







目标检测 One Stage Detection (Yolo系列上)
- 在CNN出现之后,人工智能的研究被推向了高潮,其中图片分类和目标检测也飞速发展。在目标检测领域,首先兴起的是以RCNN系列为代表的两阶段检测(Two Stage Detection)方法。最初的RCNN其实是传统计算机视觉算法和深度学习的结合。它首先用传统的select search算法提取2000个左右的特征图像块(region proposel),之后用CNN提取到图像特征,最后用包含(支持向量机)SVM分类器和目标选框回归(bbox regression)的功能头进行分类和回归操作。然而它在检测的时候速度太慢,很难用在实时的目标检测和比较低端的硬件上。虽然之后Fast-RCNN和Faster-RCNN对模型推理速度和精度进行了优化,但是推理速度依然有很大提升空间。
- 天下武功为快不破,横空出世yolo网络以它惊人的检测速度成为了目标检测领域的一颗明珠,也开启了一阶段目标检测(One Stage Detection)的时代。快速的目标检测能够使得检测系统在安防,无人驾驶,公共场所秩序的管理维护等方面落地成为可能。
YoloV1:
- YoloV1为今后的Yolo模型定下了基础,之后的模型都是在YoloV1总思想的指导下进行调整的。
总流程:
-
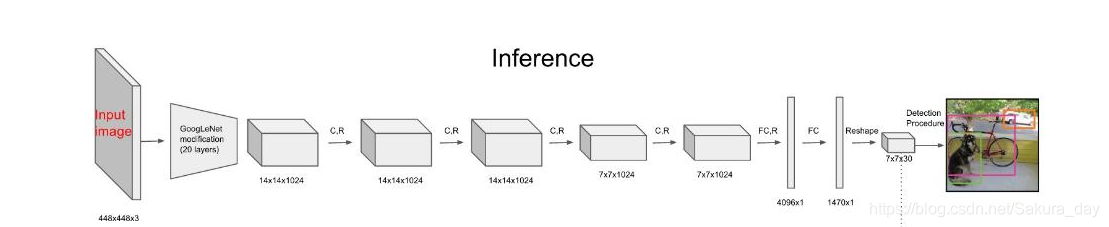
首先将448 * 448的图片输入到darknet的backbone中,得到size是7*7的特征图。这个特征图和原图的映射关系和RCNN系列是一样的。在预测的时候,一旦一个物体的中心点落到了某个格子之中,那么这个格子就负责这个物体的检测。
-
当物体中心在网格上呢?就直接左开右闭处理。如果有两个物体中心都落在一个格子里面呢?就把置信度高的BBox挑选出来,总之只能预测一个物体。
-
网络预测的参数有 :
BBox:x,y,w,h(center)还有置信度:Confidence: P r ( P_{r}( Pr( object ) ⋅ ) \cdot )⋅ IoU pred truth _{\text {pred }}^{\text {truth }} pred truth ,得到的output维度是 S × S × ( 5 ∗ B + C ) \mathrm{S} \times \mathrm{S} \times(5 * \mathrm{~B}+\mathrm{C}) S×S×(5∗ B+C) 对于论文也就是 [ 7 × 7 × ( 5 ∗ 2 + 20 ) ] − > v 1 [7 \times 7 \times(5 * 2+20)]->\mathrm{v} 1 [7×7×(5∗2+20)]−>v1
B指代有2个bbox,20指代一共有20中类别。
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OuuxPyYY-1617810573625)(目标检测 One Stage Detection(Yolo 系列).assets/image-20210407215226186.png)]](https://i-blog.csdnimg.cn/blog_migrate/d3cc857a867f497ca6dcbe1ff27f5150.png)
损失函数:
-
要进行检测选框回归就必然要有损失函数,yolov1的损失函数比较复杂。但是可以大致分成三个部分,总之可以分成三部分bbox回归/置信度回归/分类的回归。通过这个复杂的损失函数,网络就可以通过梯度下降法更新参数进而学习。
-
YoloV1 的损失函数:
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1nYhYZDS-1617810573628)(目标检测 One Stage Detection(Yolo 系列).assets/image-20210407215936120.png)]](https://i-blog.csdnimg.cn/blog_migrate/56bc41d7751820577f4b89722c12845b.png)
-
2.1部分是BBox回归的Loss函数,其中我们可以看到,作者在w和h的损失函数上加了根号,这是为了使得大物体的loss不要太大,否则小物体的特征无法被训练。加了 λ coord \lambda_{\text {coord }} λcoord 使得网络中正样本损失大一些,因为正样本的个数远小于负样本个数。
-
公式2.2部分是置信度的损失函数,其中 I i j obj \mathbb{I}_{i j}^{\text {obj }} Iijobj 表示是物体的蒙版, I i j noobj \mathbb{I}_{i j}^{\text {noobj }} Iijnoobj 表示不是物体的蒙版,他们在各个数值上是完全相反的。 λ noobi \lambda_{\text {noobi }} λnoobi 平衡不均匀正负样本的参数。 C ^ i : \widehat{C}_{i}: C i: 是预测的BBox和标签的IOU 乘以真实的物体的模板。 C i C_{i} Ci :网络生成的BBox和标签的IOU乘以网络生成的物体的模板。
-
2.3是对正样本分类置信度损失的计算。每一个小格子只能预测一个物体,预测出的物体由有大的IOU的bbox决定。最终要进行NMS把没有用的选框给清除了
YoloV2:
-
YoloV1最大的优点就是快,但是太快就没有什么感觉,会忽视一些东西。比如说:
- YoloV1对密集物体的检测效果不好,因为一张图片到顶就预测49个物体。
- 对小物体不友好这是肯定的。毕竟损失函数这么复杂有这么粗糙。
- 对不同长宽比的物体预测不太好,毕竟这是无意识的anchor free网络吧
- 没有BN层,原来的作者真的厉害,怎么训练的网络都不知道
-
YoloV2努力实现又快又好又有感觉:首先的改进就是加了BN层,使得网络更好训练,表现得更好
-
然后再Backbone训练的时候也用了一些trick,比如说,先再224X224的Image网络上训练,然后继续在448X448的ImageNet上finetune,这样在输入大图片的时候检测的效果会好很多
-
最后在在真实的目标检测dataset上进行微调,最后得到13x13的feature map。
Reorg网络层:
-
在介绍这个层之前,我们要知道层数比较低的卷积核得到的是空间,颜色,纹理,边缘等信息,层数比较深的卷积核得到的是抽象的语义信息。
-
如何把两种信息结合起来,使得深层网络在进行目标检测的时候不会丢失位置信息呢?作者想到了把浅层feature map和深层feature map拼接起来的方法。然而深层feature map的size毕竟还是比较小的,如何contact呢?作者就把浅层的feature map进行一定的拆分:
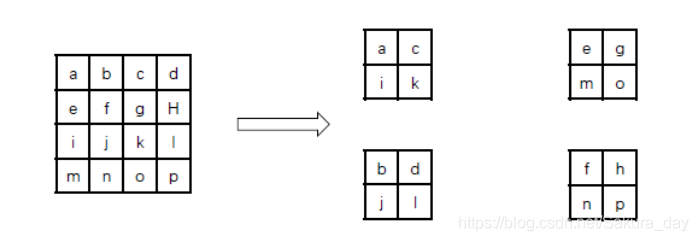
-
拆分的过程如上图所示,经过这样的拆分就可以成功的和深层的feature map拼接起来了。
多尺度训练:
- 为了使得网络能够输入不同大小的图片,作者把FC层给取出了,这样就可以接受各种size的图片,然后使得模型更有鲁棒性。
Anchor:
- Yolo和Faster RCNN也是你抄我我抄你,不抄白不抄。Yolo的Anchor是用label进行Kmeans计算出来的,一共有五个。中心点数值有10个。不过anchor也还是有一些缺点,就是要根据不同数据集设计不同anchor,计算比较复杂。
- 比如Anchors: 0.57273, 0.677385, …, 9.77052, 9.16828 [10 numbers]
- 分别代表是 a w 0 , a h 0 , … , a w 4 , a h 4 a_{w_{0}}, \quad a_{h_{0}} \quad, \ldots, \quad a_{w_{4}}, \quad a_{h_{4}} aw0,ah0,…,aw4,ah4 十个数字。
- anchors [ 0 ] = a w i = a w ori W ∗ 13 [0]=a_{w_{i}}=\frac{a_{w_{\text {ori }}}}{W} * 13 [0]=awi=Wawori ∗13 ,就是对格子进行一定的归一化,然后乘以格子数目
- anchor改变了,那么真实的BBox也要跟着改变,也要相对于图像的长宽进行归一化,然后乘以13.使得真实的BBox范围也在0-13之间,方便网络进行训练。
- final box: [ x f , y f , w f , h f ] ∈ [ 0 , 1 ] \left[x_{f}, y_{f}, w_{f}, h_{f}\right] \in[0,1] [xf,yf,wf,hf]∈[0,1]
- x f = x − i x_{f}=x-i xf=x−i 这样就可以确定中心点在哪个个格子里面了
- y f = y − j y_{f}=y-j yf=y−j
-
w
f
=
log
(
w
/
w_{f}=\log (w /
wf=log(w/ anchors [0])
h f = log ( h / h_{f}=\log (h / hf=log(h/ anchors [1] ) ) )
# 伪代码:
box_xy =sigmoid (feats..., 2)
box_wh=k.exp(feats[...2: 4])
box_confidence =K.simoid(feats[..., 4: 5])
box_class_probs =K.softmax(feats[..., 5:])
#Adjust preditions to each spatial grid point and anchor size.
#Note: YOLO iterates over height index before width index.
box_xy =(box_xy + conv_index) / conv_dims
box_wh = box_wh * anchors_tensor / conv_dims
- 一共输出25个feature,其中有x,y,w,h+置信度,一共五个anchor。
- 当然YoloV2还是有一些问题,就是它对于小物体检测还是不太行,虽然精确率高了些。
损失函数:
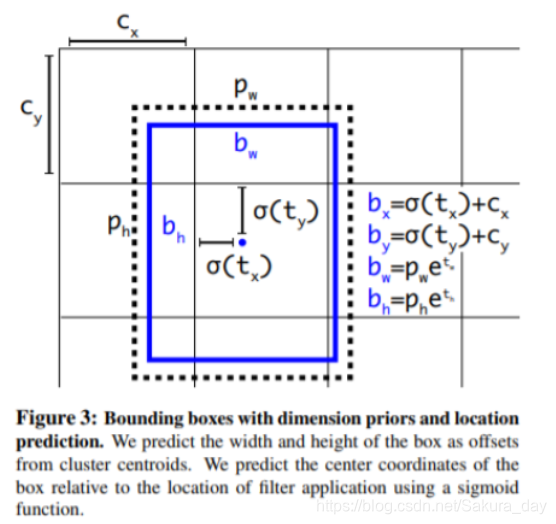
{ σ ( t x p ) = b x − C x , σ ( t y p ) = b x − C x t w p = log ( b w p w ) , t h p = log ( b h p h ) t x g = g x − g x . f l o o r ( 0 , t y g = g y − g y . f l o o r 0 t w g = log ( g w p w ) , t h g = log ( g h p h ) \left\{\begin{array}{c}\sigma\left(t_{x}^{p}\right)=b_{x}-C_{x}, \sigma\left(t_{y}^{p}\right)=b_{x}-C_{x} \\ t_{w}^{p}=\log \left(\frac{b_{w}}{p_{w}}\right), t_{h}^{p}=\log \left(\frac{b_{h}}{p_{h}}\right) \\ t_{x}^{g}=g_{x}-g_{x . f l o o r}\left(0, t_{y}^{g}=g_{y}-g_{y . f l o o r} 0\right. \\ t_{w}^{g}=\log \left(\frac{g_{w}}{p_{w}}\right), t_{h}^{g}=\log \left(\frac{g_{h}}{p_{h}}\right)\end{array}\right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧σ(txp)=bx−Cx,σ(typ)=bx−Cxtwp=log(pwbw),thp=log(phbh)txg=gx−gx.floor(0,tyg=gy−gy.floor0twg=log(pwgw),thg=log(phgh)
- 为什么要 σ ( t x p ) \sigma\left(t_{x}^{p}\right) σ(txp) 呢?这是因为网络不知道什么时候就会抽风,所以加上这个保证输出的差在0-1之间,因为anchor和预测的中心点不要差1个格子以上吧。
- 这个其实也是一种残差拟合的方法,加上SmoothL1应该就可以进行反向传播了。论文并没有写损失函数是什么的感觉。
- KaTeX parse error: Undefined control sequence: \C at position 75: … &\left(C_{x}, \̲C̲_{y}\right) \le…
- 这个公式算是对上面的公式的一个解释吧
YoloV3:
- YoloV2在残差网络出来了之后还可以进行进一步的改进。YoloV3其实并不是一片论文,而是一个报告。
模块改进:
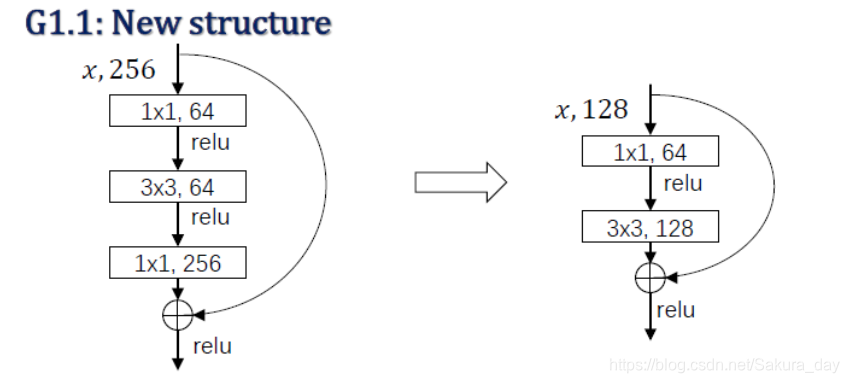
- 这是一个不彻底的残差结构,我偏偏就用一半的结构你能给我怎么地
多尺度输出:
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yhbHV7kJ-1617810573629)(目标检测 One Stage Detection(Yolo 系列).assets/image-20210407230259187.png)]](https://i-blog.csdnimg.cn/blog_migrate/283855e1ca7a6f3699ac521a4a2b7087.png)
-
三层的resolution不同(就是有13x13,26x26,52x52(小图像)每一层有3个anchor,用了kmeans做了9个anchor,用小中大进行分类,每一组有三个anchor,主要是针对大小不同的物体进行分类)增大featuremap的resolution,对小物体更加友好。通过不同的scale设计不同的feature map同时进行训练。
-
其实就是把格子打得更加密集一些,预测小物体的时候比较好搞定。
-
在分类的时候因为有很多类别,作者把softmax改成了logistics regression
-
网络在输出的时候,输出的尺度如下图所示:
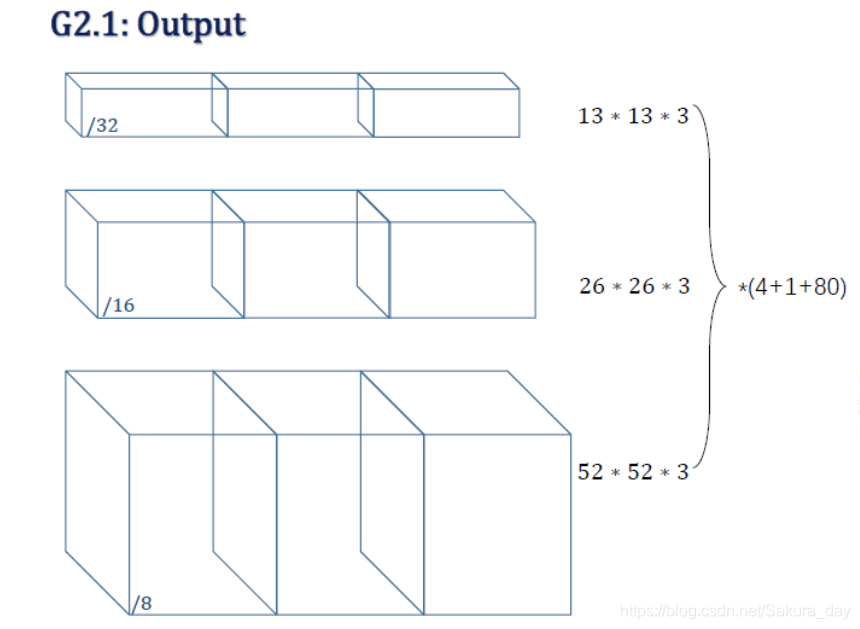
-
80 表示COCO数据集一共有80个类别,3表示每一个size一共有三种anchor,对应的输出也有三种。4+1就是熟悉的xywh+置信度c
FPN Net:
- 这个网络其实是一个比较万金油的网络,放在One Stage和Two Stage里面都可以,也叫做特征金字塔网络。它是由以下网络逐渐发展而来的。这个网络也是YoloV3设计的一个思路来源。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YnmyoYBs-1617810573631)(目标检测 One Stage Detection(Yolo 系列).assets/image-20210407231052999.png)]](https://i-blog.csdnimg.cn/blog_migrate/64246250ebfbe3e22b8337a739dc7607.png)
(a): 图像金字塔:featurized image pyramid。靠高斯核去模拟(原始的手算算法,高斯核唯一能够模拟人眼。。),要有尺度不变形!这个是没有cnn的时候这样做的。但是显然各个特征图之间没有交互,高层容易丢失一些信息。
(b):sigle feature map ,一个尺度输出一个预测,这就是传统CNN在做的事情。
(c):pyramidal feature hierarchy,通过降采样进行预测,不同的特征图之间有连接。只不过高层的位置信息会缺一些,底层的语义信息会缺失一些。
(d):FPN,其实和U-Net异曲同工,FPN把高层的语义信息和底层的位置纹理等信息结合了起来。如何进行互联呢:通过1x1修改channel,然后要进行upsampling之后再相加,最后对每一个尺度进行预测。当然FPN是一个比较吃资源的网络,对于速度型网络慎用。
- 关于损失函数的变化其实应该不大。具体还是得从代码中看。
休息一下,换一个网络之RetinaNet:
-
以Yolo为代表的One Stage检测精度一直都比Two Stage差,这是为什么呢?原来的人们一直以为这是因为Two Stage有Region Proposal,可以进行微调,而One stage并没有这个东西,所以效果会差一些。然而这个答案只是经验的结果,何大神再次出场提出了自己的见解:
-
效果有差别最重要的是:正负样本不均衡问题。以YoloV1为例,看看那个正负样本物体模板,一张图样本的正例寥寥无几,更不用说YoloV3了,52 * 52的格子,正负样本比例真的跟寺庙(某某工科大学)男女比差不多了。而看看RCNN系列,一直都是batchsize是128,正负样本比1:3牢牢保持着。正负样本差别马上就体现出来了。
-
正负样本失衡会使得整个样本的梯度和损失函数被简单样本占据,这样,网络就会学习一堆的简单信息,一堆负样本的没有用的信息,不知不觉,网络学坏了。
-
网络结构如下:
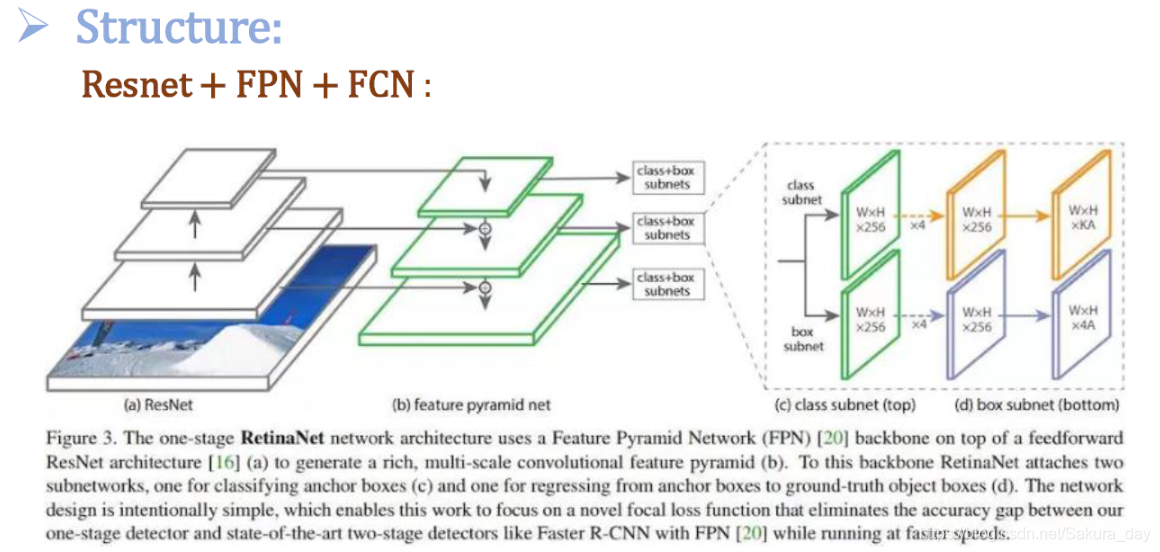
-
为了解决正负样本不均衡的问题,何大神提出了Focal Loss的方法:
-
focal loss是在交叉熵的基础上进行改进得到的,总体思想是提高正样本的权重,降低容易分类的样本和负样本的权重。最终出现了以下公式:α是用来解决正负样本的问题,γ用来解决样本难易的问题(focusing paramters)
-
p t = { p if y = 1 1 − p otherwise p_{\mathrm{t}}=\left\{\begin{array}{ll}p & \text { if } y=1 \\ 1-p & \text { otherwise }\end{array}\right. pt={p1−p if y=1 otherwise 交叉熵是: − y l o g ( p ) − ( 1 − y ) l o g ( 1 − p ) -ylog(p)-(1-y)log(1-p) −ylog(p)−(1−y)log(1−p),之后化一下就变成了下面的交叉熵
-
CE ( p , y ) = CE ( p t ) = − log ( p t ) \operatorname{CE}(p, y)=\operatorname{CE}\left(p_{\mathrm{t}}\right)=-\log \left(p_{\mathrm{t}}\right) CE(p,y)=CE(pt)=−log(pt) (这个是普通的交叉熵) (p->1的时候说明预测的是正样本,反之是负样本)
-
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) \mathrm{FL}\left(p_{\mathrm{t}}\right)=-α_{t}(1-p_{\mathrm{t}})^{\gamma} \log \left(p_{\mathrm{t}}\right) FL(pt)=−αt(1−pt)γlog(pt) γ>=0
-
为什么要加上这个调制系数呢?目的是通过减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。
-
当pt=0时就分错了,正常学习,当pt是1就分对了,就不用学习了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









