





ACM SIGSPATIAL国际地理信息系统大会(ACM SIGSPATIAL 2021)于2021年11月2日至5日在中国北京举行。该会议始于1993年,旨在汇集研究人员、开发人员、用户和实践者基于地理空间数据和知识,促成跨学科的、覆盖地理信息系统方方面面的交流与合作。本届论文涵盖面较为宽泛,分为6个大类,超过40个小类。接下来,我们将进行一个系列的SigSpatial2021-时空主题论文研读。
Vehicle Trajectory Recovery on Road Network Based on Traffic Camera Video Data
1.研究背景
目前,一种用于记录大规模车辆轨迹的系统引起了许多研究人员的关注,由于其在改善车辆管理和监控(图1(a))、车辆流量估计、交通信号控制(图1(b))和城市资源规划方面具有巨大潜力。然而,由于数据壁垒以及设备和环境的限制,车辆轨迹通常无法直接使用。现有的解决方案要么基于人工标注,要么基于低采样率的gps数据进行轨迹恢复,存在成本高、耗时长的问题。此外,gps设备无法收集到对下游任务至关重要的全部流量数据。因此,需要开发一种系统通过易获取的数据自动化地还原全量车辆轨迹。
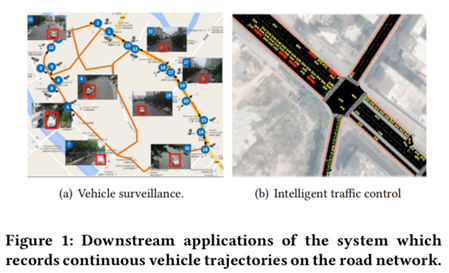
随着发达城市十字路口安装的交通摄像头的普及,可以方便地收集每天的视频或图像数据。利用这些数据来还原路网中的车辆轨迹成为趋势。因此,本文的目标是充分利用交通摄像机采集的大规模视频图像数据来还原车辆轨迹,提升摄像机视频数据的利用率,并开发一个适用于下游任务的系统。
为了实现这一目标,本文在中国某个城市收集了来自673个摄像机覆盖24小时的大规模视频数据,并开发了一个包括视觉模块、时空恢复模块的通用系统。具体来说,基于输入的摄像头视频数据,首先提取视觉特征,根据多模态聚类算法得到车辆聚类结果;然后,根据原始车辆聚类结果得到离散的轨迹点,输入到时空模块中进行路网轨迹还原;最后,将还原的车辆轨迹和聚类结果输送到下游任务中。
然而,轨迹还原问题存在诸多挑战,包括相机不稳定、时空分布不平衡、图像质量问题等。这些问题影响车辆聚类的结果。例如,一个车辆集群可能包含别的车辆记录;同时,一辆车的记录可能分散在不同的集群中。这会降低轨迹还原任务的性能,导致后续的应用程序性能下降。
为了解决上述问题,本文首先分析了问题的本质:基于视觉特征的车辆聚类可以为轨迹还原提供必要的离散点,而还原的轨迹可以将时空约束带回原始车辆集群中。在本文的实践中,初始低采样轨迹是可优化的,因为它依赖于车辆聚类的结果。在此基础上,本文开发的系统的核心部分应用了一个迭代框架,实现了车辆聚类和轨迹还原的协同优化。这里的关键想法是,两个任务可以相互提高彼此的性能。一方面,车辆聚类任务为轨迹还原提供必要的离散点,更准确的聚类结果有助于轨迹还原。另一方面,还原的路网轨迹在时空上有助于修正仅考虑图像视觉信息的初始聚类结果。因此,直观的方法是利用还原的轨迹为车辆聚类去除噪声和提供信息。例如,轨迹级别信息可以排除错误的图像。此外,即使图像没有被相机清晰地捕捉到,还原的轨迹也可以将一些丢失的记录补回到相应的集群中。然后根据更新的聚类再次还原轨迹,重复上述步骤,直到满足要求。将此迭代框架应用于提出的系统,可以提高车辆聚类和轨迹还原的性能。
本文主要贡献可以总结如下:
- 首次利用城市摄像机采集到的视频来还原大规模的车辆轨迹。为了实现这一目标,收集了一个大规模的数据集,涵盖了来自1106个交叉口673个摄像头24小时的视频数据。最重要的是,收集了连续车辆轨迹的真实值;
- 提出了一种在路网上还原车辆轨迹的通用流程,并以迭代框架为核心,将车辆聚类和轨迹还原任务结合起来,通过聚合轨迹中包含的时空信息来提高车辆聚类的性能,最后通过强化车辆聚类得到更精确的轨迹;
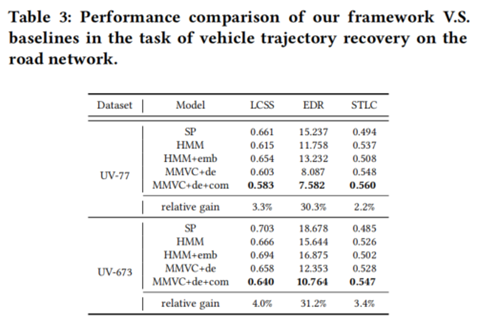
- 在收集的真实世界的数据集上进行实验,证明该框架在聚类任务上f1-score优于基线2.8%,在轨迹还原任务上LCSS优于基线4.0%、STLC优于基线3.4%。该系统已经部署在实际交管项目中。
2.问题定义
- Road Network:Gr(I,Eii) , I是路网节点集合,Eii是边集合,边权重w(ip,iq) 是交叉口之间的地理距离。
- Vehicle camera record:一条记录是一个三元组<r,c,t> , 表示一张记录特定车辆的图片r在t时刻被相机c捕捉到。具体来说,图片r表示从原始视频数据中抽取出的聚焦于某一特定车辆的图像;相机c安装于某一交叉口,可关联到经纬度上。
- Vehicle mobility record:一条记录是一个三元组<v,i,t> , 表示车辆v在t时刻经过交叉口i。
- Vehicle Trajectory:车辆v的轨迹定义为Trv :<v,i1,t1> ,<v,i2,t2>,…,<v,in,tn>。这里的轨迹在道路网上是连续的(连续交叉口),以方便各种下游任务(如交通预测、信号控制等)。
- Target:给定由交通摄像机采集的原始视频数据,然后将其转换为Vehicle camera record:<r1,c1,t1>,<r2,c2,t2>,…,<rN,cN,tN>,N为相机数量。本文目标是还原路网Gr中的连续车辆轨迹Trv :<v,i1,t1> ,<v,i2,t2>,…,<v,in,tn> (交叉口粒度)。
3.系统设计
3.1. 系统概要
系统分成3个主要模块:visual模块, spatial-temporal模块 和 visual-ST模块,如下图所示。
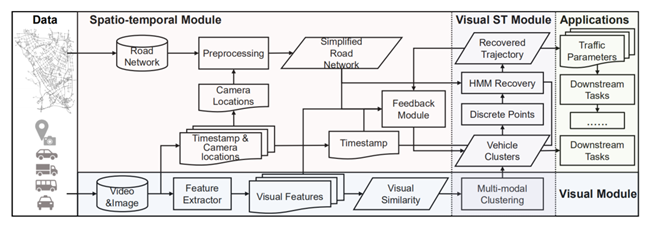
原始输入数据包括路网数据和视频数据。首先,通过OSMnx将输入道路网转换为简单的道路网,覆盖所有摄像头位置和邻近道路交叉口,将空间约束纳入车辆轨迹还原。然后,从视频数据中提取多个视觉特征,并将其输入到多模态聚类模型中,生成初始车辆聚类。利用车辆集群,通过HMM-based的方法来还原道路网络上的轨迹。然后,设计了一个spatial-temporal module,利用还原的轨迹对上游聚类任务进行去噪和数据补充,并将输出再次还原为道路网络上的连续轨迹。最后,系统的输出包括路网中的还原车辆轨迹以及车辆集群,被输入到各种下游应用程序中。
3.2. 车辆聚类模块
- 特征提取
针对摄像机采集到的初始视频数据,首先采用标准模型提取视觉特征,包括车辆特征和车牌特征,以及相应记录的基本时空属性(相机位置和时间戳)。具体来说,通过解析原始视频数据,提取每辆车的图像。车辆图像按时间顺序存储。对于每辆车,通过车辆特征提取模型得到256维的车辆特征向量,通过车牌特征提取模型得到256维的车牌特征向量,车牌文本由车牌OCR模型提取。
- 车辆聚类
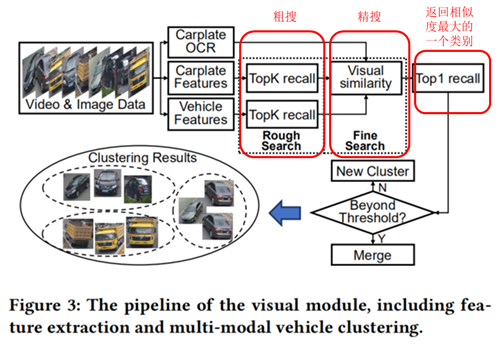
根据从图像中提取的视觉特征聚类属于同一辆车的车辆记录。该聚类算法的输出是根据相应的相似度评分排序的候选图像列表。
首先,根据余弦相似度计算两个车辆的视觉相似度(visual similarity):
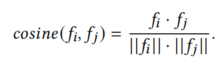
其中fi和fj分别代表两辆车的视觉特征(包括车辆特征和车牌特征)。车牌特征的相似度记为Sg,车辆特征的相似度记为Sf。
Step1:在粗搜阶段,分别搜索具有车辆特征的图像集合和具有车牌特征的图像集合。对于每辆车,选择K个Sg和Sf得分最高的搜索结果,从而得到两组K个元素的集合。接下来,计算这两个集合的并集作为粗略的搜索结果。在粗略的搜索阶段,选择了一个更宽松的K,它被设置为128,这里的目的是召回尽可能多的车辆 [K,2K]。
Step2:在精搜阶段,对于粗搜索集合中的每个元素,首先计算其所在聚类中心的车辆特征、车牌特征以及车牌文本。然后根据图像的视觉特征和元素对应的聚类中心计算多模态联合相似度。聚类中心f的车辆特征计算如下:
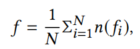
其中N是车辆集群里的车辆数,fi是车辆i的车辆特征,n是L2正则化操作:
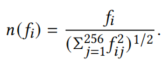
同理,聚类中心g的车牌特征计算为:
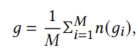
其中M是集群中有车牌的车辆数,gi是车辆i的车牌特征。具体来说,中心车牌是在集群中出现最频繁的车牌。
考虑到车辆定位和图像质量的因素,无法检测到一些车辆的车牌,所以并不是所有的车辆都有车牌特征和车牌文本。如果两辆车都有车牌,成对的车牌文本的编辑距离用D表示。联合视觉相似度S计算式:

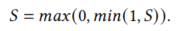
其中SD是编辑距离增益,αf和αg表示相似度权重。
Step3:对于给定图像,在精搜结果中选取联合视觉相似度S最高的类别,判断联合相似度是否大于经验阈值。如果它大于经验阈值,则认为给定图片应该属于该类别。通过上面的步骤,属于一辆车的图片记录会聚集成一个集群。
3.3.轨迹还原模块
车辆聚类是车辆轨迹还原的上游任务,为车辆轨迹还原任务提供了离散点。对于同一集群中的记录,结合路网信息以及附加到车辆摄像机记录上的时间戳来还原车辆轨迹。考虑到实际业务应用对算法精度的要求,这里采用了一种经典有效的匹配算法——HMM。该算法的本质是利用隐马尔可夫模型(HMM)找到路网中最可能的路径,该路径由带时间戳的经纬度对序列表示。
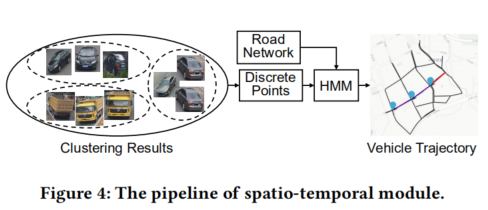
考虑到输出隐藏状态的不连续性,采用最短路算法对路网中不连续的轨迹对进行平滑。
3.4.Visual-ST 模块
现有研究大多直接利用聚类结果和还原的轨迹进行下游任务。然而由于初始车辆集群中存在噪声和缺失点,轨迹还原性能较差,导致下游应用效果不佳。因此,在本文的设计中,visual模块(包括视觉特征提取和聚类)作为spatial-temporal模块的主干,为轨迹还原提供必要的离散点。在此基础上,提出了一个新的迭代框架,即visual-ST 模块,将还原的轨迹的时空约束反馈到初始集群中,使聚类和还原任务协同优化。
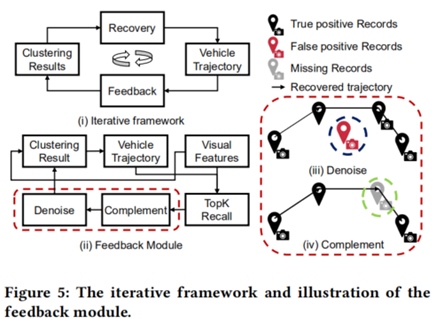
- Complement
实践表明属于同一辆车的记录可能会分散在不同集群中,导致轨迹还原性能不佳。在检查了最初集群中的误判样本后,发现了两种类型误判情况。第一类是孤立集群;第二类是一辆车的记录分散在多个集群中。利用还原后的轨迹来处理孤立集群:
给定有多个记录的车辆集群和对应的路网上已还原的轨迹,找到具有最高视觉相似性的top K集群。然后,通过分别设置空间阈值和时间阈值,来检查孤立集群中的样本是否包含在还原轨迹中,从而合并只有一个记录的孤立集群。
如果选定的top K集群有多个记录,对于每个选定的集群,采用LCSS计算从选定的集群和给定的集群中两个轨迹的相似度。如果相似度大于经验阈值,则合并两个集群。
- Denoise
利用从还原轨迹中获得的时空信息,对一些噪声点进行去噪。每个还原点都可以映射到一个交叉口i,这里的交叉口是与从还原轨迹中选择的给定记录最接近的一个。最后,采用一个经验阈值来删除那些不满足路网空间约束的记录,进行轨迹去噪。
通过反馈模块更新车辆集群,然后再次输入时空模块进行轨迹还原。重复上述过程,直到满足停止迭代要求。
4.实验
4.1. 实验设置
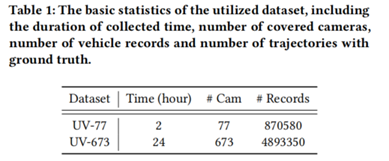
数据描述。本文收集了中国某个城市673台摄像机24小时的视频数据。对于每个通道的视频数据,利用车辆检测和跟踪的方法来获得单摄像机多目标跟踪的结果,即所有经过摄像机的车辆的序列图像。由于数据量大,对于单摄像机的轨迹,只选择了车辆帧最大的车辆图像,并将其保存为一个车辆记录,从而减少了存储量。此外,还记录了每个图像的拍摄时间、相机编号、相机坐标信息。
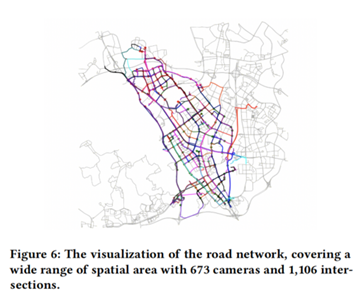
为了证明所提出的框架的稳健性,本文提取了整个数据集的一个子集,包含77个摄像机在2小时内收集的9万辆汽车记录。将整个收集的数据集表示为UrbanVehicle-673(UV-673),子数据集表示为UrbanVehicle-77(UV-77)。这两个数据集的基本统计数据如表1所示。在收集视频数据的当天,要求驾驶员驾驶169辆车尽可能经过673个摄像头,并通过某一应用程序记录车辆的经纬度信息,以评估还原的轨迹。
评价指标。采用在真实序列上的编辑距离(EDR)、最长公共子序列(LCSS)和时空线性组合距离(STLC)进行综合评价。
4.2.结果分析
本文提出的模型在车辆聚类和轨迹还原任务上,在两个数据集上具有更好的性能,这证明了所提出的框架的有效性和鲁棒性。

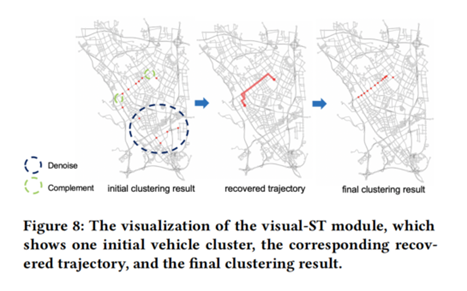
4.3.案例分析
在visual-ST模块中对车辆聚类进行迭代,分别绘制出初始聚类、还原的轨迹和最终聚类结果。如下图所示,在初始集群中有一些缺失的点和噪声记录。通过visual-ST模块,可以召回一些满足时空约束的缺失点,然后在与还原的轨迹进行匹配后,对一些不符合空间约束的点进行去噪。本研究证明了还原的轨迹可以给初始聚类结果带来时空约束,从而实现了以更高的召回率和精度再现车辆聚类的目标。
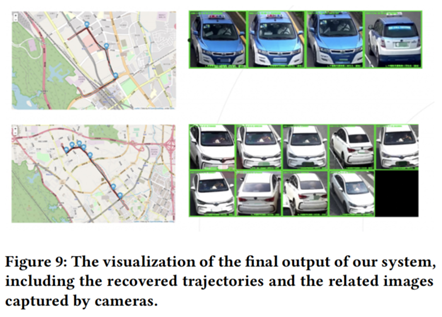
4.4.系统界面展示
本文给出了在道路网络上还原的轨迹和由摄像机捕获的相应图像。这些结果可用于车辆管理和监测。此外,该系统可以根据还原的轨迹计算各种交通参数,包括交叉口之间的平均行驶时间/速度和路网中车流量。这些参数可以输入到下游任务,如拥堵分析、信号控制等。例如,该系统可以检测出交通流量最大的关键路口。然后分别对关键交叉口的关键信号相位向上游或下游延伸,找到由大流量组成的方向。重复这些步骤,直到交通流低于某个饱和阈值。找到关键路口可以帮助交通控制决策。
5.总结与展望
**总结:**本文探讨了从城市摄像机收集的视频/图像数据中还原车辆轨迹的可行性。开发了一个在道路交叉口粒度上还原车辆轨迹的通用系统,其核心是提出了一个新的迭代框架,自动增强车辆聚类和轨迹还原任务。为了实现这一目标,本文收集了一个时空覆盖率高、具有准确真值的数据集。在数据集上进行了广泛的实验,表明该系统框架的性能优于最先进的方法。该系统已经与地方交警合作在项目中落地,可以在道路交叉口水平上输出精确的车辆集群和车辆轨迹,赋能各种下游任务。例如,输出车辆集群主要用于无证车辆和同行车辆的分析。还原后的轨迹可进一步应用于车辆跟踪、流量估计、拥堵分析、交通参数提取、智能信号控制等下游任务。
**展望:**本文探讨了从城市摄像机收集的视频/图像数据中还原车辆轨迹的可行性。开发了一个在道路交叉口粒度上还原车辆轨迹的通用系统,其核心是提出了一个新的迭代框架,自动增强车辆聚类和轨迹还原任务。为了实现这一目标,本文收集了一个时间和空间覆盖率高、具有准确真值的数据集。的数据集上进行了广泛的实验,表明该系统框架的性能优于最先进的方法。
更多内容,敬请关注同名微信公众号:时空大数据兴趣小组。
















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









