






问题描述:我想通过自己的后端向服务器发送请求,服务器上跑通义千问-14b的int4模型,通过官方github上的OpenAI API格式的本地API部署方法进行部署。
关键代码如下:
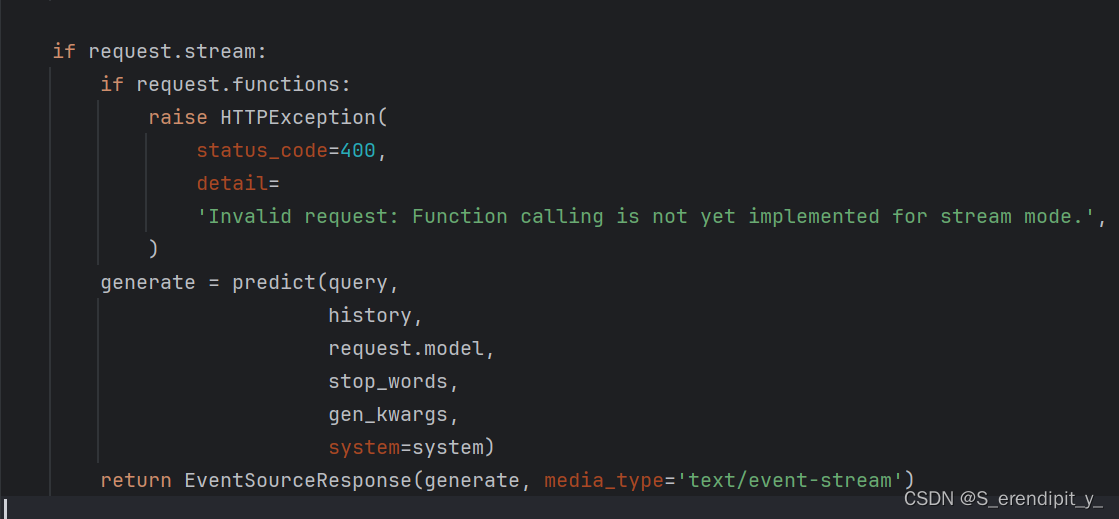
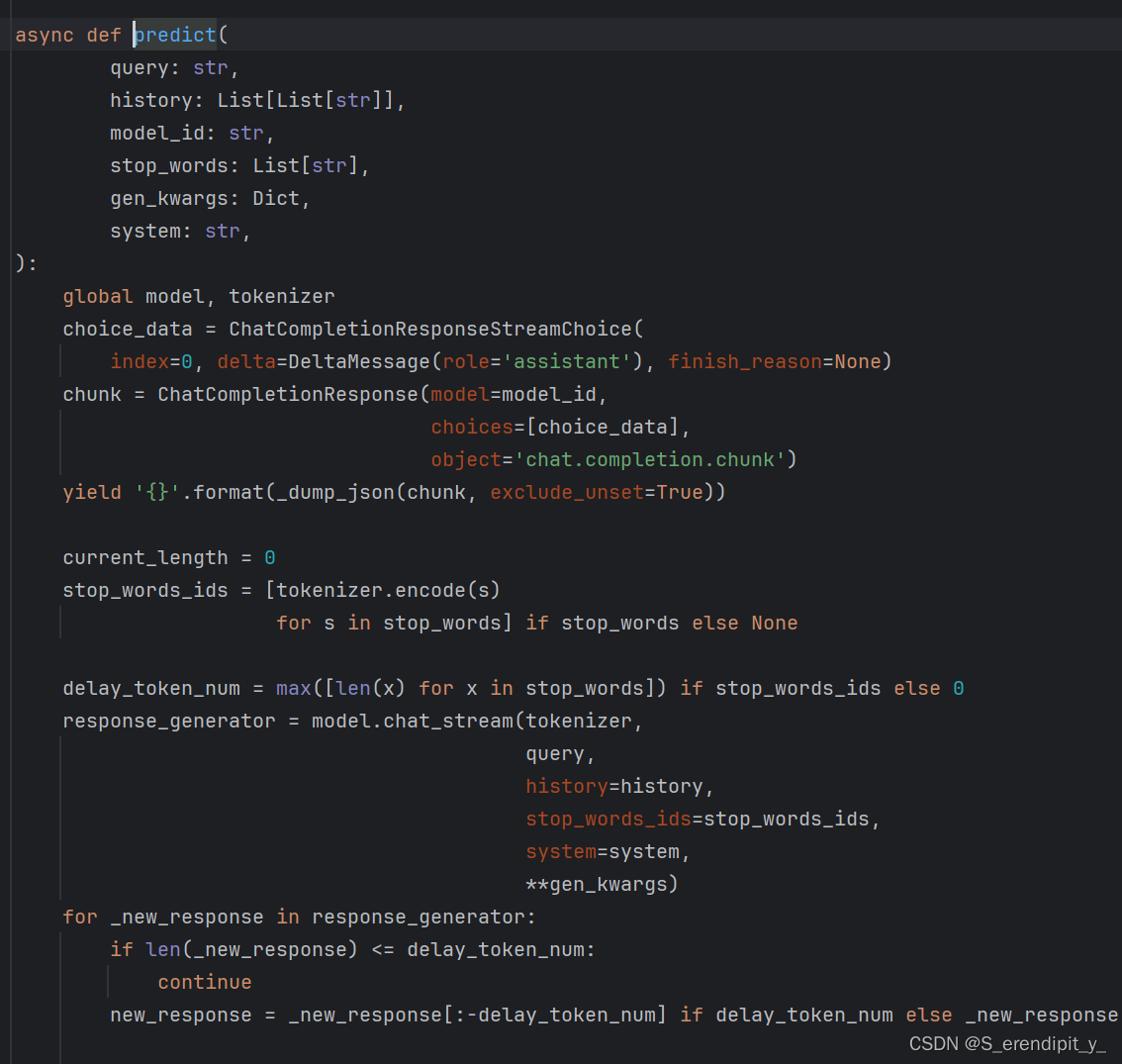
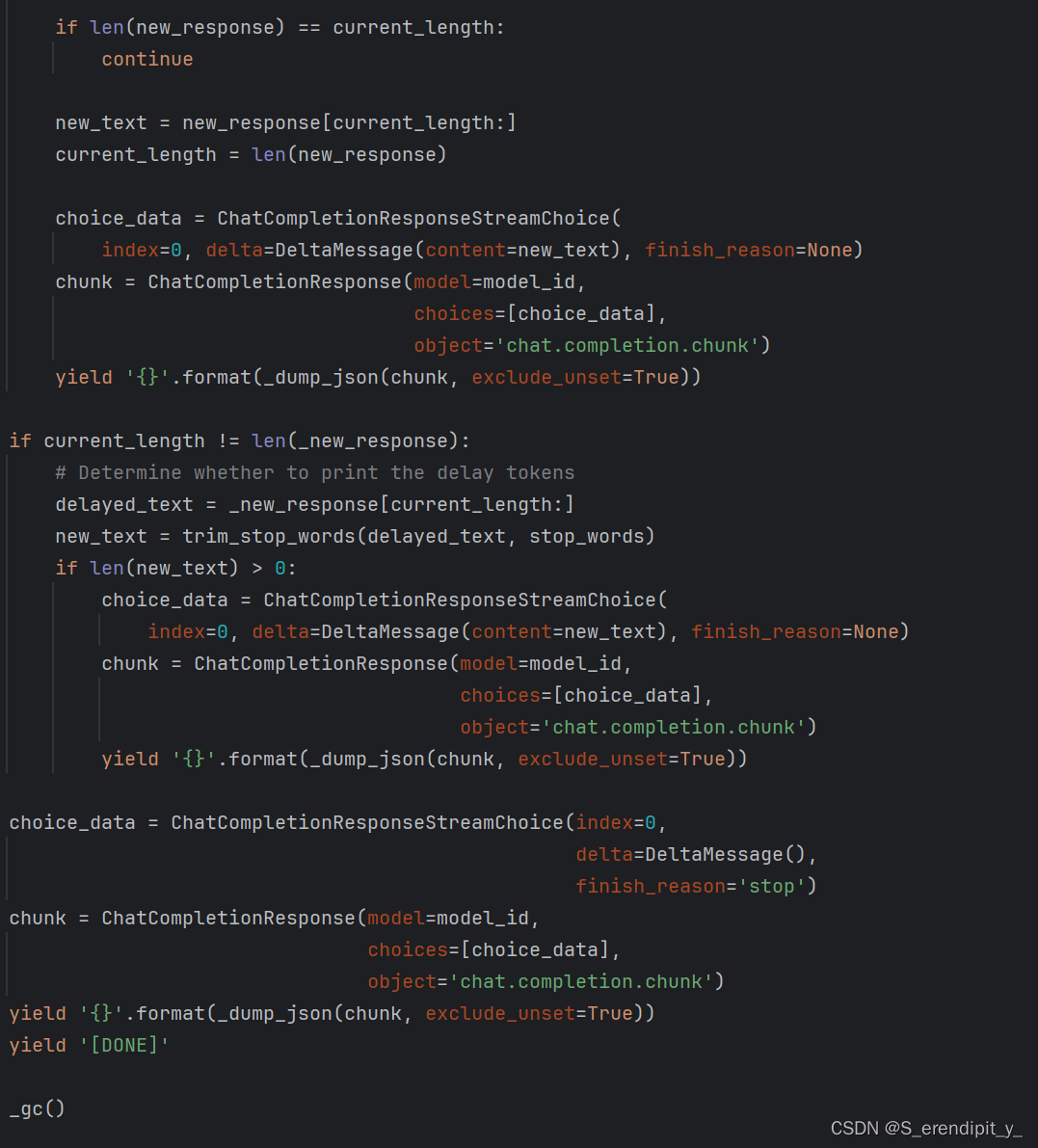
predict代码如下:
本地通过以下代码来使用api
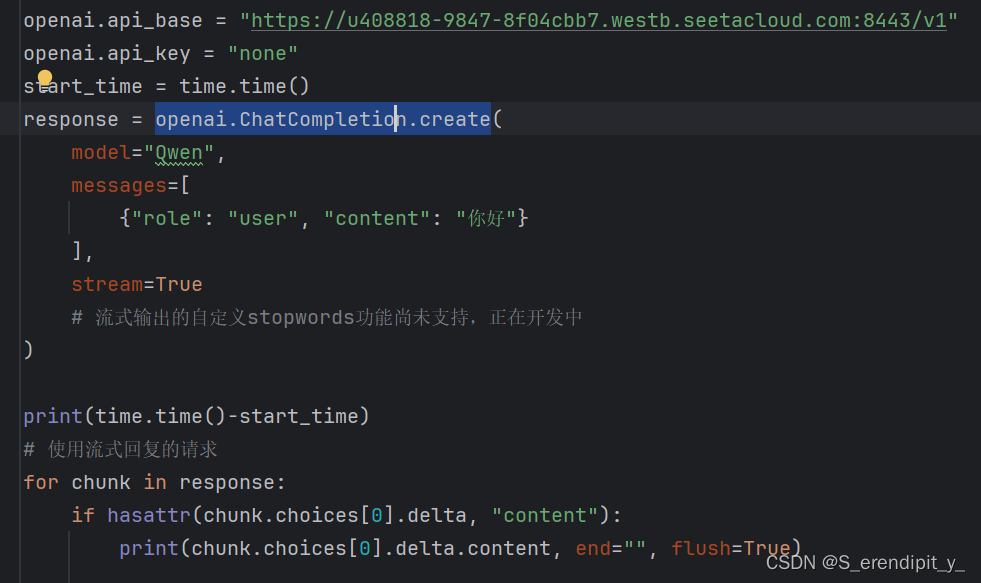
我期望的是后端可以分段的接收到服务器的回答,但是实际运行并不是这样,虽然回答被分段,但是所有的回答几乎同一时间抵达后端,我对服务器和后端都进行了调试,只发现服务器的yield这里确实是流式输出的,其他地方都没发现问题。
如果您也遇到了这方面的问题并且有解决问题的思路,请您加我的联系方式qq:1764704854,希望前辈们不吝赐教。我对问题如果有描述不清楚的地方,也请加我的联系方式我可以进一步讨论















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









