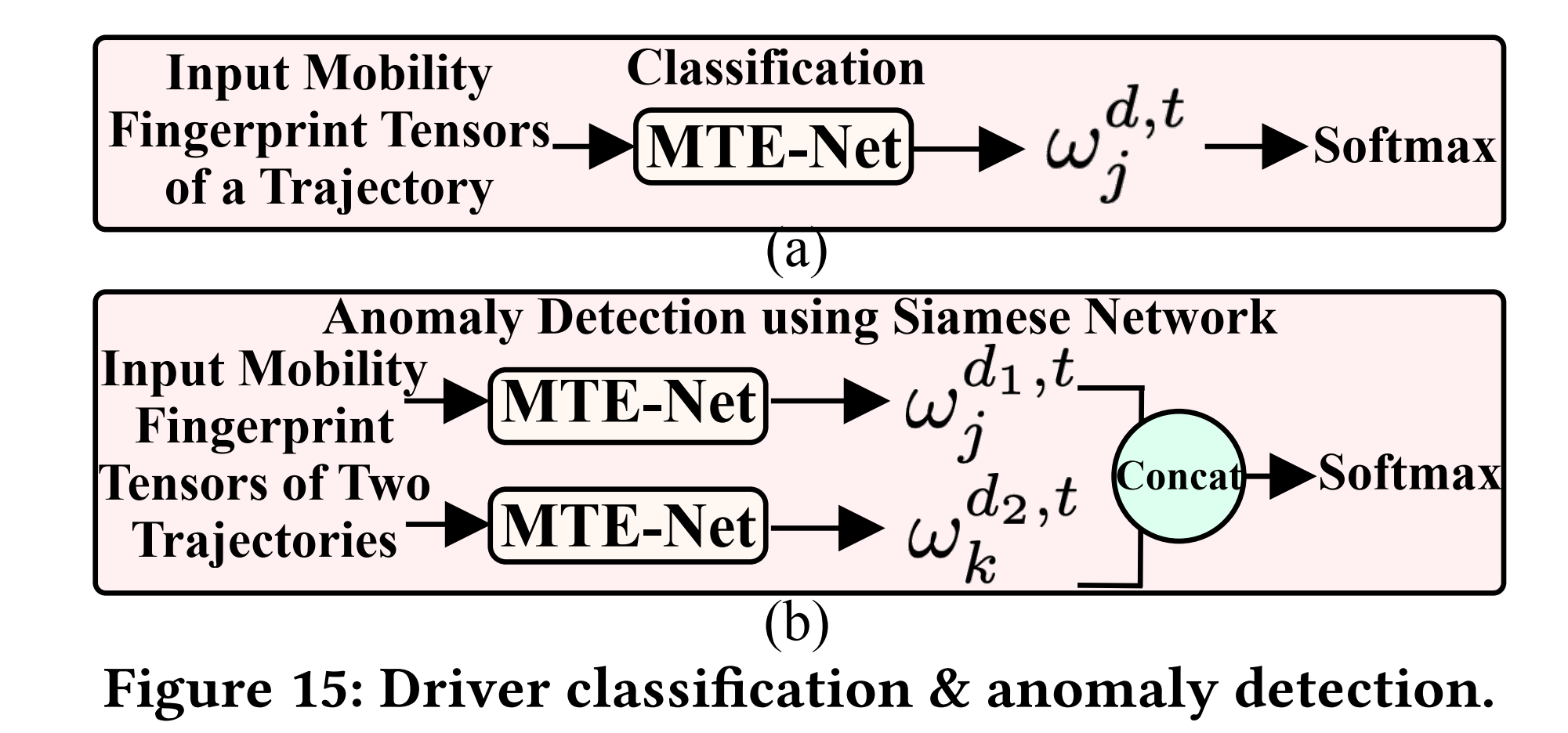
(3)驾驶员分类&异常检测:在驾驶员分类方面,将轨迹的移动性指纹张量(以驾驶员的标签作为真值)输入到MTE-Net,利用多分辨率卷积神经网络(MR-CNN)识别驾驶员;对于异常检测,采用连体网络,即使用两个具有相同网络结构的MTE-Net模块,构造一个用于驾驶员异常检测的二元分类器。
2.2 问题定义
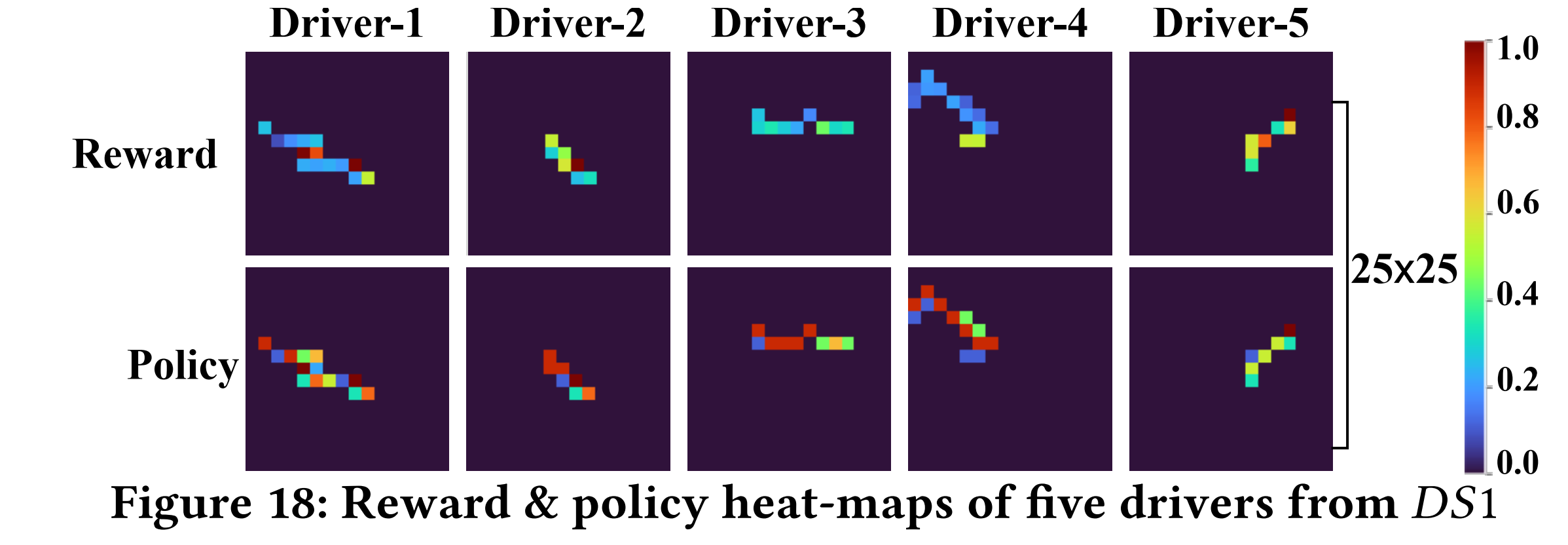
base-map:大小为 H l × W l \mathcal{H}_{l} \times \mathcal{W}_{l} Hl×Wl的矩阵,其中的值为归一化到[0,1]的数值,来表示不同的空间输入特征。利用base-map可以构造不同的轨迹heat-map,如Figure5所示。对每条离散化后的轨迹 ( τ l , j d , t ) ′ \left(\tau_{l, j}^{d, t}\right)^{\prime} (τl,jd,t)′,都会根据reward R l d , t R_{l}^{d, t} Rld,t和policy π l d , t \pi_{l}^{d, t} πld,t base-maps,生成reward/policy heat-maps χ l , j d , t \chi_{l, j}^{d, t} χl,jd,t 和 ψ l , j d , t \psi_{l, j}^{d, t} ψl,jd,t。
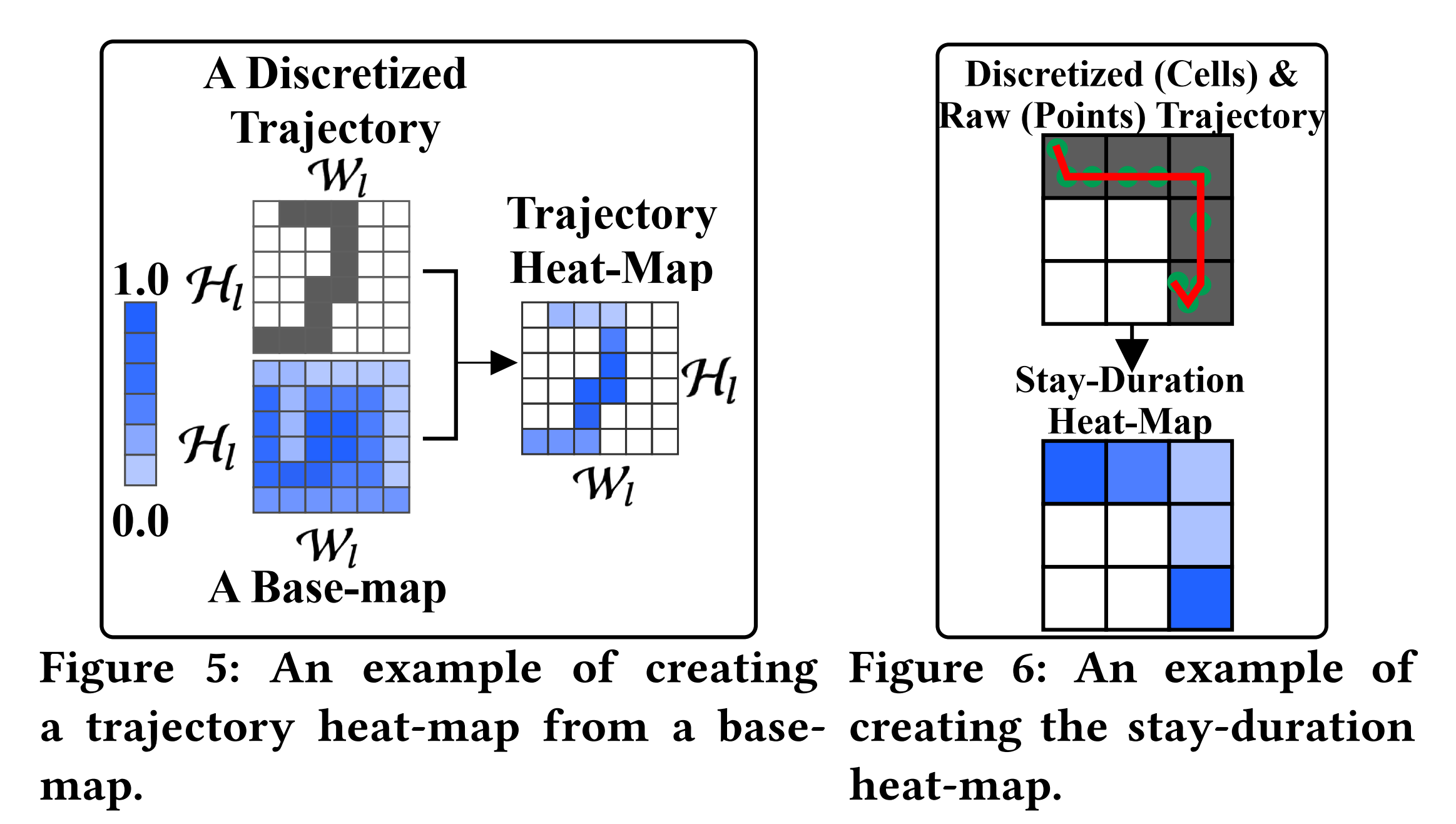
上下文因素:利用 Z Z Z类POI,基于其在地图上的分布生成 Z Z Z个base-maps,然后利用上述相同方法生成相应的heat-maps, o l , j d , t \mathbf{o}_{l, j}^{d, t} ol,jd,t。然后根据温度、雨雪等,生成7维的天气向量 c j d , t ∈ R 1 × 7 c_{j}^{d, t} \in \mathbb{R}^{1 \times 7} cjd,t∈R1×7。
移动性指纹张量:
f
l
,
j
d
,
t
=
(
ϕ
l
,
j
d
,
t
,
χ
l
,
j
d
,
t
,
ψ
l
,
j
d
,
t
,
o
l
,
j
d
,
t
)
f_{l, j}^{d, t}=\left(\phi_{l, j}^{d, t}, \chi_{l, j}^{d, t}, \psi_{l, j}^{d, t}, \mathbf{o}_{l, j}^{d, t}\right)
fl,jd,t=(ϕl,jd,t,χl,jd,t,ψl,jd,t,ol,jd,t)
问题定义:
已知多个驾驶员的历史轨迹数据,根据时空离散化后的轨迹,得到轨迹多分辨率下的时空和移动性特征,结合POI分布及天气等上下文信息,得到多分辨率下的移动性指纹张量,作为RM-Drive的输入,以实现异常检测和驾驶员分类。
2.3 轨迹特征提取
ST-IRL:
状态–对应着地图的每个网格;动作–对应着在地图网格上移动的方向

policy base-map示例如Firgure 9,每个值表示在该状态下policy建议的action的索引。
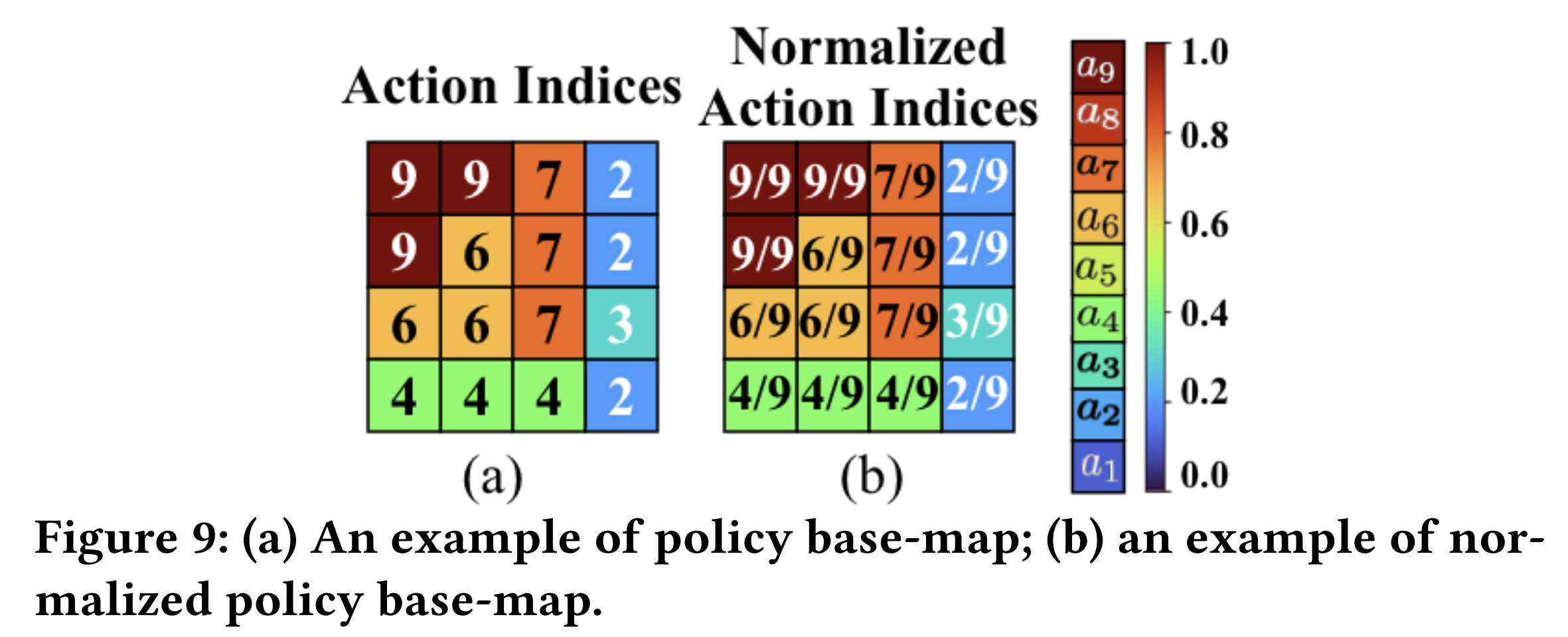
ST-IRL的目标是根据历史轨迹,恢复reward
R
l
d
,
t
R_{l}^{d, t}
Rld,t和policy
π
l
d
,
t
\pi_{l}^{d, t}
πld,t base-maps。
根据同一驾驶员各时间段下的state-action历史轨迹,可以得到对应的reward base-map,其中每个值表示对应状态下驾驶员𝑑的奖励值。
在恢复policy base-map时目标函数是在给定reward base-map下,最大化生成state-action轨迹的联合后验分布。

Fig. 10展示了使用reward、policy和两个POI类别base-map为离散轨迹创建的输入移动性指纹张量的示例。
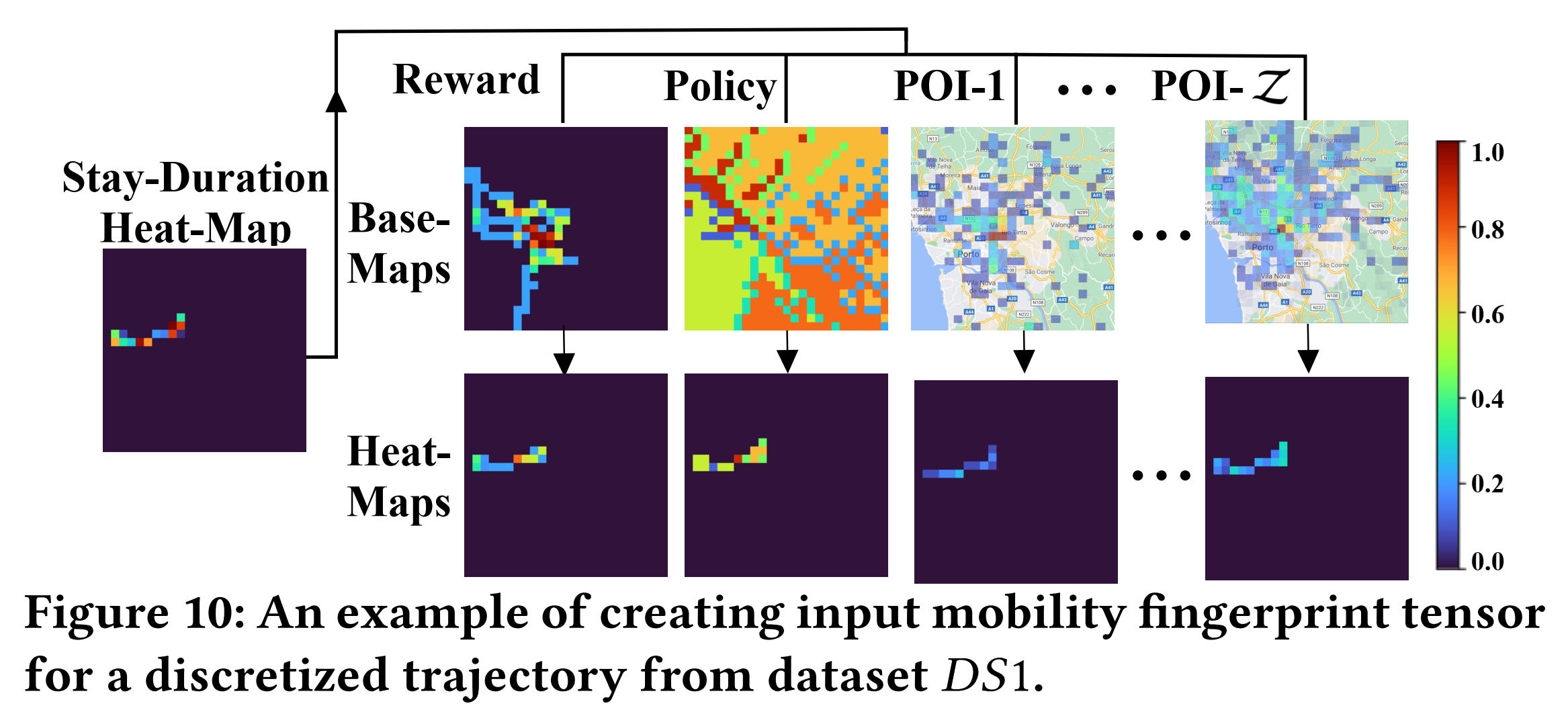
2.4 多分辨率下的轨迹embedding网络
在本研究中,针对每个驾驶员的轨迹,生成3组不同分辨率下的移动性指纹张量,每组有 ( Z + 3 ) (Z+3) (Z+3)个heat-maps,包括驻留时长heat-map,根据reward、policy生成的heat-maps,以及 Z = 11 Z=11 Z=11类POI的heat-maps。然后利用多分辨率轨迹表征网络(MTE-Net),包含三个轨迹encoder network,来生成3中分辨率下的轨迹embedding。

MTE-Net的输入是移动性指纹张量,
f
l
,
j
d
,
t
=
(
ϕ
l
,
j
d
,
t
,
χ
l
,
j
d
,
t
,
ψ
l
,
j
d
,
t
,
o
l
,
j
d
,
t
)
(
l
∈
{
1
,
2
,
3
}
)
f_{l, j}^{d, t}=\left(\phi_{l, j}^{d, t}, \chi_{l, j}^{d, t}, \psi_{l, j}^{d, t}, \mathbf{o}_{l, j}^{d, t}\right)(l \in\{1,2,3\})
fl,jd,t=(ϕl,jd,t,χl,jd,t,ψl,jd,t,ol,jd,t)(l∈{1,2,3})。
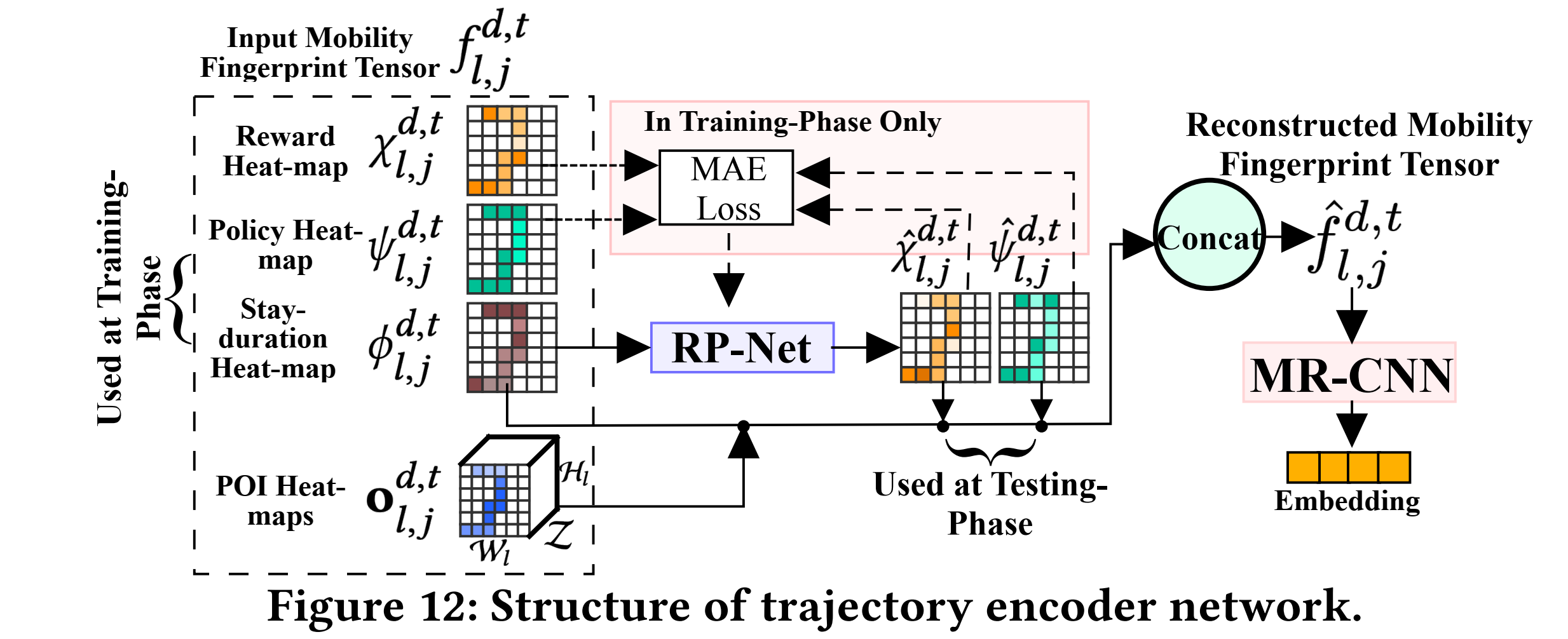
轨迹encoder network将该输入张量转换为轨迹embedding。在训练阶段,基于驻留时长heat-map,利用RP-Net学习重构reward和policy heat-maps;将前述3个heat-maps以及POI相关heat-maps进行拼接,得到重构移动性指纹张量;利用MR-CNN,将该张量生成embedding,用于后续的异常检测和驾驶员分类。
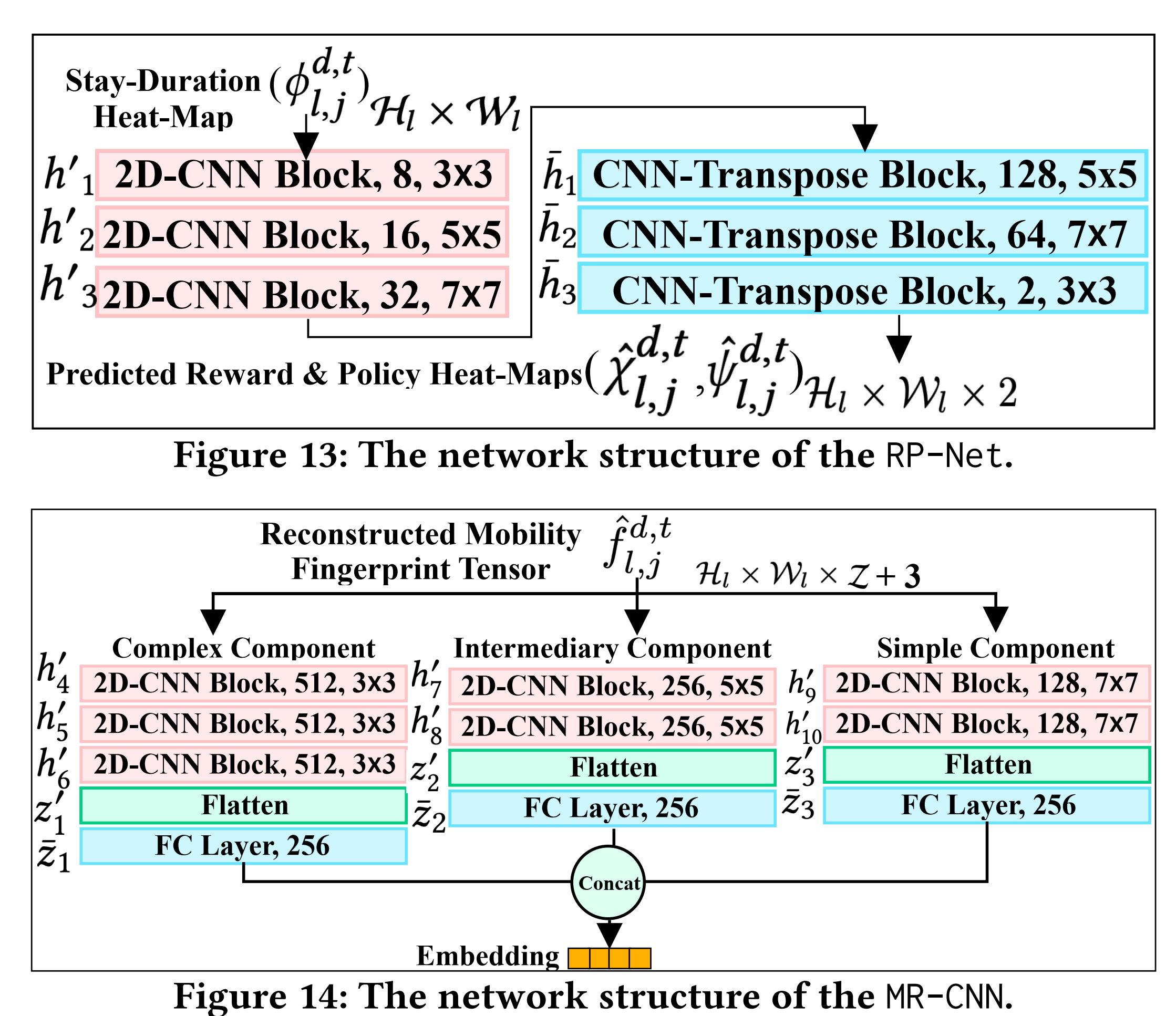
RP-Net的网络结构由2D-CNN和2D-CNN转置块组成。除了2D-CNN块,MR-CNN还包括平坦操作和全连接(FC)层。
最终输出的embedding结果,包含三组分辨率,以及由一个全连接层计算得到的天气特征向量
ω
j
d
,
t
=
Concat
(
E
1
(
f
1
,
j
d
,
t
)
,
E
2
(
f
2
,
j
d
,
t
)
,
E
3
(
f
3
,
j
d
,
t
)
,
ζ
(
c
j
d
,
t
)
)
.
\omega_{j}^{d, t}=\text { Concat }\left(E_{1}\left(f_{1, j}^{d, t}\right), E_{2}\left(f_{2, j}^{d, t}\right), E_{3}\left(f_{3, j}^{d, t}\right), \zeta\left(c_{j}^{d, t}\right)\right).
ωjd,t= Concat (E1(f1,jd,t),E2(f2,jd,t),E3(f3,jd,t),ζ(cjd,t)).
2.5驾驶员识别和异常检测
驾驶员分类:
将最终的embedding向量
ω
j
d
,
t
\omega_{j}^{d, t}
ωjd,t输入具有
D
D
D(驾驶员个数,或类别数)
个神经元的全连接层并后接softmax方程。
异常检测:
利用连体网络来检测给定轨迹是否由特定驾驶员产生。首先使用两个MTE-Net模块,分别对两条轨迹进行embedding,将结果拼接后输入具有两个神经元的全连接层并后接softmax方程,以实现二元分类(异常或正常)。
3. 实验和结果
数据集:
DS1:收集于葡萄牙波尔图市,从2014年到2015年,包含了442辆出租车的1710670条GPS轨迹,GPS采样率为1/15 Hz。从中选择了100名司机,研究了他们的29353条轨迹(每条轨迹平均有29个GPS点)。
DS2:收集于意大利罗马,2014年2月。该数据集包含320辆出租车在30天内的58,589条GPS轨迹,GPS采样率为1/7 Hz。对26278条轨迹(平均每条轨迹161个GPS点)进行数据分析,从这个数据库中选择100个驾驶员的轨迹。
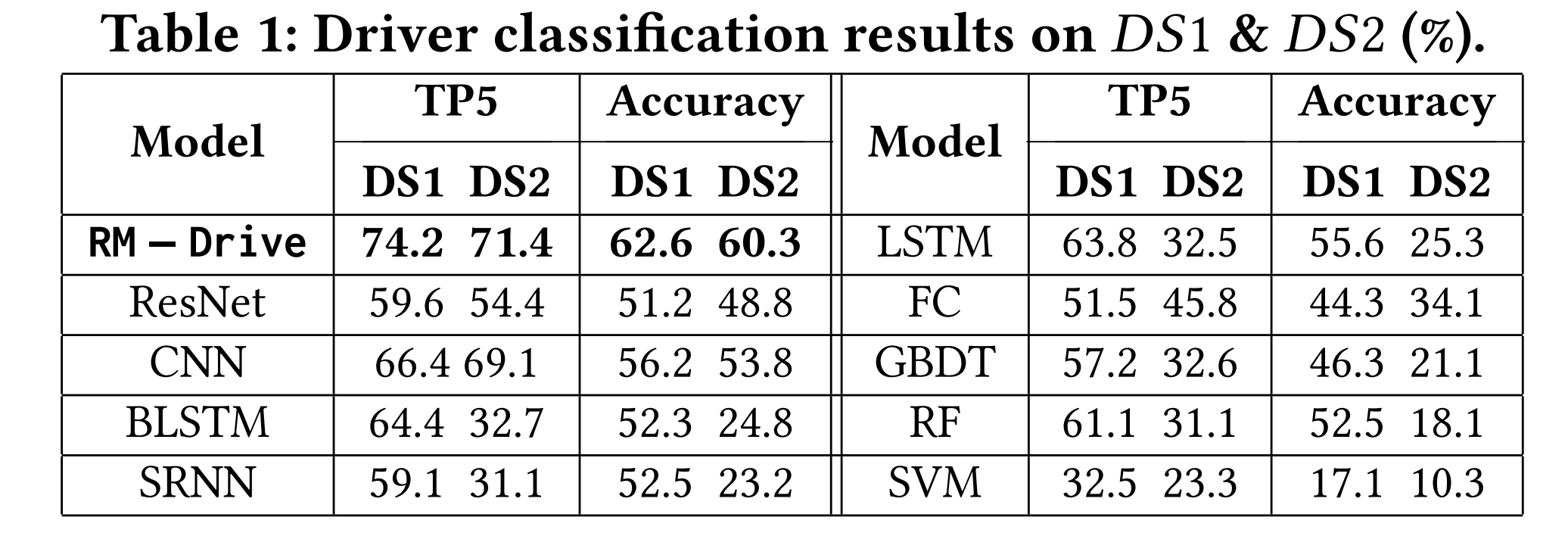
对于驾驶员分类任务,RM-Drive在𝐷𝑆1和𝐷𝑆2数据集上,均优于最精确的baseline(CNN)方法。

异常检测任务中,RM-Drive也比baseline方法的效果更好。实验将异常情况的类标签设置为1。因此,RM-Drive实现的高精度意味着该模型具有较低的假阳性率,并且不经常将正常情况标记为异常。

特征消融试验表明,去除ST-IRL提取的DMF会导致两个显著的性能下降。此外,去除上下文因素也会导致准确性下降,这说明了这些因素对于学习更有特色的DMF的重要性。
此外,去除MR-CNN和多分辨率输入移动性指纹张量导致的性能下降验证了多分辨率模型的重要性,表明输入
具有多种分辨率的DMF张量对于良好的acc是必不可少的。

4. 结论和展望
本研究提出了RM-Drive,使用时空逆强化学习(ST-IRL)提取DMF。其中包含多分辨率轨迹嵌入网络(MTE-Net),集成了多分辨率卷积神经网络(MR-CNN);还考虑了上下文因素(即天气条件和POIs)与驾驶员决策行为模式之间的相关性,以提高预测的准确性。最后在两个大型真实数据集上进行广泛实验,研究证实了RM-Drive用于DMF识别的准确性、效率和适用性。
论文中的研究主要创新在于对轨迹的特征提取和表征方式,特别是根据驾驶员历史轨迹,利用时空逆强化学习获取的reward和policy basemaps。这一特征既结合了问题需求(不同驾驶员的路线偏好特征),又结合了方法本身的特性(根据历史行为反推个体策略),从实验结果上看也是对效果影响最大的特征。如果有需要对个体表征用户画像的场景,可以考虑该方法,但需要数量足够的个体历史数据。此外还有对轨迹的多分辨率表征,以及对天气、POI等上下文信息的融合应用,综合实现了分类和异常检测的性能提升,也有很大的参考价值。
更多内容,敬请关注同名微信公众号:时空大数据兴趣小组。
















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









