






目录
简介:
KNN(k-Nearest Neighbor),也称K-近邻分类算法。分类的目的是学会一个分类器。该分类器能把数据映射到事先给定类别中的某一个类别。分类属于一种监督学习方式,分类器的学习是在被告知每一个训练样本属于哪个类别后进行的。每个训练样本都有一个特定的标签,与之相对应。在学习过程中,从这些给定的训练数据集中学习一个函数。等新的数据到来时,可以根据这个函数判断结果。
1 基本思路:
基本思路是,如果一个样本在特征空间中的k个最邻近样本中的大多数属于某一个类别,则该样本也属于这个类别,该算法在决定类别上只依据最近的一个或几个样本的类别来决定带分类样本所属的类别,kNN算法中所选择的邻居都是已经正确分类的对象。
2 算法流程:
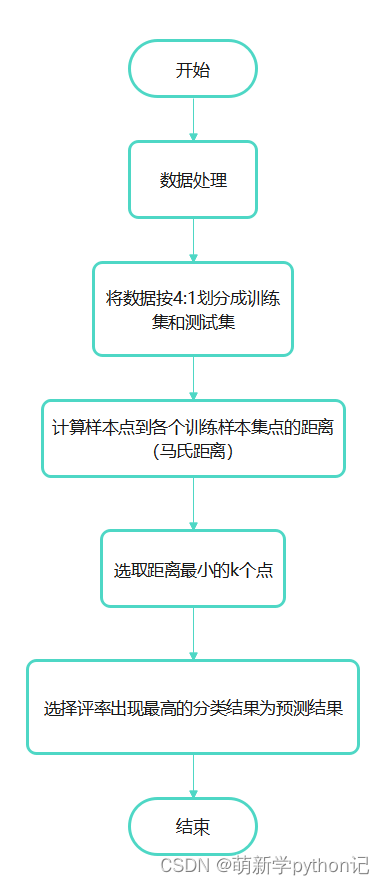
1. 算距离:给定测试对象,计算它与训练集中的每个对象的距离;
2. 找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻;
3. 做分类:根据这k个近邻归属的主要类别,来对测试对象分类。
流程图:
3 KNN代码Python实现:
3.1 K值的确定:
K值确定:
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#读取数据集
data = np.loadtxt('data.tzt', delimiter=',')
X = data[:,1:-1]
x= (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
y = data[:, -1]
k_range = range(1, 31)
k_error = []
#循环,取k=1到k=31,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
k_error.append(1 - scores.mean())
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel('Value of K for KNN')
plt.ylabel('Error')
plt.show()

由图可知当k=4时erros最小故针对该数据里采用KNN(k=4)进行分类预测。
3.2 KNN主程序:
主程序:
import numpy as np
from scipy.spatial.distance import cdist, mahalanobis
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class KNN:
def __init__(self, k=4):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
# 计算训练集的协方差矩阵和其逆矩阵
self.cov_mat = np.cov(X.T)
self.cov_mat_inv = np.linalg.inv(self.cov_mat)
def predict(self, X):
y_pred = [self._predict(x) for x in X]
return np.array(y_pred)
def _predict(self, x):
# 计算与训练集的距离矩阵
distances = cdist(x.reshape(1,-1),self.X_train, metric='mahalanobis', VI=self.cov_mat_inv)[0]
# 找到距离最近的k个样本的索引
k_indices = np.argsort(distances)[:self.k]
# 找出k个样本所属的类别
k_nearest_labels = [self.y_train[i] for i in k_indices]
# 返回出现频率最高的类别作为待分类样本的类别
most_common_label = max(set(k_nearest_labels), key=k_nearest_labels.count)
return most_common_label
# 生成数据集
data = np.loadtxt('data.tzt', delimiter=',')
X = data[:,1:-1]
X= (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
y = data[:, -1]
# 划分数据集为训练集和测试集
test_size = 0.2
train_size = 1 - test_size
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, train_size=train_size)
# 训练模型
knn = KNN(k=4)
knn.fit(X_train, y_train)
# 预测测试集并计算正确率
y_pred = knn.predict(X_test)
test_accuracy = accuracy_score(y_test, y_pred)
print(f'Test accuracy: {test_accuracy:.2f}')
# 预测训练集并计算正确率
y_pred = knn.predict(X_train)
train_accuracy = accuracy_score(y_train, y_pred)
print(f'Train accuracy: {train_accuracy:.2f}')
# 新样本的特征向量
x_new = np.array([0.51651,0.6354,0.00,0.2356,0.9653,0.00,0.5236,0.5701,0.00])
# 对新样本进行分类
y_new = knn.predict(x_new.reshape(1, -1))
print(f'New sample belongs to class {y_new[0]}')
















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









