







 通过Python编程从英语词典中筛选出符合中国燃油车牌命名规则的英语单词,转换为有趣的车牌号。
通过Python编程从英语词典中筛选出符合中国燃油车牌命名规则的英语单词,转换为有趣的车牌号。
以前在大街上看到一些有趣的车牌号,由于国家规定燃油车的车牌号没有字母I和O,用数字1、0代替,这样看来有些车牌号像个英语单词,我萌生出一个想法:从英语词典里找出符合车牌号命名规则的单词,看看有哪些更有趣的车牌号。现在用Python编程实现了我的想法。
第一步:先获取英语词典。
ntlk库集合了多个外语词典,下载词典的方法可以参照下面文章的教程:
首先,打开CMD用pip安装nltk
pip install nltk打开Python终端并输入以下内容来安装 NLTK 包:
import nltk
nltk.download()在弹出的下载对话框里有不少英语词典,我下载对比过几个词典,觉得corpus里面的Open English WordNet的词汇量比较多,下载它(网速很慢的话你需要scientifically上网),完成后会自动解压至C:\Users\Administrator\AppData\Roaming\nltk_data\corpora\wordnet。
第二步:筛选5~6位数的单词
燃油车牌(蓝牌)的命名规则是:序号中使用最多两位英文字母,其他位为阿拉伯数字,26个英文字母中I和O不能使用,用1和0代替。根据此规则,导入ntlk库的词典后进行筛选5~6位数的英语单词。
from nltk.corpus import wordnet
word_list = wordnet.words()运行这两行代码会报错:提示缺少资源库 omw-1.4。
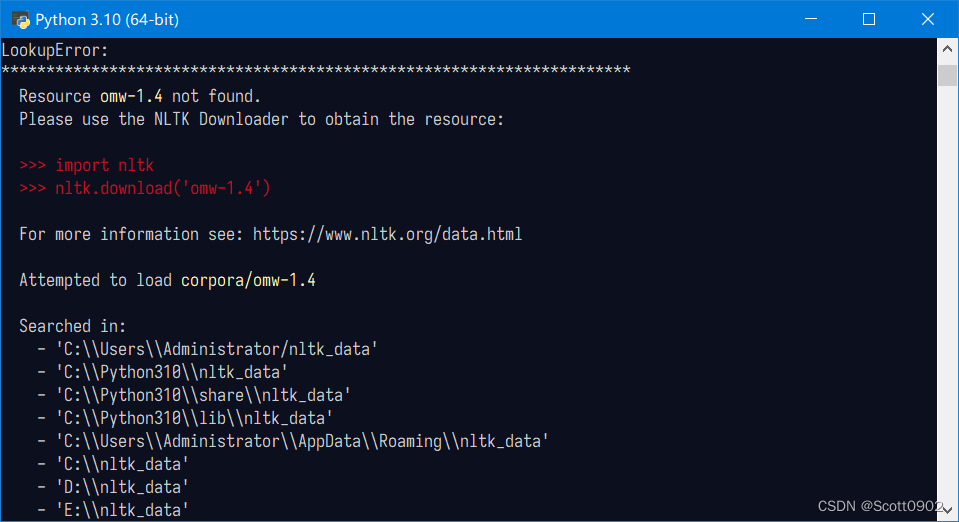
看来还得再下载这个 omw-1.4。按照其提示,运行代码:
import nltk
nltk.download('omw-1.4')之后再运行代码:word_list = wordnet.words()
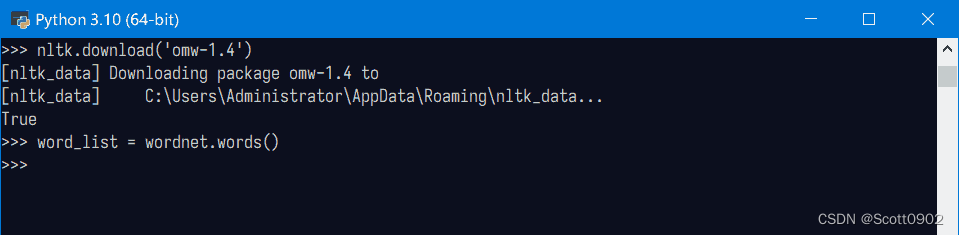
没有报错了,这样就加载了wordnet词典的单词到变量word_list里。此时尝试看看词库的词汇量,输入len(word_list),报错:该变量类型不能使用len()。输入type(word_list),显示word_list的类型是<class 'dict_keyiterator'>,是一个词典的迭代器。
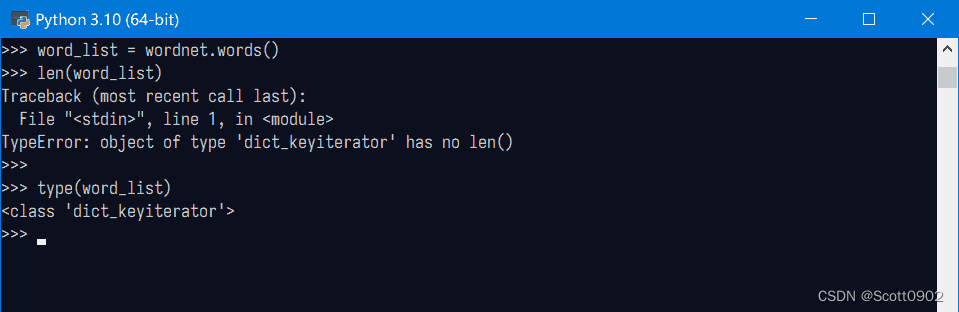
迭代器说明什么?原来词库并没有加载到内存中,凡是迭代器的东西必须使用for遍历访问它才会从中提取词库的单词。
from nltk.corpus import wordnet
word_list = wordnet.words()
# 读取词库,此时word_list的属性是词典的迭代器
# 需要for遍历访问才能真正读取单词
words = []
for i in word_list:
# 筛选5位、6位而且不带数字和符号的单词
# isalpha()是Python的字符串函数,只要字符串是纯英文字母才返回True值
if (len(i) == 5 or len(i) == 6) and i.isalpha():
words.append(i)
这样就筛选了5~6位的英语单词到words列表里,接下来:
第三步:替换字符并判断是否符合命名规则
Python常用的替换字符串语句是replace,但Python还有一个批量替换字符串的函数:maketrans()和translate(),使用示范:将英语单词的字母I改为数字1,字母O改为数字0:
intab = 'IO'
outtab = '10'
trantab = word.maketrans(intab, outtab)
trans_word = word.translate(trantab)
'''
例如输入word="BIOS"
返回的trans_word值是"B10S"
'''写一个子程序处理替换字符、判断是否符合规则:
def match_or_not(word):
# 设定批量替换字符的规则
intab = 'IO'
outtab = '10'
trantab = word.maketrans(intab, outtab)
trans_word = word.translate(trantab)
# 统计字母数,不超过两个字母才符合规定
alpha_count = 0
for s in trans_word:
if s.isalpha():
alpha_count += 1
if alpha_count <= 2:
return True, trans_word
else:
return False, ''
第四步:写一个完整的处理代码,输出符合规则的英语单词。
from nltk.corpus import wordnet
# 从5、6位数单词中找出有趣的车牌号
def find_interesting(words):
interesting = []
for i in words:
i = i.upper()
length = len(i)
if length == 5:
# 对5位数的单词进行判断,输出以“粤A”开头的车牌号
result = match_or_not(i)
if result[0]:
interesting.append(f'粤A {result[1].upper()}\t{i}')
else:
# 对6位数的单词,先从第2位字母判断,然后输出以“粤”开头的车牌号
result = match_or_not(i[1:])
if result[0]:
interesting.append(f'粤{i[0]} {result[1].upper()}\t{i}')
return interesting
def match_or_not(word):
# 设定批量替换字符的规则
intab = 'IO'
outtab = '10'
trantab = word.maketrans(intab, outtab)
trans_word = word.translate(trantab)
# 统计字母数,不超过两个字母才符合规定
alpha_count = 0
for s in trans_word:
if s.isalpha():
alpha_count += 1
if alpha_count <= 2:
return True, trans_word
else:
return False, ''
if __name__ == '__main__':
word_list = wordnet.words()
# 读取词库,此时word_list的属性是词典的迭代器
# 需要for遍历访问才能真正读取单词
words = []
for i in word_list:
# 筛选5位、6位而且不带数字和符号的单词
if (len(i) == 5 or len(i) == 6) and i.isalpha():
words.append(i)
interesting = find_interesting(words)
for i in interesting:
print (i)
运行结果:
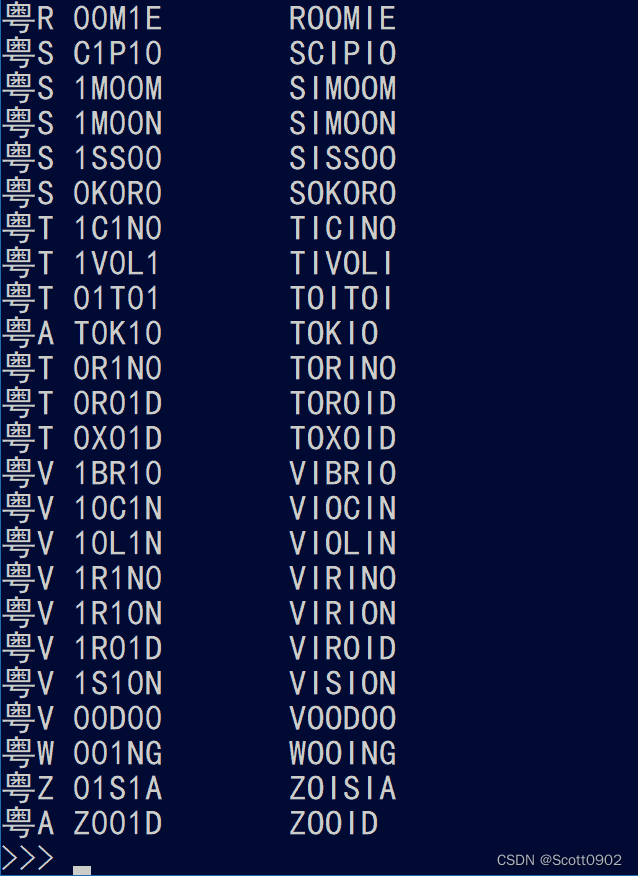
从中可以找到一些有意思的车牌号,比如:
C00K1E (COOKIE,曲奇)
1D10T (IDIOT,傻瓜)
B1K1N1 (BIKINI,比基尼)
M1N10N (MINION,小黄人)
0N10N (ONION,洋葱)
P01S0N (POISON,毒)
V10L1N (VIOLIN,小提琴)
K0S0V0 (KOSOVO,科索沃)
D0M1N0 (DOMINO,多米诺)
如果扩展一下替换字符的范围,如字母L改为1,B改为8,S改为5,把其中的替换字符规则代码修改一下:
intab = 'IOLBS'
outtab = '10185'输出的结果将更多更有趣。
现实中,车管所对自定义车牌号可能有所限制,如限定某位数只能是数字,或者只能是某个字母范围。因此本文纯属娱乐。

















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









