






 文章讲述了作者在处理SSV2视频数据集时遇到的抽帧问题,包括使用ffmpeg进行抽帧操作,遇到的错误如乱码和无图片生成,以及解决方法——安装ffmpeg并配置环境变量。
文章讲述了作者在处理SSV2视频数据集时遇到的抽帧问题,包括使用ffmpeg进行抽帧操作,遇到的错误如乱码和无图片生成,以及解决方法——安装ffmpeg并配置环境变量。
关于我在处理ssv2数据集时候遇到的问题,真的挺糟心的,虽然都不么大毛病但是会搞人心态
一. 问题简单介绍
因为ssv2数据集都是视频,不像ssv1有现成的jpg图片,所以这里要对视频进行抽帧处理,网上主流的处理方法大概有两种:
第一种是csdn上up主——海苔眉毛提供的一种:
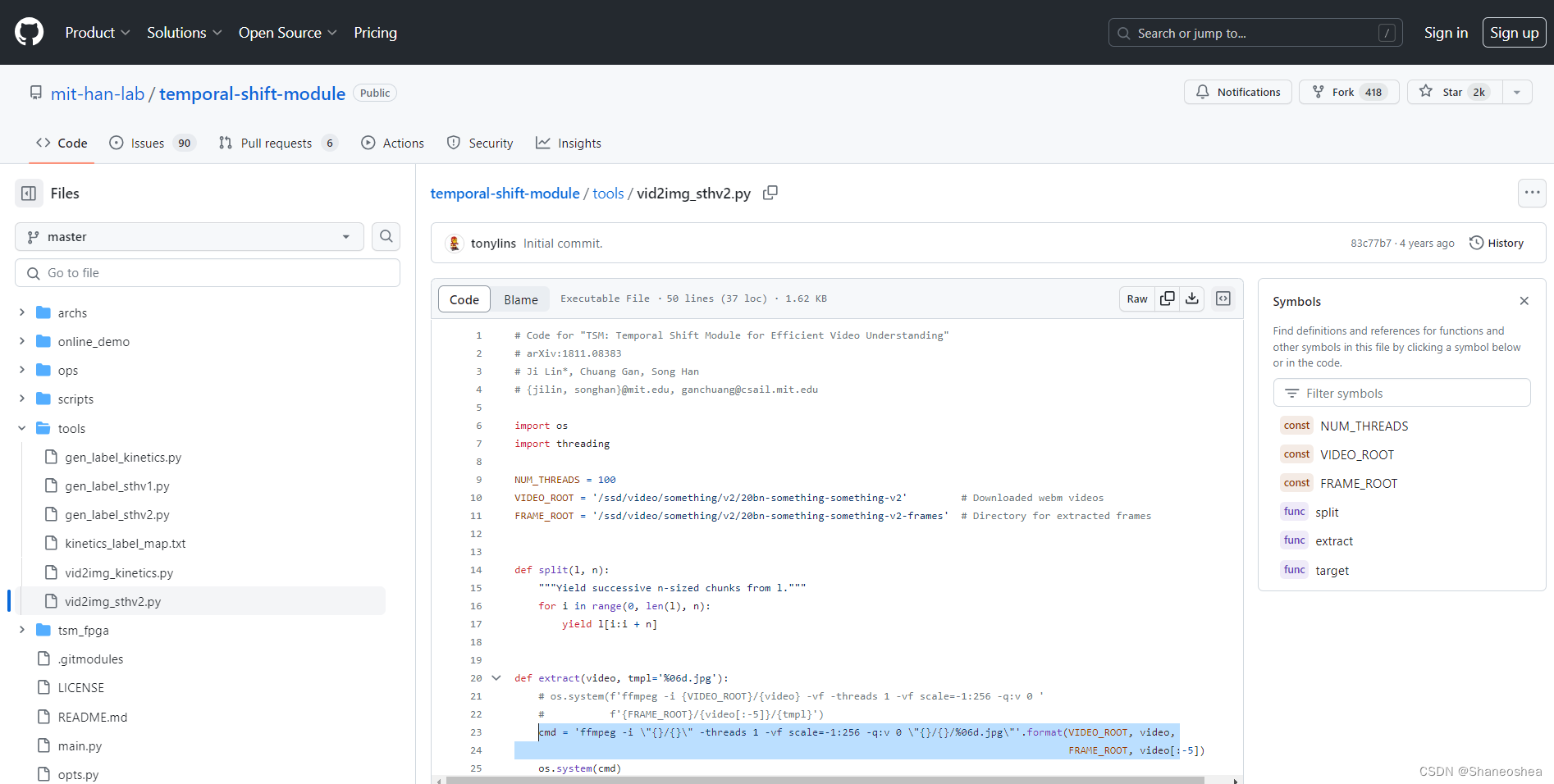
第二种是github上,TSM作者提供的一个数据集处理,不仅有ssv2抽帧的,还有后面划分的处理,还有k400和ssv1的数据集的处理过程,算是很详细了,这里挂个链接:
https://github.com/mit-han-lab/temporal-shift-module/blob/master/tools/vid2img_sthv2.py
两种方法都是用的ffmpeg来实现的,代码上大同小异,本人用的是第一种csdn上大佬的代码,改动了一个地方——加了一个帧率fps:每秒抽帧的数量。
原代码是:
except:
print(dst_directory_path)
continue
cmd = 'ffmpeg -i \"{}\" -vf scale=-1:240 \"{}/%06d.jpg\"'.format(video_file_path, dst_directory_path)
print(cmd)
subprocess.call(cmd, shell=True)
print('\n')
本人的是:
except:
print(dst_directory_path)
continue
cmd = 'ffmpeg -i \"{}\" -r 24 -vf scale=-1:240 \"{}/%06d.jpg\"'.format(video_file_path, dst_directory_path)
print(cmd)
subprocess.call(cmd, shell=True)
print('\n')增加了一个 -r 24 :表示每一秒抽出24帧
- i :要处理视频的文件路径
第一个 {} 里是待处理的webm格式的ssv2视频,不用转换成mp4,即后面video_file_path对应的值,第二个 {} 里是生成jpg图片存放的路径,即dst_directory_path对应的值
- vf :指定图像的宽度
scale = - 1:240 :按照视频的宽高比例自适应调整宽度,高度为 240 像素
(最后得到的实际大小是宽高为:427*240)

%06d.jpg:是抽帧的图片格式及名称,这里留了六位来命名,从000001开始
二. 具体的操作流程
数据集的下载和解压就不赘述了,可以参考大佬的做法,这里简单介绍下关于抽帧操作的问题,将代码复制过去保存为.py格式,然后新建一个存放抽帧后的jpg文件夹,如图,本人的ssv2视频文件夹为input_dir,存放图片的文件夹是img_ssv2,代码名是video_to_jpg.py
然后win + r ,cmd 回车,进入数据集所在目录,本人数据集在D盘,输入D: ,然后输入cd D:\文件\somethingV2即可进入指定目录,然后运行代码:
python 代码名.py dir_path dst_dir_pathpython与 .py 文件,输入路径与输出路径之间都有一个空格
dir_path:是待处理的webm格式的ssv2视频存放文件夹
dst_dir_path:是生成的jpg图片存放的文件夹
本人运行的是:
python video_to_jpg.py D:\文件\somethingV2\input_dir D:\文件\somethingV2\img_ssv2然后就可以看到运行过程了:跑得非常快,因为视频很多,有十几万条
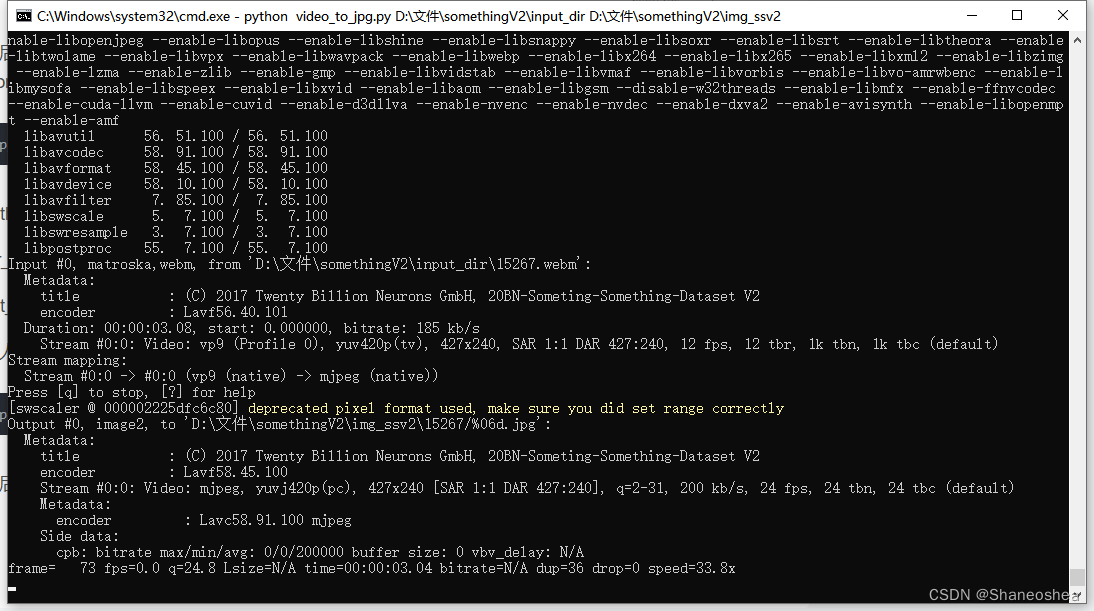
同时点开img_ssv2文件夹可以看到有生成对应的文件夹,文件夹里有抽好的帧
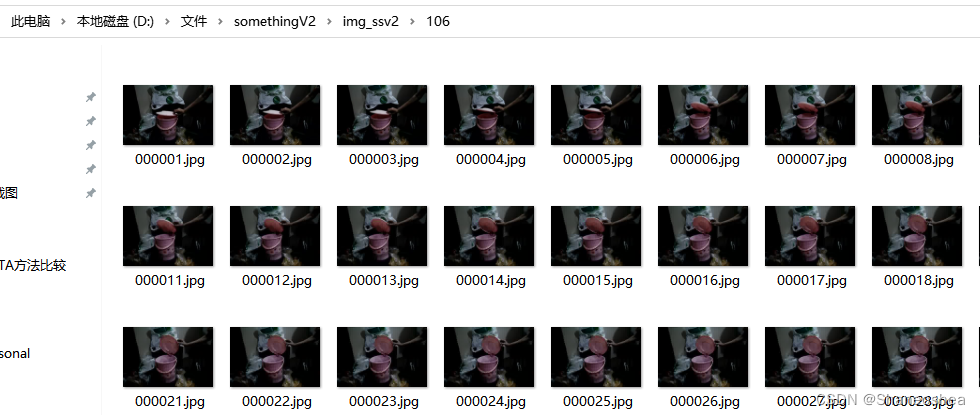
然后挂机等它跑完就行了,大概需要半天时间(实验室电脑上跑的,没用服务器,有点慢),本人两个小时成功搞出来3万多个。
三. 一些实施过程中具体的问题
在具体操作过程中也不是一帆风顺,还是遇到了很多问题,所以才想写个博客记录一下
1.在原up的评论区有小伙伴说最后生成的文件夹是空的,没有图片,本人也遇到了这个问题,简单说明一下:
在运行代码后出现了这样的bug:ffmpeg �����ڲ����ⲿ���Ҳ���ǿ����еij��� ���������ļ���
这串乱码其实是‘ffmpeg‘ 不是内部或外部命令,也不是可运行的程序这个问题,后面发现本人没有在电脑上安装ffmpeg,不是在pycharm里install一个package就够的,要去官网上找ffmpeg这个软件下载,win64的静态的压缩包,然后解压,配置环境变量
挂个链接:ffmpeg Old Versions Downloads - VideoHelp --- ffmpeg 旧版本下载 - 视频帮助
一定要下static的这个,下载后解压,然后找到bin文件夹,复制路径,
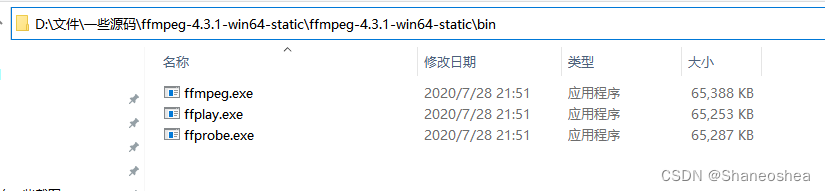
然后给它添加环境变量,在我的电脑,右键,属性,高级系统设置
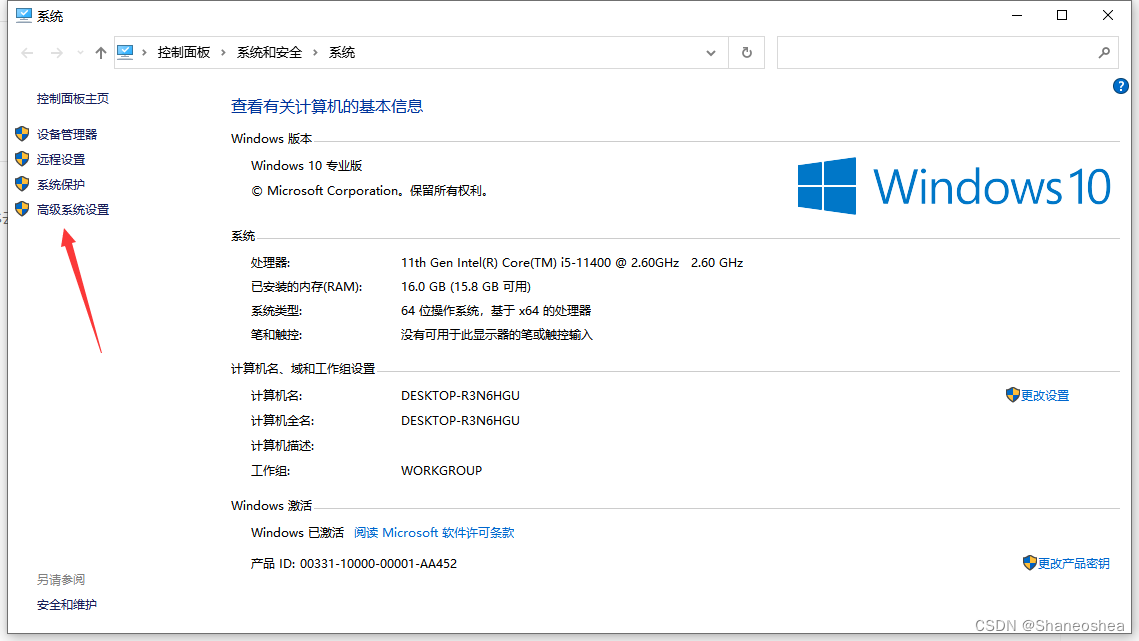
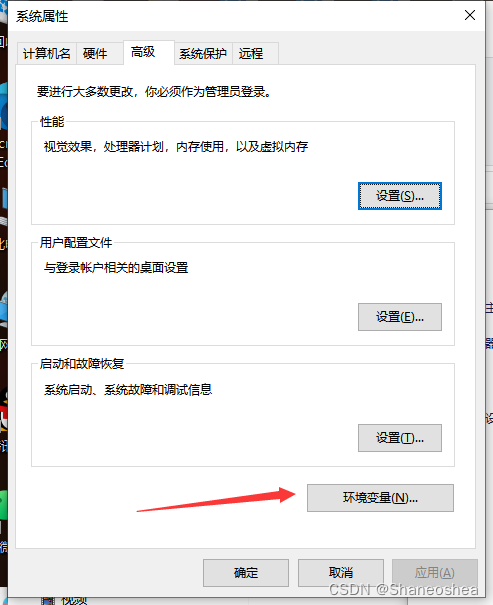
点击环境变量后,双击Path,进去新建环境变量
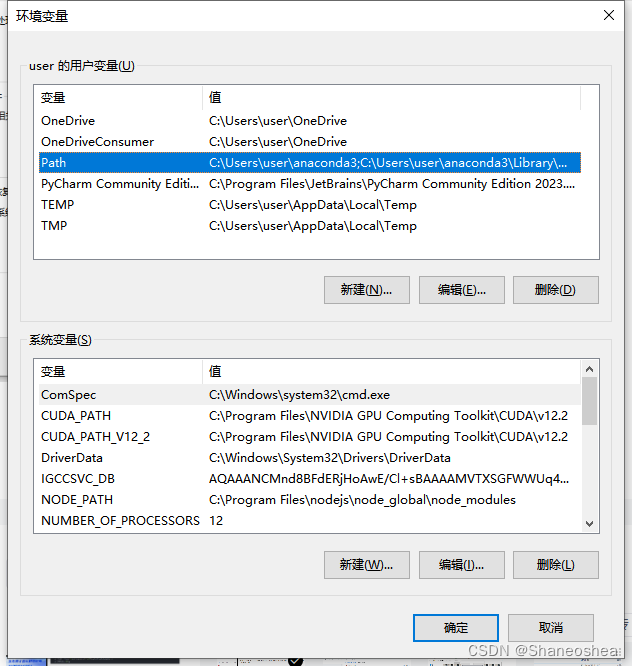
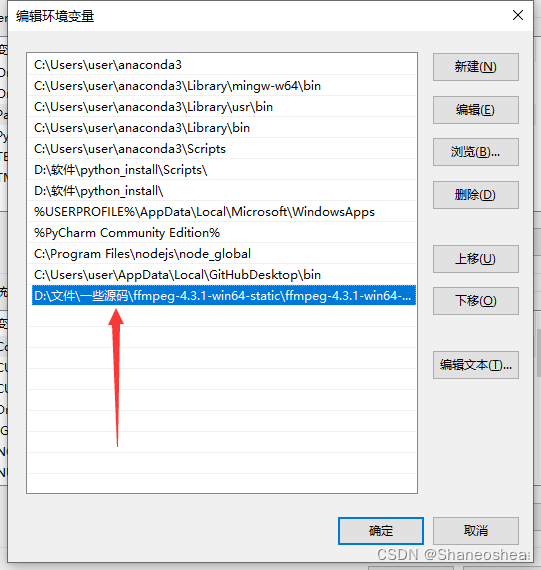
然后把刚才复制的bin路径粘贴过来就行了,然后确定即可
接着win+R,回车,输入ffmpeg -version,出现如图字段即说明环境变量配置成功
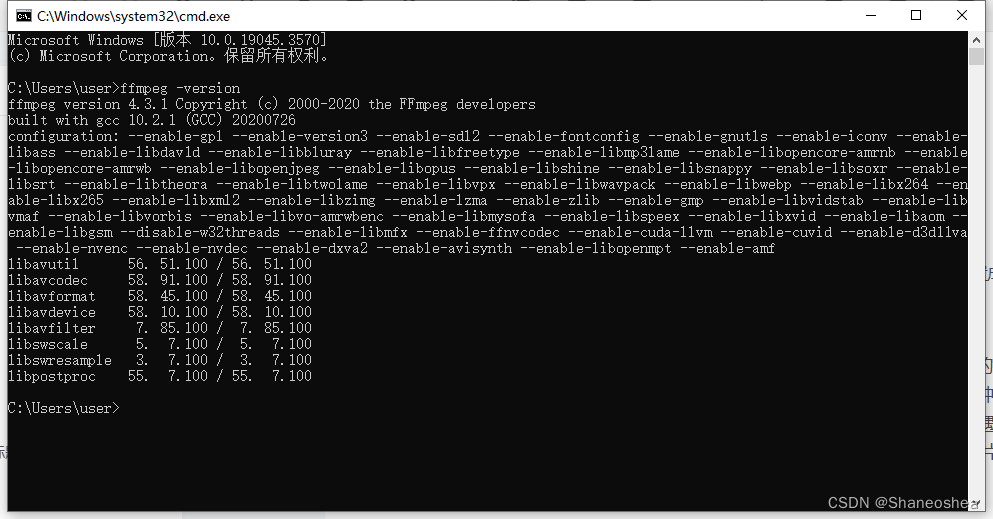
将这一步处理好之后,再运行刚才的抽帧代码就成功了,也没有再出现刚才的乱码情况。同样的问题,本人还遇到过一种,在没有进行ffmpeg环境变量配置的时候采取了第二种方式——github上TSM作者提供的抽帧代码,本人在实验室的服务器上运行这个代码的时候也遇到了问题,显示总线忙的问题,然后在img_ssv2的文件夹里有生成相应的文件夹但是里面没有图片。现在想来应该是没有配置ffmpeg 的环境变量导致的
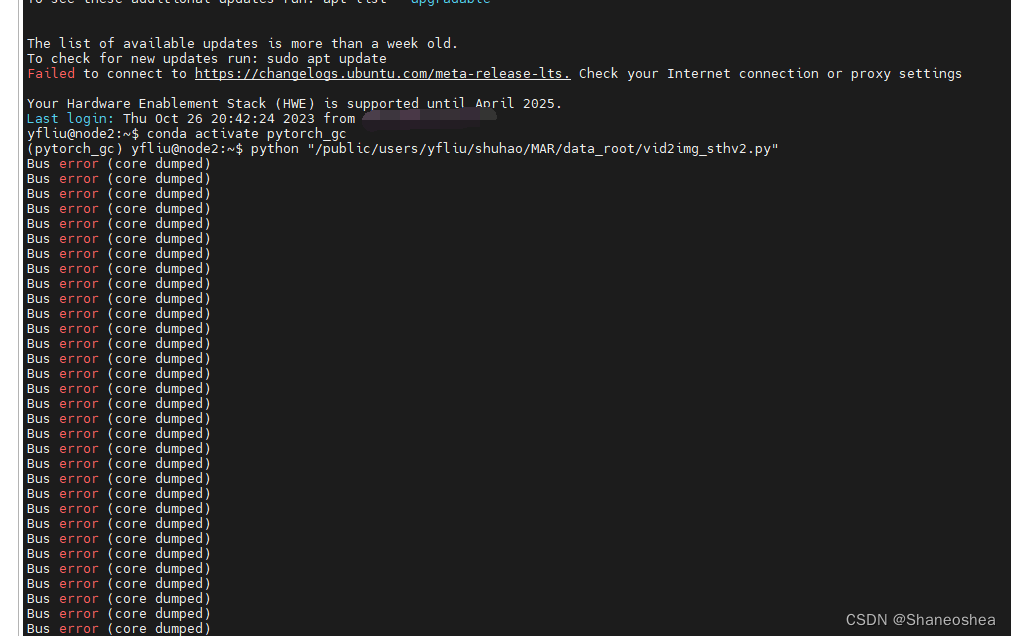
建议在开始尝试运行代码的时候,可以新建两个用来测试的文件夹,输入视频的文件夹里放3-5个webm视频就行了,然后用这个来测试是否成功,如果用ssv2的整个视频数据来测试的话最后可能会生成很多空文件夹,然后再运行代码的时候会出bug。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









