







本笔记为阿里云天池龙珠计划SQL训练营的学习内容,链接为:https://tianchi.aliyun.com/specials/promotion/aicampsql
阿里天池——SQL训练营学习随记
数据库相关概念
- 数据库(Database,DB)是将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合。
- 数据库管理系统(Database Management System,DBMS)是用来管理数据库的计算机系统
- 数据库系统的种类
- 层次数据库(Hierarchical Database,HDB)
- 关系数据库(Relational Database,RDB)
- 面向对象数据库(Object Oriented Database,OODB)
- XML数据库(XML Database,XMLDB)
- 键值存储系统(Key-Value Store,KVS),举例:MongoDB
- RDBMS的常见系统结构:客户端 / 服务器类型(C/S类型)

- 阿里云MySQL服务器的使用
阿里云MySQL服务器使用介绍
SQL核心语句
- DDL(Data Definition Language,数据定义语言) 用来创建或者删除存储数据用的数据库以及数据库中的表等对象。DDL 包含以下几种指令。
- CREATE : 创建数据库和表等对象
- DROP : 删除数据库和表等对象
- ALTER : 修改数据库和表等对象的结构
- DML(Data Manipulation Language,数据操纵语言) 用来查询或者变更表中的记录。DML 包含以下几种指令。实际使用的 SQL 语句当中有 90% 属于 DML
- SELECT :查询表中的数据
- INSERT :向表中插入新数据
- UPDATE :更新表中的数据
- DELETE :删除表中的数据
- DCL(Data Control Language,数据控制语言) 用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对 RDBMS 的用户是否有权限操作数据库中的对象(数据库表等)进行设定。DCL 包含以下几种指令。
- COMMIT : 确认对数据库中的数据进行的变更
- ROLLBACK : 取消对数据库中的数据进行的变更
- GRANT : 赋予用户操作权限
- REVOKE : 取消用户的操作权限
- 语法书写规范
- SQL 不区分关键字的大小写,但是插入到表中的数据是区分大小写的
- win 系统默认不区分表名及字段名的大小写
- linux / mac 默认严格区分表名及字段名的大小写
- 时间的表达方式
'26 Jan 2010', '10/01/26', '2010-01-26'
数据库和表的创建
- 数据库的创建
CREATE DATABASE <数据库名称>;
- 表的创建
CREATE TABLE < 表名 >
( < 列名 1> < 数据类型 > < 该列所需约束 > ,
< 列名 2> < 数据类型 > < 该列所需约束 > ,
< 列名 3> < 数据类型 > < 该列所需约束 > ,
< 列名 4> < 数据类型 > < 该列所需约束 > ,
.
.
.
< 该表的约束 1> , < 该表的约束 2> ,……);
【例】
CREATE TABLE product(
product_id CHAR(4) NOT NULL, --NOT NULL表示不得为空
product_name VARCHAR(100) NOT NULL, -- 可变长字符串
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER,
purchase_price INTEGER,
regist_date DATE, --日期
PRIMARY KEY(product_id)
);
形成表如下:

- 命名规则
- 只能使用半角英文字母、数字、下划线(_)作为数据库、表和列的名称
- 名称必须以半角英文字母开头
- 数据类型
- INTEGER :用来指定存储整数的列的数据类型(数字型),不能存储小数。
- CHAR :用来存储定长字符串,当列中存储的字符串长度达不到最大长度的时候,使用半角空格进行补足,由于会浪费存储空间,所以一般不使用。
- VARCHAR(M):表示可变长字符串,最长为M个字符,相比于CHAR格式更节省储存空间,详情看:VARCHAR有最大长度吗
- DATE:用来指定存储日期(年月日)的列的数据类型(日期型)
- 约束的设置
- NOT NULL是非空约束,即该列必须输入数据。
- PRIMARY KEY是主键约束,代表该列是唯一值,可以通过该列取出特定的行的数据。
表的删除和更新
【ALTER TABLE 语句和 DROP TABLE 语句一样,执行之后无法恢复。误添的列可以通过 ALTER TABLE 语句删除,或者将表全部删除之后重新再创建。】
- 删除表DROP
DROP TABLE < 表名 >;
DROP TABLE IF EXISTS productins;-- 如果表存在,删除
- 添加列ALTER–ADD COLUMN
ALTER TABLE < 表名 > ADD COLUMN < 列名 >< 数据类型 > < 该列所需约束 >;
-- 比如
ALTER TABLE product ADD COLUMN product_name_pinyin VARCHAR(100);
ALTER TABLE product ADD COLUMN product_value DEFAULT 0; -- 默认值为0
- 删除列
ALTER–`DROP COLUMN
ALTER TABLE < 表名 > DROP COLUMN < 列名 >;
- 清空表内容TRUNCATE
相比drop/delete,truncate用来清除数据时,速度最快。
TRUNCATE TABLE < 表名 >;
- 更新数据UPDATE
- 基本语法
UPDATE <表名>
SET <列名> = <表达式> [, <列名2>=<表达式2>...];
WHERE <条件>; -- 可选,非常重要。
ORDER BY 子句; --可选
LIMIT 子句; --可选
- 使用 update 时要注意添加 where 条件,否则将会将所有的行按照语句修改
-- 修改所有的注册时间
UPDATE product
SET regist_date = '2009-10-10';
-- 仅修改部分商品的单价
UPDATE product
SET sale_price = sale_price * 10
WHERE product_type = '厨房用具';
- NULL清空和多列操作
UPDATE product
SET regist_date = NULL
sale_price = NULL
WHERE product_id = '0008';
数据的插入
- 基本语法
INSERT INTO <表名> (列1, 列2, 列3, ……) VALUES (值1, 值2, 值3, ……);
- 对表进行全列 INSERT 时,可以省略表名后的列清单。
INSERT INTO productins
VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
- 大多数据库系统都支持一次插入多行,不过ORACLE语法不一样
-- DB2、SQL、SQL Server、 PostgreSQL 和 MySQL多行插入
INSERT INTO productins
VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11'),
('0003', '运动T恤', '衣服', 4000, 2800, NULL),
('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
-- Oracle
INSERT ALL
INTO productins VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11')
INTO productins VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL)
INTO productins VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20')
SELECT * FROM DUAL;
- INSERT … SELECT FROM语句复制其他表
INSERT INTO productions
SELECT * FROM products;
表操作练习
- 练习1
编写一条 CREATE TABLE 语句,用来创建一个包含表 1-A 中所列各项的表 Addressbook (地址簿),并为 regist_no (注册编号)列设置主键约束

CREATE TABLE Addressbook(
regist_no INTEGER NOT NULL,
name VARCHAR(128) NOT NULL,
address VARCHAR(256) NOT NULL,
tel_no CHAR(10),
mail_address CHAR(20),
PRIMARY KEY(regist_no));
- 练习2
假设在创建练习1.1中的 Addressbook 表时忘记添加如下一列 postal_code (邮政编码)了,请把此列添加到 Addressbook 表中。
列名 : postal_code
数据类型 :定长字符串类型(长度为 8)
约束 :不能为 NULL
ALTER TABLE addressbook ADD COLUMN postal_code CHAR(8) NOT NULL;
- 练习3
编写 SQL 语句来删除 Addressbook 表。
DROP TABLE addressbook;
- 练习4
编写 SQL 语句来恢复删除掉的 Addressbook 表。
答:删除后无法恢复
SQL基础中的部分要点
- 含有NULL时的真值
这时真值是除真假之外的第三种值——不确定(UNKNOWN)。一般的逻辑运算并不存在这第三种值。SQL 之外的语言也基本上只使用真和假这两种真值。与通常的逻辑运算被称为二值逻辑相对,只有 SQL 中的逻辑运算被称为三值逻辑。
- 聚合函数的注意事项
- COUNT函数的结果根据参数的不同而不同。COUNT(*)会得到包含NULL的数据行数,而COUNT(<列名>)会得到NULL之外的数据行数。
- 聚合函数会将NULL排除在外。但COUNT(*)例外,并不会排除NULL。
- MAX/MIN函数几乎适用于所有数据类型的列。SUM/AVG函数只适用于数值类型的列。
- 想要计算值的种类时,可以在COUNT函数的参数中使用DISTINCT。
- 在聚合函数的参数中使用DISTINCT,可以删除重复数据。
- 在数据量极大的情况下尽量不使用DISTINCT。大多数情况下,Distinct函数都会导致对最终结果集完成一次排序,因此,这就成为成本最昂贵的排序之一。Distinct一直是SQL语言中成本最高的函数之一。如果查询中包含Distinct,只要不会因此导致执行一个排序,这个查询可能也很高效。
- 聚合键中包含NULL时,会将NULL作为一组特殊数据进行处理。
视图view
- 视图的概念
- 视图是一个虚拟的表,不同于直接操作数据表,操作视图时会根据创建视图的SELECT语句生成一张虚拟表,然后在这张虚拟表上做SQL操作。
- 视图与表的区别—“是否保存了实际的数据”。
- 视图是原表的一个窗口,所以原表的修改透过它可以看到更新,它修改也只能修改透过窗口能看到的内容。
- 视图的作用
- 通过定义视图可以将频繁使用的SELECT语句保存以提高效率。
- 通过定义视图可以使用户看到的数据更加清晰。
- 通过定义视图可以不对外公开数据表全部字段,增强数据的保密性。
- 通过定义视图可以降低数据的冗余。
- 视图的创建
- 在一般的DBMS中定义视图时不能使用ORDER BY语句。这是因为视图和表一样,数据行都是没有顺序的。
- 在 MySQL中视图的定义是允许使用 ORDER BY 语句的,但是若从特定视图进行选择,而该视图使用了自己的 ORDER BY 语句,则视图定义中的 ORDER BY 将被忽略。
- SELECT 语句中列的排列顺序和视图中列的排列顺序相同。
CREATE VIEW <视图名称>(<列名1>,<列名2>,...)
AS
<SELECT语句>
- 视图的修改
修改视图不需要带上全部列名,新的窗口以AS后的SELECT语句为准。
ALTER VIEW <视图名> AS <SELECT语句>
ALTER VIEW productSum
AS
SELECT product_type, sale_price
FROM Product
WHERE regist_date > '2009-09-11';
- 视图的更新UPDATA—SET
- 对于一个视图来说,如果包含以下结构的任意一种都是不可以被更新的:
- 聚合函数 SUM()、MIN()、MAX()、COUNT() 等。
- DISTINCT 关键字。
- GROUP BY 子句。
- HAVING 子句。
- UNION 或 UNION ALL 运算符。
- FROM 子句中包含多个表。
- 视图归根结底还是从表派生出来的,因此,如果原表可以更新,那么 视图中的数据也可以更新。反之亦然。
- 创建视图时尽量使用限制不允许通过视图来修改表
- 对于一个视图来说,如果包含以下结构的任意一种都是不可以被更新的:
- 视图的删除DROP VIEW
DROP VIEW <视图名1> [ , <视图名2> …]
- 再次强调:视图是原表的一个窗口,所以原表的修改透过它可以看到更新,它修改也只能修改透过窗口能看到的内容。
子查询(略)
视图和子查询练习
- 练习1
创建出满足下述三个条件的视图(视图名称为 ViewPractice5_1)。使用 product(商品)表作为参照表,假设表中包含初始状态的 8 行数据。
条件 1:销售单价大于等于 1000 日元。
条件 2:登记日期是 2009 年 9 月 20 日。
条件 3:包含商品名称、销售单价和登记日期三列。
CREATE VIEW ViewPractice5_1(product_name, sale_price, regist_date)
AS
SELECT product_name,
sale_price,
regist_date
FROM product
WHERE sale_price >= 1000
AND regist_date = '2009-09-20'
LIMIT 8;
-
练习2
向习题一中创建的视图 ViewPractice5_1 中插入如下数据,会得到什么样的结果呢?
答:VIEW是一个虚拟表,相当于对于原表的一个窗口,只能修改窗口内的原表数据,不能向VIEW中添加数据 -
练习3(略)
-
练习4(略)
各种常用函数
算数函数
- ABS(数值)
NULL的绝对值为NULL - MOD(被除数,除数)
取余操作,相当于% - ROUND(m,n)
四舍五入,保留n位小数
字符串函数
CONCAT(str1,str2,str3)拼接函数LENGTH(str)字符串长度LOWER(str)/UPPER(str)大小写变换- REPLACE 替换
REPLACE( 对象字符串,替换前的字符串,替换后的字符串 ) - SUBSTRING 截取
SUBSTRING( 对象字符串 FROM 起始位置 FOR 截取长度 ) - SUBSTRING_INDEX按索引截取
SUBSTRING_INDEX( 对象字符串,分隔符,n)
n表示截取到第n个分隔符的位置(不含分隔符),正负表示方向
日期函数
CURRENT_TIMESTAMP等同于SYSDATE()
SELECT CURRENT_DATE; -- 2021-10-06
SELECT CURRENT_TIME; -- 10:05:30
SELECT CURRENT_TIMESTAMP; -- 2021-10-06 10:05:50 SYSDATE()
SELECT EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year,
EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month,
EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day,
EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour,
EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS MINute,
EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second;
转换函数
- CAST 类型转换
SELECT CAST('0001' AS SIGNED INTEGER); - COALESCE 将NULL值转换为其他值
COALESCE(expression,value1,value2,……,valuen)
MYSQL中等价于IFNULL(expression,value),即如果expression不为NULL,则返回expression,如果为NULL,则返回value。
对于COALESCE,如果value1还为NULL,则返回value2,以此类推。
谓词
- LIKE
%代表0个或多个字符,_代表1个字符
SELECT *
FROM samplelike
WHERE strcol LIKE '%d_d%'
- BETWEEN
BETWEEN m AND n,是闭区间,包含m和n - IS NULL/ IS NOT NULL
- IN/ NOT IN
需要注意的是,在使用IN 和 NOT IN 时是无法选取出NULL数据的。
实际结果也是如此,上述两组结果中都不包含进货单价为 NULL 的叉子和圆珠笔。 NULL 只能使用 IS NULL 和 IS NOT NULL 来进行判断。 - EXISTS/ NOT EXISTS
EXISTS和IN基本上可以代替,对比代码如下:
SELECT product_name, sale_price
FROM product
WHERE product_id IN (SELECT product_id
FROM shopproduct
WHERE shop_id = '000C');
SELECT product_name, sale_price
FROM product AS p
WHERE EXISTS (SELECT 1
FROM shopproduct AS sp
WHERE sp.shop_id = '000C'
AND sp.product_id = p.product_id);
- 由于
EXISTS只需要True OR False,因此SELECT 1替代SELECT * EXISTS需要用关联子查询联接两个表
CASE表达式
- 搜索CASE表达式
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
ELSE <表达式>
END
- 简单CASE表达式:功能有限,不能写判断式
CASE sex WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE NULL
END
- 实现列方向上的聚合函数
首先对比SUM,实现了行方向上的聚合
SELECT product_type,
SUM(sale_price) AS sum_price
FROM product
GROUP BY product_type;
+--------------+-----------+
| product_type | sum_price |
+--------------+-----------+
| 衣服 | 5000 |
| 办公用品 | 600 |
| 厨房用具 | 11180 |
+--------------+-----------+
3 rows in set (0.00 sec)
假如要在列的方向上展示不同种类额聚合值,可用SUM-CASE实现
SELECT SUM(CASE WHEN product_type = '衣服' THEN sale_price ELSE 0 END) AS sum_price_clothes,
SUM(CASE WHEN product_type = '厨房用具' THEN sale_price ELSE 0 END) AS sum_price_kitchen,
SUM(CASE WHEN product_type = '办公用品' THEN sale_price ELSE 0 END) AS sum_price_office
FROM product;
+-------------------+-------------------+------------------+
| sum_price_clothes | sum_price_kitchen | sum_price_office |
+-------------------+-------------------+------------------+
| 5000 | 11180 | 600 |
+-------------------+-------------------+------------------+
1 row in set (0.00 sec)
再比如,假设有如下图表的结构
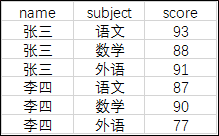
计划得到如下的图表结构,即行转列,则把需转置的列作为CASE中True的输出。
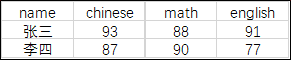
SELECT name,
SUM(CASE WHEN subject = '语文' THEN score ELSE NULL END) AS chinese,
SUM(CASE WHEN subject = '数学' THEN score ELSE null END) as math,
SUM(CASE WHEN subject = '外语' THEN score ELSE null END) as english
FROM score
GROUP BY name;
+------+---------+------+---------+
| name | chinese | math | english |
+------+---------+------+---------+
| 张三 | 93 | 88 | 91 |
| 李四 | 87 | 90 | 77 |
+------+---------+------+---------+
2 rows in set (0.00 sec)
注意:
- 当待转换列为数字时,可以使用SUM AVG MAX MIN等聚合函数;
- 当待转换列为文本时,可以使用MAX MIN等聚合函数
task3练习
- 练习1
运算或者函数中含有 NULL 时,结果全都会变为NULL ?
答:算数和字符串函数的运算都会变成NULL,聚合函数会忽略NULL。COALESCE函数用于NULL的转换 - 练习2
IN和NOT IN时是无法选取出NULL数据的。且尽量不要出现NULL,避免无法预知的后果。有NULL时,要用OR拆分IN的语句,并用IS NULL或IS NOT NULL进行判断。
SELECT product_name, purchase_price
FROM product
WHERE purchase_price NOT IN (500, 2800, 5000);
-- 错误写法
SELECT product_name, purchase_price
FROM product
WHERE purchase_price NOT IN (500, 2800, 5000, NULL);
--正确写法
SELECT product_name, purchase_price
FROM product
WHERE purchase_price != 500
OR purchase_price != 2800
OR purchase_price != 5000
OR purchase_price IS NOT NULL;
- 练习3
按照销售单价( sale_price)对练习 6.1 中的 product(商品)表中的商品进行如下分类。
低档商品:销售单价在1000日元以下(T恤衫、办公用品、叉子、擦菜板、 圆珠笔)
中档商品:销售单价在1001日元以上3000日元以下(菜刀)
高档商品:销售单价在3001日元以上(运动T恤、高压锅)
请编写出统计上述商品种类中所包含的商品数量的 SELECT 语句。
-- 用SUM函数和CASE表达式
SELECT SUM(CASE WHEN sale_price <= 1000 THEN 1 ELSE 0 END) AS low_price,
SUM(CASE WHEN sale_price BETWEEN 1001 AND 3000 THEN 1 ELSE 0 END) AS mid_price,
SUM(CASE WHEN sale_price >= 3001 THEN 1 ELSE 0 END) AS high_price
FROM product;
集合运算
UNION 并集
- UNION 会对两个查询的结果集进行合并和去重
- UNION ALL 合并但不去重
- 倘若要将两个不同的表中的结果合并在一起, 就不得不使用 UNION 了.
- bag 模型与 set 模型:Bag 是和 set 类似的一种数学结构, 不一样的地方在于: bag 里面允许存在重复元素, 如果同一个元素被加入多次, 则袋子里就有多个该元素。对于两个 bag, 他们的并运算会按照: 1.该元素是否至少在一个 bag 里出现过, 2.该元素在两个 bag 中的最大出现次数 这两个方面来进行计算. 因此对于
A = {1,1,1,2,3,5,7}, B = {1,1,2,2,4,6,8}两个 bag, 它们的并就等于{1,1,1,2,2,3,4,5,6,7,8}. - 隐式类型转换:即使数据类型不完全相同, 也会通过隐式类型转换来将两个类型不同的列放在一列里显示, 例如字符串和数值类型
其他集合
- INTERSECT 交集(MySQL不支持) 相当于IN、AND
- EXCEPT 差集(MySQL不支持)相当于NOT IN
- 对称差(异或)= (两个差集之和)
-- 使用 NOT IN 实现两个表的差集
SELECT *
FROM product
WHERE product_id NOT IN (SELECT product_id FROM product2)
UNION
SELECT *
FROM product2
WHERE product_id NOT IN (SELECT product_id FROM product)
连结JOIN
- 集合运算是行(上下)方向上的运算,连结是列方向的合并
- 连结、关联子查询和VLOOKUP:在思路上, 关联子查询更像是 vlookup 函数: 以表 A 为主表,然后根据表 A 的关联列的每一行的取值,逐个到表 B 中的关联列中去查找取值相等的行。当数据量较少时,这种方式并不会有什么性能问题。但数据量较大时,对于外部查询返回的每一行数据,都会向内部的子查询传递一个关联列的值,然后内部子查询根据传入的值执行一次查询然后返回它的查询结果。例如外部主查询的返回结果有一万行,那么子查询就会执行一万次,这将会带来非常恐怖的时间消耗。因此使用关联子查询时,子查询的表应为小的一方。
关于GROUP BY的ONLY_FULL_GROUP_BY
- 栗子:每个商店中, 售价最高的商品的售价分别是多少?
SELECT SP.shop_id
,SP.shop_name
,MAX(P.sale_price) AS max_price
FROMshopproduct AS SP
INNER JOINproduct AS P
ON SP.product_id = P.product_id
GROUP BY SP.shop_id,SP.shop_name
- 如何获取每个商店里售价最高的商品的名称和售价?
SELECT SP.shop_id
,SP.shop_name
,P.product_name
,MAX(P.sale_price) AS max_price
FROMshopproduct AS SP
INNER JOINproduct AS P
ON SP.product_id = P.product_id
GROUP BY SP.shop_id,SP.shop_name
结果发生报错sql_mode=only_full_group_by
原因是MySQL在5.7版本以上默认开启了ONLY_FULL_GROUP_BY,SELECT、HAVING以及ORDER BY后面的元素必须出现在GROUP BY后面。对于语义限制都比较严谨的多家数据库,如SQLServer、Oracled等数据库都不支持select target list中出现语义不明确的列,这样的语句在这些数据库中是会被报错的,所以从MySQL 5.7版本开始修正了这个语义,就是所说的ONLY_FULL_GROUP_BY语义。
因此,虽然说可以修改配置关闭only_full_group_by,但不建议使用。
解决方法是使用group_concat( [DISTINCT] 要连接的字段 [Order BY 排序字段 ASC/DESC] [Separator ‘分隔符’] )函数和SUBSTRING_INDEX(列名,截取分隔符,第几位)组合,先拼接字段并排序,然后截取第1个字段,就可以把“商店里售价最高的商品的名称”选出来啦。
SELECT SP.shop_id
,SP.shop_name
,SUBSTRING_INDEX(GROUP_CONCAT(P.product_name ORDER BY P.sale_price DESC),',',1)
,MAX(P.sale_price) AS max_price
FROM shopproduct AS SP
INNER JOIN product AS P
ON SP.product_id = P.product_id
GROUP BY SP.shop_id,SP.shop_name;
关于实际环境中需要查询出NULL值的情况
栗子:使用外连结从shopproduct表和product表中找出那些在某个商店库存少于50的商品及对应的商店,希望得到如下结果。
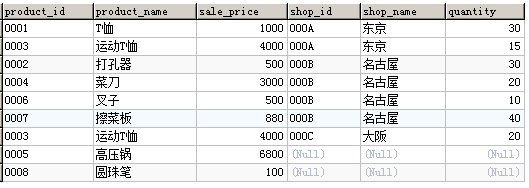
按照正常思路,会写出如下语句:
SELECT P.product_id
,P.product_name
,P.sale_price
,SP.shop_id
,SP.shop_name
,SP.quantity
FROM product AS P
LEFT OUTER JOIN shopproduct AS SP
ON SP.product_id = P.product_id
WHERE quantity< 50;
以上,返回结果会缺少在所有商店都无货的高压锅和圆珠笔。因此,要通过在WHERE过滤条件中增加OR quantity IS NULL的判断条件,得到预期结果。
但在实际环境中,由于数据量大且数据质量并非像我们设想的那样"干净",我们并不能容易地意识到缺失值等问题数据的存在。因此最好调整思路,先在shopproduct中找出所有数量少于50的商品,再进行外连结,即可得到答案。
SELECT P.product_id
,P.product_name
,P.sale_price
,SP.shop_id
,SP.shop_name
,SP.quantity
FROM product AS P
LEFT OUTER JOIN-- 先筛选quantity<50的商品
(SELECT *
FROM shopproduct
WHERE quantity < 50 ) AS SP
ON SP.product_id = P.product_id;
窗口函数
<窗口函数> OVER ([PARTITION BY <列名>] ORDER BY <排序用列名>)
PARTITON BY是用来分组,即选择要看哪个窗口,类似于GROUP BY子句的分组功能,但是PARTITION BY子句并不具备GROUP BY子句的汇总功能,并不会改变原始表中记录的行数。ORDER BY是用来排序,即决定窗口内,是按那种规则(字段)来排序的。ORDER BY子句也不会影响最终结果的排序。其只是用来决定窗口函数按何种顺序计算。- 原则上,窗口函数只能在
SELECT子句中使用。 - 常用窗口函数有两类:
- 将SUM、MAX、MIN等聚合函数用在窗口函数中
- RANK、DENSE_RANK等排序用的专用窗口函数
专用窗口函数,主要用于排序
* **RANK函数(英式排序)**
计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
(例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
* **DENSE_RANK函数(中式排序)**
同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
(例)有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
* **ROW_NUMBER函数**
赋予唯一的连续位次。
(例)有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位
SELECT product_name
,product_type
,sale_price
,RANK() OVER (ORDER BY sale_price) AS ranking
,DENSE_RANK() OVER (ORDER BY sale_price) AS dense_ranking
,ROW_NUMBER() OVER (ORDER BY sale_price) AS row_num
FROM product

配合聚合函数使用,主要用于累计
SELECT product_id
,product_name
,sale_price
,SUM(sale_price) OVER (ORDER BY product_id) AS current_sum
,AVG(sale_price) OVER (ORDER BY product_id) AS current_avg
,MAX(sale_price) OVER (ORDER BY product_id) AS current_avg
,MIN(sale_price) OVER (ORDER BY product_id) AS current_min
FROM product;
以上代码即按product_id排序后,输出该行以上累计的SUM、AVG、MAX、MIN的情况

用框架做移动平均
在上面提到,聚合函数在窗口函数使用时,计算的是累积到当前行的所有的数据的聚合。 实际上,还可以指定更加详细的汇总范围。该汇总范围成为框架(frame)。
<窗口函数> OVER (ORDER BY <排序用列名>
ROWS n PRECEDING )
<窗口函数> OVER (ORDER BY <排序用列名>
ROWS BETWEEN n PRECEDING AND n FOLLOWING)
-
ROWS PRECEDING(“之前”), 将框架指定为 “截止到之前 n 行”,加上自身行 -
ROWS FOLLOWING(“之后”), 将框架指定为 “截止到之后 n 行”,加上自身行 -
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING,将框架指定为 “之前1行” + “之后1行” + “自身” -
例如要做前后三行数据的移动平均,则
SELECT product_id
,product_name
,sale_price
,AVG(sale_price) OVER (ORDER BY product_id
ROWS BETWEEN 1 PRECEDING
AND 1 FOLLOWING) AS moving_avg
FROM product

ROLLUP - 计算合计及小计
常规的GROUP BY 只能得到每个分类的小计,有时候还需要计算分类的合计,可以用 ROLLUP关键字。
最简单的例子:
SELECT product_type
,regist_date
,SUM(sale_price) AS sum_price
FROM product
GROUP BY product_type, regist_date WITH ROLLUP

实际场景中可能遇到的例子,看这两个帖子
SQLSERVER 使用 ROLLUP 汇总数据,实现分组统计,总计(合计),小计
SQL Server中Rollup关键字使用技巧(统计功能)














 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









