







动手学深度学习-李沐(视频):08 线性回归 + 基础优化算法【动手学深度学习v2】_哔哩哔哩_bilibili
动手学深度学习-李沐(网页):3. 线性神经网络 — 动手学深度学习 2.0.0 文档 (d2l.ai)
⭐这是jupyter与torch结合的笔记!!!
自从开始和数学有关的就已经精神不正常惹,所以说话有点抽象
而且感觉还有待补充
目录
1. 线性回归
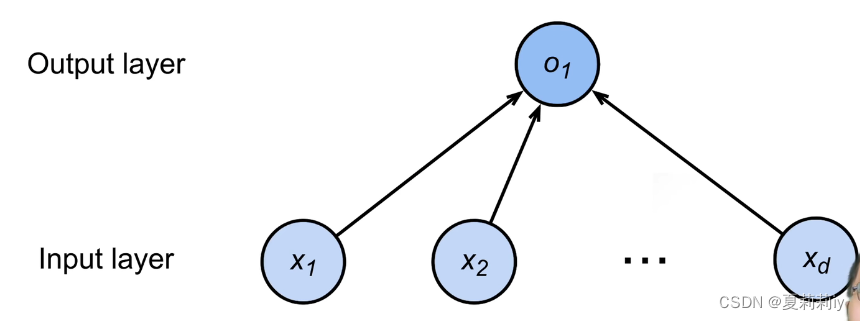
1.1. 线性模型
(1)线性模型可以看作是单层的神经网络
1.2. 损失函数
(1)常用的平方误差公式
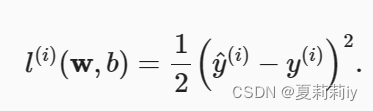
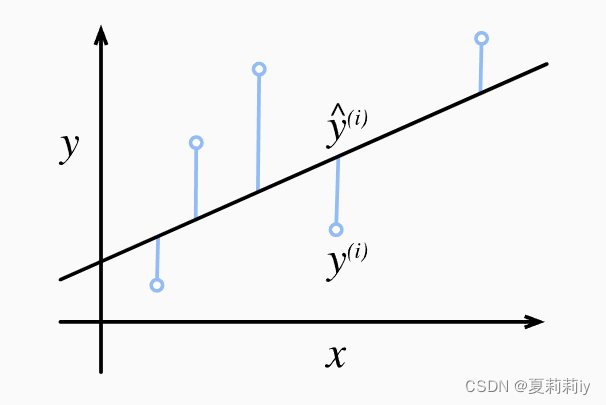
①公式里小写l只是一组y_hat和y的损失值
②但是很明显我们求出来的回归函数(那根黑线)离实际值(蓝色空心圆)有很多组都应该有差异
(2)整体损失均值
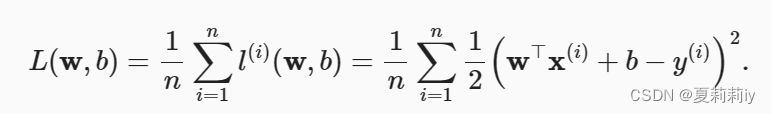
①这里大写L是所有的y和我们求出来的回归函数的误差的平均
②y_hat(我们回归函数的值)被替换成了wx+b
③前面那一大坨就是取平均值
④把括号里的倒一圈变成y-wx-b也没什么问题,反正是平方
⑤如果要写成向量的话就长成下面这个样子,可以省略掉Σ了

(3)这么看那条黑线和蓝点差异太大了,实际上我们不想要这么大的差异,不然很可能预测不准。因此要最小化整体均方误差(当每个点都被我们的回归函数穿过时均方误差就最小了!但是这样可能造成过拟合)
(4)很明显,这个L(w,b)的大小是由w和b决定的,而且L肯定>=0。于是我们希望找到一组w和b使得L尽可能小

(5)这个偏差加入权重,应该是

(6)然后l对w求导(展开求就好了)
①矩阵求导
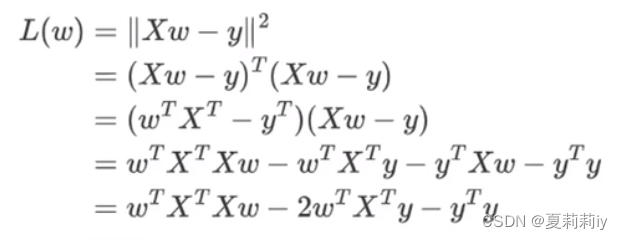
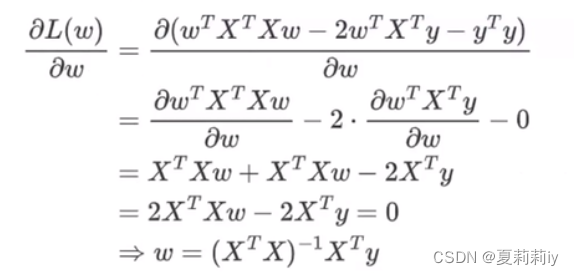
此时第二步到第三步采用了矩阵求导,即如下公式
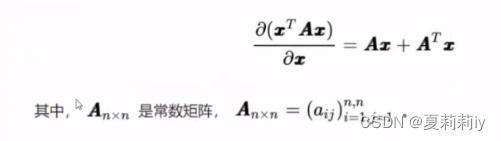
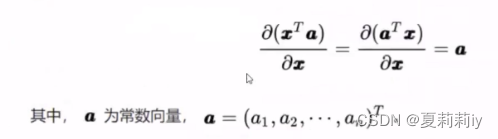
求导来源:可能是全网最详细的线性回归原理讲解!!!_哔哩哔哩_bilibili
②多项式求导
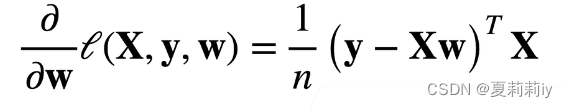
(7)显式解
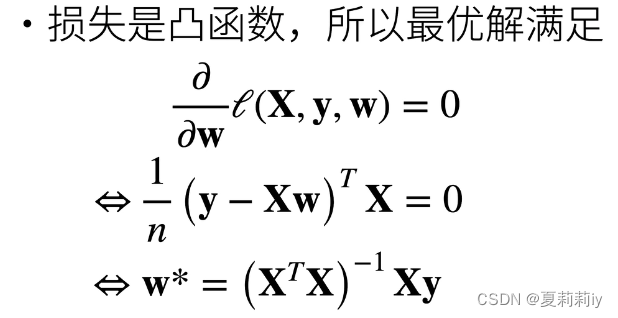
1.3. 梯度下降
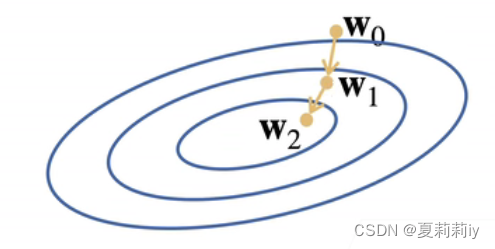
(1)当一个模型没有显式解的时候就要用梯度下降(我咋知道哪些有哪些没有)(是不是没有为0的时侯的意思?)
(2)所以先挑选一个w的随机初始值w0,然后不断更新,使得它接近最优解(这个η是学习率)

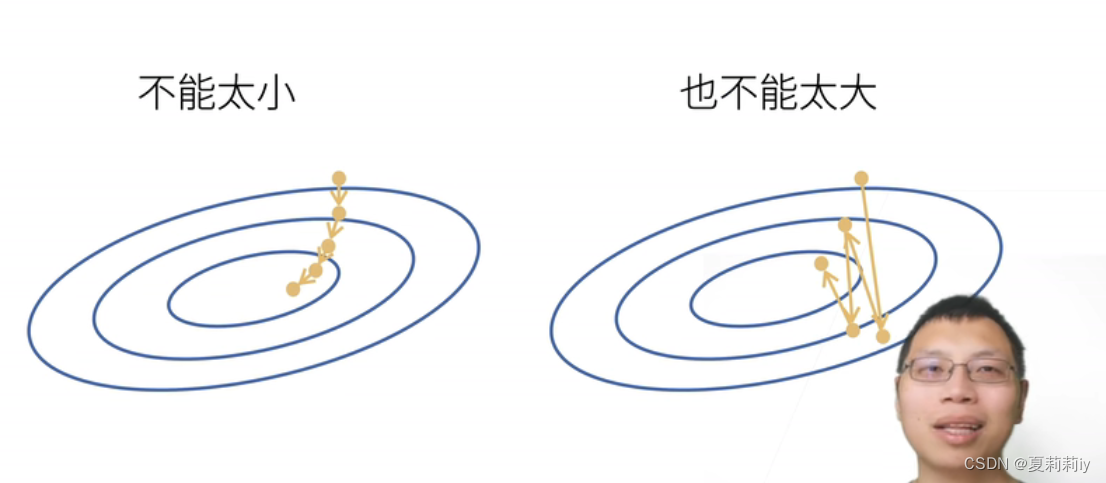
(3)学习率是超参数,是人为指定的值,它不能太小也不能太大(吴恩达那有细🔒)
(4)小批量随机梯度下降(深度学习用的多的)
①意思是如果我们的样本有几千亿个(我就随便说说),这个n实在是太大了,y和y_hat也需要取几千亿个,因此人为采用采用小批量的b(批量大小)来计算一个相对好的损失就好了
②公式(还是一样的惹)
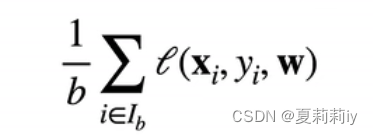
(5)随机梯度下降指的是这个批量的采样是随机的
①可以先把所有数据shuffle,然后再按批次取并取完(这样实际就是原来的那些点)。取不完的话扔掉也可以,再补随机的也可以
②也可以在全部数据里面随机取,这样可能取不完也可能取得完,但是影响不大
③记得每个batch做完之后梯度清零一下
1.4. 矢量化加速
(1)我觉得他想表达的意思就是,对于两个有一千个元素的列向量a和b,要实现a+b,用for循环一个元素一个元素加的速度比直接d=a+b慢得多
1.5. 正态分布与平方损失
(1)太闹心了,我cv了
(2)公式

2. 线性回归的从零开始实现
2.1. 自制数据集和回归
(1)完全是自制随机数据集→写函数→训练这样,可以参考书
3. 线性回归的简洁实现
3.1. 导入data简洁实现
(1)导入包
from torch.utils import data
from torch import nn(2)nn可以带来预定义好的层
(3)相当于不用手动定义函数
4. Softmax回归
4.1. 分类
(1)分类实际上就是从回归的单输出变成了多输出(预测概率)
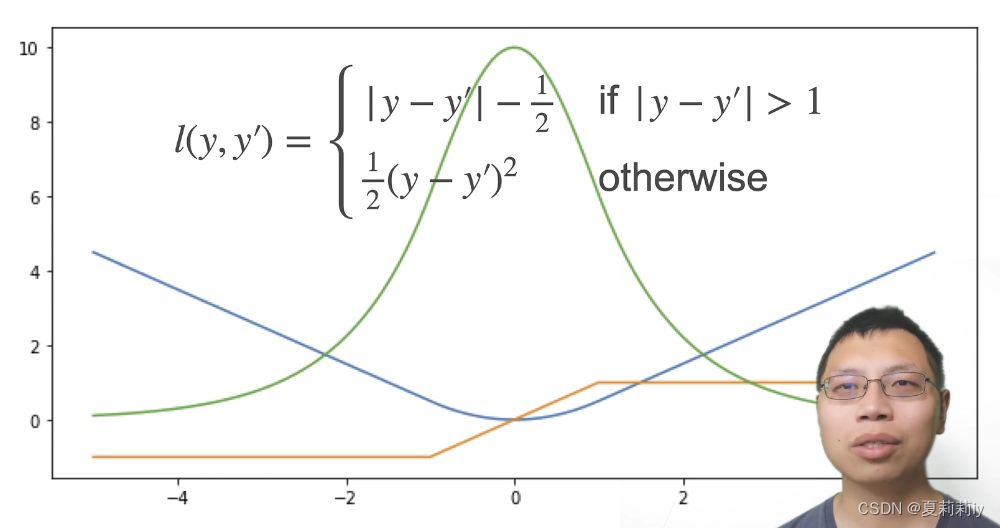
4.2. 损失函数
(蓝色是曲线,绿色线是似然函数,橙色是导数)
(1)均方损失
(2)绝对值损失函数
(3)Huber's Robust loss
5. 图像分类数据集
5.1. 导库
(1)代码
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()5.2. 读取数据集
(1)代码
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)6. Softmax回归的从零开始实现
6.1. 导库
(1)代码
import torch
"""主要是加了这个IPython"""
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)7. Softmax回归的简洁实现
7.1. 上溢
(1)可能分母在累积的时候变得过于大了,因为计算机存储的原理会变成0或NaN

(2)在减法和规范化步骤之后,可能有些具有较大的负值。 由于精度受限,将有接近零的值,即下溢(underflow)。 这些值可能会四舍五入为零,于是可以采用以下
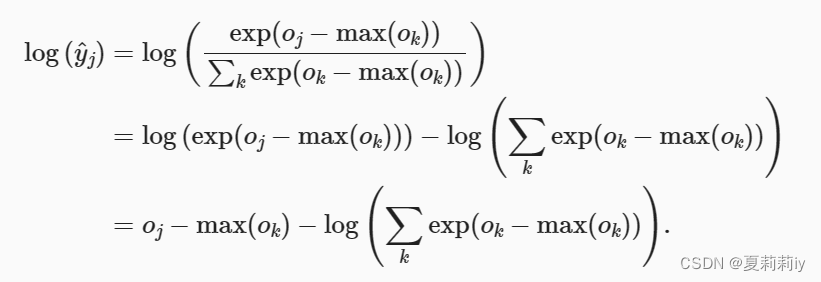


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









