






1. 如何使用DeepSeek
1.1 关键原则
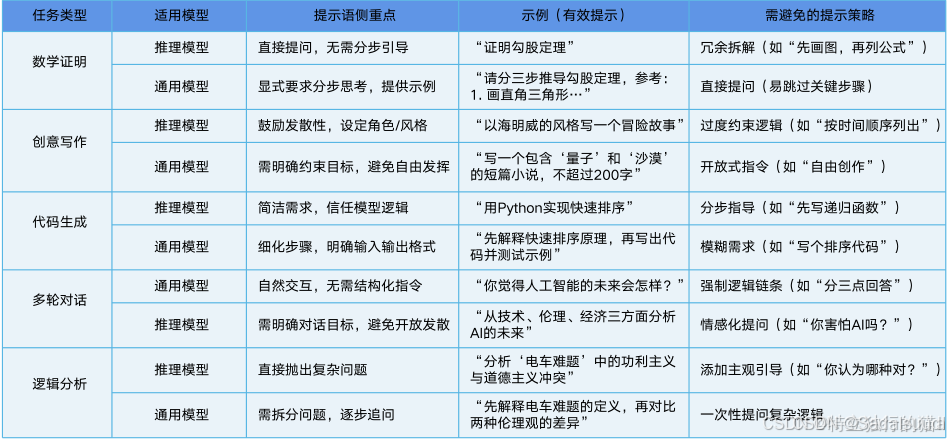
- 模型选择:根据任务类型选择合适的模型(表格为举例,推理模型即R1,通用模型即不选择深度思考的V3模型)

1.2 提示词设计
- 推理模型:简洁指令,聚焦目标,不需要结构性的提示词,让模型自己推理思考。
- 通用模型:结构化、补偿性引导,需要分步进行并提供具体实例。

- CoT(思维链)拓展
- 简单解释:指令+逻辑依据+示例;
- 指令:用于描述问题并告知大模型输出格式;
- 逻辑依据:即中间推理过程,可以包含问题的解决方案、推理步骤以及与问题相关的任何外部知识。
- 示例:以少量样本的方式为大模型提供输入输出的基本格式,每一个示例都包含:问题、推理过程与答案。
- 说人话版:记得R1的思考过程吗?使用通用模型的时候把这样的思考过程告诉AI,然后丢几个范例给它看,让它按照范例格式生成你需要的新的主题内容。
- 部分提示词策略示例
- 官方文档:Prompt Library | DeepSeek API Docs
2. 高效提示词原则
2.1 三大原则
- 清晰性:首要原则,明确任务目标;
- 结构化:分步骤与逻辑层次,通过将任务分解为多个子任务,通过逐步完成步骤最终实现整体目标;
- 上下文控制:限定范围与角色,通过多次生成打磨出更符合预期的输出。
2.2 清晰性:明确任务目标
2.2.1 什么是清晰性?
- 明确的任务描述:明确指出需要完成的任务是什么;
- 具体的要求:包含具体的任务要求,如格式、内容、长度等;
- 避免歧义:避免使用模糊或有多重含义的词汇,确保模型不会产生误解。
2.2.2 如何实现?
- 明确任务目标:例如,任务是生成一篇短视频文案,提示词应明确指出主题、长度、风格等要求。
- 具体化要求:例如,任务是生成一个短视频脚本,需要时长为2分钟,则提示词应明确限定视频的时长要求。
- 避免模糊词汇:例如,避免使用“可能”、“大概”等词汇。
2.2.3 案例举例
案例1:模糊提示词
生成一个关于美食的短视频脚本分析:过于模糊的任务目标,基本无法生成符合预期的内容 。
案例2:清晰提示词
生成一个关于美食的短视频脚本,主题为“擂椒拌饭”,
要求时长2分钟,开头要有钩子吸引客户,内容有梗、有网感,结尾有金句并能让人印象深刻。分析:我瞎写的,建议你自己根据原理来写(bushi)
2.3 结构化:分步骤与逻辑层次
2.3.1 什么是结构化?
- 任务分解:将复杂任务分解为多个子任务。
- 逻辑层次:按照逻辑层次组织子任务,确保每个步骤都有明确的输入和输出。
- 逐步完成:模型能够逐步完成每个子任务,最终实现整体目标。
2.3.2 如何实现?
- 任务分解:例如,任务是生成一篇关于美食的短视频脚本,可以将任务分解为生成标题、生成主体、生成结尾等子任务。
- 逻辑层次:例如,先根据主题生成主体,根据主体生成互动性结尾,最后根据主体和结尾生成创意性标题
2.3.3 案例举例
1. 生成一个主题是“擂椒拌饭”的短视频脚本的主体部分,时长为90秒。
2. 根据主体部分生成互动性结尾,吸引顾客留存,时长为30秒。
3. 根据主体部分和结尾生成标题,要求具有创意性和幽默感,字数不超过15字。分析:想吃擂椒拌饭了(bushi),举例都是我瞎写的哈
2.4 上下文控制:限定范围与角色
2.4.1 什么是上下文控制?
- 限定范围:明确任务的范围,确保模型生成的内容在指定范围内。
- 限定角色:明确模型的角色,确保模型生成的输出符合角色要求。
- 一致性:确保模型生成的内容与任务背景和限制一致。
2.4.2 如何实现?
- 限定范围:例如,任务是生成一篇关于美食的短视频脚本,可以限定脚本的主题为“擂椒拌饭外卖商家的宣传短视频脚本”。
- 限定角色:例如,如果模型的角色是“资深短视频运营剪辑师”,生成内容将更贴合要求。
2.4.3 案例举例(是的我又要乱编了)
1. 你是热门短视频脚本撰写专家,你有很多创意,掌握各种网络流行梗blabla
2. 这是你输出的脚本需要遵循的格式(喂范例)
3. 生成一个主题为“擂椒拌饭真好吃”的外卖商家的宣传短视频脚本主体部分,要求xxx,时长xx秒
4. 生成脚本的结尾部分,要求xxx,时长xx秒
5. 根据主体和结尾生成5个爆款标题,并说明技巧
6. 模型生成脚本后,进行多次优化修改,例如:优化一下主体部分,看看怎么更吸引人
3. 常见陷阱
- 缺乏迭代:过度复杂的初始化提示语、忽视对模型输出的分析和反馈。
- 过度指令与模糊指令:提示语过于长或过于简短、意图不明确。
- 应对策略:
- 从基础提示语开始,逐步添加细节和要求;
- 明确要求优先级,突出重要关键点;
- 要求模型对输出内容进行自我评估,并提供改进建议;
- 多轮对话。

















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









