







SSD,Center Net
- SSD并不像Yolo一样满地开花,比较像一个孤岛。虽然在初期有比较惊艳的表现,但是在发育上明显落后Yolo,被人家甩飞了,但是毕竟也是目标检测元老级的人物,还是需要在学习笔记上留下它的身影才可以。

-
上图是SSD的网络结构图,从图上可以知道,BBox的输出是多尺度的,每一层的feature map都有输出。不像之后的Yolo,只有固定的输出层有输出。在SSD里面,低层预测小目标,高层预测大目标。
-
设置的anchor数量还是比较多的,所以对不同大小的目标检测效果比较好。前面我们知道了SSD提取的是anchor对应区域的特征,实际训练的时候还需要知道每个anchor的分类和回归的label,如何确定呢?SSD通过anchor与groundtruth匹配来确定label。
-
对于anchor的一些问题:在Yolo里面没有整理,在这里可以整理一下:
-
- 为什么要设置anchor:
- 通过设计anchor,能够使得特征图与特定大小的目标进行相应。
-
- 为什么同一个检测层可以设置不同大小的anchor:
- 有效感受野理论说明,每一层实际响应的区域其实是有效感受野区域,而且这个感受野区域在训练的过程中会发生变化(比如不同数据集影响等)。正是由于有效感受野能够随着训练过程发生变化,具有自适应性,所以可以在同一个检测层设置不同大小的anchor,到时候直接通过网络来选择到底哪个anchor的响应更好。
-
- 为什么可以在同一个特征图上设置多个anchor检测到不同尺度的目标:
- 分类和回归使用的是同一个特征图,但是不同通道的卷积核学习到的那块区域是有不同的特征的,所以不同通道对应的anchor能够监测到不同尺度的目标。
-
- anchor本身不参与网络的实际训练,anchor影响的是classification和regression分支如何作用。测试的时候anchor就像滑动窗口一样,在图像中滑动,对每个anchor做分类和回归得到最终的结果。
-
SSD里面用到了难样本挖掘的方法,这个可以注意一下。对loss比较大的样本和分类错误的样本加比较大的权重,进行特别关照。
SSD缺点:
- 对小物体检测效果一般,作者认为小目标在高层没有足够信息。
- 对小目标检测的改进可以通过下面几个方面考虑:增大输入尺寸,使用更低的特征图做检测,或者用FPN。其实检测和分割都会用到这种方法。
- anchor的设置可以和Yolo差不多,通过聚类的方式找到比较是和的anchor大小。
Center Net:
-
其实anchor还是有很多缺点的,它的缺点可以总结如下:
-
- 需要根据不同数据集进行设置,泛化能力比较差,不太好设置
- 会增大运算量,产生很多的数据冗余,最终要进行NMS等后处理才能够选出合适的结果
- 正负样本不均衡严重,要应用focal loss等平衡正负样本的方法
-
我们知道YoloV1也是anchor free的网路,只不过效果比较不好。这个center net是论文里面没有center net的那一篇文章的center net。它主要有以下重点知识:
-
center net又快有准,直接把物体当成点去检测,只检测物体的中心点。它把卷积神经网络乐高化了。把它变成backbone -> link -> function head这三个结构,backbone可以随便改,link只管承上启下,function head可以自己加。具体如下图所示:
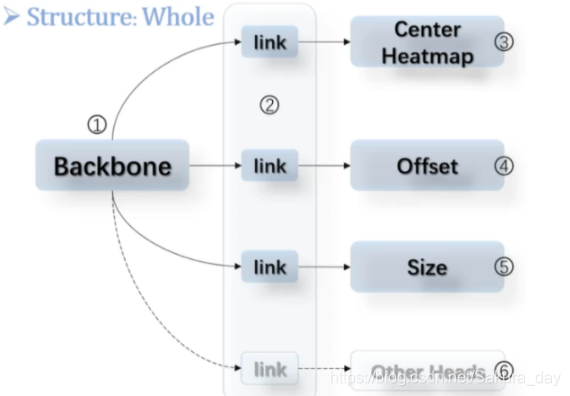
-
我们可以大致看看backbone用了啥:

-
这个backbone清一色在最后进行了upsample,这个是比较重要的,如果feature map的分辨率太小的话,会导致定位会有量化误差,并不准,所以需要扩大了方便定位。这也和分割网络有异曲同工之处。具体的backbone就不介绍了,觉得万变不离其宗。
-
在center net里面,它的function head主要包括三个部分,一个是中心热力点云,一个是量化误差预测,还有一个就是size的回归。我们一个一个来说:
Center Heatmap:
- 这个应该是非常重要的一部分了,决定了选框能否准确。
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WQDVY4v8-1625839749460)(SSD和Center Net:.assets/image-20210709213040354.png)]](https://i-blog.csdnimg.cn/blog_migrate/fb6052505f238717ff8142414ca28929.png)
- 首先我们可以看到Center Heatmap的feature map的shape,为什么有80个通道呢?因为coco数据集有80类,每一个通道用来预测一个类别。这一部分是用来提取特征的。
- 在这个网络里面,没有直接通过xy回归得到中心点坐标,因为直接暴力回归的准确率确实比较堪忧(经过下采样再上采样,引入的误差和量化量还是比较可观的,特别是非对称结构的上下采样,肯定会引入无法避免的量化误差)。而是通过点云回归。其实不需要通过这么硬的标签进行回归,硬的不行软的也可以凑合一下。所以通过高斯核软化中心坐标,是它变成概率点云。其实和热力图差不多,半径的选择是经过cornet 指导的,在这个网络有特别的半径选择方法。说白了就是通过bbox的大小确定,如果bbox的size比较大,那么就让半径大一些,反之就小一些。这样回归经过实验效果会好一些。
- 在loss函数的计算上用focal loss,这样可以滤除不是中心点,但是有一定概率的点云点。
- 产生了bbox之后当然需要后处理了。其实这一次的后处理用3x3max pool,为什么可以呢?因为我们用的是点云,所以只要找到邻域里面最大值的点。经过max pool,如下图,我们找到的一般就是最大值的点。然后可以和其他的不是最大值的点隔开。这样就能起到后处理的效果。通过max pool得到mask,再用mask就能找到效果最好的中心点了。
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UAoEHmof-1625839749462)(SSD和Center Net:.assets/image-20210709214722207.png)]](https://i-blog.csdnimg.cn/blog_migrate/76f343dc83e194fb6d3a1fd35600e6ea.png)
offset:
-
现在我们已经知道了量化误差这个东西,不管是Yolo还是RCNN全家桶都有量化误差这个苦恼。所以对于中心点的预测肯定有1个像素范围内的误差。现在用点云也会有误差,因为不一定刚刚好就在整坐标上。如果有误差可以直接预测,专门用两个channel预测误差,一个预测x误差一个是预测y的误差。~是向下取整的意思。
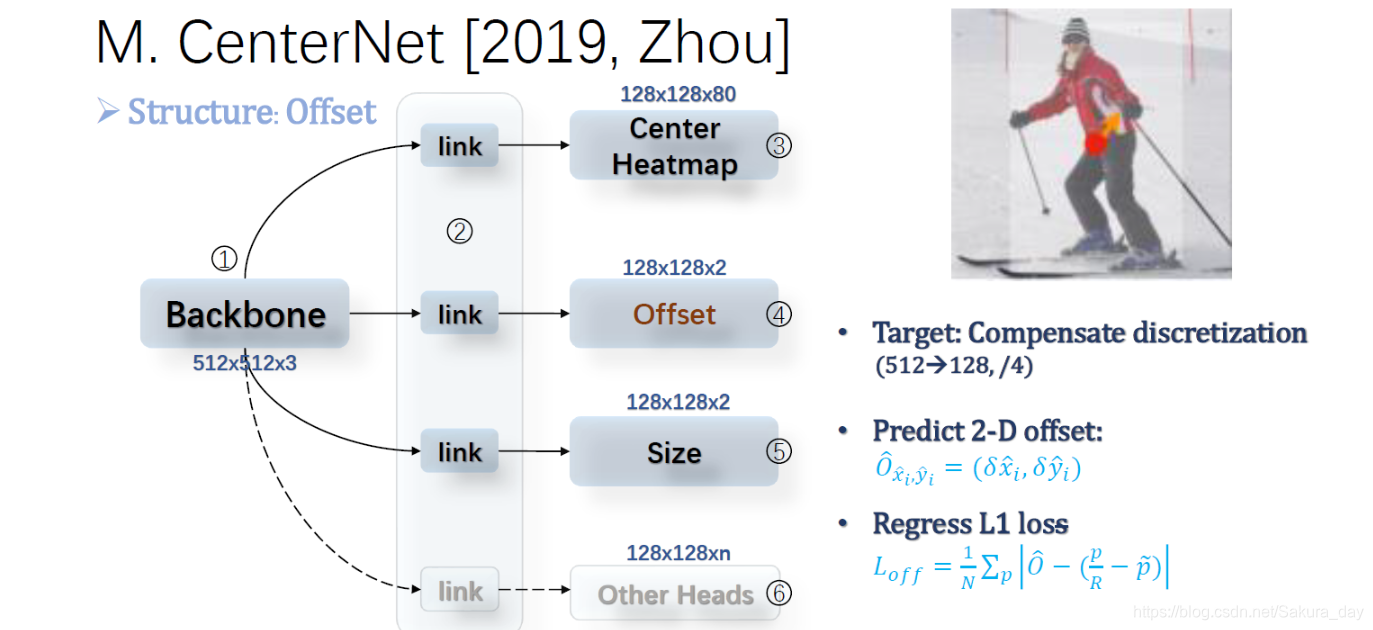
-
量化误差是无法避免的,干脆就去预测就好了,有这样想法的作者也是很豪爽。
最后一步:预测size:
- 中心点都预测出来了,接下来就预测size,宽高就可以了。最终得到的需要反向传播的loss如下图所示:
- L det = L k + λ size L size + λ off L eff , ( λ size = 0.1 , λ off = 1 ) L_{\text {det }}=L_{k}+\lambda_{\text {size }} L_{\text {size }}+\lambda_{\text {off }} L_{\text {eff }},\left(\lambda_{\text {size }}=0.1, \lambda_{\text {off }}=1\right) Ldet =Lk+λsize Lsize +λoff Leff ,(λsize =0.1,λoff =1)
- 如果还需要其他功能,比如预测深度,加上分割,就直接添加相应功能头就可以了。
![- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j1vIqeuU-1625839749463)(SSD和Center Net:.assets/image-20210709215712342.png)]](https://i-blog.csdnimg.cn/blog_migrate/556747e9d979bfadf92631b0bf3c1602.png)

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









