









Pyhton学习笔记01
环境安装

百度搜索上述三个软件,官网下载即可。
IDE用的pycharm,官网可以下载社区版和专业版,我直接用的别人给我发的文件就没找了,专业版收费需要激活,网上有教程,也可以某宝直接购买。
Anaconda配合pycharm使用,因为刚开始学对开发环境这些不是很在意,尽快能够上手写python即可,安装过程也是下一步下一步,

看了下安装说明 大概翻译过来就是用Anaconda带的python3.6作为IDE默认的python系统

安装后进入目录 查看一下包


网课上说需要更新所有python的依赖包,conda update -all命令更新所有包,因为一般初次安装的包都比较老,为避免报错,更新所有的包 。这一步感觉下包的速度太慢了,我属于每次开电脑就把这个更新给挂着,后面出问题再说吧,暂时使用没问题
打开pycharm配合使用Anconda

新建项目,配置环境




根据图片一步一步来就是了,看英文大概也能理解作用。
pycharm和python的安装就不写了,网上教程很多。


配好后 就可以直接在pycharm上运行python文件了
1.python基础语法
1.1 变量
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
变量由程序运行时实际变量赋的变量,决定变量的类型,也就是说类型取决于关联对象
变量申明需要赋值
counter =100
name = 'asd'
miles = 100.25
print(counter)
print(name)
print(miles)
100
asd
100.25
变量定义常见规则
- 包含字母数字下划线
- 只能以字母或下划线开头
- 不能有空格
- 避免与python关键字或函数重复,如print
- 简短有描述性
- 区分1,l,0,0
python中变量是指向对象的,对象会在内存中占位置,可用id进行查看
print(id(miles))
print(id(name))
3150459131296
3150411228584
python中对象引用举例

1.2 数据类型
1.2.1 数字(Number)
整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。
注意:256以下的整数对象在内存中是默认创建的
创建格式
num1 =14
num2 =14
print(id(num1))
print(id(num2))
140710953915616
140710953915616
浮点型(float,decimal) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
boolean型和int型
python中的boolean型也是int型一种
True代表1
false代表0
1.2.2 字符串(str)
是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 " )来创建字符串。
var1 = 'Hello World!'
var2 = "Runoob"
1.2.3 列表(list)
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'Runoob', 1997, 2000];
list2 = [1, 2, 3, 4, 5 ];
list3 = ["a", "b", "c", "d"];
1.2.4 元组(tuple)
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
tup1 = ('Google', 'Runoob', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d"; # 不需要括号也可以
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用:

1.2.5 字典(dit)
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中
创建格式:
d = {key1 : value1, key2 : value2 }
定义一个字典
dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print ("dict['Name']: ", dict['Name'])
print ("dict['Age']: ", dict['Age'])
dict['Name']: Runoob
dict['Age']: 7
1.2.6 集合(set)
集合是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合总结
集合包括
序列(str,list),主要区别在是否可变
映射(dict)
集合(set)
1.2.7 文件
假设我们本机上有一个文件data,.txt
我们新建一个变量指向一个对象由这个对象链接这个文件操作。
基本语法
file = open(‘文件名’,mode(操作参数))
mode常见参数r,w,a
写和读文件用的都是open这个方法
例如创建一个文件变量 对hello.txt对象进行写(w)操作

我是在IDLE里敲的代码,因此默认生成在了我的当前项目文件夹下
给文件对象进行写操做

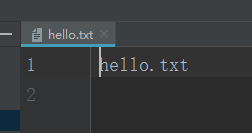
默认是读操作可以不用写
myfile = open('hello.txt','w')
myfile.write("hello.txt\n")
myfile.close()
f = open('hello.txt')
line2 = f.read()
line = f.readline()
print("content:"+line+"class:"+str(type(line)))
print("line2content:"+line2+"class:"+str(type(line2)))
运行效果
content:class:<class 'str'>
line2content:hello.txt
class:<class 'str'>
注意到第二次阅读为空,因为read方法相当于指针,使用一次后已经阅读到了文件的最后
向文件中追加内容
f = open('course.txt','w',encoding='utf8')
x,y,z = 1,2,3
l = [1,2,3]
f.write("{},{},{}".format(x,y,z))
f.close()
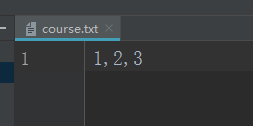
向文件中追加列表内容

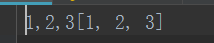
加入文件编码方式,防止乱码,python3默认unicod编码
参数说明:
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
pickle模块
进行序列化操作,各大语言都有序列化数据的方式,方便存储读取
内存中的数据可能会发生变化,需要及时存到硬盘上,硬盘需要接受序列化的二进制文件,读取时进行反序列化的操作,恢复文件信息
关于序列化的相关知识https://www.jianshu.com/p/8cb5d2e06f2f
https://blog.csdn.net/weixin_42994592/article/details/82704581
简单理解
针对java:
序列化:将对象转化为二进制byte流的过程
反序列化:将二进制byte流转换为对象的过程
针对python:
从数据类型到字符串的过程叫序列化
从字符串到数据类型的过程叫反序列化
python提供了pickle模块对数据进行序列化和反序列化操作
将文件保存成pkl形式的文件,pkl文件是python里面保存文件的一种格式,如果直接打开会显示一堆序列化的东西。正确的操作方式是使用Pickle模块。Pickle模块将任意一个Python对象转换成一系统字节,这个操作过程叫做串行化对象。
例,对字典对象进行序列化操作存储到pkl文件中
d = {'a':1,'b':2}
f = open('datafile.pkl','wb')
import pickle
pickle.dump(d,f)#进行序列化操作
f.close()
print(open('datafile.pkl','rb').read())
f = open('datafile.pkl','rb')
data = pickle.load(f)#反序列化操作
print(str(data)+str(type(data))+"\n"+str(data.get('a'))+str(type(data.get('a'))))
b'\x80\x03}q\x00(X\x01\x00\x00\x00aq\x01K\x01X\x01\x00\x00\x00bq\x02K\x02u.'
{'a': 1, 'b': 2}<class 'dict'>
1<class 'int'>
可以看到序列化操作后数据类型,再进行反序列化操作,读取到了字典数据
'''
逐行读取一段文件
'''
file2 = open('file2.txt','w')
file2.write('第一行文字\n')
file2.write('第二行文字\n')
file2.write('第三行文字\n')
file2.close()
file2r=open('file2.txt').readlines()
print(file2r)
for i in file2r:
print(i+str(type(i)))
['第一行文字\n', '第二行文字\n', '第三行文字\n']
第一行文字
<class 'str'>
第二行文字
<class 'str'>
第三行文字
<class 'str'>
json模块
python可调用方法及命令
函数function
生成器Generator
类class
输出输入格式化
str.format()
基本使用如下
print('{}网址: "{}!"'.format('菜鸟教程', 'www.runoob.com'))
菜鸟教程网址: "www.runoob.com!"
括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换。
在括号中的数字用于指向传入对象在 format() 中的位置,如下所示:
>>> print('{0} 和 {1}'.format('Google', 'Runoob'))
Google 和 Runoob
>>> print('{1} 和 {0}'.format('Google', 'Runoob'))
Runoob 和 Google
其他
str(): 函数返回一个用户易读的表达形式。
repr(): 产生一个解释器易读的表达形式。















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









