







第六章 文字显示
6.1 字符的编码方式
6.1.1 编码与字体
1、编码:指用数字来表示字符,如用0x41来表示字符A
2、字体:同一个字符在屏幕上显示出来时可以使用不同的形状
3、 TXT 文件中保存的是字符的核心:它的编码值。而 Notepad 上显示时,这些字符对应什么样的形状态,这是由字体决定的。
6.1.2 编码标准
对于同一种字符,不同编码标准的编码值不同。
1、ASCⅡ码(美国信息交换标准代码)
(1)ASCII 编码中使用一个字节来表示一个字符,只用到其中的 7 位,一共能表示2ˇ7即128个字符
(2)最高位bit7恒为 0
(3)缺点是表示的字符太少
2、ANSⅠ码
(1)使用记事本保存文件时,可以选择“ANSI”编码,但没有“ASCII”
(2)ANSⅠ 是 ASCII 的扩展,向下包含 ASCII:
ASCⅡ字符:仍然用一个字节表示,并且bit7为0;
非ASCⅡ字符:用两个字节表示,bit7为1。如汉字就是非ASCⅡ字符,占两个字节。
(3)选择ANSⅠ编码时需选择相应的字符集,才能显示想要的字符。比如在中国大陆地区, ANSI 的默认编码是 GB2312;在港澳台地区默认编码是 BIG5。
这仅仅是在中国地区就出现这些不兼容的问题。对于不同国家,它们默认的ANSI 编码各不相同,所以同一个 TXT 文件在不同国家就很有可能出现乱码。
3、UNICODE编码
(1)UNICODE 编码解决了编码不同导致乱码的问题:对于地球上任意一个字符,都给它一个唯一的数值。
(2)UNICODE 仍然向下兼容 ASCII,但是对于其他字符会有对应的数值,比如对于“中”、“笢”,它们的数值分别是:0x4e2d、0x7b22 (一个是简体一个是繁体)
(3)UNICODE 中的数值范围是 0x0000 至 0x10FFFF,有 1,114,111 即 100 多万个数值,可以表示 100 多万个字符,足够地球人使用了。
(4)UNICODE编码按照不同的编码实现可以分为四种:“UTF-16 LE”、“UTF-16 BE”、“UTF-8”、“带有 BOM 的 UTF-8”,这些分别可以咋保存txt文本文件的界面进行选择。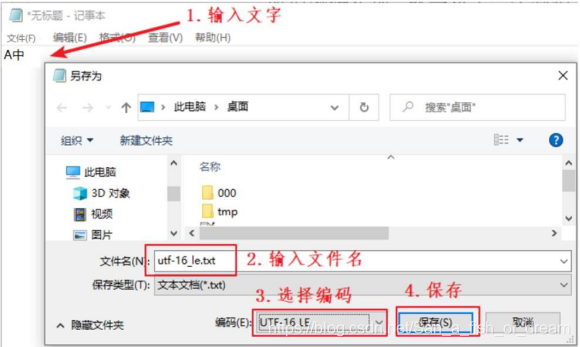
6.1.3 编码实现
一、编码实现的概念
所谓编码实现,就是对于一个数值,怎么表示它。
比如“中”的 UNICODE值是 0x4e2d,在 TXT 文件中怎么表示 0x4e2d?
问题的关键在于:怎么断字。在 TXT 文件中,2 字节数据“0x2d 0x4e”是作为一个整体看待,还是拆成 2 部分看待?
所以,需要用一定的技巧来表示数值,这就对应不同的编码实现。
比如现在我们知道:
(1)ASCII 编码中使用一个字节来表示一个字符,只用到其中的 7 位,最高位恒为 0;
(2)ANSI 编码中,对于ASCII 字符仍使用一个字节来表示(BIT7 是 0),对于非 ASCII 字符一般使用 2 个字节来表示,非 ASCII 字符的数值 BIT7 都是 1。
二、UNICODE的编码实现
1、使用 3 个字节表示一个 UNICODE
缺点:太浪费内存,本来一两个字节的信息结果用三个字节来表示。
2、 UTF-16 LE 与 UTF-16 BE
(1)三个字节既然浪费那就采用两个字节,两个字节可以表示 2^16=65536 个字符,全世界常用的字符都可以表示了。
(2)但是会出现另一个问题:字节序问题
小字节序:数值中权重低的字节放在前面。
大字节序:数值中权重低的字节放在后面
如编码值0x41有大字节序0x41 0x00和小字节序0x00 0x41。
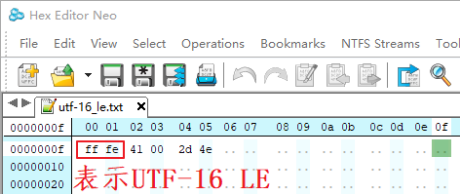
(3)UCS-2 Little endian / UTF-16 LE
Little endian (LE)表示小字节序,文件开头的“0xff 0xfe”表示“UTF-16 LE”。
比兔“A”使用“0x41 0x00”两字节表示;“中”使用“0x2d 0x4e”两字节表示。
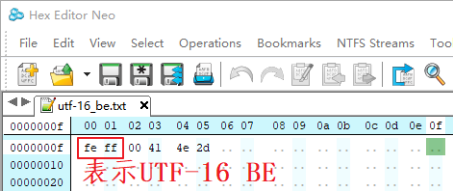
(4)UCS-2 Big endian / UTF-16 BE
Big endian(BE) 表示大字节序,文件开头的“0xfe 0xff”表示“UTF-16 BE”。
比如“A”使用“0x00 0x41”两字节表示;“中”使用“0x4e 0x2d”两字节表示。
(5)对于上述两种方法,每一个 UNICODE 使用 2 字节来表示,这有 3 个缺点:
①表示的字符数量有限
②对于ASCII 字符有空间浪费
③如果文件中有某个字节丢失,这会使得后面所有字符都因为错位而无法显示。
因此才出现UTF8 来解决上述问题
3、UTF8
(1)UTF8 是变长的编码方法,有 2 种 UTF8 格式的文件:带有头部、不带头部。
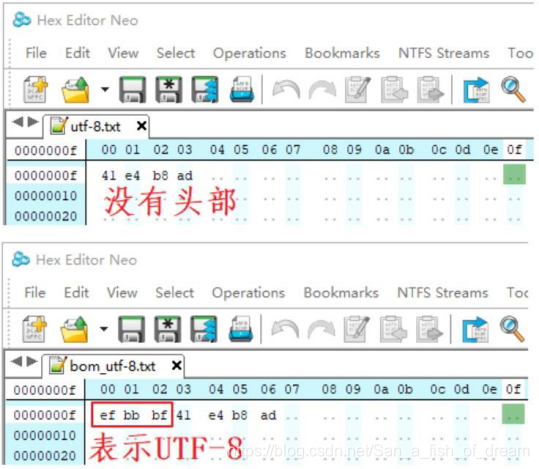
(2)对于其中的 ASCII 字符,在 UTF8 文件中直接用其 ASCII 码来表示,比如0x61 表示字符 a、0x62 表示字符 b。ASCII 字符与非ASCII 字符的区别在于前者的bit7位是0,这与前面的内容是完全一致的。
(3)对于非 ASCII 字符,使用变长的编码:每一个字节的高位都自带长度信息。请看下图:
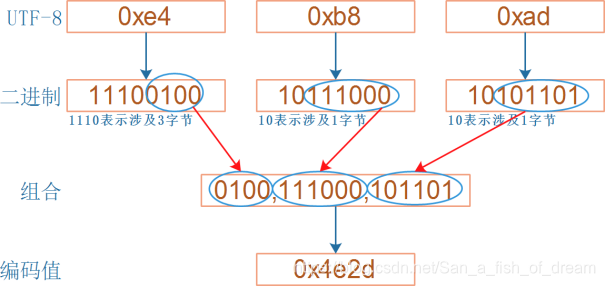
上图中,0xe4 的二进制是“11100100”,高位有 3 个 1,表示从当前字节起有 3 字节参与表示 UNICODE;
0xb8 的二进制是“10111000”,高位有 1 个 1,表示从当前字节起有 1 字节参与表示UNICODE;
0xad 的二进制是“10101101”,高位有 1 个 1,表示从当前字节起有 1 字节参与表示 UNICODE;
除去高位的“1110”、“10”、“10”后,剩下的二进制数组合起来得到“01001110001101”,它的十六进制表示就是 0x4e2d,即“中”的 UNICODE 值。 非 ASCII 字符正是这样通过带有长度信息的编码来解决字节丢失引起的乱码问题。(详解见下)
(4)因为每个 字节都自带长度信息,所以即使 TXT 文件中丢失了某些数据,也只会影响到当前字符的显示,后面的字符不受影响。
比如假设上面的例子中丢失了0xb8这个字节:本来应用程序读取了0xe4后知道包括0xb4在内有三个字节的数据来表示这个非 ASCII 字符,所以当读取到后面两个字节是10开头时就会将其参与编码。而丢失字节后,读取到0xad的下一个字节开头不是10,表示不参与这个字符的编码。最后该字符的编码值只读取到0xad,所以出现乱码,而后面的字节不参与这个字符的编码;并且此时编码受到字节中长度信息的控制,字节丢失不会引起字节错位,所以后续所有的字节都不会受到影响。
再比如丢失了0xe4这个字节:应用程序读取到0xb8、0xad两个字节的开头都是10,不能形成编码(bit7位是1的单独字节既不能表示 ASCII 字符也不能表示非 ASCII 字符,非 ASCII 字符至少两个字节),所以会形成乱码。当读到0xad后面的字节不是10又会恢复正常的编码,而且由于前面两个字节以10开头,所以不会使后面字节参与到前面的编码。
疑问:
如果丢失的数据不是以字节为单位而是之丢失了几位二进制位呢,那会不会导致数据错位然后全部乱码?还是说数据的丢失必定是以字节为单位呢?















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









