






最近 AI 圈是不是跟过年一样热闹?DeepSeek 的余温还没散,千问Qwen3就来炸场,这不,字节的 Deerflow 又带着一身光环闪亮登场了!不得不说,大厂们的 AI 大战,精彩程度堪比“东子大战美团”的年度大戏!
DeerFlow:为深度研究而生的加速器

DeerFlow,是字节跳动在GitHub上开源的一个Deep Research项目。从帮你搜集整理文献数据、做深度分析,到辅助你训练模型、验证结果,甚至还能帮你润色报告、生成PPT和播客!简直就是想把科研狗从水深火热中解救出来的“天降神兵”啊!
传统部署的“拦路虎”:环境配置的隐形壁垒
然而,正如许多前沿的开源项目一样,想要率先体验 DeerFlow 的强大功能,往往需要先跨越环境配置这道门槛。
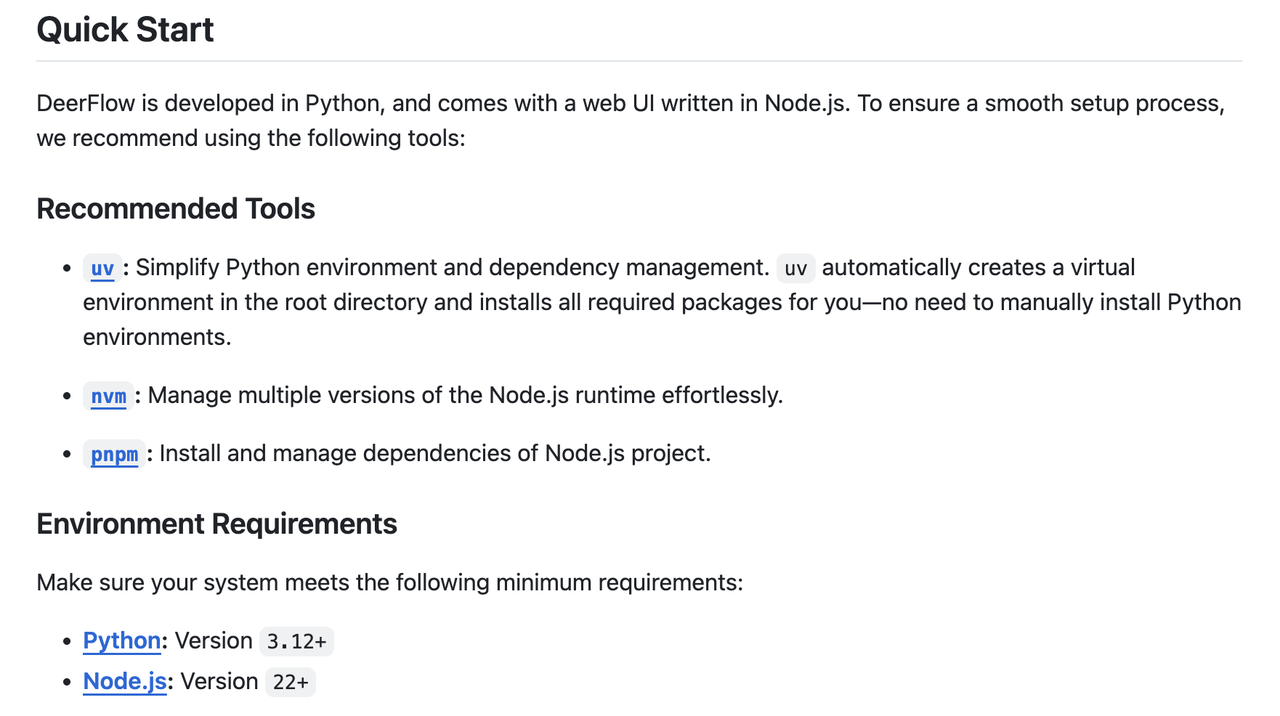
根据官方文档,DeerFlow 对运行环境有着明确且相对严苛的要求:Python 版本需为 3.12 或更高,Node.js 版本则需达到 22 或更高。
对于许多开发者而言,在本地环境中精确管理和切换多个 Python 或 Node.js 版本,确保它们之间的依赖隔离与正确激活(例如通过 pyenv, nvm 等工具并手动配置环境变量),往往是一项复杂且耗时的工作,稍有不慎便可能陷入版本冲突的泥潭。这种前期的环境搭建难题,无疑会消耗开发者宝贵的精力,甚至可能成为探索新技术的“劝退符”。
ServBay:macOS 上部署 DeerFlow 的优雅之道
幸运的是,对于广大的 macOS 用户而言,我们拥有一个更为高效和优雅的选择——ServBay。作为一款专为 macOS 设计的一站式本地开发环境,ServBay 能够完美化解 DeerFlow 部署过程中的环境挑战,让开发者将精力聚焦于创新本身。
选择 ServBay 部署 DeerFlow 的核心优势在于:
-
精细化的多版本管理与一键切换:这正是 ServBay 应对 DeerFlow特定版本需求的“杀手锏”。ServBay 允许用户通过直观的图形化界面,轻松安装并同时管理多个不同版本的 Python (如 Python 3.11, 3.12, 3.14 等) 和 Node.js (如 Node.js 18, 20, 22, 23 等)。为 DeerFlow 启用所需的 Python 3.12+ 和 Node.js 22+?只需在 ServBay 界面上几次点击,即可完成版本的激活与切换。ServBay 会在底层自动处理复杂的路径和依赖关系,确保环境的纯净与准确。
-
真正的一站式集成开发平台:ServBay 的能力远不止于 Python 和 Node.js 的管理。它原生集成了 PHP(多版本)、MySQL、MariaDB、PostgreSQL、Redis、Memcached,以及 Caddy、Nginx、Apache 等主流Web服务器。这意味着,如果您的 DeerFlow 项目未来需要集成数据库支持或其他后端服务,ServBay 依然能提供一站式的解决方案,无需额外配置其他工具。
-
完善的环境隔离机制:ServBay 为每个启用的服务和版本都提供了出色的隔离。您为 DeerFlow 配置的 Python 3.12 和 Node.js 22 环境,将与系统中其他项目或其他版本的环境完全隔离,有效避免了潜在的冲突,同时也保障了 macOS 系统环境的整洁与稳定。
-
极致的易用性与直观操作:ServBay 彻底告别了繁琐的命令行配置和晦涩的配置文件编辑。其清爽直观的图形用户界面,使得服务的安装、版本的切换、日志的查看、配置的修改等操作都变得前所未有的简单高效。
实战演练:使用 ServBay 快速搭建 DeerFlow 运行环境
在开始之前,请确保您的 macOS 系统已成功安装 ServBay。若尚未安装,请访问 ServBay 官方网站 (https://www.servbay.com) 下载最新版本并完成安装。其安装过程与常规 macOS 应用无异,简单直接。
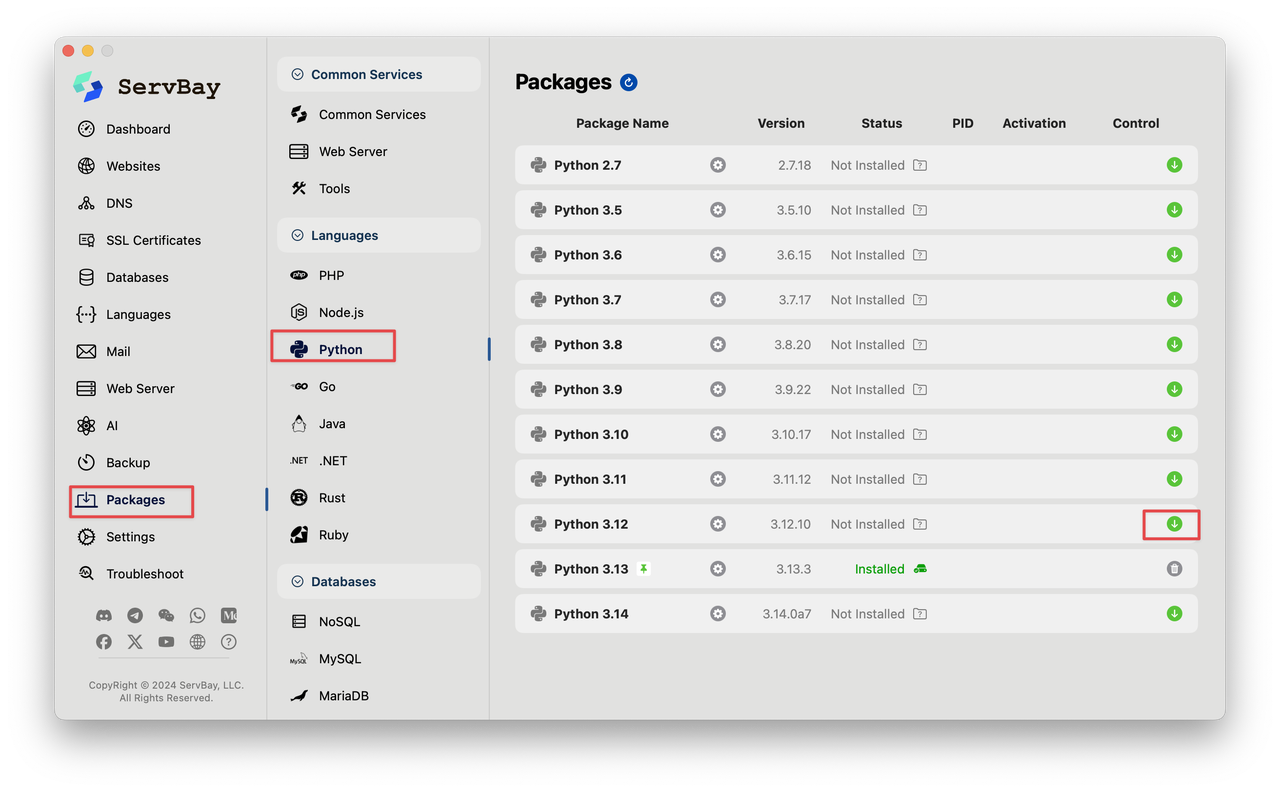
第一步:通过 ServBay 安装 Python 3.12+
-
启动 ServBay 应用程序。
-
在左侧导航栏中,选择「软件包」选项。
-
在服务列表中找到 Python。您会看到 ServBay 支持的多个 Python 版本。
-
选择 Python 3.12 或任何更新的版本,点击其右侧的下载或安装按钮。ServBay 将自动完成下载和安装过程。
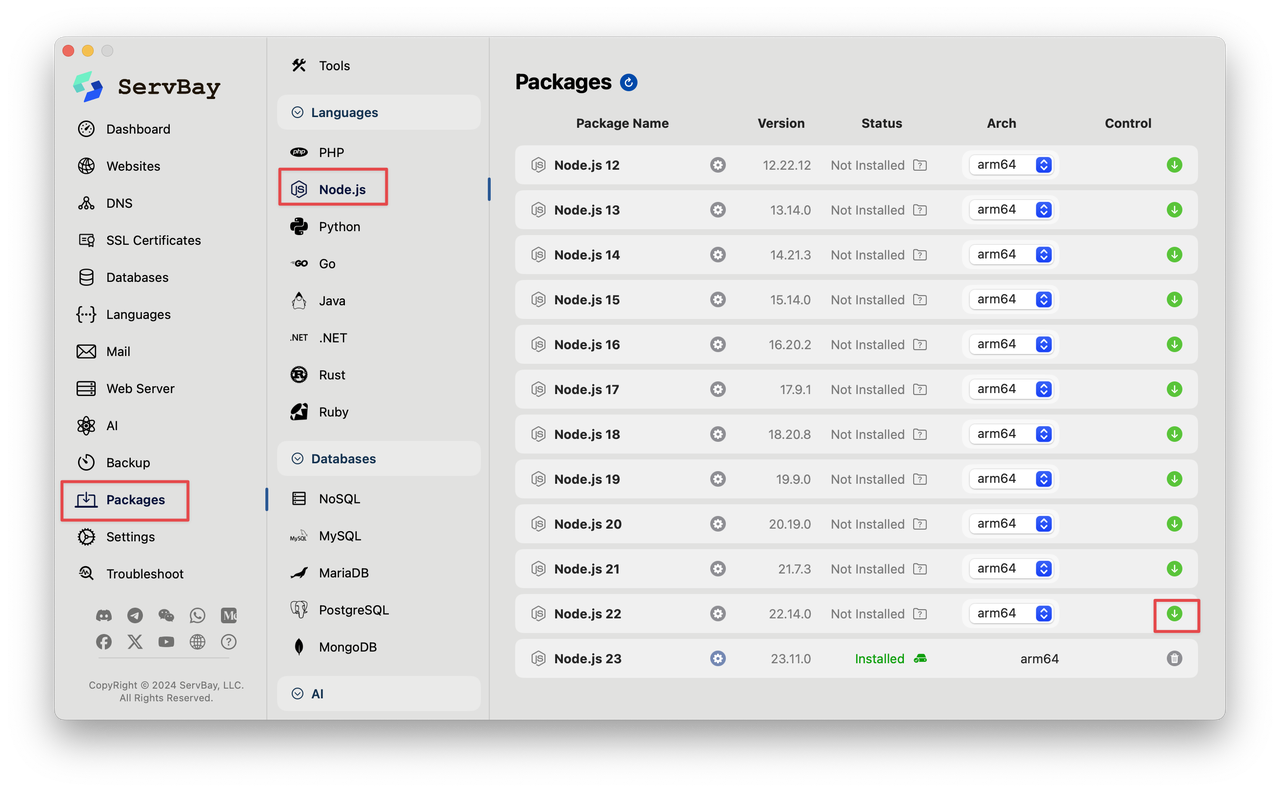
第二步:通过 ServBay 安装 Node.js 22+
-
同样在 ServBay 的「软件包」管理界面。找到 Node.js 并选择 Node.js 22 或任何更新的版本下载。
第三步:验证环境配置
配置完成后,验证是确保一切就绪的关键步骤。
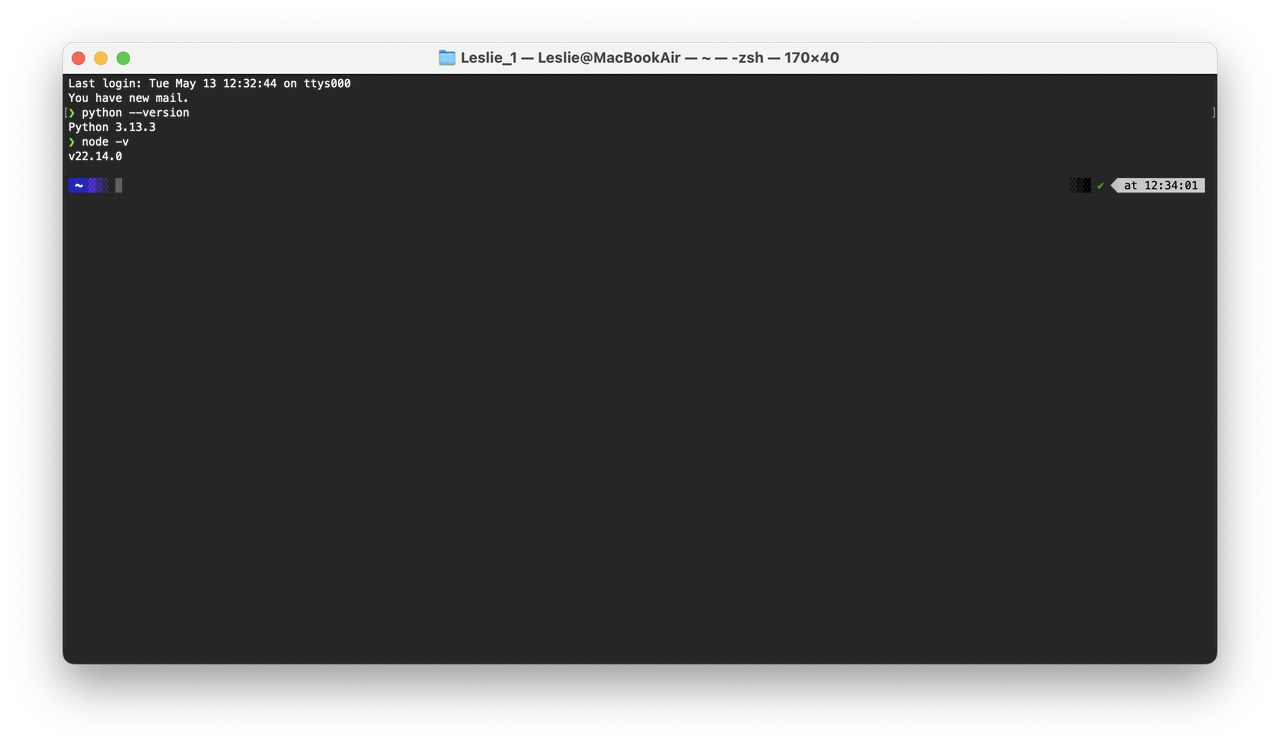
应该能看到输出结果分别显示 Python 3.13.3 和 Node.js 22.14.0,这表明 ServBay 已成功配置了符合 DeerFlow 要求的运行环境。
获取并安装 DeerFlow 项目
基础配置
环境万事俱备,接下来是 DeerFlow 项目本身的安装与配置
# Clone the repository
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
# Install dependencies, uv will take care of the python interpreter and venv creation, and install the required packages
uv sync
# Configure .env with your API keys
# Tavily: https://app.tavily.com/home
# Brave_SEARCH: https://brave.com/search/api/
# volcengine TTS: Add your TTS credentials if you have them
cp .env.example .env
# See the 'Supported Search Engines' and 'Text-to-Speech Integration' sections below for all available options
# Configure conf.yaml for your LLM model and API keys
# Please refer to 'docs/configuration_guide.md' for more details
cp conf.yaml.example conf.yaml
# Install marp for ppt generation
# https://github.com/marp-team/marp-cli?tab=readme-ov-file#use-package-manager
brew install marp-cli划重点!别忘了要修改.env和conf.yaml配置,不然就401了。
官方默认的搜索引擎是Tavily(Tavily AI),这是一个针对 AI 应用程序的专用搜索 API。火山引擎暂时用不上,就先不填。修改后的命令是这样.
# Search Engine
SEARCH_API=tavily
TAVILY_API_KEY=tvly-xxx
# JINA_API_KEY=jina_xxx # Optional, default is None
# Optional, volcengine TTS for generating podcast
VOLCENGINE_TTS_APPID=xxx
VOLCENGINE_TTS_ACCESS_TOKEN=xxx
# VOLCENGINE_TTS_CLUSTER=volcano_tts # Optional, default is volcano_tts
# VOLCENGINE_TTS_VOICE_TYPE=BV700_V2_streaming # Optional, default is BV700_V2_streaming同样我们需要修改 conf.yaml, 这里主要是用到的基础模型,官方推荐是chatGPT,但我觉得Gemini更好用,而且API还是免费。
BASIC_MODEL:
base_url: "https://generativelanguage.googleapis.com/v1beta/openai/"
model: "gemini-2.0-flash"
api_key: YOUR_API_KEY完成了安装和基础配置,就可以让DeerFlow跑起来了。
# Run the project in a bash-like shell
uv run main.py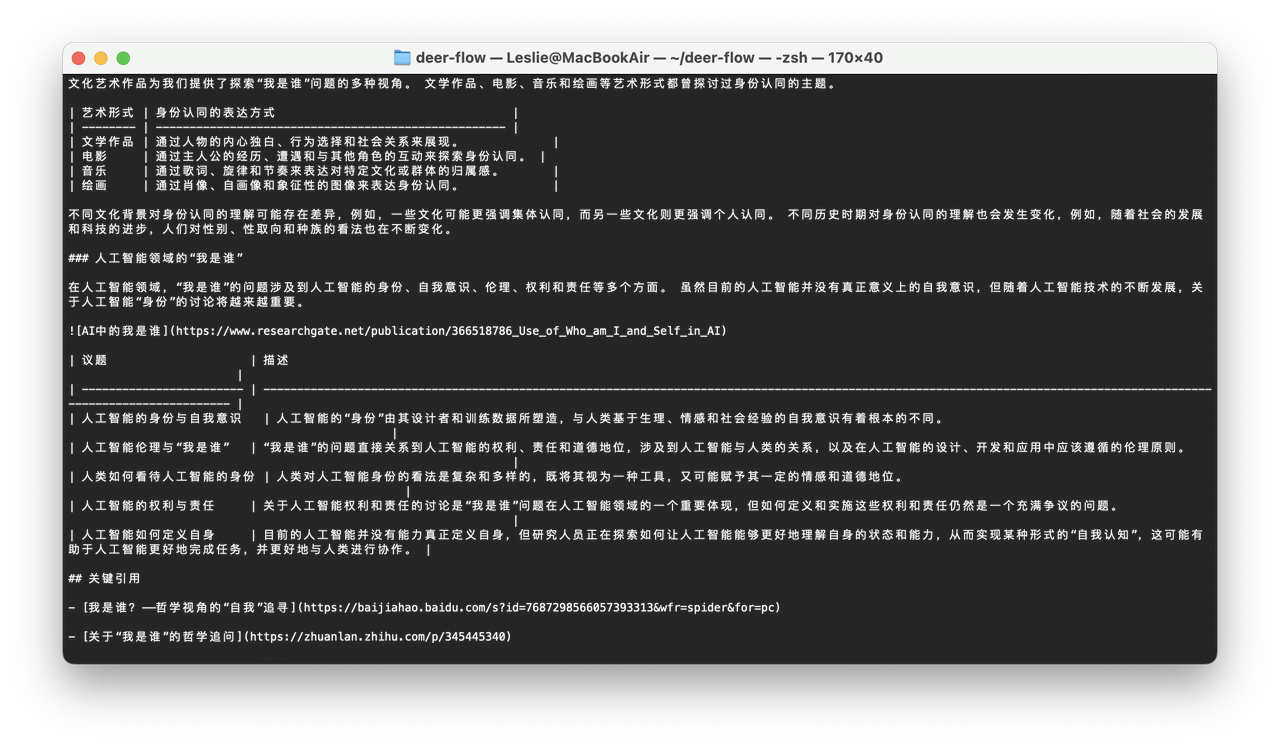
Web UI交互
但这种黑魆魆的终端实在难看,那么可以安装一个Web UI来进行交互。
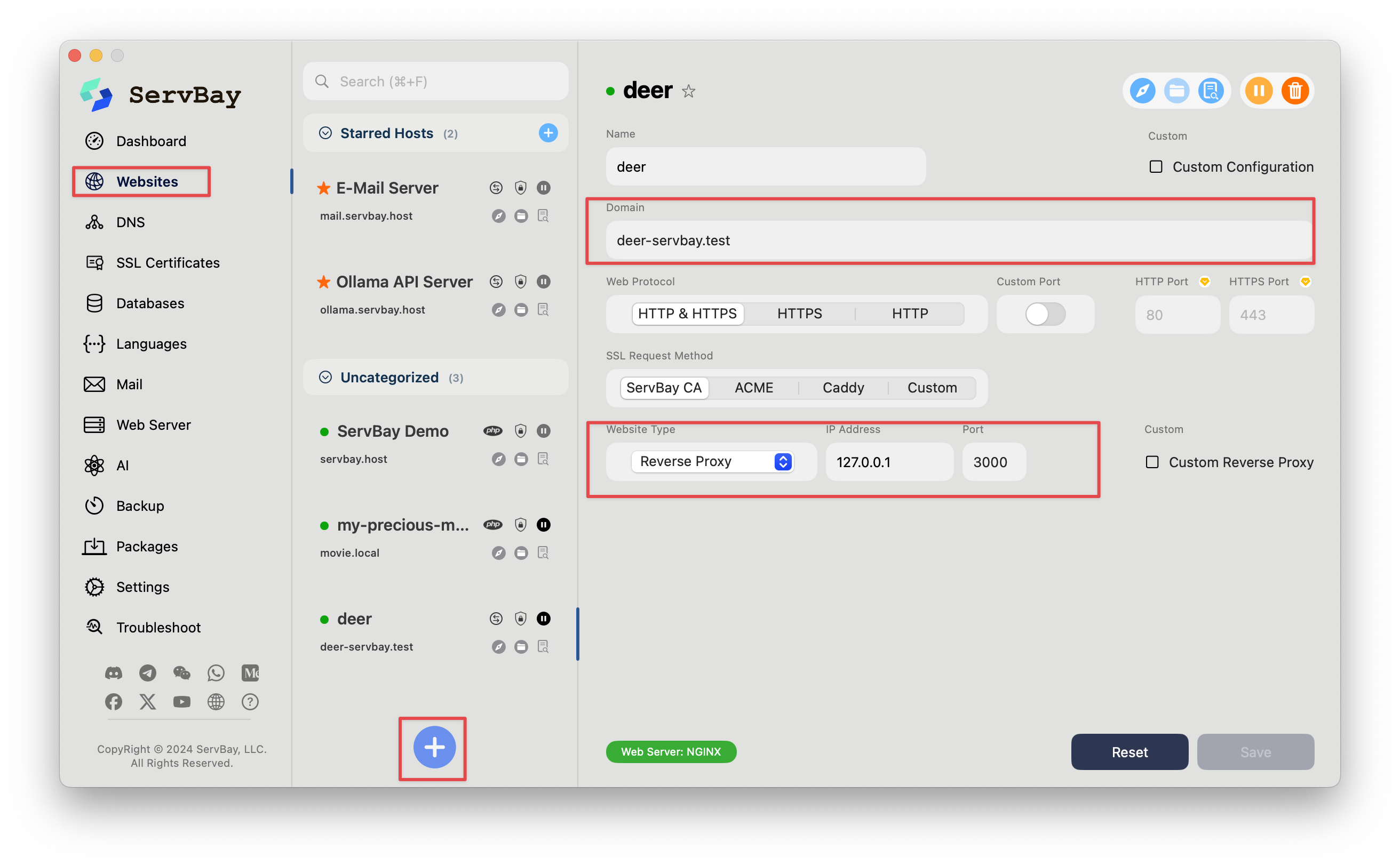
官方是用localhost来打开这个Web UI的,但我更推荐用ServBay,通过ServBay创建一个反向代理,自定义域名,使用起来更方便。
-
在ServBay左边的导航菜单栏中,找到「网站」,下方的「+」按钮添加新的网站。
-
名字:起个自己喜欢的名字
-
域名:自定义一个好记的域名
-
网站类型:选择反向代理
-
IP地址:输入127.0.0.1
-
端口:3000
输入命令启动bootstrap.sh
# Run both the backend and frontend servers in development mode
# On macOS/Linux
./bootstrap.sh -d在浏览器输入自定义的域名,就可以和DeerFlow实现交互了。
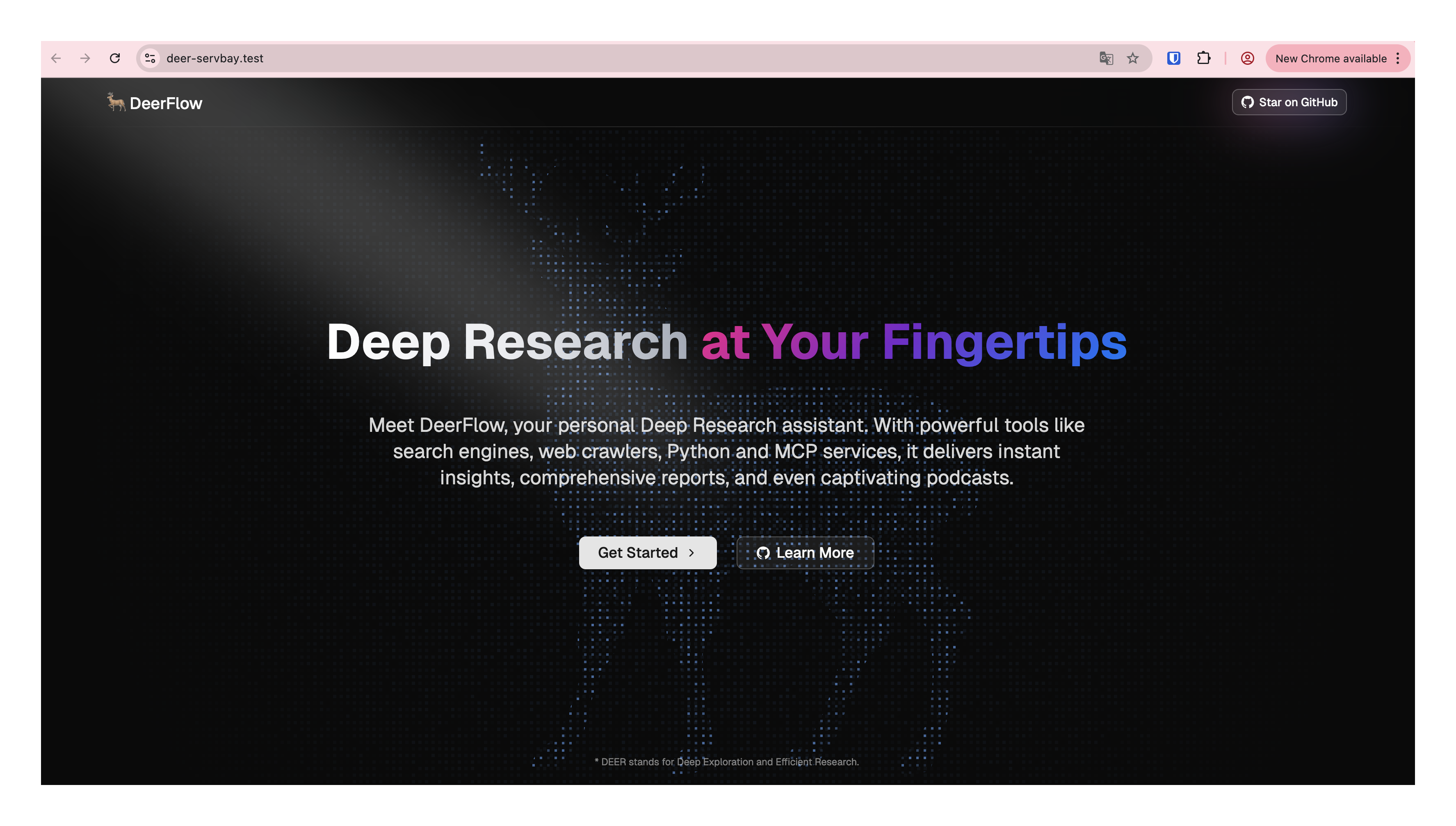
是不是非常的方便?
进阶玩法
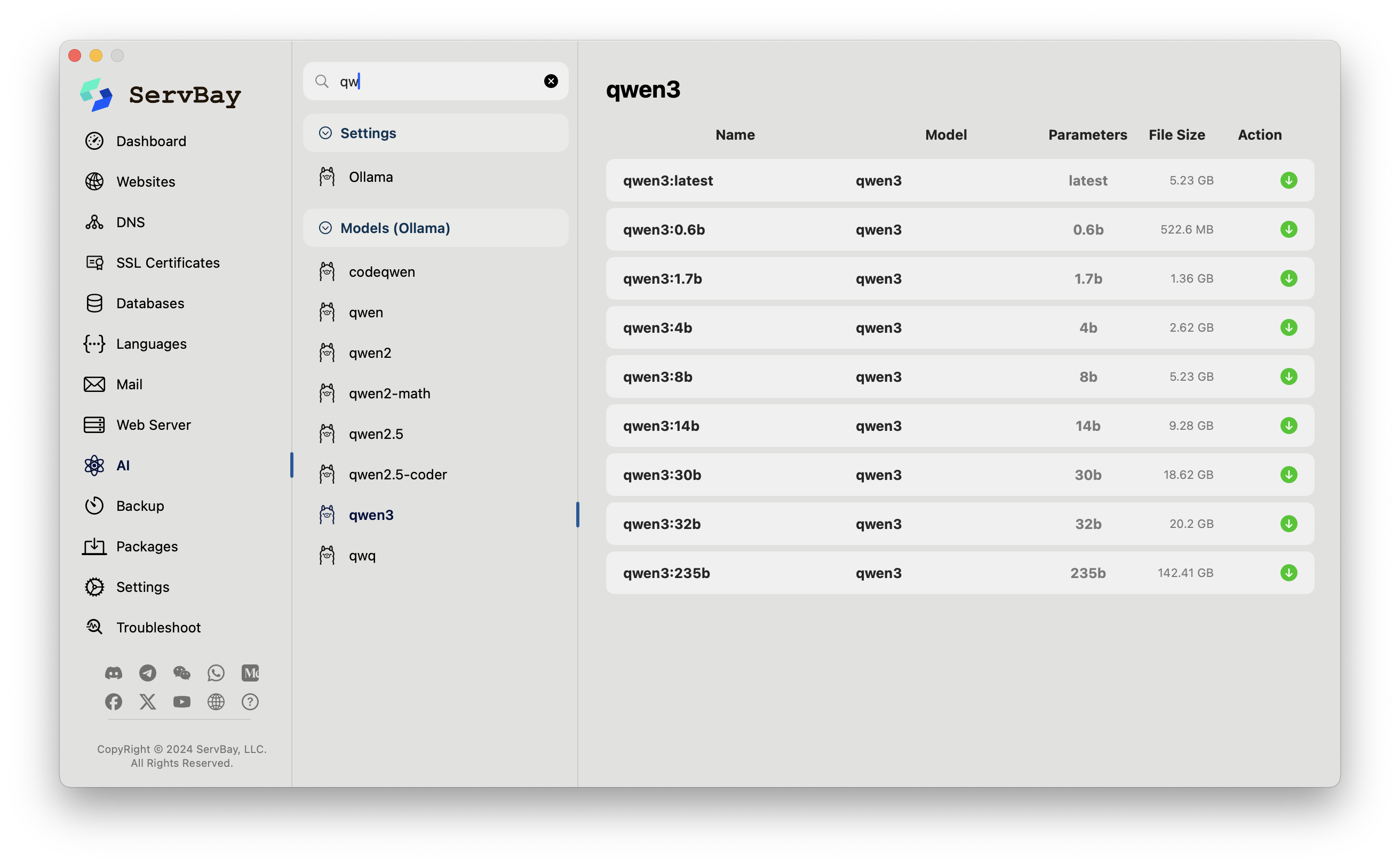
正当我以为 DeerFlow 只可以在线上运行的时候,我看到了它居然支持Ollama,这就意味着在本地也能部署啊。
还是掏出神器ServBay。
ServBay早就支持了Ollama,安装好后,本地部署千问Qwen3(什么,你说DeepSeek?它已经不流行了,现在Qwen3才是王道),就可以在本地愉快地跑起来啦。
DeerFlow 的广阔应用前景:赋能多元场景的深度探索
掌握了如何通过 ServBay 高效部署 DeerFlow 之后,我们不禁要问:这个强大的深度研究平台,究竟能在哪些领域大放异彩?从其核心功能——深度研究辅助、多模态内容处理、AI增强报告编辑及演示文稿生成等——我们可以预见其在多个关键场景下的巨大潜力:
1. 学术研究与科学探索:
- 文献综述与知识发现:DeerFlow 能够协助研究人员快速搜集、筛选和分析海量学术文献、专利数据和行业报告,自动提取关键信息,生成结构化的知识图谱或综述摘要,极大提升文献调研效率。
- 实验数据分析与解读:结合其数据处理能力,研究者可以利用 DeerFlow 对实验数据进行深度分析,结合AI模型进行模式识别、趋势预测,并辅助生成初步的分析报告。
- 科研成果展示与传播:通过AI增强的报告编辑和PPT自动生成功能,科研人员可以更高效、更专业地撰写研究论文、制作学术报告和演讲材料,促进科研成果的快速传播与交流。
2. 商业智能与市场分析:
-
行业动态与竞品追踪:企业分析师可以利用 DeerFlow 持续监控行业新闻、社交媒体动态、竞品情报,通过AI进行情感分析、趋势识别,形成深度洞察报告,为决策提供依据。
-
用户研究与产品反馈:整合用户调研数据、产品使用日志、客服记录等多源信息,DeerFlow 能够帮助产品团队深入理解用户需求与痛点,优化产品设计与运营策略。
-
内容营销与知识分享:市场团队可以借助 DeerFlow 快速生成行业白皮书、技术解读文章、在线研讨会PPT乃至播客脚本,提升内容生产效率与专业度。
3. 教育与知识服务:
- 个性化学习资源生成:教师或教育内容开发者可以利用 DeerFlow 针对特定主题或课程,快速整合相关知识,生成定制化的学习材料、课件和测验。
- 复杂概念解读与可视化:对于复杂的科学原理或技术概念,DeerFlow 可以辅助生成易于理解的图文报告或演示,帮助学生更好地吸收知识。
4. 金融与投资分析:
- 财报分析与风险评估:分析师可以运用 DeerFlow 对上市公司的财务报表、新闻公告进行深度挖掘,结合宏观经济数据,进行更全面的风险评估和投资价值分析。
- 市场情绪与舆情监控:实时追踪金融市场的相关新闻和社交媒体讨论,通过AI分析市场情绪,为交易决策提供参考。
5. 法律与合规领域:
- 案例研究与法律文献检索:律师和法务人员可以利用 DeerFlow 高效检索和分析大量法律文书、判例和法规,辅助案件准备和法律咨询。
- 合规性审查报告生成:辅助生成合规性审查的初步报告,梳理相关条款和潜在风险点。
结语:ServBay 赋能,探索DeerFlow更多玩法
在 ServBay 的强力支持下,为 DeerFlow 这样具有特定环境依赖的前沿项目搭建运行环境的过程,被极大地简化了。原本可能充满挑战的版本管理、环境隔离等问题,在 ServBay 直观的图形化界面和自动化处理机制面前迎刃而解,还可以和Ollama完美配合。
DeerFlow 的出现,代表了AI技术赋能深度信息处理和知识创造的新方向。随着其功能的不断完善和社区生态的持续发展,我们有理由相信,它将在更多需要深度思考、高效信息处理和专业内容生成的领域发挥关键作用。而 ServBay 这样的高效开发环境,则为每一位渴望探索和应用这些前沿技术的开发者,铺平了道路,让创新之旅更加顺畅。

















 3390
3390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









