







概念介绍
A/B Testing / Experimentation [Observing what people do not what they say]
源自于直接邮寄的测试方法,整体的项目框架为:提出假设,设立实验,得出结论。
可以概括为:“抽取10%的流量,其中50%用户访问新版本,50%访问旧版本。看看最后的结果是不是真的好。就算不好受到影响的也只有那总量中的5%的用户,如果效果显著就可以安心上线。”
A/B Testing不仅要具备统计意义(显著性差异),也要具备实际意义(现实提升)。
灰度测试(A/A测试) VS A/B测试
- 灰度测试:当推出新功能时,首先会进行一个小范围测试,然后慢慢放量,直到覆盖所有用户(5%、10%、 20%、50%、100%)。主要用于上线前的测试,然后收集用户反馈。当灰度测试结束后,线上版本会实现统一。
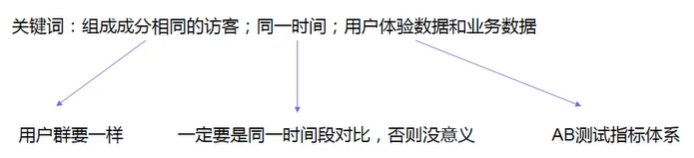
- A/B测试:制作多个程序版本,然后让组成成分相同的用户,进行随机访问,分析评估出最好的版本。A/B测试是一个反复迭代优化的过程,强调同一时间维度,对相似属性分组用户进行测试。
【注意事项】服务器能否支持对应的用户量及数据量 - 维度考量:流量比例,IP地址库,用户ID,用户特征(人口属性&行为)
适用场景:
1)UI/UX界面型:
- 落地页风格
- 添加元素
- 元素大小、位置
2)算法策略型: - 首屏推荐,是方案A 100%推荐兴趣预选,方案B 80%兴趣预选+20%随机,方案C 70%兴趣预选+20%热点+10%随机等等
- 广告位置

理论基础
定理
- 大数定理
随机变量X,随机采样N次,若N趋于正无穷时,抽样的平均值收敛于这个随机变量的期望 - 中心极限定理
无论什么分布,当变量是独立随机时,样本容量越大,其均值分布趋于正态分布。
(1)任何一个样本的平均值将会约等于其所在总体的平均值。
(2)不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的平均值周围,并且呈正态分布。
中心极限定理作用:
(1)在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体。
(2)根据总体的平均值和标准差,判断某个样本是否属于总体。 - 辛普森悖论
探究两种变量是否具有相关性的时候,会分别对之进行分组研究。然而,在分组比较中都占优势的一方,在总评中有时反而是失势的一方。原因:(1) 两个分组的数据差距很大;(2) 自变量不是影响因变量的唯一因素,甚至可能是毫无影响的。 -> 添加权重 - 假设检验 Hypothesis Analysis
利用样本对总体进行某种推断,先对μ的值提出一个假设,然后利用样本信息去检验这个假设是否成立,即两个样本是否存在显著性差异。 - 置信区间&置信度(Level of confidence)&显著性
置信区间是通过样本计算得出的总体参数变量存在的范围,置信度(置信水平)就是总体参数落在计算出的这个范围的可信程度。
显著性(P-Value):事件发生的概率
基本原理:1)一个命题只能证伪,不能证明为真 ;2)在一次观测中,小概率事件(5%)不可能发生; 3)在一次观测中,如果小概率事件发生了,那就是原命题为假。
因此P-Value越小,代表该事件发生的可能性越小,为小概率事件。
Sample Size的计算原理/如何选择Sample Size
最低样本量通过先验假定求得:考虑两类错误(统计功效),baseline越小,需要的样本容量越大。
最小样本量计算参数
- 统计功效Power:拒绝H0后接受H1的概率,即α
- 置信度:做出结论的可信度,1-pValue
- 显著性:P-Value
- Baseline Rate:历史经验值
- Minimum Detective Effect:最小改善率,即想提升多少
为什么做AB测试的时候要计算Sample Size?
1)样本容量过于小的话,无法佐证实验结论
2)假设检验可能存在的两类错误
,且两类错误此消彼长,目前唯一可以同时减少两类错误的可行方案就是增大样本容量
如何确定测试时长?
1)版本个数(包括控制版本)
2)每日独立访客数量UV
分层试验 & 流量正交
尽管AB测试是抽取了总体流量的一部分进行试验,但是由于每次AB测试只能针对单一改动进行测试,如果改动点很多,测试用的流量不够用怎么办?采用分层实验。(基于Google《Overlaping Experiment Infrastructure More, Better, Faster Experimentation》)
概念:
将多个实验建立起多层实验结构,每一层实验室用过的流量,下一层接着使用。例如按钮颜色、背景颜色、推荐算法优化均提高了点击率,但是从按钮分流进算法的流量,比从背景色分流进算法的提升率更大,因此可以初步判断按钮颜色和推荐算法这两个试验点间,存在互相的增益效果。

流量正交
保证每一层用完的流量进入下一层时,一定是均匀的重新分配,以便下一层的每个实验点都有近乎等量的来自上一层各个实验点的流量。
分层原则
1)有依赖关系的实验点必须划分在同一层,例如上述按钮颜色、背景颜色、字体颜色等等等
2)没有依赖关系的实验点可以划分在不同层
3)每个变量实验点只出现在一层中,不会出现在多层中
如果统计显著但是实际发现不显著是什么原因,怎么验证?
分桶不平衡:
- AA testing
- 大流量
如何排除偏见(Bias)干扰?注意事项?
1)AB两个组是否真的相同
- 只有一个变量改变,进行测试
2)策略是否生效?
- 分析师需要抽样去看,查看实验组的用户是否真的上线了优化版本
3)AB测试评估指标体系
- 测试开始前,就要沟通好进行哪些综合性指标的查看
| 实验策略 | 日期 | 用户数 | 次留 | 时长 | 点击率 |
|---|---|---|---|---|---|
| 001 | XXXX-XX-XX | 10w | 0.32 | 4.8min/人 | 18% |
| 001002 | XXXX-XX-XX | 10.2w | 0.35 | 5min/人 | 20% |
4)多观察几天的数据
- 往往刚开始测试时,前几天的数据可能有些问题,一般3天后数据才可正式使用
- 1-3天可以发现试验是否有问题
- 4-10天相对稳定,可以当做测试结论
5) AB测试的存档规划
- 所有AB测试都要文档化,以便后续寻找增长点及工作复盘
- 定期复盘做了哪些AB测试,预期效果,实际效果
- 5W1H方法管理AB测试
| AB测试项 | 具体内容What | 为何测试Why | 对应业务方或业务Where | 测试平台Where | 测试时间When | 测试负责人Who | 预期效果 | 实际效果 |
|---|---|---|---|---|---|---|---|---|
实验过程

A/B测试工具
- Oracle Maxymiser
- Google Optimize
经典结论
- 美即好用效应 Aesthetic Usability Effect






















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









