








Qwen3介绍
25年4月29日,阿里推出了最新的Qwen3模型,Qwen3是 Qwen 系列大型语言模型的最新成员,之前部署的还是Qwen2.5。Qwen3旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现均更加优异。另一方面,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能,性能成倍的提升,性能的提升以为这成本和价格的下降,对我们消费者来说都是福利。
下面是官方给出的对比图:
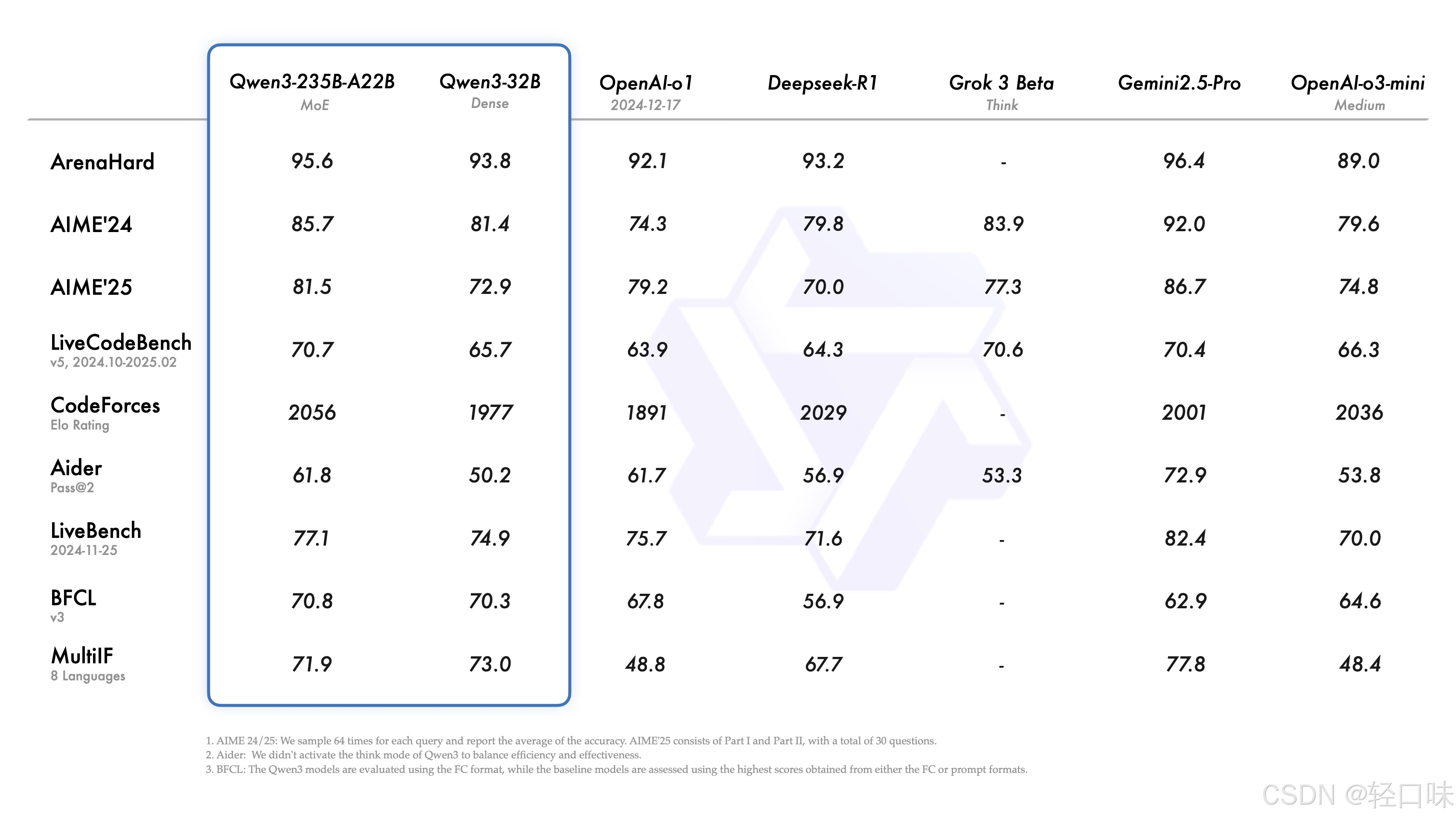
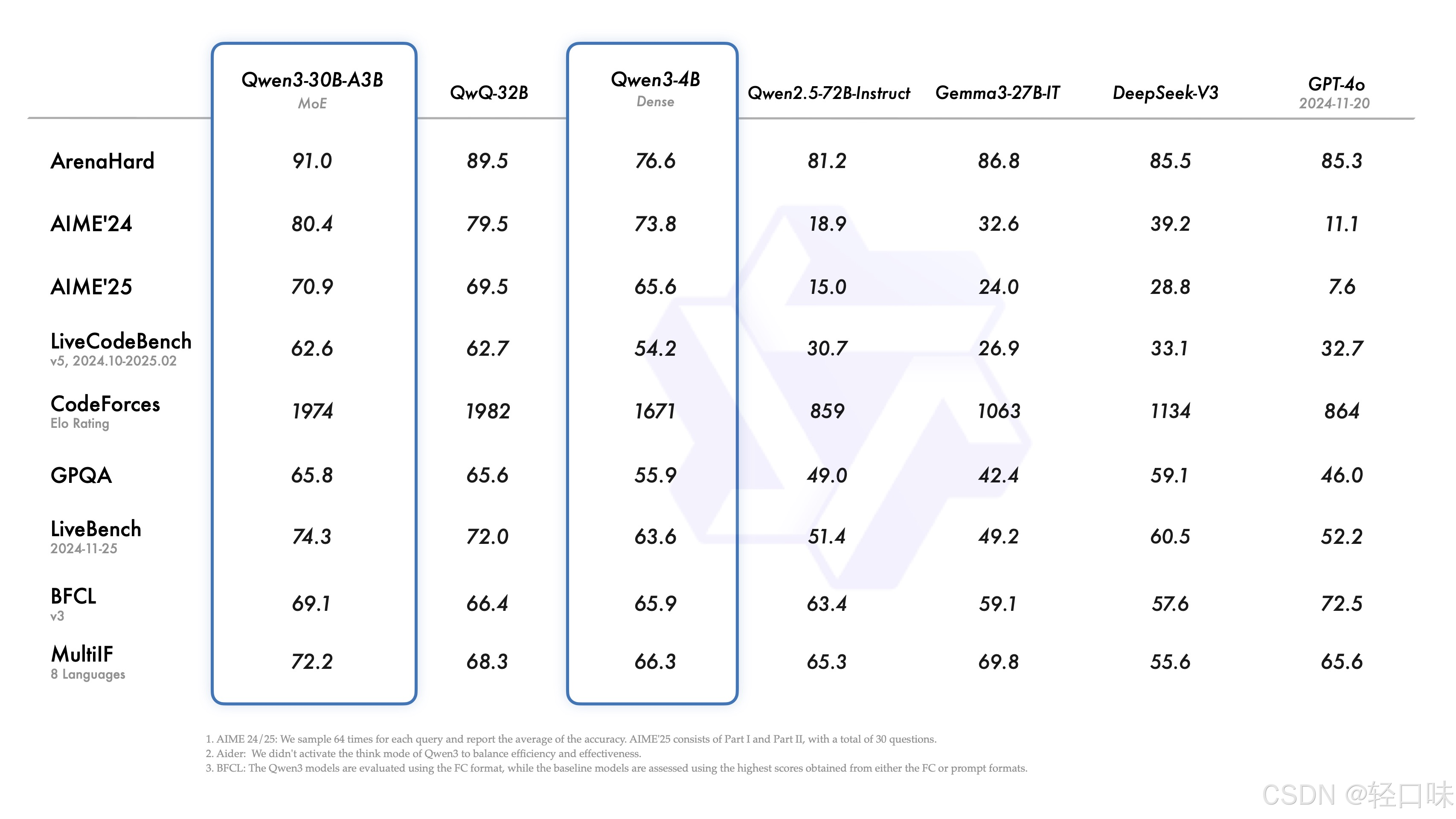
这次Qwen3延续了之前的开源作风,基于Apache 2.0 许可下开源了八个模型,两个 MoE 模型,六个 Dense 模型:
- Moe模型:
- Qwen3-235B-A22B,一个拥有 2350 多亿总参数和 220 多亿激活参数的大模型
- Qwen3-30B-A3B,一个拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型
- Dense模型:
- Qwen3-32B
- Qwen3-14B
- Qwen3-8B
- Qwen3-4B
- Qwen3-1.7B
- Qwen3-0.6B
具体参数信息如下:
| Models | Layers | Heads (Q / KV) | Tie Embedding | Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32K |
| Qwen3-8B | 36 | 32 / 8 | No | 128K |
| Qwen3-14B | 40 | 40 / 8 | No | 128K |
| Qwen3-32B | 64 | 64 / 8 | No | 128K |
| Models | Layers | Heads (Q / KV) | # Experts (Total / Activated) | Context Length |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
Qwen3亮点
多种思考模式
Qwen3 模型支持两种思考模式:
- 思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
- 非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。如上文所述,Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
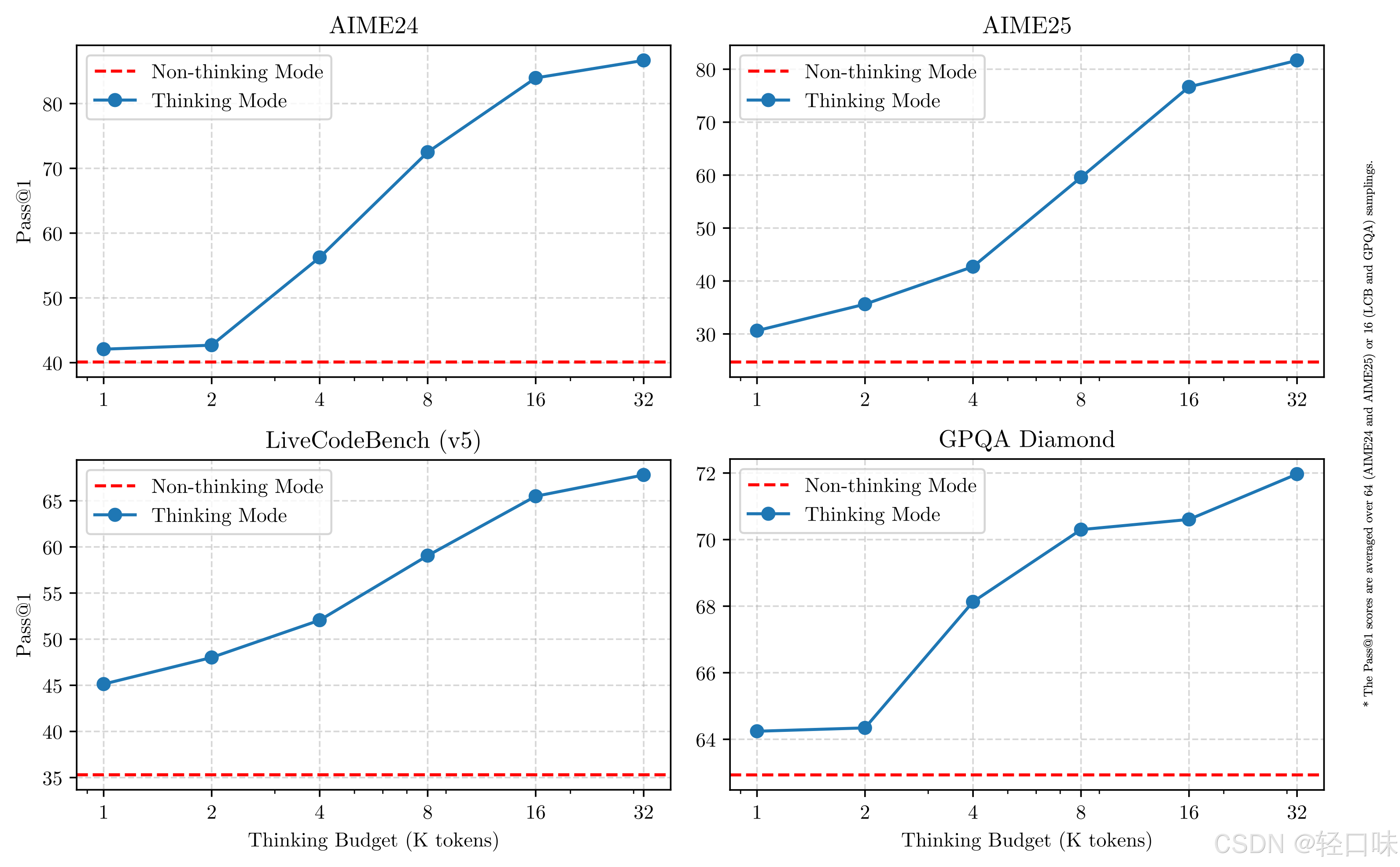
多语言
Qwen3 模型支持 119 种语言和方言。这一广泛的多语言能力为国际应用开辟了新的可能性,让全球用户都能受益于这些模型的强大功能
| 语系 | 语种&方言 |
|---|---|
| 印欧语系 | 英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、挪威语(博克马尔语)、挪威尼诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、西里西亚语、阿斯图里亚语、恰蒂斯加尔语、阿瓦德语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里雅语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁岛语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克语、阿尔巴尼亚语、林堡语、罗马尼亚语、达里语、南非荷兰语、马其顿语僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 |
| 汉藏语系 | 中文(简体中文、繁体中文、粤语)、缅甸语 |
| 亚非语系 | 阿拉伯语(标准语、内志语、黎凡特语、埃及语、摩洛哥语、美索不达米亚语、塔伊兹-阿德尼语、突尼斯语)、希伯来语、马耳他语 |
| 南岛语系 | 印度尼西亚语、马来语、他加禄语、宿务语、爪哇语、巽他语、米南加保语、巴厘岛语、班加语、邦阿西楠语、伊洛科语、瓦雷语(菲律宾) |
| 德拉威语 | 泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 |
| 突厥语系 | 土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 |
| 壮侗语系 | 泰语、老挝语 |
| 乌拉尔语系 | 芬兰语、爱沙尼亚语、匈牙利语 |
| 南亚语系 | 越南语、高棉语 |
| 其他 | 日语、韩语、格鲁吉亚语、巴斯克语、海地语、帕皮阿门托语、卡布维尔迪亚努语、托克皮辛语、斯瓦希里语 |
增强的 Agent 能力
不仅优化了 Qwen3 模型的 Agent 和 代码能力,同时还加强了对 MCP 的支持。
本地部署
官方推荐使用 SGLang 和 vLLM 等框架,而对于本地使用推荐 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 这样的工具。
本文我们以Ollama为例安装Qwen-3 8B模型,并查看效果。
之前安装了Qwen2.5 7B版本模型,电脑配置如下:

下面我们开始安装8B模型,执行ollama run qwen3:8b开始安装:

安装完成看看效果:

输出速度感官上看很优秀。
下面给一篇文章让生成摘要:
给出内容是一篇鸿蒙文档,输出结果如下:

结果也比较满足需求。
再来看看代码能力:
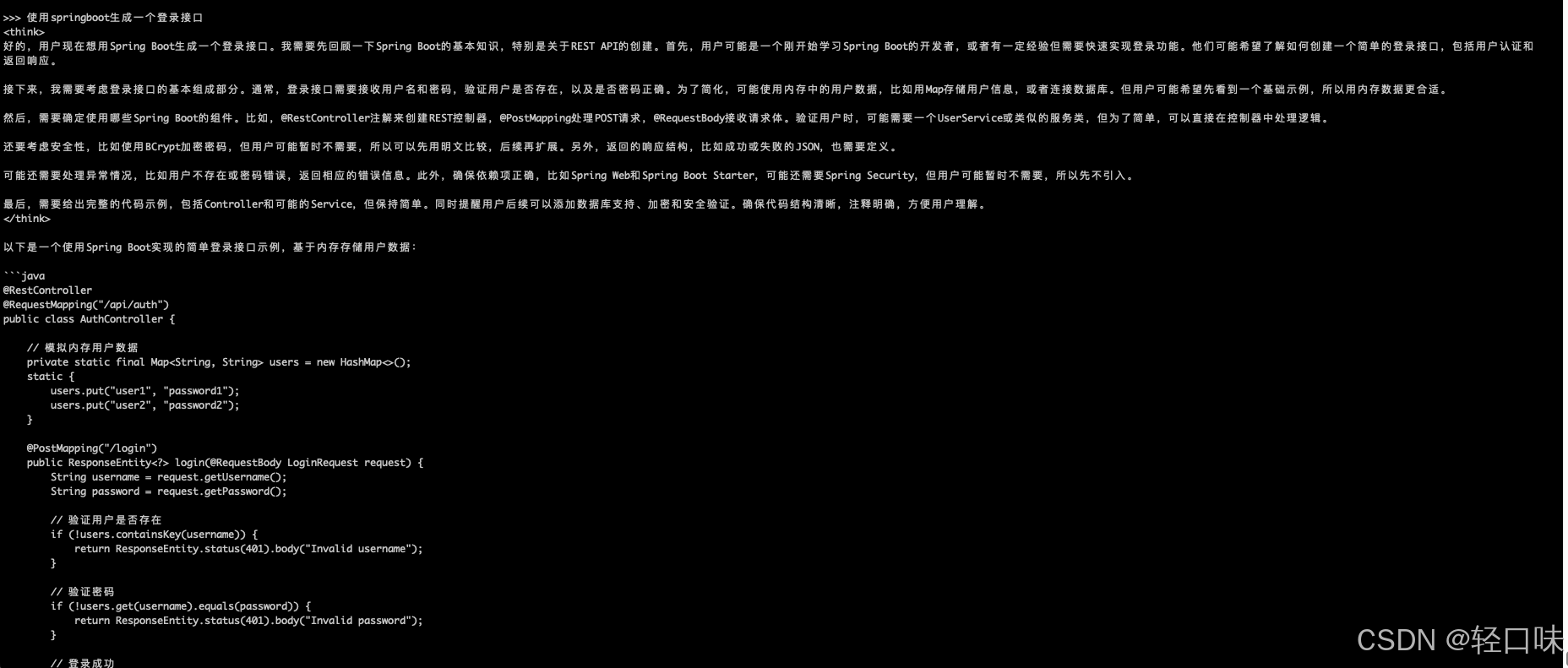
感官效果很不错,把之前本地两个模型先卸载掉:
参考
- 开源地址:https://github.com/QwenLM/Qwen3



















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











