







同朴素贝叶斯一样,高斯判别分析(Gaussian discriminant analysismodel, GDA)也是一种生成学习算法,在该模型中,我们假设y给定的情况下,x服从混合正态分布。通过训练确定参数,新样本通过已建立的模型计算出隶属不同类的概率,选取概率最大为样本所属的类。
一、混合正态分布(multivariate normal distribution)
混合正态分布也称混合高斯分布。该分布的期望和协方差为多元的:期望,协方差
,协方差具有对称性和正定性。混合高斯分布:
,它的的概率密度函数为:
其中,为混合高斯分布的期望
,
为其协方差
,
表示协方差的行列式。
下面用图形直观的看一下二维高斯分布的性质:
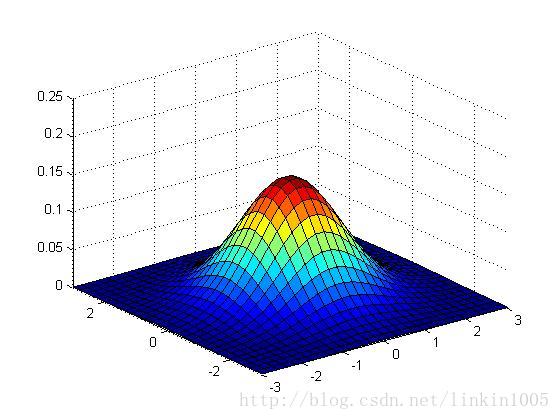
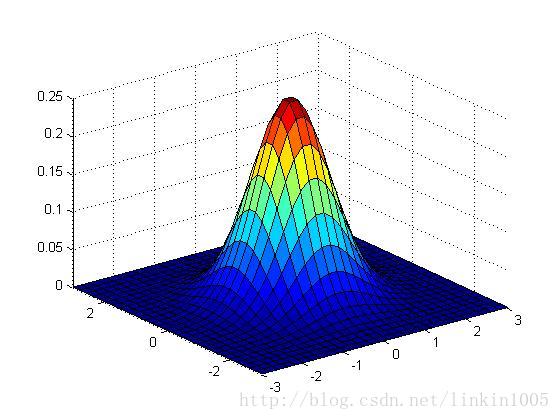
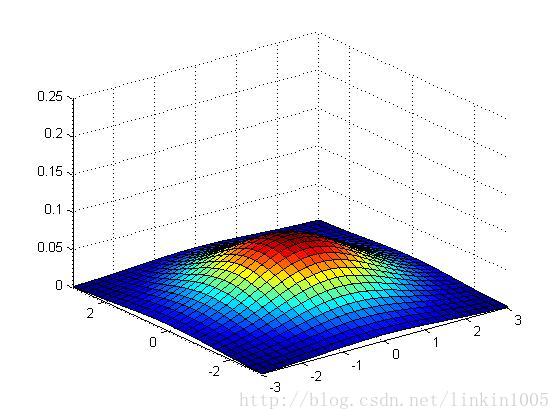
以上三个图形的期望都为:,最左端图形的协方差
,中间的
,最右端的
,我们可以看出:当
变小时,图像变得更加“瘦长”,而当
增大时,图像变得更加“扁平”。
再看看更多的例子:
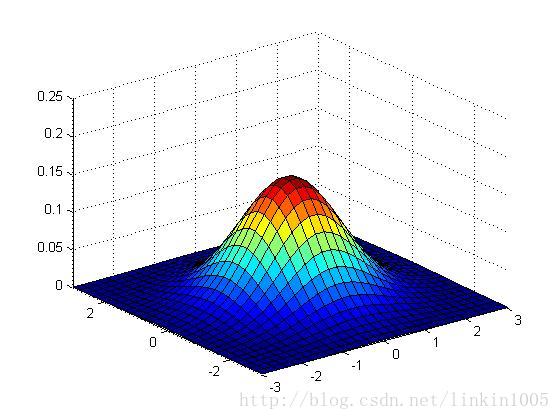
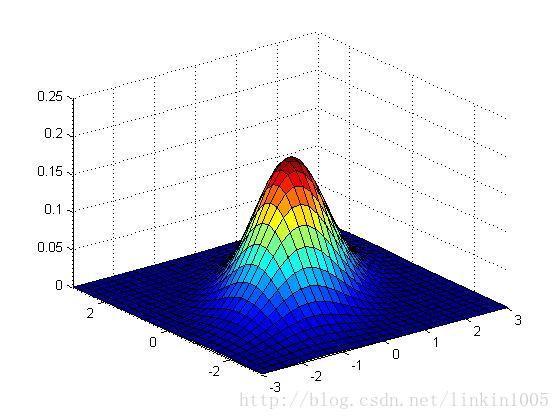
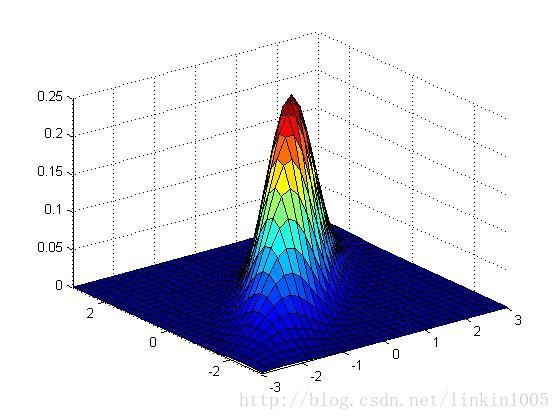
以上三个图形的期望都为:,从左至右三个图形的协方差分别的:
可以看到随着矩阵的逆对角线数值增加,图形延方向,即底部坐标45度角压缩。图形在这个方向更加“扁”。
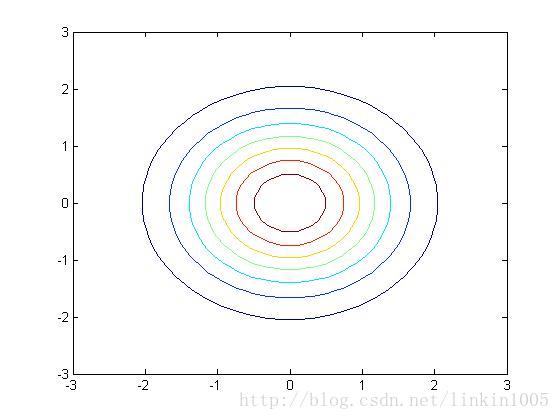
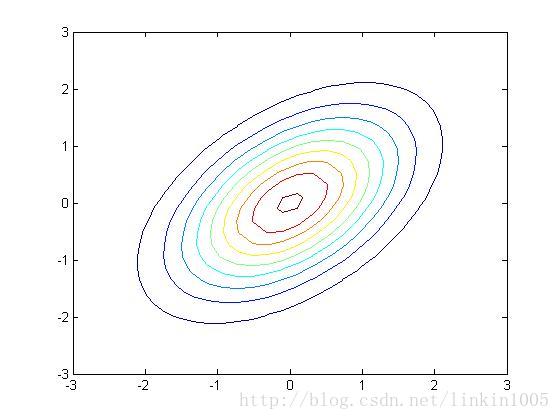
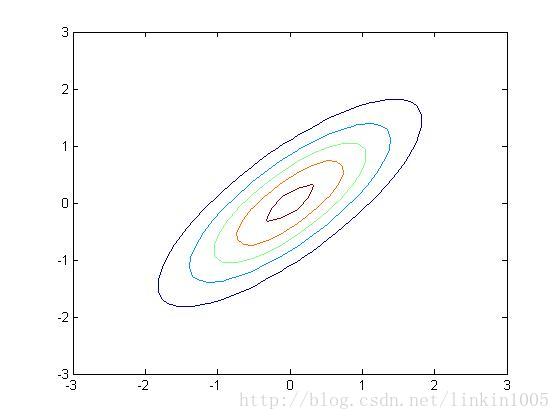
以上三幅图分别是以上图形的等高线,可以更直观的看到调整逆对角线的数值对图像的压缩程度。
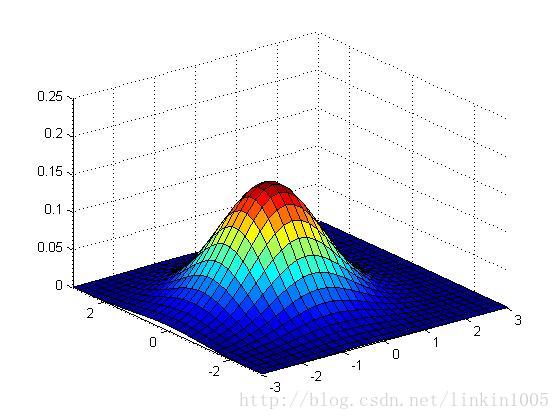
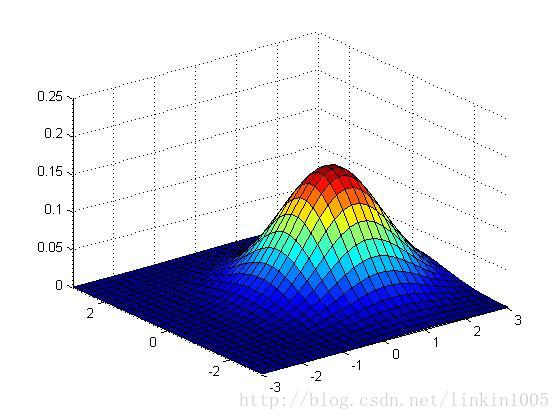
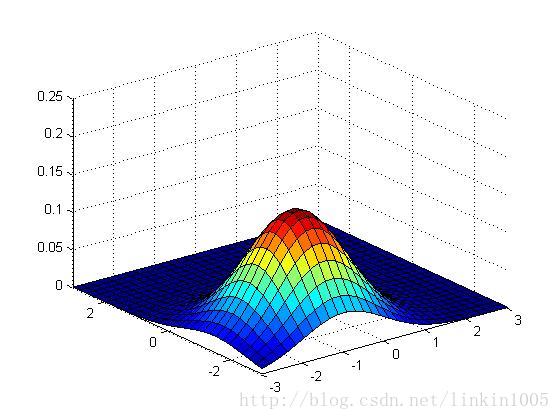
以上三幅图保持协方差不变,期望的值分别为
;
;
可以看出,随着期望的改变,图形在平面上平移,而其他特性保持不变。
二、高斯判别分析模型
如果特征值x是连续的随机变量,我们可以使用高斯判别分析模型完成特征值的分类。为了简化模型,假设特征值为二分类,分类结果服从0-1分布。(如果为多分类,分类结果就服从二项分布)
模型基于这样的假设:
他们的概率(密度)函数分别为:
模型的待估计参数为,通常模型有两个不同的期望,而有一个相同的协方差。
该模型的极大似然对数方程为:
求解该极大似然方程得:
在对计算完成之后,将新的样本x带入进建立好的模型中,计算出
、
,选取概率更大的结果为正确的分类。
三、GDA和logistic回归
GDA模型和logistic回归模型存在这样有趣的关系:假如我们将视作关于x的函数,该函数可以表示成logistic回归形式:
其中,可以用以
为变量的函数表示。
前文中已经提到,如果为混合高斯分布,那么,
就可以表示成logistic回归函数形式;相反,如果可表示成logistic回归函数形式,并不代表
服从混合高斯分布。这意味着GDA比logistic回归需要更加严格的模型假设,当然,如果混合高斯模型的假设是正确的,那么,GDA具有更高的拟合度。基于以上原因,在实践中使用logistic回归比使用GDA更普遍。

















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









