







Unet演化系列大整理:
- Unet是学习语义分割不可缺少的一个网络。它的对称美和简洁一直能够震撼人心。
主要摘要和前人工作:
- 作者发现,要进行分割任务需要很多的标注好的图片,然而标注图片是一个费时费力的过程。他提出了一个strong use of data augmentation方法能够更好的利用现有的数据。这个网络更主要是用在医疗图像分割方面。
- 作者说道了一个sliding-window模型。这个模型通过形成patch(其实就是通过不同大小的卷积核吧,当做滑动窗口)来对每一类像素进行预测。然而,这个方法会使得计算速度非常慢,而且由于不同的patch有重叠,就会出现很多冗余的计算。在定位精度和内容理解方面,大patch和小patch有冲突。大的patch需要经常使用maxpool,使得定位的精度降低。然而小的patch看到的内容比较少,虽然定位精度比较高。现在多尺度的卷积层能够进行融合,就像FCN一样。所以,网络层应该是有可能兼顾定位精度和内容理解的。
- Unet是从FCN更改而来的。主要是通过正常的类似于VGG的收缩网络,让每个层的feature map变小,之后再不断通过上采样代替pooling操作(论文里面是这么说)Unet内容并不是很多,主要是要注意网络结构的改进以及接下来的创新点。
网络结构详解:
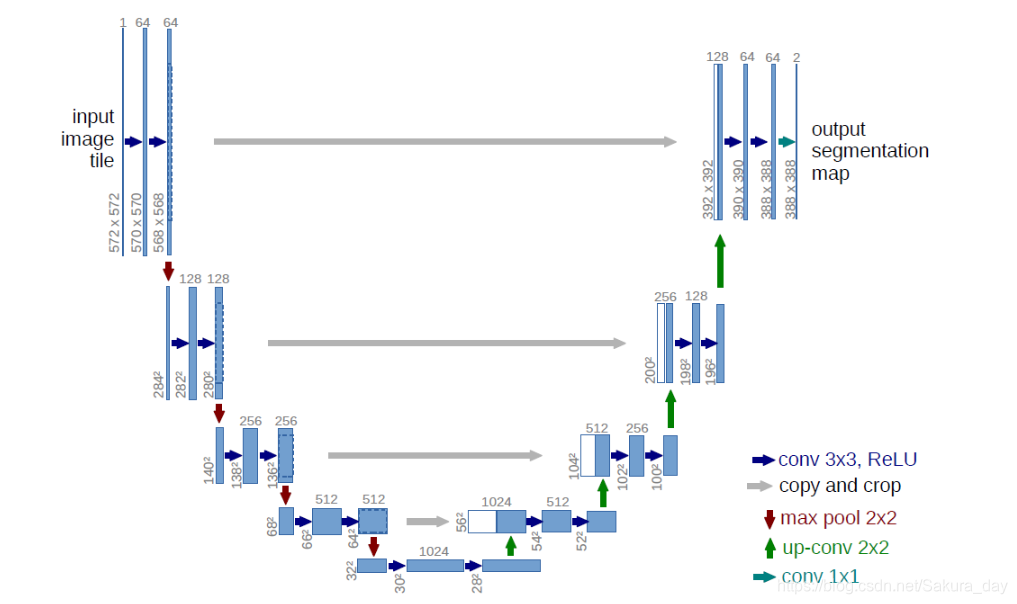
- 最小的feature map大小是32 x 32.蓝色的表示不同通道数的feature map,通道数在上面,feature map大小在左侧标注出来。之后各种箭头代表不同的处理方法。这个网络并没有经过padding,feature map的大小是通过严格计算的。
- 压feature map的被作者叫做encode,还原图像的上采样过程叫做decode过程。这个网络并没有全连接层,只有卷积层。在encode部分,作者遵循了之前卷积网络的结构,就是不断用两个3 x 3卷积核进行卷积,之后用ReLU和2 x 2的pooling层(stride = 2)来降低feature map的大小。每一次downsample都会让响应feature map的channel数增大一些。
- 在decode部分,作者用2 x 2的反卷积之后马上降低feature map一半的channel数目。为了和之前encode的feature map拼接起来。拼接之后用1 x 1的卷积核对通道数进行处理就可以了。网络一共有23个卷积层。
网络训练:
- 用了大图片,小batch进行训练。这样能够减少显存使用。
- 损失函数主要用的是交叉熵损失,用的是softmax, p k ( x ) = exp ( a k ( x ) ) / ( ∑ k ′ = 1 K exp ( a k ′ ( x ) ) ) p_{k}(\mathbf{x})=\exp \left(a_{k}(\mathbf{x})\right) /\left(\sum_{k^{\prime}=1}^{K} \exp \left(a_{k^{\prime}}(\mathbf{x})\right)\right) pk(x)=exp(ak(x))/(∑k′=1Kexp(ak′(x)))
- 在进行损失函数的计算的时候,他们的公式是这样的。前景是细胞的区域,背景是边界的像素。一堆都是细胞的区域
- E = ∑ x ∈ Ω w ( x ) log ( p ℓ ( x ) ( x ) ) E=\sum_{\mathbf{x} \in \Omega} w(\mathbf{x}) \log \left(p_{\ell(\mathbf{x})}(\mathbf{x})\right) E=∑x∈Ωw(x)log(pℓ(x)(x)) 其中 w ( x ) = w c ( x ) + w 0 ⋅ exp ( − ( d 1 ( x ) + d 2 ( x ) ) 2 2 σ 2 ) w(\mathbf{x})=w_{c}(\mathbf{x})+w_{0} \cdot \exp \left(-\frac{\left(d_{1}(\mathbf{x})+d_{2}(\mathbf{x})\right)^{2}}{2 \sigma^{2}}\right) w(x)=wc(x)+w0⋅exp(−2σ2(d1(x)+d2(x))2) (用形态学计算距离)它不仅会把细胞标注出来,也会单独标注出边界。x是每个像素输出的代表类别的向量。
- w c ( x ) w_{c}(\mathbf{x}) wc(x) 是平衡不同类别数目不均衡的权重。而 d 1 d_1 d1, d 2 d_2 d2 则代表边界离最近的细胞中心的距离和第二近的细胞中心离边界的距离。 w 0 w_0 w0是超参数,作者设置成10, σ \sigma σ = 5 pixels.
数据増广
Overlap-tile strategy:
- 这个方法可以用在任意大的图片上。
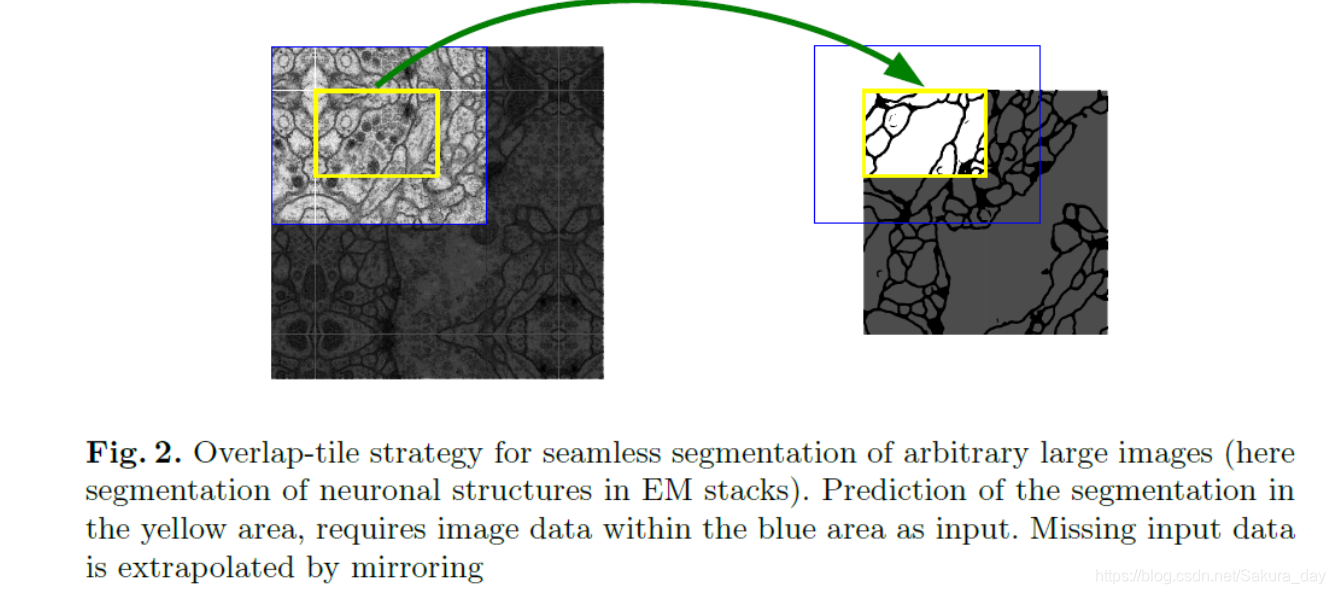
- 总而言之就是把图片分割成适当大小的部分。当然要首先进行padding,使得图片大小能够适用于Unet网络。在进行padding的时候,空白部分(不在图片里的部分)是通过镜像得到的。黄色部分是进行预测的图像部分,蓝色的是输入网络的图片。
- 像这种平铺策略能够适用于大型图片。把大型图片分成一个个patch有利于减少GPU的显存。能够使得我们能够进行U型的训练。
弹性变形:
- 这个非常适合细胞方面。因为细胞都是软软的,通过进行弹性变形,可以使得人免去标注新的内容。这个是一个比较好用的数据増广方法,不过应用方面有局限性就是了。
正负样本不均衡的问题:
- 作者在进行分割的时候发现,正样本数量明显少于负样本数量。所以,他们给正样本的损失函数加了适当大的权重。论文主要的内容就如上所示。
下游任务:
1. 人体姿态估计网络:Stacked Hourglass Networks(沙漏网络)
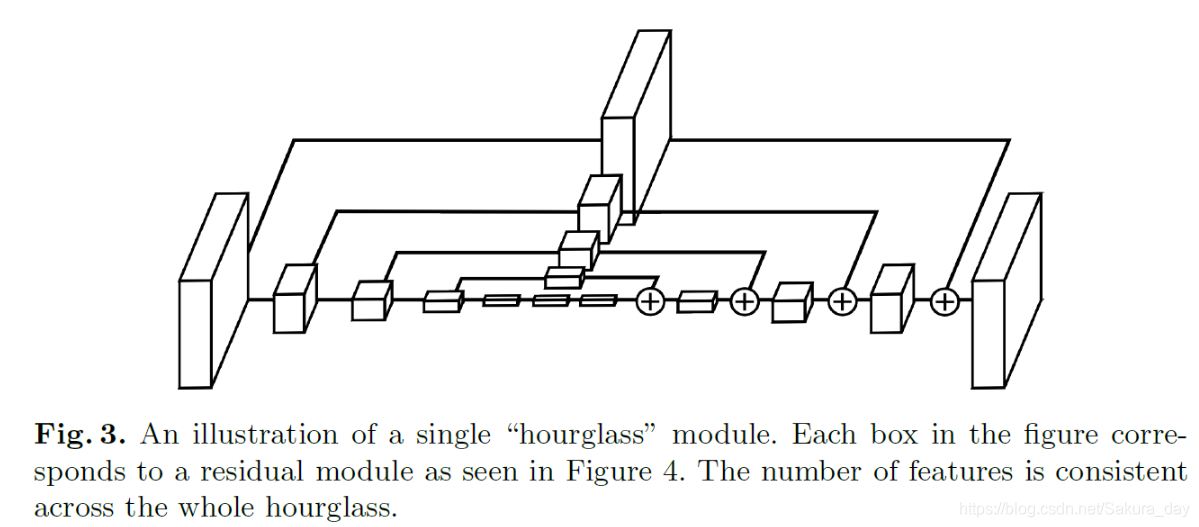
-
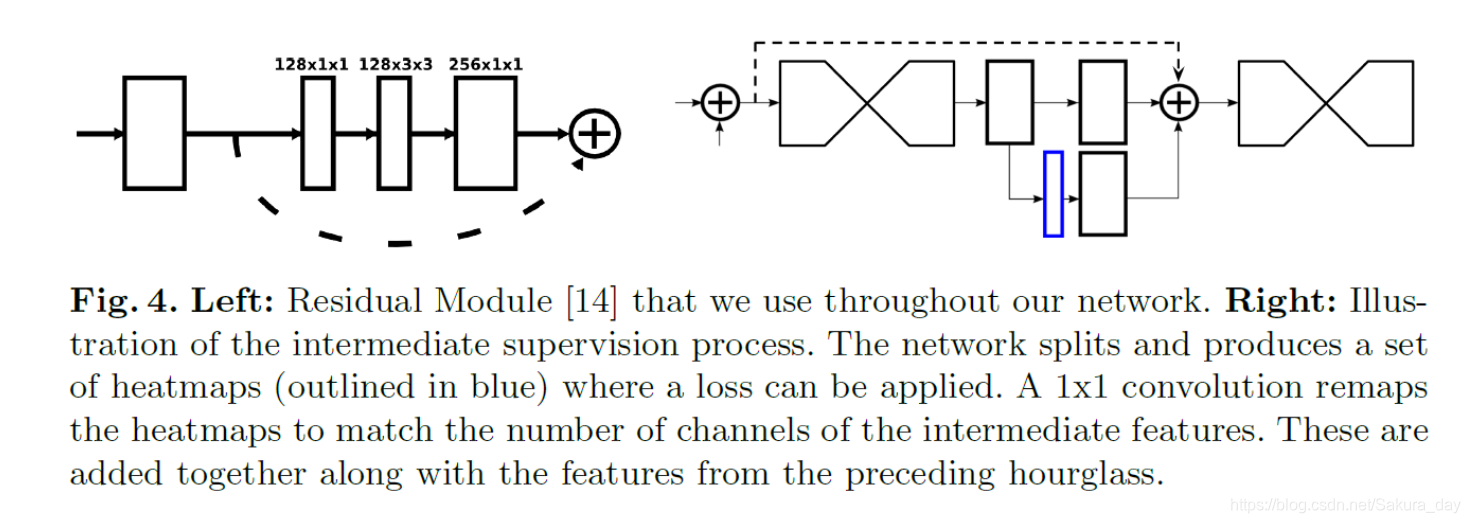
每一个都是一个残差网络。上采样的时候后主要通过最近邻插值和skip connections进行上采样。这个方法就很好玩了。在进行encode的时候,最小的feature map大小是4x4.作者在进行计算的时候,说256x256的输入太占用显存了。所以他输出的时候为了减少显存,分辨率变成了64x64.(就是一输入网络就用7x7的stride = 2的卷积层加上maxpool使得图像分辨率下降,就是说在hourglass中最大分辨率是64x64)这个并没有对模型的精确度造成很大影响
-
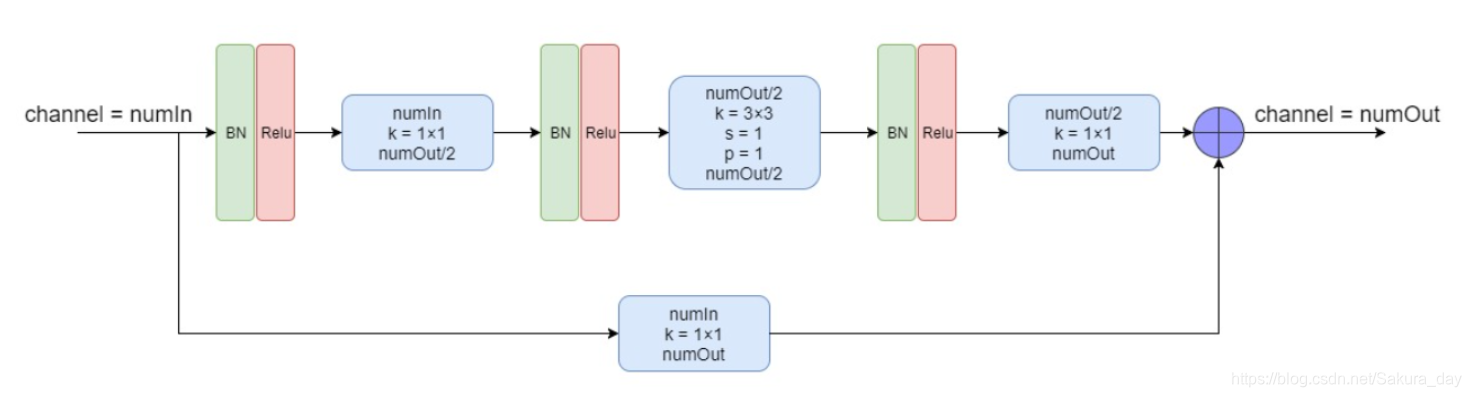
这个是上面的相对应的残差layer模块。作者在整个网络结构中堆叠了许多hourglass模块,从而使得网络能够不断重复自底向上和自顶向下的过程,作者提到采用这种结构的关键是要使用中间监督来对每一个hourglass模块进行预测,即对中间的heatmaps计算损失。
-
关于中间监督的位置,作者在文中也进行了讨论。大多数高阶特征仅在较低的分辨率下出现,除非在上采样最后。如果在网络进行上采样后进行监督,则无法在更大的全局上下文中重新评估这些特征;如果我们希望网络能够进行最佳的预测,那么这些预测就不应该在一个局部范围内进行。
-
由于hourglass模块整合了局部和全局的信息,若想要网络在早期进行预测,则需要它对图片有一个高层次的理解即使只是整个网络的一部分。作者在每一个沙漏结构的中间都添加了一个属于它的Loss函数。这个Loss函数是从这个蓝色的框框得到的。之后这一部分是可以继续用到网络中去的,只要用1x1卷积改变通道数就可以了。
Unet网络结构的修改:
-
更多尺度的融合,elewise改成contact也可以
-
在卷积内部进行更多的多尺度融合也可以,在外部也可以进行多尺度的融合。
-
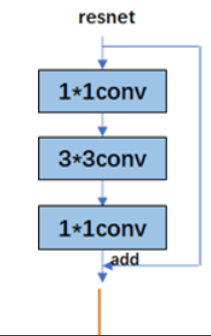
首先在卷积Block内做resnet的变种:
-
Bottle Neck:
-
这个就不画也不太想要解释了,因为这个已经是比较普遍的结构了。
-
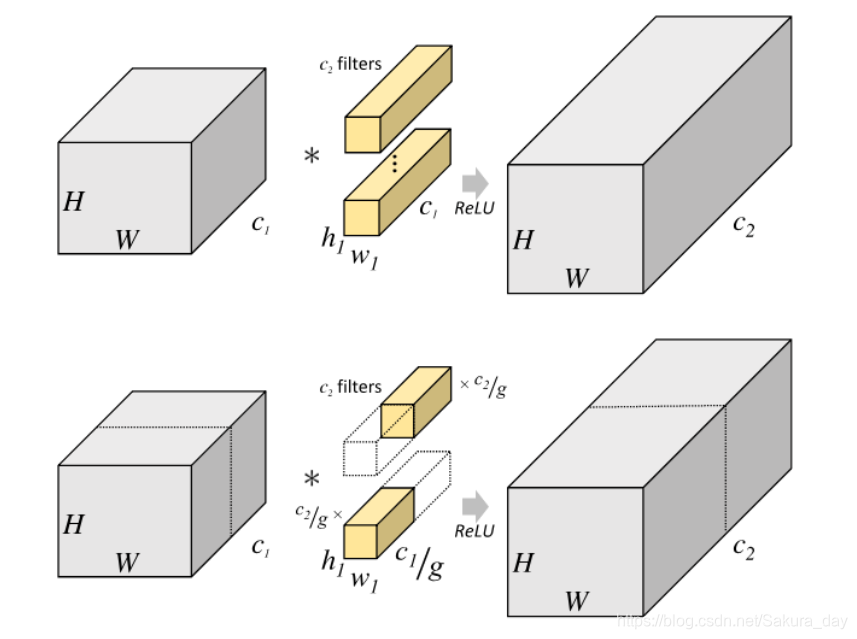
标准卷积的参数量:h1 x w1 x c1 x c2(一共有c2个卷积核)
-
组卷积的参数量:将输入特征图按照通道数分成 g g g 组, 则每组输入特征图的尺寸为 H × W × ( c 1 g ) H \times W \times\left(\frac{c_{1}}{g}\right) H×W×(gc1), 对应的卷积核尺寸为 h 1 × w 1 × ( c 1 g ) h_{1} \times w_{1} \times\left(\frac{c_{1}}{g}\right) h1×w1×(gc1), 每组输出特征图尺寸为 H × W × ( c 2 g ) H \times W \times\left(\frac{c_{2}}{g}\right) H×W×(gc2) 。将 g g g 组结果拼接(concat), 得到最终尺寸为 H × W × c 2 H \times W \times c_{2} H×W×c2 的输出特征 图。分组卷积层的参数量为 h 1 × w 1 × ( c 1 g ) × ( c 2 g ) × g = h 1 × w 1 × c 1 × c 2 × 1 g h_{1} \times w_{1} \times\left(\frac{c_{1}}{g}\right) \times\left(\frac{c_{2}}{g}\right) \times g=\boldsymbol{h}_{1} \times \boldsymbol{w}_{1} \times \boldsymbol{c}_{\mathbf{1}} \times \boldsymbol{c}_{\mathbf{2}} \times \frac{\mathbf{1}}{\boldsymbol{g}} h1×w1×(gc1)×(gc2)×g=h1×w1×c1×c2×g1
-
分成几组,参数量就下降几倍。
-
深度可分离卷积就是g = c1 = c2的分组卷积,只不过没有将g组结果进行contact,而是用1x1conv拼接起来。深度可分离卷积的参数是标准卷积的 1 / c 2 + 1 / D K 2 1 / {c_2}+1 / D_{K}^{2} 1/c2+1/DK2 。一般来说N远大于 D k D_k Dk。所以降低的参数量为 1 / D K 2 1 / D_{K}^{2} 1/DK2 .
-
Res2net:
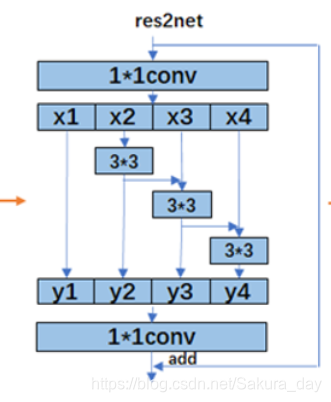
-
这个Block给我的印象就是比较花里胡哨。觉得解释性不是特别好。首先是吧channel平分成4部分。x1部分不作处理,之后x2用3x3卷积,一部分输出得到y2,一部分和x3相加之后再进行卷积。Res2Net在粒度级别表示多尺度特征,并增加了每个网络层的感受野。
-
综合上图结构以及上式,可看出由于这种拆分混合连接结构,Res2Net模块的输出包含不同感受野大小的组合,该结构有利于提取全局和本地信息。为了减少参数的数量,省略了第一个分割部分x1的卷积,这也可以视为特征重用的一种形式。
-
为什么增加了感受野呢?因为x4部分经过了3次卷积,每一次卷积都会使得感受野增加。当然,分成4部分是论文里面指定的。其实把channel分成几部分可以由自己确定。这样做的优点是分成越多部分感受野越大,且级联(conact)引入的计算/内存开销小,可以忽略不计。
-
Resnext:
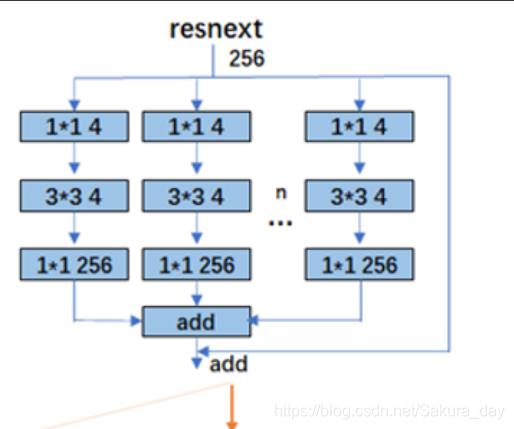
-
相当于用到了组卷积。在简化的Inception增加了一个short-cut。每一个框框里面是卷积的H x W x C。
-
ResNeXt确实比Inception V4的超参数更少,但是他直接废除了Inception的囊括不同感受野的特性仿佛不是很合理,在更多的环境中我们发现Inception V4的效果是优于ResNeXt的。类似结构的ResNeXt的运行速度应该是优于Inception V4的,因为ResNeXt的相同拓扑结构的分支的设计是更符合GPU的硬件设计原则。
-
SENet:
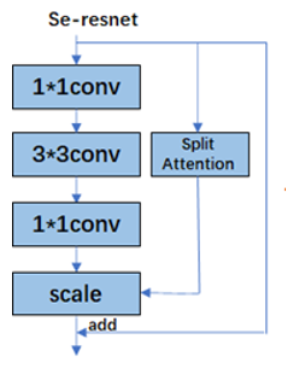
- 主要是通过Global pooling和FC层等对每一个channel计算出一个权重。通过这些权重网络能够知道哪些channel是更需要注意的。
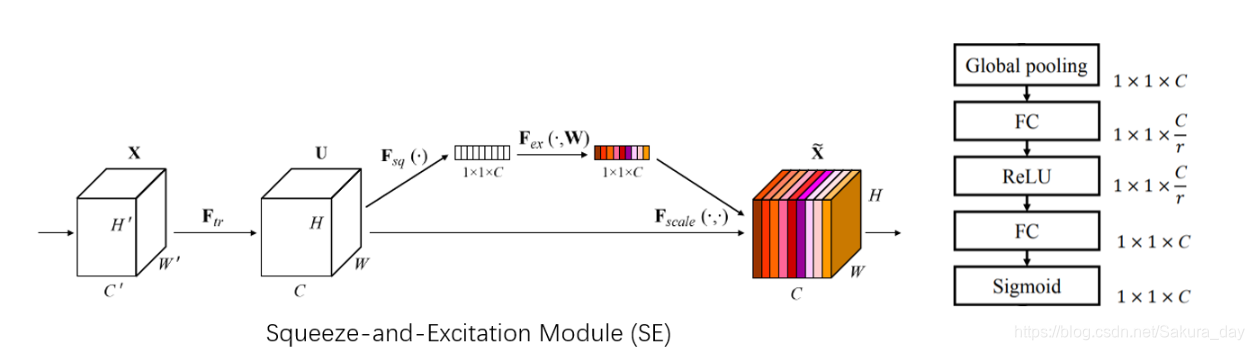
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rXdDt2SK-1623501581102)(论文大整理.assets/image-20210612194259831.png)]](https://i-blog.csdnimg.cn/blog_migrate/5f61a69a95e6e20f13dc5f6b4acb9b17.png)
-
用了不同种类的卷积核进行多尺度融合的方法。用3x3和5x5卷积核得到两个feature map。相加起来之后通过global pooling和FC(ReLU)计算出权重a和b。公式如下:
-
a c = e A c z e A c z + e B c z , b c = e B c z e A c z + e B c z a_{c}=\frac{e^{A_{c} z}}{e^{A_{c} z}+e^{B_{c} z}}, b_{c}=\frac{e^{B_{c} z}}{e^{A_{c} z}+e^{B_{c} z}} ac=eAcz+eBczeAcz,bc=eAcz+eBczeBcz
-
其中 A , B ∈ R C × d , a , b A, B \in \mathrm{R}^{C \times d}, \quad \mathrm{a}, \mathrm{b} A,B∈RC×d,a,b 表示 U ~ \tilde{U} U~ 和 U ^ \hat{U} U^ 的soft attention, A c ∈ R 1 × d A_{c} \in \mathrm{R}^{1 \times d} Ac∈R1×d 是A的第c行,
a c a_{c} ac 是a的第c个元素。在两个分支的情况下, 矩阵B是咒余的, 因为 a c + b c = 1 a_{c}+b_{c}=1 ac+bc=1 。最终的特征 映射V是通过各种卷积核的注意力权重获得的:
V c = a c ⋅ U ~ c + b c ⋅ U ^ c , a c + b c = 1 V_{c}=a_{c} \cdot \tilde{U}_{c}+b_{c} \cdot \hat{U}_{c}, a_{c}+b_{c}=1 Vc=ac⋅U~c+bc⋅U^c,ac+bc=1 -
如果是两个尺度的话,就不需要另一个矩阵B了。上面的a就是z直接做softmax,下面的b就是1-a之后做softmax。
-
最强的ResNeSt:
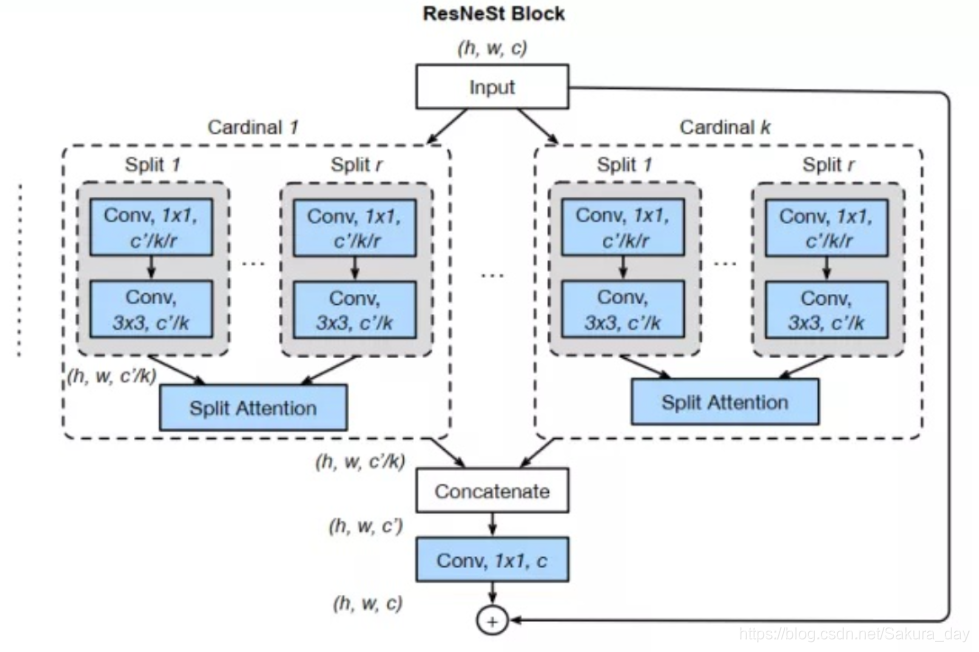
- 以下是Split Attention
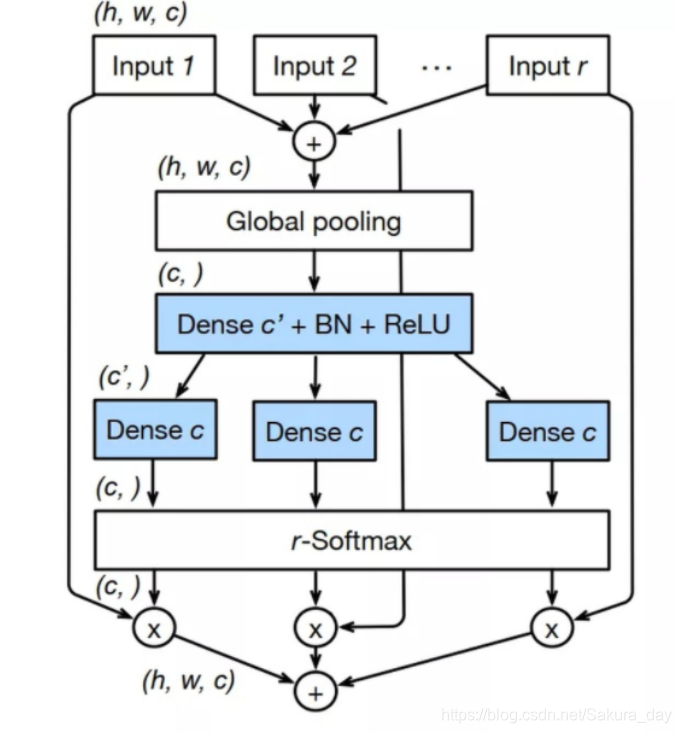
- 直接把ResNext和SKNet结合起来了。只不过看起来结构复杂了一些。
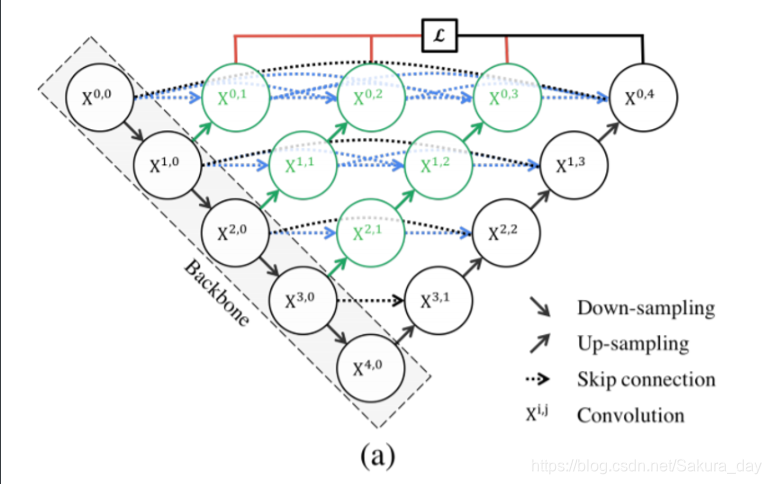
最后的Unet++:
-
总的来说就是在Unet中间不断地插入一些contact模块,让各种尺度的特征集合起来。
-
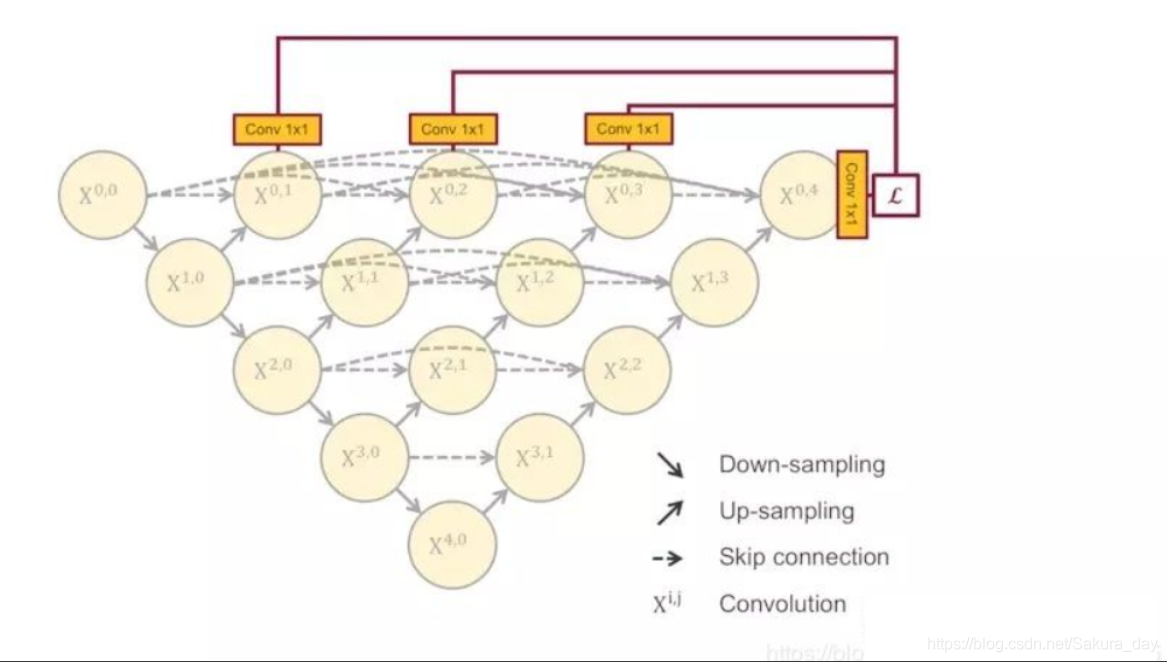
刚刚在讲本篇的第5节的时候留了一个伏笔,说这个结构在反向传播的时候, 如果只用最右边的一个loss来做的话, 中间部分会收不到过来的梯度,导致无法训练, 解决的办法除了用短连接的那个结构外,还有一个办法就是用深监督(deep supervision).如下图所示,具体的实现操作就是在图中 X0,1 、X0,2、 X0,3 、X0,4后面加一个1x1的卷积核,相当于去监督每个level,或者说监督每个分支的U-Net的输出。这样可以解决那个结构无法训练的问题.
-
具体的Unet++大总结可以参见这个链接https://zhuanlan.zhihu.com/p/44958351
-
一些杂碎
-
今天就这样吧。等下开始愉快地刷LeetCode啦。
-
程序设计 = 算法 + 数据结构 + 编程范式
-
C++ 面向过程,对象,泛型编程,函数式编程
-
printf有返回值,返回成功输出的字符数。printf是变参函数,format:格式控制字符串。printf可以接收任意多个的参数。

















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









