







框架是MMSegmentation;
自己的数据集是 voc 格式;
代码:https://github.com/NVlabs/SegFormer
mmlab环境的安装:https://blog.csdn.net/Scenery0519/article/details/129595886?spm=1001.2014.3001.5501
mmseg 教程文档:https://mmsegmentation.readthedocs.io/zh_CN/latest/useful_tools.html#id10
文章目录
一、环境配置
首先需要配置好 mmlab 环境。
参考 mmlab环境的安装:https://blog.csdn.net/Scenery0519/article/details/129595886?spm=1001.2014.3001.5501
安装如下的库,版本按照自己匹配的来
pip install torchvision==0.8.2
pip install timm==0.3.2
pip install mmcv-full==1.2.7
pip install opencv-python==4.5.1.48
cd SegFormer && pip install -e . --user
二、跑训练
# Single-gpu training
python tools/train.py local_configs/segformer/B1/segformer.b1.512x512.ade.160k.py
报错1:
AssertionError: MMCV==1.7.1 is used but incompatible. Please install mmcv>=[1, 1, 4], <=[1, 7, 0].
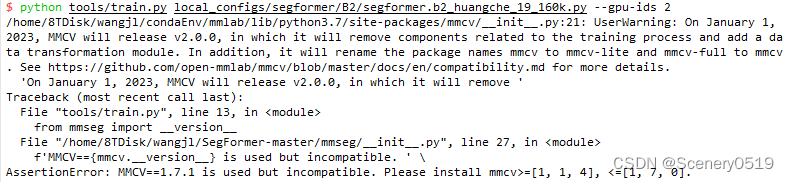
修改 /SegFormermaster/mmseg/init.py 文件

使自己的mmcv版本匹配在这个区间里。我使用的是mmcv==1.6.0版本可以正常跑程序。
报错2:
File “/home/8TDisk/wangjl/condaEnv/mmlab/lib/python3.7/site-packages/timm/models/layers/helpers.py”, line 6, in
from torch._six import container_abcs
ImportError: cannot import name ‘container_abcs’ from ‘torch._six’ (/condaEnv/mmlab/lib/python3.7/site-packages/torch/_six.py)
上边的报错内容给出了出错的文件路径,照着路径找到 _six.py 文件修改。
修改 condaEnv/mmlab/lib/python3.7/site-packages/timm/models/layers/helpers.py
修改内容如下所示,将 from torch._six import container_abcs 注释掉,替换下面的代码。
# from torch._six import container_abcs
import torch
TORCH_MAJOR = int(torch.__version__.split('.')[0])
TORCH_MINOR = int(torch.__version__.split('.')[1])
if TORCH_MAJOR == 1 and TORCH_MINOR < 8:
from torch._six import container_abcs
else:
import collections.abc as container_abcs
报错3:
File “/home/8TDisk/wangjl/condaEnv/mmlab/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py”, line 430, in _get_default_group
"Default process group has not been initialized, "
RuntimeError: Default process group has not been initialized, please make sure to call init_process_group.
修改 /SegFormermaster/mmseg/apis/train.py 文件如下
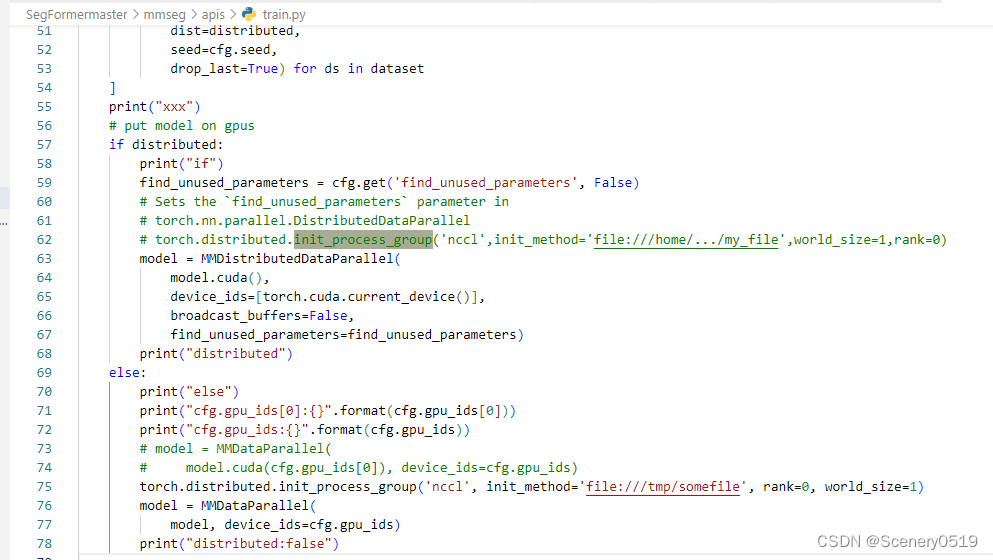
代码如下:
if distributed:
print("if")
find_unused_parameters = cfg.get('find_unused_parameters', False)
# Sets the `find_unused_parameters` parameter in
# torch.nn.parallel.DistributedDataParallel
# torch.distributed.init_process_group('nccl',init_method='file:///home/.../my_file',world_size=1,rank=0)
model = MMDistributedDataParallel(
model.cuda(),
device_ids=[torch.cuda.current_device()],
broadcast_buffers=False,
find_unused_parameters=find_unused_parameters)
print("distributed")
else:
print("else")
print("cfg.gpu_ids[0]:{}".format(cfg.gpu_ids[0]))
print("cfg.gpu_ids:{}".format(cfg.gpu_ids))
# model = MMDataParallel(
# model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)
torch.distributed.init_process_group('nccl', init_method='file:///tmp/somefile', rank=0, world_size=1)
model = MMDataParallel(
model, device_ids=cfg.gpu_ids)
print("distributed:false")
如果报这个错:
RuntimeError: open(/tmp/somefile): Permission denied
已放弃 (核心已转储)
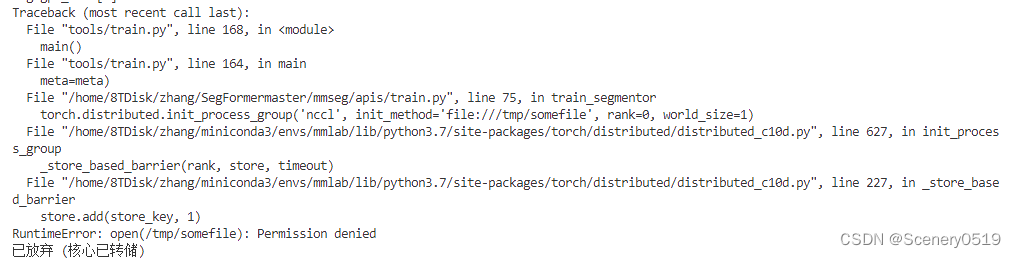
说明:‘file:///tmp/somefile’ 这个文件没有访问权限
换一个地址就可以了。
报错4:
File “/condaEnv/mmlab/lib/python3.7/site-packages/mmcv/runner/hooks/logger/text.py”, line "153, in _log_info
log_str += f’time: {log_dict[“time”]:.3f}, ’
KeyError: ‘data_time’
修改:
找到环境目录下
/condaEnv/mmlab/lib/python3.7/site-packages/mmcv/runner/hooks/logger/text.py 下文件,导入 time 库
import time
153行,做如下更改:
# log_str += f'time: {log_dict["time"]:.3f}, ' \
# f'data_time: {log_dict["data_time"]:.3f}, '
log_dict["data_time"] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_str += f'time: {
log_dict["time"]}, ' \
f'data_time: {
log_dict["data_time"]}, '
三、构造自己的 VOC 格式数据集
需要更改的文件或创建的文件:
- /SegFormermaster/local_configs/segformer/B0/segformer.b0.512x512.ade.160k.py
- /SegFormermaster/local_configs/_base_/datasets/pascal_voc12.py
- /SegFormermaster/local_configs/_base_/models/segformer.py
- /SegFormermaster/mmseg/datasets/voc.py
- /SegFormermaster/mmseg/datasets/_init_.py
- /SegFormermaster/mmseg/core/evaluation/class_names.py
1、segformer.b0.512x512.ade.160k.py
目录:/SegFormermaster/local_configs/segformer/B0/
参考文件:segformer.b0.512x512.ade.160k.py
新建自己的配置文件:segformer.b0.800x800.self.160k.py
修改:自己数据集的配置文件路径、类别数(num_classes)。
_base_ = [
'../../_base_/models/segformer.py',
'../../_base_/datasets/self_dataset.py', # 改这里,是自己的数据集配置文件路径,也就是下边2、改的文件路径
'../../_base_/default_runtime.py',
'../../_base_/schedules/schedule_160k_adamw.py'
]
# model settings
norm_cfg = dict(type= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5683
5683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









